图像分类精度提升方法
1.本发明涉及一种图像分类精度提升方法,属于图像分类技术领域。
背景技术:
2.为了实现更高的图像分类精度,卷积神经网络(cnn)被设计得越来越大、越来越深,然而计算成本也被极大的提高。
3.为了降低计算成本,有研究人员提出了网络剪枝方法并被广泛应用,它可以去除对分类精度贡献较小的网络参数。通过该方法可以尽可能降低计算成本,同时保证剪枝后的网络保持原始网络的表示能力,以使分类精度下降最小,以获取紧凑的网络模型。
4.现有的网络剪枝方法大致可以分为两类:静态剪枝和动态剪枝,其中静态通道剪枝方法,通过删除对整体性能贡献较小的特征通道,获取静态的简化模型;动态剪枝方法则获取与输入图片实例相关的子网络,以减少运行时的计算成本。
5.传统的动态剪枝方法中利用附属的门控模块生成通道级的二进制掩码,即门控向量,用于指示通道的删除或保留。门控模块根据不同输入的特征变化探索实例级冗余,即,对于不同的输入实例,识别特定特征的通道可以自适应地打开或者关闭。
6.然而,现有的网络剪枝方法通常忽略了特征和门控分布之间的一致性。例如,当实例对具有相似特征但是迥异的门控时,由于门控特征是由特征向量和门控向量的通道相乘产生的,因此两者分布的不一致会导致门控特征空间中的失真,门控特征的失真可能会将噪声实例引入相似的实例对或使它们分离,从而降低修剪网络的表示能力。
7.因此,有必要对门控耦合进行更深入的研究,以期解决上述技术问题。
技术实现要素:
8.为了克服上述问题,本发明人进行了深入研究,设计出一种图像分类精度提升方法,包括:
9.获取图像数据集;
10.设置卷积神经网络;
11.采用特征-门控耦合方法对卷积神经网络进行动态网络剪枝,获得优化网络;
12.将待分类图像输入优化网络,利用优化网络对图像进行分类,
13.所述特征-门控耦合方法,包括以下步骤:
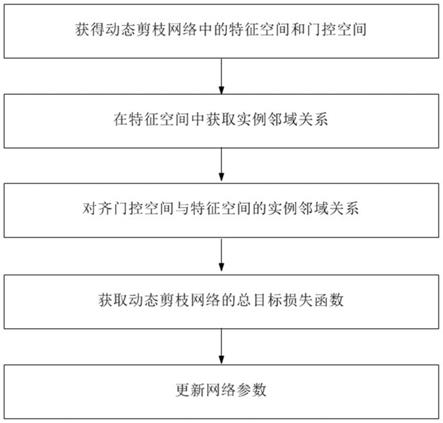
14.步骤1、获得动态剪枝网络中的特征空间和门控空间;
15.步骤2、在特征空间中获取实例邻域关系;
16.步骤3、对齐门控空间与特征空间的实例邻域关系;
17.步骤4、获取动态剪枝网络的总目标损失函数;
18.步骤5、更新网络参数。
19.优选地,步骤2包括以下子步骤:
20.步骤21、池化实例特征,获得实例池化向量
21.步骤22、根据实例池化向量获取实例的相似性矩阵
22.步骤23、通过实例的相似性矩阵确定实例的最近邻实例,将最近邻实例序号的集合作为自监督信号。
23.优选地,在步骤22中,通过度量不同实例池化向量之间的相似度获得不同实例之间的相似度,所述度量通过点积进行。
24.优选地,在步骤23中,对的第i行进行排序,获得序列中k个最大元素的列序号,将这些序列号所对应的实例集合作为实例i的自监督信号。
25.优选地,步骤3中,通过对比损失函数聚拢正例和离散反例,从而实现门控空间与特征空间的实例邻域关系的对齐。
26.优选地,步骤3包括以下子步骤:
27.步骤31、获取实例j为实例i正实例的概率;
28.步骤32、根据正实例概率获取对比损失函数,对比损失函数最小化,实现门控空间与特征空间的实例邻域关系的对齐。
29.优选地,步骤31中,输入实例在门控空间中被识别为实例i的正实例的概率为:
[0030][0031]
其中,l表示第l层网络,实例i通过门控模块后的输出的门控概率,是实例j通过门控模块后的输出的门控概率,τ为温度超参数。
[0032]
