一种扩展核密度空间分析的地理流方法
1.本发明涉及一种基于核密度空间分析的地理流方法,具体为一种扩展核密度空间分析的地理流方法,属于基于流的核密度估计模型的层次密度聚类技术领域。
背景技术:
2.地理流,也称为空间流,或空间相互作用(si),代表地球表面各区域之间有意义的人类关系,这里的流是由它的空间原点和空间目的地定义的,并不考虑其间路径的空间布局。因此,描述地理空间位置之间地理对象的移动或交互的空间流可以被建模为由起点o和终点d组成的有序连接点对,即o-d流。
3.研究空间流的首要任务就是揭示它存在的模式。对流模式的分析的前提是识别流模式,目前,对于地理流的研究方法主要有利用k函数和l函数、层次密度聚类方法hdbscan这几种方法扩展到空间流的情境中,而目前的研究进展主要集中在流的聚集模式上。聚集模式的定义是流的起点o和终点d都聚集的模式。通过识别流的聚集模式可以发现空间对象共同的移动特征以及空间位置之间的密切交互关系。现有的流的聚类方法可以分为两类:一种方法是将流视为整体的研究对象,利用时空扫描方法、层次聚类方法和基于密度的聚类方法提取聚集模式;二是将流看作点对,通过起点和终点聚集特征的组合,定义不同模式的流聚类,这类聚类的识别和提取主要依赖于统计判别方法。
技术实现要素:
4.本发明的目的就在于为了解决问题而提供一种扩展核密度空间分析的地理流方法,通过定义流的距离和流的搜索邻域,将核密度估计模型运用于流的情境中,提出基于核密度估计(kde)的层次密度聚类方法,并通过模拟实验验证来分析该方法的有效性和可靠性。
5.本发明通过以下技术方案来实现上述目的:一种扩展核密度空间分析的地理流方法,包括以下步骤:
6.步骤一、随机设计一组流,对其中所有的“o_d”流,用核密度估计公式每个流的邻域r内的该流的核密度,再计算流领域的搜索半径r,筛选搜索半径内的流,并选取核函数计算搜索半径内的流之间的核函数矩阵;
7.步骤二、对得到每个流的核密度大小进行从大到小排序,并归一化核密度,对核密度和前面值差距较大的离群的流进行剔除,将其视为噪波;从最大的核密度的流开始遍历,初始的每一个流的1/2r邻域内的流都形成一簇ci;接着往下遍历,若簇的邻域有公共交界/有公共流,则两簇扩充为一簇;若没有,则保留遍历的流的r邻域流簇,继续往下;直到最后合并完所有的流簇,生成分层聚类树;
8.步骤三、最后需要对流簇稳定性进行分析,引入了称为聚类稳定性的特殊指标作为评价标准来判定聚类结果。
9.作为本发明再进一步的方案:所述步骤一中,根据s搜索半径内的空间流,通过选
取的核函数计算核函数矩阵的具体包括以下过程:
10.一、随机设定一组流数据,根据流数据的o、d点坐标,选择距离公式
1.:
[0011][0012]
式中:分别为流fi与fj之间oi点与oj点、di点与dj点之间的欧氏距离。
[0013]
二、计算出流距离矩阵;按照arcgis中默认的选取搜索半径的公式
[2]
:
[0014][0015]
式中:sd为标准距离;dm为中值距离;n:如果没有使用流的属性字段,如人口流数据当中的人口字段,则为点数。或者,如果提供了流的属性字段,则n是人口字段值的总和;min:表示将使用两个选项中较小的一个,得到流邻域的搜索半径r;
[0016]
三、筛选搜索半径内的流,并选取核函数,此处本方法选取高斯函数,并计算搜索半径内的流之间的核函数矩阵,核函数的选取对结果影响并不大,其中kds的高数函数计算公式如下
[3-4]
:
[0017][0018]
式中:r是kde的搜索半径(带宽),k是对位置s来说在点i到位置s的距离dis下点i的权重。
[0019]
作为本发明再进一步的方案:所述步骤三中,评价流簇稳定性的具体步骤是
[5]
:
[0020][0021]
式中:s(ci)是聚类ci的聚类稳定性,λ此处为核密度,λbegin(fj)和λend(fj)分别对应于流fj属于聚类ci的最小和最大λ值。λstay(fj)表示介于两者之间的λ值范围。
[0022]
