用于食管光学相干层析图像生成的方法及系统
1.本发明涉及医学图像处理领域,特别涉及一种用于食管光学相干层析图像生成的方法及系统。
背景技术:
2.光学相干层析成像(optical coherence tomography,oct)是一种相对较新的无创成像方式。通过结合内窥镜探头,oct设备可以进入上消化道,并在显微镜下提供生物组织的高分辨图像。受益于此,内窥oct设备能够可视化食管病变引起的形态学变化,并用于食管疾病诊断。oct图像中的健康食管壁具有清晰可见的层状组织,而对于有病变的患者,则可能出现结构异常。因此,食管组织的自动分析在食管疾病的诊断中起着重要作用,近年来受到越来越多的关注。
3.近年来,深度学习已在医学成像领域得到广泛应用。在食管oct图像处理中,也有研究表明深度学习方法能够更好的分析数据,比如获得更精确的分割结果。充足的数据量是深度学习模型充分训练的必要条件,一般通过数据增强技术来实现。然而,传统的数据增强技术(例如,裁剪、旋转、弹性变形)所产生的数据彼此高度相关,难以真正保证数据的多样性。此外,这些方法都是在整个图像层面上进行处理,这导致增强图像丢失了输入的全局拓扑信息,从而导致所生成的样本包含不合理的特征。
4.数据扩充的另一种方式是采用具有特定结构的深度神经网络。其中,最具代表性的方法是变分自编码器(variational autoencoder,vae)(d.p.kingma and m.welling,“auto-encoding variational bayes,”in international conference on learning representations(iclr),2014.)以及生成对抗网络(generative adversarial networks,gan)(i.j.goodfellow,j.pouget-abadie,m.mirza,b.xu,d.warde-farley,s.ozair,a.courville,and y.bengio,“generative adversarial nets,”advances in neural information processing sys-tems 27(nips 2014),vol.27,pp.2672
–
2680,2014.)。这两种模型应用广泛,但依然具有一定的局限性。vae易于训练,但会产生缺乏细节的模糊图像。gan能够获得更高的图像质量,但在训练稳定性和模式崩溃方面面临挑战。针对gan所存在的问题,研究者提出了多种解决方案来应对这些挑战。一种常用的方法是从粗到精的生成策略,即从低分辨率图像生成开始,逐渐提高图像质量。代表性模型为pggan(t.karras,t.aila,s.laine,and j.lehtinen,“progressive growing of gans for improved quality,stability,and variation,”in international conference on learning representations(iclr),2018.)。然而,这种改进极大增加了计算负担。此外,还有研究提出了结合vae和gan的混合模型使网络容易训练且具备相对较高的图像生成能力。vaegan是混合模型的典型案例(a.b.l.larsen,s.k.and o.winther,“autoencoding beyond pixels using a learned similarity metric,”corr,vol.abs/1512.09300,2015.[online].available:http://arxiv.org/abs/1512.09300.),然而,混合模型通常包含编码器,解码器以及判别器三个网络,结构较为复杂,且所生成的图像质量常常不及gan。
[0005]
所以,现在需要一种更可靠的方案。
技术实现要素:
[0006]
本发明所要解决的技术问题在于针对上述现有技术中的不足,提供一种用于食管光学相干层析图像生成的方法及系统。
[0007]
为解决上述技术问题,本发明采用的技术方案是:一种用于食管光学相干层析图像生成的方法,包括以下步骤:
[0008]
1)采集食管oct图像并进行预处理,作为训练样本;
[0009]