优选地,在步骤4中,所述总目标损失函数loss为:
[0033][0034]
其中,是交叉熵损失函数,表示第l层的对比损失函数,为第l层的l0范数损失函数;η、ρ为系数,ω为网络层序号的集合。
[0035]
本发明还提供了一种电子设备,包括:
[0036]
至少一个处理器;以及
[0037]
与所述至少一个处理器通信连接的存储器;其中,所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行上述的方法之一。
[0038]
本发明还提供了一种存储有计算机指令的计算机可读存储介质,其中,所述计算机指令用于使所述计算机执行根据上述的方法之一。
[0039]
本发明所具有的有益效果包括:
[0040]
(1)能够对齐动态剪枝网络中的特征分布和相应的门控分布;
[0041]
(2)通过迭代地执行邻域关系探索和特征-门控对齐来实现特征-门控耦合,能够极大地减少门控特征的失真;
[0042]
(3)能够显著提高动态剪枝网络的性能。
附图说明
[0043]
图1示出根据本发明一种优选实施方式的特征-门控耦合方法进行动态网络剪枝流程示意图。
具体实施方式
[0044]
下面通过附图和实施例对本发明进一步详细说明。通过这些说明,本发明的特点和优点将变得更为清楚明确。
[0045]
在这里专用的词“示例性”意为“用作例子、实施例或说明性”。这里作为“示例性”所说明的任何实施例不必解释为优于或好于其它实施例。尽管在附图中示出了实施例的各种方面,但是除非特别指出,不必按比例绘制附图。
[0046]
传统的动态网络剪枝方法可能会出现门控特征的失真,为解决该问题,在本发明中,通过对齐特征和门控的分布,最大程度地减少门控特征的失真。
[0047]
根据本发明提供的图像分类精度提升方法,包括:
[0048]
获取图像数据集;
[0049]
设置卷积神经网络;
[0050]
采用特征-门控耦合方法对卷积神经网络进行动态网络剪枝,获得优化网络;
[0051]
将待分类图像输入优化网络,利用优化网络对图像进行分类,
[0052]
在本发明中,所述图像数据集用于训练神经网络,图片数据集的获取方法在本发明中不做特别限制,可以是任意一种公开图片分类训练集,也可以是本领域技术人员根据实际需要自行设计的图像数据集。
[0053]
在本发明中,对所述卷积神经网络的具体结构不做限定,本领域技术人员可根据实际需要选择合适的卷积神经网络结构。
[0054]
所述特征-门控耦合方法,如图1所示,包括以下步骤:
[0055]
步骤1、获得动态剪枝网络中的特征空间和门控空间;
[0056]
步骤2、在特征空间中获取实例邻域关系;
[0057]
步骤3、对齐门控空间与特征空间的实例邻域关系;
[0058]
步骤4、获取动态剪枝网络的总目标损失函数;
[0059]
步骤5、更新网络参数。
[0060]
在步骤1中,按照动态网络剪枝bas中的方法将输入卷积神经网络的图片实例映射至特征空间和门控空间,动态网络剪枝bas相关介绍可参见论文:b.ehteshami bejnordi,t.blankevoort,m.welling,batch-shaping for learning conditional channel gated networks,in:proceedings of international conference on learning representations(iclr),2020.