作为本发明再进一步的方案:所述步骤三中,分析结束后,将核密度函数应用于空间流领域,进而应用于海量流数据处理领域。
[0023]
本发明的有益效果是:将应用于点数据的核函数应用于“o-d”空间流中,将点的数据处理方法转换为线的处理方法,是一种方法的创新,为探索海量空间流数据提供了有效工具。
附图说明
[0024]
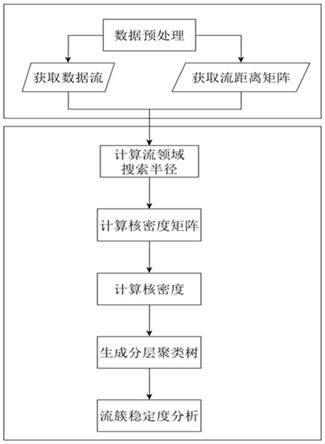
图1是种基于核密度空间分析的地理流方法流程图;
[0025]
图2是两个流的o点和d点之间的距离的示例图;
[0026]
图3是本方法样本流的起点终点坐标的示例表格;
[0027]
图4是流距离矩阵的示例表格;
[0028]
图5是核函数矩阵的示例表格;
[0029]
图6是进行核密度归一化、剔除后的聚类流的核密度的示例表格;
[0030]
图7是分层聚类树(红色方框表示提取的聚类)示意图;
[0031]
图8是芝加哥divvy共享单车轨迹数据(2021年2月)示意图;
[0032]
图9是随机选取100条共享单车流数据示意图;
[0033]
图10是分层聚类树示意图;
[0034]
图11是聚类结果示意图。
具体实施方式
[0035]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0036]
实施例一
[0037]
请参阅图1-11,一种扩展核密度空间分析的地理流方法,包括以下步骤:
[0038]
步骤一、随机设计一组流,对其中所有的流,用核密度估计公式每个流的邻域r内的该流的核密度,再计算流领域的搜索半径r,筛选搜索半径内的流,并选取核函数计算搜索半径内的流之间的核函数矩阵;
[0039]
步骤二、对得到每个流的核密度大小进行从大到小排序,并归一化核密度,对核密度和前面值差距较大的离群的流进行剔除,将其视为噪波。从最大的核密度的流开始遍历,初始的每一个流的1/2r邻域内的流都形成一簇ci;接着往下遍历,若簇的邻域有公共交界/有公共流,则两簇扩充为一簇;若没有,则保留遍历的流的r邻域流簇,继续往下;直到最后合并完所有的的流簇,生成分层聚类树;
[0040]
步骤三、最后需要对流簇稳定性进行分析,引入了称为聚类稳定性的特殊指标作为评价标准来判定聚类结果。
[0041]
在本发明实施例中,所述步骤一中,根据s搜索半径内的空间流,通过选取的核函数计算核函数矩阵的具体包括以下过程:
[0042]
一、随机设定一组流数据,根据流数据的o、d点坐标,选择距离公式
1.:
[0043][0044]
式中:分别为流fi与fj之间oi点与oj点、di点与dj点之间的欧氏距离。
[0045]
按照arcgis中默认的选取搜索半径的公式
[2]
:
[0046][0047]
(sd:标准距离;dm:中值距离;n:如果没有使用属性字段,如人口流当中的人口字段,则为点数。或者,如果提供了人口字段,则n是人口字段值的总和;min:表示将使用两个选项中较小的一个),得到流邻域的搜索半径r;
[0048]
筛选搜索半径内的流,并选取核函数,此处本方法选取高斯函数,并计算搜索半径内的流之间的核函数矩阵,核函数的选取对结果影响并不大,其中kds的高数函数计算公式如下
[3-4]:
[0049][0050]
其中r是kde的搜索半径(带宽),k是对位置s来说在点i到位置s的距离dis下点i的权重;
[0051]
得到核密度计算矩阵后,依照公式,加权计算每条流的核密度得到结果,具体公式如下
[2]
:
[0052][0053]
其中λ(s)是位置s的密度,核函数k通常被认为是dis和r之比的函数。因此,点i与位置s之间的距离越远,该点在计算总密度时的权重就越小。位置s的带宽r内的所有点相加,以计算s处的密度。
[0054]
二、计算出流距离矩阵;按照arcgis中默认的选取搜索半径的公式
[2]
:
[0055][0056]