2)构建对抗变分自编码网络模型v,该网络模型v包括编码器e和生成器g,其中编码器e同时承担判别和编码两种任务;
[0010]
3)利用步骤1)中得到的训练样本对步骤2)构建的抗变分自编码网络模型v进行训练,训练过程中,编码器e和生成器g的优化过程交替进行,收敛后,得到最终的对抗变分自编码网络模型v';
[0011]
4)利用训练后得到的抗变分自编码网络模型v'产生虚拟的食管oct图像。
[0012]
优选的是,所述步骤2)中的对抗变分自编码网络模型v中,采用l
like
项用于衡量网络的还原程度,采用l
prior
项用于衡量隐含向量与高斯分布的接近程度,采用l
gan
表示网络模型v的对抗损失;
[0013]
采用e1表示编码器的编码输出,e2表示编码器的判别输出;x表示输入的真实样本,xr表示生成器g通过编码向量z重构得到的生成数据,如公式(1)所示:
[0014][0015]
公式(1)的含义为:真实样本x通过编码器e后所输出的编码z服从分布q(z|x),隐藏向量z通过生成器g得到的重构样本xr服从分布p(x|z);
[0016]
采用z
p
表示从高斯分布采样得到的随机向量,z
p
维度与z一致,x
p
表示生成器g通过z
p
重构得到的采样样本;
[0017]
l
like
项的计算公式为:
[0018][0019]
l
prior
项的计算公式为:
[0020]
l
prior
=d
kl
(q(z∣x)||p(z))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3);
[0021]
其中,d
kl
为kl散度,p(z)=n(0,1)表示标准正态分布;
[0022]
l
gan
项的计算公式为:
[0023][0024]
其中,中,e表示期望,角标表示随机变量为x,该变量x服从样本数据的分布,即x采样自真实样本数据集;中,e表示期望,角标表示z为随机变量,z服从pz(z)分布,即采样自正态分布。
[0025]
优选的是,步骤3)中,对编码器e进行优化的损失函数le的计算公式为:
[0026][0027]
对生成器g进行优化的损失函数lg的计算公式为:
[0028][0029]
其中,为当前使用的生成器,为当前使用的编码器,λ1和λ2为权重参数。
[0030]
优选的是,步骤3)中,抗变分自编码网络模型v进行训练的步骤具体包括:
[0031]ⅰ、训练编码器e:
[0032]
ⅰ‑
1、保持生成器g参数固定,从训练样本中抽取样本组成真实样本x,这些样本通过编码器e得到隐藏向量z,根据样本数据x和隐藏向量z,结合公式(1)和公式(3)得到l
prior
项;
[0033]
ⅰ‑
2、隐藏向量z通过固定参数的生成器g生成重构样本xr,结合公式(2)计算出l
like
项以衡量x与xr的相似程度;
[0034]
ⅰ‑
3、z
p
表示从标准正态分布中采样得到与隐藏向量维度一致的向量,将z
p
输入到生成器g中,生成虚假样本x
p
;其中,编码器e同时承担判别器的任务,能够区分真实样本x、重构样本xr和虚假样本x
p
,通过公式(4)计算l
gan
项以衡量编码器e的判别能力;
[0035]
ⅰ‑
4、最后,按照公式(5)计算得到编码器的损失函数le,通过梯度下降法,最终完成编码器e的优化;
[0036]ⅱ、训练生成器g:
[0037]
ⅱ‑
1、保持编码器e参数固定,从训练样本中抽取样本组成真实样本x,通过编码器e得到隐藏向量z,根据样本数据x和隐藏向量z,结合公式(1)和公式(3)得到l
prior
项;
[0038]
ⅱ‑
2、隐藏向量z通过生成器g生成重构样本xr,结合公式(2)计算出l
like
项;
[0039]
ⅱ‑
3、z
p
表示从标准正态分布中采样得到与隐藏向量维度一致的向量,将z
p
输入到生成器g中,生成虚假样本x
p
;通过公式(4)计算l
gan
项以衡量编码器e的判别能力;
[0040]
ⅱ‑
4、最后,按照公式(6)计算得到编码器的损失函数lg,通过梯度下降法,最终完成生成器g的优化;
[0041]ⅲ、编码器e和生成器g的优化过程交替进行,收敛后,得到最终的对抗变分自编码网络模型v'。
[0042]
优选的是,食管oct图像预处理的方法为:
[0043]