[0061]
所述特征空间包含当前卷积层的实例特征,根据本发明,所述动态网络剪枝可以设置在卷积神经网络的任意卷积层,当动态网络剪枝设置在卷积神经网络的第l卷积层时,所述实例特征表示为:
[0062][0063]
其中,i表示不同的实例,l表示卷积神经网络的层;
[0064]
是卷积神经网络第l卷积层的输入,是第l卷积层的输出,c
l
是第l卷积层的输出通道数,w
l
表示第l卷积层的卷积权值矩阵,*表示卷积算子,relu表示激活函数,。
[0065]
所述门控空间包含当前卷积层的门控向量,进一步地,当动态网络剪枝设置在卷积神经网络的第l卷积层时,门控向量与实例特征进行通道级相乘,得到门控特征,表示为:
[0066][0067]
其中,g表示门控模块,
⊙
表示通道级相乘,表示门控特征。
[0068]
在一个优选的实施方式中,所述门控模块g可以表示为:
[0069]
g()=binconcrete(linear(p()))(三)
[0070]
其中,p表示全局平均池化层,用于生成输入特征的空间描述符;linear()表示两个完全连接层,用于生成门控概率;binconcrete为激活函数。
[0071]
进一步地,卷积神经网络第l卷积层对应的门控概率表示为:
[0072][0073]
卷积神经网络第l卷积层对应的门控向量为:
[0074][0075]
进一步地,根据式一、式三、式六,卷积神经网络第l卷积层对应的门控特征还可以表示为:
[0076][0077]
在步骤2中,由于实例邻域关系在不同语义层级的特征空间中不同,例如在低级特征空间中,具有相似颜色或纹理的实例可能更接近,而在高级特征空间中,同一类中的实例可能聚在一起,因此,人工注释无法提供跨不同网络阶段的实例邻域关系的自适应监督,如何获取特征空间中的实例邻域关系是本发明的难点所在。
[0078]
本发明提出了一种自适应获取每个特征空间中的实例领域关系的方法,该方法能够在网络的任意层中使用,获取用于特征-门控分布对齐的自监督信号。
[0079]
具体地,包括以下子步骤:
[0080]
步骤21、池化实例特征,获得实例池化向量
[0081]
针对设置有动态网络剪枝的卷积神经网络第l卷积层,使用全局平均池化层将该层中的第i个实例的特征池化为向量池化后的向量称之为实例池化向量,通过池化,将特征的维度从c
l
×wl
×hl
减少到c
l
×1×
1,提高后续处理的效率及效果。
[0082]
步骤22、根据实例池化向量获取实例的相似性矩阵
[0083]
所述实例的相似性矩阵用于表征l层中不同实例之间的相似度,进一步地,通
过度量不同实例池化向量之间的相似度表征不同实例之间的相似度,优选地,所述度量通过点积进行,不同实例之间的相似度可以表示为:
[0084][0085]
其中,i、j表示不同的实例,表示卷积神经网络第l卷积层中,第i个实例和第j个实例之间的相似度,t表示转置。
[0086]
进一步地,将第l卷积层中所有实例的相似度组合成矩阵,该矩阵即为相似性矩阵矩阵的元素为n表示用于训练的总实例数。
[0087]
步骤23、通过实例的相似性矩阵确定实例的最近邻实例,将最近邻实例序号的集合作为自监督信号。
[0088]
对的第i行进行排序,获取k个最大元素的列序号,这些列序号对应的实例即为实例i的最近邻实例,最近邻实例序号的集合即为实例i的自监督信号,用于规整门控模块,表示为:
[0089][0090]
其中,表示实例i的自监督信号,topk表示的第i行中的k个列序号,所述列序号在第i行中对应的元素为第i行中最大的k个元素。
[0091]
优选地,k的取值为100-500,更优选为200。
[0092]
在一个优选的实施方式中,在步骤21中,并不是每次输入新的图片实例都将所有已输入的图片实例重新计算实例池化向量,而是将已获得的实例池化向量存储在特征内存库中,其中d是池化特征的维度,即通道数c
l
,在后续输入的图片实例中,在计算相似性时,直接调用中的向量即可。
[0093]
进一步地,所述特征内存库以动量方式更新,可以表示为:
[0094][0095]
其中动量系数m设置为0.3-0.7,优选为0.5,内存库中的所有向量初始化时为单位随机向量。
[0096]
在步骤3中,根据实例i的自监督信号,可以获得实例i的最近邻集合,表示为最近邻集合中的实例即为要拉近的正实例,而最近邻集合外的其它实例则为要在门控空间中推开的负实例。
[0097]
所述正实例是指实例i的最近邻实例,除了最近邻实例外的实例称为负实例。
[0098]
在一个优选的实施方式中,步骤3包括以下子步骤:
[0099]
步骤31、获取实例j为实例i正实例的概率。
[0100]