式中:sd为标准距离;dm为中值距离;n:如果没有使用流的属性字段,如人口流数据当中的人口字段,则为点数。或者,如果提供了流的属性字段,则n是人口字段值的总和;min:表示将使用两个选项中较小的一个,得到流邻域的搜索半径r;
[0057]
三、筛选搜索半径内的流,并选取核函数,此处本方法选取高斯函数,并计算搜索半径内的流之间的核函数矩阵,核函数的选取对结果影响并不大,其中kds的高数函数计算公式如下
[3-4]:
[0058][0059]
式中:r是kde的搜索半径(带宽),k是对位置s来说在点i到位置s的距离dis下点i的权重。
[0060]
在本发明实施例中,所述步骤三中,评价流簇稳定性的具体步骤是
[5]
:
[0061][0062]
式中:s(ci)是聚类ci的聚类稳定性,λ此处为核密度,λbegin(fj)和λend(fj)分别对应于流fj属于聚类ci的最小和最大λ值。λstay(fj)表示介于两者之间的λ值范围,如果一个流与一个簇保持很大范围的λ值,它被认为是这个簇的忠实成员。如果一个集群包含许多忠诚的成员,它就被认为是稳定的。为了解决诸如是否将一个聚类分0成更小的聚类,或者是否将有争议的聚类成员作为噪声丢弃之类的困惑,我们只需要计算和比较s(ci)值。
[0063]
在本发明实施例中,所述步骤三中,分析结束后,将核密度函数应用于空间流领域,进而应用于海量流数据处理领域。
[0064]
实施例二
[0065]
请参阅图1-11,一种扩展核密度空间分析的地理流方法,根据从芝加哥divvy共享单车2021年2月的轨迹数据共共49408条中随机选取100条流数据进行聚类分析,包括以下步骤:
[0066]
一、原始数据收集
[0067]
本方法,采用开放数据集,芝加哥divvy共享单车轨迹数据(2021年2月)。也可以适用于其他流数据。
[0068]
二、计算核密度函数
[0069]
进行对筛选的流数据利用公式
1.:计算流的距离矩阵;通过比较标准距离和中值距离得到搜索半径大小;筛选每条流在搜索半径内的所有流;根据流距离和搜索半径,将数据代入高斯核函数中计算得到核函数矩。
[0070]
三、计算核密度
[0071]
将核函数结果代入核密度公式
[2]
中
[0072][0073]
计算得到每条流的核密度;生成分层聚类树并利用公式[5]:
[0074][0075]
对流簇进行稳定度分析,提取得到稳定流簇。
[0076]
四、结果及评估
[0077]
通过处理得到的结果如图9和图10所示。对100条流的聚类用前述方法处理,仅有一个稳定的流聚类结果,命名为流簇c1,用红色粗线表示,聚类主要集中在流样本所经社区的中部地区,共24条流,经毗邻的3社区,可知在所筛选的数据里,这3社区ggxiandanche交流更为紧密,共享单车的出行更为频繁,交流更为紧密。
[0078]
工作原理:对原始地理流数据进行处理,对一组流中所有的单一“o-d”流,用核密度估计公式每个流的邻域r内的该流的核密度,选择距离公式,提取地理流距离矩阵。再选取搜索半径,计算出地理流邻域的搜索半径r,并计算搜索半径内的地理流之间的核函数矩阵。然后对每个地理流的核密度大小进行从大到小排序,并归一化核密度,对核密度和前面值差距较大的离群的流进行剔除,将其视为噪声;依次循环,直到最后合并完所有的流簇,生成分层聚类树。最后进一步对流簇稳定性进行分析,引入了称为聚类稳定性的特殊指标作为评价标准来判定聚类结果。
[0079]
对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本发明内。不应将权利要求中的任何附图标记视为限制所涉及的权利要求。
[0080]
此外,应当理解,虽然本说明书按照实施方式加以描述,但并非每个实施方式仅包含一个独立的技术方案,说明书的这种叙述方式仅仅是为清楚起见,本领域技术人员应当将说明书作为一个整体,各实施例中的技术方案也可以经适当组合,形成本领域技术人员
可以理解的其他实施方式。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1