先对采集的食管oct图像进行归一化:对于任意图像,将该图像任一像素的灰度值与该图像所有像素的灰度值的均值相减后再与该图像所有像素的灰度值标准差相除;
[0044]
然后设置图像输入尺寸,大于输入尺寸的图像降采样到输入尺寸,小于输入尺寸的图像填零至输入图像尺寸。
[0045]
本发明还提供一种用于食管光学相干层析图像生成的系统,其采用如上所述的方法生成虚拟的食管oct图像。
[0046]
本发明还提供一种存储介质,其上存储有计算机程序,该程序被执行时用于实现如上所述的方法。
[0047]
本发明还提供一种计算机设备,包括存储器、处理器以及存储在所述存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如上所述的方法。
[0048]
本发明的有益效果是:本发明提供的用于食管光学相干层析图像生成的方法及系统能够生成接近真实图像的虚拟食管oct图像,其中,编码器同时承担判别和编码两种任务,能简化网络结构,从而使得网络的训练更为高效;本发明能够得到优于pggan模型的食管oct图像生成结果。
附图说明
[0049]
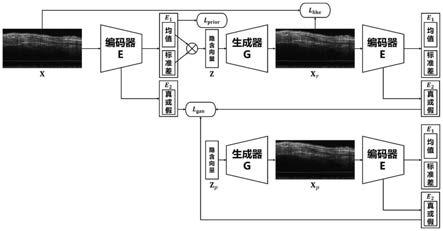
图1为本发明的对抗变分自编码网络模型v的结构示意图;
[0050]
图2为本发明的实施例3中的食管oct图像生成结果。
具体实施方式
[0051]
下面结合实施例对本发明做进一步的详细说明,以令本领域技术人员参照说明书文字能够据以实施。
[0052]
应当理解,本文所使用的诸如“具有”、“包含”以及“包括”术语并不排除一个或多个其它元件或其组合的存在或添加。
[0053]
实施例1
[0054]
本实施例的一种用于食管光学相干层析图像生成的方法,包括以下步骤:
[0055]
1)采集食管oct图像并进行预处理,作为训练样本。
[0056]
预处理方法为:先对采集的食管oct图像进行归一化:对于任意图像,将该图像任一像素的灰度值与该图像所有像素的灰度值的均值相减后再与该图像所有像素的灰度值标准差相除;
[0057]
然后设置图像输入尺寸,大于输入尺寸的图像降采样到输入尺寸,小于输入尺寸的图像填零至输入图像尺寸。
[0058]
2)构建对抗变分自编码网络模型v,该网络模型v包括编码器e和生成器g,其中编码器e同时承担判别和编码两种任务。
[0059]
本实施例中的对抗变分自编码网络模型v的网络结构如图1所示,其中,采用l
like
项用于衡量网络的还原程度,采用l
prior
项用于衡量隐含向量与高斯分布的接近程度,采用l
gan
表示网络模型v的对抗损失;
[0060]
采用e1表示编码器的编码输出,e2表示编码器的判别输出;x表示输入的真实样本,xr表示生成器g通过编码向量z重构得到的生成数据,如公式(1)所示:
[0061][0062]
公式(1)的含义为:真实样本x通过编码器e后所输出的编码z服从分布q(z|x),隐藏向量z通过生成器g得到的重构样本xr服从分布p(x|z);
[0063]
采用z
p
表示从高斯分布采样得到的随机向量,z
p
维度与z一致,x
p
表示生成器g通过z
p
重构得到的采样样本;
[0064]
l
like
项的计算公式为:
[0065][0066]
l
prior
项的计算公式为:
[0067]
l
prior
=d
kl
(q(z∣x)||p(z))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3);
[0068]
其中,d
kl
为kl散度,p(z)=n(0,1)表示标准正态分布;
[0069]
l
gan
项的计算公式为:
[0070][0071]
其中,中,e表示期望,角标表示随机变量为x,该变量x服从样本数据的分布,即x采样自真实样本数据集;中,e表示期望,角标表示z为随机变量,z服从pz(z)分布,即采样自正态分布。
[0072]
在一种优选的实施例中,编码器e和生成器g的结构如表1所示,编码器e包括输入图像层、若干下采样单元(每个下采样单元中包括若干卷积块和一个下采样层)、全局池化层(global average)以及最后的两个1
×
1卷积块(分别输出e1和e2),生成器g包括若干上采用单元,第一个上采用单元包括latent vector e1(e1为隐藏向量,即编码器e的输出结果,此为解码器g的输入)、卷积块、reshape函数、上采样层,最后一个上采用单元包括1