具体地,输入卷积神经网络的实例在第l卷积层对应的门控空间中被识别为实例i的正实例的概率为:
[0101][0102]
其中,l表示卷积神经网络的第l卷积层,实例i通过门控模块后输出的门控概率,是实例j通过门控模块后输出的门控概率,τ为温度超参数,优选设置为0.01-0.2,例如设置为0.07。
[0103]
步骤32、根据正实例概率获取对比损失函数,对比损失函数最小化,实现门控空间与特征空间的实例邻域关系的对齐。
[0104]
具体地,所述对比损失函数为:
[0105][0106]
通过对比损失函数最小化,即可将特征空间中的最近邻在门控空间中拉近,从而在门控空间内再现特征空间的实例邻域关系,实现门控空间与特征空间的实例邻域关系的对齐。
[0107]
本发明中设计的对比损失函数是infonce损失函数的一种变体,该对比损失函数最小化能够提升特征分布和门控分布之间的互信息,其具体原理可以通过以下分析进行解释:
[0108]
将实例特征分布和门控特征分布之间的互信息定义为:
[0109][0110]
和之间的互信息可以由一个概率密度比例例来表示,且是所对应的门控概率,是对应的正实例的门控概率。
[0111]
根据上式,可以将对比损失函数重写为:
[0112][0113]
其中,表示特征空间中的最近邻实例特征。
[0114]
和之间的互信息受到如下不等式的约束:
[0115][0116]
上式表明对比损失函数最小化可以最大化实例特征分布和门控特征分布的互信息的下限,相应地,实例特征分布和门控特征分布的互信息的提升促进了两者分布的对
齐。
[0117]
在一个优选的实施方式中,在步骤31中,通过门控内存库来存储任一个实例i的门控概率在步骤32中,根据实例i的自监督信号从门控内存库中提取对应的正例以计算公式(十一),从而避免了重复性的计算,降低计算量。
[0118]
进一步地,当输入新的实例后,所述门控内存库以动量方式更新,可以表示为:
[0119][0120]
其中动量系数m设置为0.3-0.7,优选为0.5,内存库中的所有向量初始化时为单位随机向量。
[0121]
在步骤4中,所述总目标损失函数loss设置如下:
[0122][0123]
其中,是交叉熵损失函数,表示第l卷积层的对比损失函数,为第l卷积层的l0范数损失函数,与bas中的l0范数损失函数相同;η、ρ为系数,ω为卷积神经网络中设置有特征-门控耦合的卷积层序号的集合。
[0124]
进一步地,用于每个门控层,其中‖
·
‖0是l0范数。
[0125]
根据本发明,系数ρ的取值本领域技术人员可根据需要通过多次试验确定,其中,系数ρ用来控制剪枝模型的稀疏性,即ρ越大,模型越稀疏,精度越低,ρ越低,稀疏性越低,精度越高。
[0126]
优选地,系数η的取值为0.002-0.004,更优选为0.003。
[0127]
根据本发明,总目标损失函数包括了交叉熵损失函数、l0范数损失函数和对比损失函数。其中,交叉熵损失函数用于图像分类任务;l0范数损失函数用于强化门控向量的稀疏性;对比损失函数用于特征-门控分布对齐。通过上述设置,使得动态网络剪枝能够将特征与门控耦合,最大程度地减少了门控特征的失真。
[0128]
在步骤5中,根据动态剪枝网络的总目标损失函数,通过通过梯度反传更新动态剪枝网络的参数,若网络收敛,则终止并返回最后的模型;否则重复步骤1-5,进行迭代更新。
[0129]
该步骤的具体方法与传统的神经网络更新参数方法相同,在本发明中不做赘述。
[0130]
本发明中以上描述的方法的各种实施方式可以在数字电子电路系统、集成电路系统、场可编程门阵列(fpga)、专用集成电路(asic)、专用标准产品(assp)、芯片上系统的系统(soc)、负载可编程逻辑设备(cpld)、计算机硬件、固件、软件、和/或它们的组合中实现。这些各种实施方式可以包括:实施在一个或者多个计算机程序中,该一个或者多个计算机程序可在包括至少一个可编程处理器的可编程系统上执行和/或解释,该可编程处理器可以是专用或者通用可编程处理器,可以从存储系统、至少一个输入装置、和至少一个输出装置接收数据和指令,并且将数据和指令传输至该存储系统、该至少一个输入装置、和该至少一个输出装置。
[0131]
用于实施本发明的方法的程序代码可以采用一个或多个编程语言的任何组合来编写。这些程序代码可以提供给通用计算机、专用计算机或其他可编程数据处理装置的处理器或控制器,使得程序代码当由处理器或控制器执行时使流程图和/或框图中所规定的功能/操作被实施。程序代码可以完全在机器上执行、部分地在机器上执行,作为独立软件包部分地在机器上执行且部分地在远程机器上执行或完全在远程机器或服务器上执行。
[0132]
在本发明的上下文中,机器可读介质可以是有形的介质,其可以包含或存储以供指令执行系统、装置或设备使用或与指令执行系统、装置或设备结合地使用的程序。机器可读介质可以是机器可读信号介质或机器可读储存介质。机器可读介质可以包括但不限于电子的、磁性的、光学的、电磁的、红外的、或半导体系统、装置或设备,或者上述内容的任何合适组合。机器可读存储介质的更具体示例会包括基于一个或多个线的电气连接、便携式计算机盘、硬盘、随机存取存储器(ram)、只读存储器(rom)、可擦除可编程只读存储器(eprom或快闪存储器)、光纤、便捷式紧凑盘只读存储器(cd-rom)、光学储存设备、磁储存设备、或上述内容的任何合适组合。
[0133]
为了提供与用户的交互,可以在计算机上实施此处描述的方法,该计算机具有:用于向用户显示信息的显示装置(例如,crt(阴极射线管)或者lcd(液晶显示器)监视器);以及键盘和指向装置(例如,鼠标或者轨迹球),用户可以通过该键盘和该指向装置来将输入提供给计算机。其它种类的装置还可以用于提供与用户的交互;例如,提供给用户的反馈可以是任何形式的传感反馈(例如,视觉反馈、听觉反馈、或者触觉反馈);并且可以用任何形式(包括声输入、语音输入或者、触觉输入)来接收来自用户的输入。
[0134]
可以将此处描述的方法和装置实施在包括后台部件的计算系统(例如,作为数据服务器)、或者包括中间件部件的计算系统(例如,应用服务器)、或者包括前端部件的计算系统(例如,具有图形用户界面或者网络浏览器的用户计算机,用户可以通过该图形用户界面或者该网络浏览器来与此处描述的系统和技术的实施方式交互)、或者包括这种后台部件、中间件部件、或者前端部件的任何组合的计算系统中。可以通过任何形式或者介质的数字数据通信(例如,通信网络)来将系统的部件相互连接。通信网络的示例包括:局域网(lan)、广域网(wan)和互联网。
[0135]
计算机系统可以包括客户端和服务器。客户端和服务器一般远离彼此并且通常通过通信网络进行交互。通过在相应的计算机上运行并且彼此具有客户端-服务器关系的计算机程序来产生客户端和服务器的关系。服务器可以是云服务器,又称为云计算服务器或云主机,是云计算服务体系中的一项主机产品,以解决了传统物理主机与vps服务(
″
virtual private server
″
,或简称
″
vps
″
)中,存在的管理难度大,业务扩展性弱的缺陷。服务器也可以为分布式系统的服务器,或者是结合了区块链的服务器。
[0136]
应该理解,可以使用上面所示的各种形式的流程,重新排序、增加或删除步骤。例如,本发公开中记载的各步骤可以并行地执行也可以顺序地执行也可以不同的次序执行,只要能够实现本发明公开的技术方案所期望的结果,本文在此不进行限制。
[0137]
实施例
[0138]
实施例1
[0139]
在标题准图像分类数据库上进行实验,实验数据库,即图像数据集为cifar10,cifar10数据集都包含6万个彩色图像实例,其中5万个实例用于训练和1万个实例用于测
试,实验环境为:nvidia rtx 3090 gpu,使用pytorch进行。
[0140]
设置卷积神经网络,使用resnet-20模型进行实验,模型训练400个周期,每个批次的图像实例数目为256。使用nesterov的加速梯度下降优化器,其中动量设置为0.9,权重衰减设置为5e-4
,学习率初始值设置为0.1,采用多步衰减策略,即在训练周期分别到达[200,275,350]时衰减0.1。
[0141]
采用特征-门控耦合方法对resnet-20模型中最后两个残差模块中设置动态剪枝网络进行动态剪枝,获得优网络,该动态剪枝方法包括以下步骤:
[0142]
步骤1、获得动态剪枝网络中的特征空间和门控空间;
[0143]
步骤2、在特征空间中获取实例邻域关系;
[0144]
步骤3、对齐门控空间与特征空间的实例邻域关系;
[0145]
步骤4、获取动态剪枝网络的总目标损失函数;
[0146]
步骤5、更新网络参数。
[0147]
步骤1中,resnet-20模型的最后两个残差模块的层数即为卷积神经网络的第l卷积层和第l+1卷积层,这里以第l卷积层为例进行说明,第l+1层与l层的剪枝过程相同。
[0148]
第l卷积层的特征表示为:
[0149][0150]
,resnet-20模型第l卷积层对应的门控特征表示为:
[0151][0152]
其中,
[0153]
p表示全局平均池化层;linear()表示两个完全连接层;binconcrete为激活函数。
[0154]
步骤2包括以下子步骤:
[0155]
步骤21、池化实例特征,获得实例池化向量
[0156]
针对卷积神经网络第l卷积层,使用全局平均池化层将第i个实例的特征池化为为向量
[0157]
步骤22、获取实例的相似性矩阵
[0158]
矩阵的元素为不同实例之间的相似度:
[0159][0160]
其中,表示第l层网络中,第i个实例和第j个实例之间的相似度,t表示转置
[0161]
步骤23、通过实例的相似性矩阵确定不同实例的最近邻实例,将最近邻实例序号的集合作为自监督信号;
[0162]
实例i的自监督信号为:
[0163]
[0164]
其中,表示实例i的自监督信号,topk表示的第i行中的k个最大元素的列序号,这里k取200。
[0165]
在步骤3中,步骤3包括以下子步骤:
[0166]
步骤31、获取实例j为实例i正实例的概率;
[0167]
输入卷积神经网络的实例在第l卷积层对应的门控空间中被识别为实例i的正实例的概率为:
[0168][0169]
l表示卷积神经网络的第l卷积层,实例i通过门控模块后的输出的门控概率,是实例j通过门控模块后的输出的门控概率,τ为0.07,
[0170]
步骤32、根据正实例概率获取对比损失函数,对比损失函数最小化,实现门控空间与特征空间的实例邻域关系的对齐;
[0171]
对比损失函数表示为:
[0172][0173]
通过对比损失函数最小化,实现门控空间与特征空间的实例邻域关系的对齐。
[0174]
在步骤4中,所述总目标损失函数loss设置如下:
[0175][0176]
其中,是交叉熵损失函数,表示第l层的对比损失函数,为第l层的l0范数损失函数;η、ρ为系数,η取0.003,ρ取0.4,ω为网络层序号的集合,这里共两个网络层,即l和l+1层。
[0177]
进一步地,通过优化网络在上述分类数据库上进行分类实验。
[0178]
实施例2
[0179]
进行与实施例1相同的实验,区别在于,使用resnet-32模型进行实验。
[0180]
实施例3
[0181]
进行与实施例1相同的实验,区别在于,使用resnet-56模型进行实验,在resnet-56中的最后四个残差模块中设置动态剪枝网络,动态剪枝的过程与实施例1相同,步骤4中网络层序号的集合为四层。
[0182]
实施例4
[0183]
进行与实施例1相同的实验,区别在于,实验数据库为cifar100,模型训练400个周期,每个批次的图像实例数目为128,初始学习率设置为0.1,同样采用采用多步衰减策略,在训练周期分别到达[60,120,160]时衰减0.2。
[0184]
实施例5
[0185]
进行与实施例4相同的实验,区别在于,区别在于,使用resnet-32模型进行实验。
[0186]
实施例6
[0187]
进行与实施例4相同的实验,区别在于,区别在于,使用resnet-56模型进行实验,在resnet-56中的最后四个残差模块中设置动态剪枝网络,动态剪枝的过程与实施例4相同,步骤4中网络层序号的集合为四层。
[0188]
实施例7
[0189]
进行与实施例1相同的实验,区别在于,实验数据库为imagenet,由于训练过程耗时较大,使用resnet-18模型进行实验,训练模型共130个周期,每个批次的图像实例数目为256,权重衰减设置为1e-4
,学习率初始化为0.1,同样采用采用多步衰减策略,在训练周期为[40,70,100]时衰减0.1。
[0190]
实施例8
[0191]
进行与实施例1相同的实验,区别在于,步骤23中,k的取分别为5、20、100、512、1024、2048、4096。
[0192]
结果如表一所示:
[0193]
表一
[0194][0195]
从表一可以看出,最近邻数目k为200时,取得的剪枝效果较优。
[0196]
实施例9
[0197]
进行与实施例1相同的实验,区别在于,步骤4中,系数η取值分别为5e-4、0.001、0.002、0.003、0.005、0.01、0.02。
[0198]
结果如表二所示
[0199]
表二
[0200][0201][0202]
从表二可以看出,系数η为0.003时,取得的剪枝效果较优。
[0203]
对比例
[0204]
对比例1
[0205]
进行与实施例1相同的实验,区别在于,采用sfp方法、fpgm方法、dsa方法、hinge方法、dhp方法、fbs方法、bas方法分别进行剪枝,
[0206]
sfp方法具体参见论文:y.he,g.kang,x.dong,y.fu,y.yang,soft filter pruning for accelerating deep convolutional neural networks,in:proceedings of international joint conference on artificial intelligence(ijcai),2018,pp.2234-2240.
[0207]
fpgm方法具体参见论文:y.he,p.liu,z.wang,z.hu,y.yang,filter pruning via geometric median for deep convolutional neural networks acceleration,in:proceedings of ieee conference on computer vision and pattern recognition(cvpr),2019,pp.4340-4349.
[0208]
dsa方法具体参见论文:x.ning,t.zhao,w.li,p.lei,y.wang,h.yang,dsa:more efficient budgeted pruning via differentiable sparsity allocation,in:proceedings of european conference on computer vision(eccv),2020,pp.592-607.
[0209]
hinge方法具体参见论文:y.li,s.gu,c.mayer,l.v.gool,r.timofte,group sparsity:the hinge between filter pruning and decomposition for network compression,in:proceedings of ieee conference on computer vision and pattern recognition(cvpr),2020,pp.8015-8024.
[0210]
dhp方法具体参见论文:y.li,s.gu,k.zhang,l.v.gool,r.timofte,dhp:differentiable meta pruning via hypernetworks,in:proceedings of european conference on computer vision(eccv),2020,pp.608-624.
[0211]
fbs方法具体参见论文:x.gao,y.zhao,l.dudziak,r.d.mullins,c.xu,dynamic channel pruning:feature boosting and suppression,in:proceedings of international conference on learning representations(iclr),2019.
[0212]
bas方法具体参见论文:b.ehteshami bejnordi,t.blankevoort,m.welling,batch-shaping for learning conditional channel gated networks,in:proceedings of international conference on learning representations(iclr),2020.
[0213]
对比例2
[0214]
进行与实施例2相同的实验,区别在于,采用baseline方法、sfp方法、fpgm方法、fbs方法、bas方法替换实施例2中的动态剪枝方法分别进行剪枝,
[0215]
baseline方法具体参见论文:k.he,x.zhang,s.ren,j.sun,deep residual learning for image recognition,in:proceedings of ieee conference on computer vision and pattern recognition(cvpr).2016:770-778.
[0216]
对比例3
[0217]
进行与实施例3相同的实验,区别在于,采用baseline方法、sfp方法、fpgm方法、hrank方法、dsa方法、hinge方法、dhp方法、fbs方法、bas方法替换实施例3中的动态剪枝方法分别进行剪枝。
[0218]
hrank方法具体参见论文:m.lin,r.ji,y.wang,y.zhang,b.zhang,y.tian,l.shao,hrank:filter pruning using high-rank feature map,in:proceedings of ieee conference on computer vision and pattern recognition(cvpr),2020,pp.1526-1535.
[0219]
对比例4
[0220]
进行与实施例4相同的实验,区别在于,采用baseline方法、bas方法替换实施例4中的动态剪枝方法分别进行剪枝。
[0221]
对比例5
[0222]
进行与实施例5相同的实验,区别在于,采用baseline方法、cac方法、bas方法替换实施例5中的动态剪枝方法分别进行剪枝。
[0223]
cac方法具体参见论文:z.chen,t.xu,c.du,c.liu,h.he,dynamical channel pruning by conditional accuracy change for deep neural networks,ieee trans.neural networks learn.syst.(tnnls)32(2)(2021)799-813.
[0224]
对比例6
[0225]
进行与实施例6相同的实验,区别在于,采用baseline方法、cac方法、bas方法替换实施例6中的动态剪枝方法分别进行剪枝。
[0226]
对比例7
[0227]
进行与实施例7相同的实验,区别在于,采用baseline方法、sfp方法、fpgm方法、dsa方法、lccn方法、cgnet方法、fbs方法、bas方法替换实施例7中的动态剪枝方法分别进行剪枝。
[0228]
lccn方法具体参见论文:x.dong,j.huang,y.yang,s.yan,more is less:a more complicated network with less inference complexity,in:proceedings of ieee conference on computer vision and pattern recognition(cvpr),2017,pp.1895-1903.
[0229]
cgnet方法具体参见论文:w.hua,y.zhou,c.d.sa,z.zhang,g.e.suh,channel gating neural networks,in:proceedings of advances in neural information processing systems(neurips),2019,pp.1884-1894.
[0230]
实验例1
[0231]
统计实施例1~3与对比例1~3的剪枝结果,结果如表三所示表三
[0232]
[0233][0234][0235]
实施例1、2、3中的两组结果分别为最小分类误差和最大压缩率时的性能,从两组
结果中可以看出实施例1-3可以实现分类误差与压缩率之间的更好权衡。
[0236]
在该实验例中,分类误差即为错误分类的样本占总样本数的比例,top-1分类误差的计算方式为:
[0237][0238]
其中yi代表第i样本的类别标号,n代表总的样本数目,top1(zi)代表向量zi中最大元素的下标,zi表示网络输出:
[0239][0240]
其中代表网络的输入,即第0卷积层的第i样本;nn代表卷积神经网络,由前述的多个卷积层级联而成;代表网络的输出,nc是类别数目,代表正确识别的样本数目,yi==top1(zi)的含义是,当网络的预测top1(zi)与类别标号yi一致时,取值为1,反之为0。
[0241]
剪枝比率的计算方式为:
[0242][0243]
其中代表第l卷积层的门控向量的零元素的比率,亦可以视为当前层的计算量裁剪比率,代表第l卷积层的计算量,comp
nn_original
代表原始(未裁剪)卷积网络的计算量,根据每个门控卷积层的计算量裁剪比率,计算出网络对于各个样本的裁剪计算量,取平均值后除以原始卷积网络的计算量,得到网络的裁剪比率。
[0244]
从表三中可以看出,实施例1、2、3中的方法,在更高的剪枝比率下取得了更低的分类误差,显著提高了剪枝性能,优于现有先进的网络剪枝方法。
[0245]
实验例2
[0246]
统计实施例4~6与对比例4~6的剪枝结果,结果如表四所示表四
[0247][0248][0249]
与实施例1-3相同,实施例4-6中的两组结果分别为最小分类误差和最大压缩率时的性能,从两组结果中可以看出实施例4-6可以实现分类误差与压缩率之间的更好权衡。
[0250]
从表四中可以看出,实施例4、5、6中的方法能够在更高的剪枝比率下取得了更低的分类误差,显著提高了剪枝性能,优于现有先进的网络剪枝方法。
[0251]
实验例3
[0252]
统计实施例7与对比例7的剪枝结果,结果如表五所示表五
[0253][0254][0255]
与实施例1-3相同,实施例7中的两组结果分别为最小分类误差和最大压缩率时的性能,从两组结果中可以看出实施例7可以实现分类误差与压缩率之间的更好权衡。
[0256]
该实验例中,top-5分类误差的计算方式为:
[0257][0258]
其中,top5(zi)代表向量zi中最大的5个元素的下标的集合
,
若yi属于这个集合,则yi∈top5(zi)的取值为1,反之为0;其余参数的含义与top-1分类误差中对应的参数含义相同。
[0259]
从表三、表四、表五中可以看出,实施例1-7中的方法在不同的数据集中,均能够在更高的剪枝比率下取得了更低的分类误差,优于现有先进的网络剪枝方法。
[0260]
在本发明的描述中,需要说明的是,术语“上”、“下”、“内”、“外”、“前”、“后”等指示的方位或位置关系为基于本发明工作状态下的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。此外,术语“第一”、“第二”、“第三”、“第四”仅用于描述目的,而不能理解为指示或暗示相对重要性。
[0261]
在本发明的描述中,需要说明的是,除非另有明确的规定和限定,术语“安装”“相
连”“连接”应作广义理解,例如,可以是固定连接,也可以是可拆卸连接,或一体的连接普通;可以是机械连接,也可以是电连接;可以是直接连接,也可以通过中间媒介间接连接,可以是两个元件内部的连通。对于本领域的普通技术人员而言,可以具体情况理解上述术语在本发明中的具体含义。
[0262]
以上结合了优选的实施方式对本发明进行了说明,不过这些实施方式仅是范例性的,仅起到说明性的作用。在此基础上,可以对本发明进行多种替换和改进,这些均落入本发明的保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1