×
1卷积块,其余的上采用单元包括2个3
×
3卷积块和一个上采样层。
[0073]
编码器与解码器的网络深度可根据输入图像的分辨率进行调整,调整方法为通过改变下采样的次数使得网络将图像的尺寸的最小值降至2。
[0074]
表1编码器与解码器结构参数
[0075][0076]
3)利用步骤1)中得到的训练样本对步骤2)构建的抗变分自编码网络模型v进行训练,训练过程中,编码器e和生成器g的优化过程交替进行,收敛后,得到最终的对抗变分自编码网络模型v'。
[0077]
本发明提供的抗变分自编码网络模型v中,对于编码器e来说它的优化目标有三个:1)编码输出e1能够遵循先验高斯分布;2)编码输出e1重建误差低;3)判别输出e2能够区分真实数据和生成样本。对于生成器g的优化目标有两个:1)生成与真实数据分布更加相似的样本;2)具有小的重建误差。
[0078]
据此定义得到对编码器e进行优化的损失函数le的计算公式为:
[0079][0080]
对生成器g进行优化的损失函数lg的计算公式为:
[0081][0082]
其中,为当前使用的生成器,为当前使用的编码器,λ1和λ2为权重参数。训练过程中e网络与g网络以单独交替迭代优化的方式训练,直到模型收敛或达到指定迭代次数。
[0083]
其中,抗变分自编码网络模型v进行训练的步骤具体包括:
[0084]ⅰ、训练编码器e:
[0085]
ⅰ‑
1、保持生成器g参数固定,从训练样本中抽取样本组成真实样本x,这些样本通过编码器e得到隐藏向量z,根据样本数据x和隐藏向量z,结合公式(1)和公式(3)得到l
prior
项;
[0086]
ⅰ‑
2、隐藏向量z通过固定参数的生成器g生成重构样本xr,结合公式(2)计算出l
like
项以衡量x与xr的相似程度;
[0087]
ⅰ‑
3、z
p
表示从标准正态分布中采样得到与隐藏向量维度一致的向量,将z
p
输入到生成器g中,生成虚假样本x
p
;其中,编码器e同时承担判别器的任务,能够区分真实样本x、重构样本xr和虚假样本x
p
,编码器通过判别样本的编码的不同来区分不同样本,通过公式(4)计算l
gan
项以衡量编码器e的判别能力;
[0088]
ⅰ‑
4、最后,按照公式(5)计算得到编码器的损失函数le,通过梯度下降法,最终完成编码器e的优化;
[0089]ⅱ、训练生成器g:
[0090]
ⅱ‑
1、保持编码器e参数固定,从训练样本中抽取样本组成真实样本x,通过编码器e得到隐藏向量z,根据样本数据x和隐藏向量z,结合公式(1)和公式(3)得到l
prior
项;
[0091]
ⅱ‑
2、隐藏向量z通过生成器g生成重构样本xr,结合公式(2)计算出l
like
项;
[0092]
ⅱ‑
3、z
p
表示从标准正态分布中采样得到与隐藏向量维度一致的向量,将z
p
输入到生成器g中,生成虚假样本x
p
;通过公式(4)计算l
gan
项以衡量编码器e的判别能力;
[0093]
ⅱ‑
4、最后,按照公式(6)计算得到编码器的损失函数lg,通过梯度下降法,最终完成生成器g的优化;
[0094]ⅲ、编码器e和生成器g的优化过程交替进行,收敛后,得到最终的对抗变分自编码网络模型v'。
[0095]
4)应用时,可以对生成器g输入指定维度的任意隐藏向量z,利用训练后得到的抗变分自编码网络模型v'产生与训练样本类似且接近真实图像的虚拟的食管oct图像。
[0096]
本发明可用于食管oct图像生成,本发明的编码器同时承担判别和编码两种任务,能简化网络结构,从而使得网络的训练更为高效。
[0097]
实施例2
[0098]
本实施例提供一种用于食管光学相干层析图像生成的系统,其采用实施例1的方法生成虚拟的食管oct图像。
[0099]
本实施例还提供一种存储介质,其上存储有计算机程序,该程序被执行时用于实现实施例1的方法。
[0100]
本实施例还提供一种计算机设备,包括存储器、处理器以及存储在所述存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现实施例1的方法。
[0101]
实施例3
[0102]
本实施例中采用实施例1的方法进行了食管oct图像生成,并与常规技术中使用pggan模型生成的图像进行了对比,具体如下。
[0103]
本实施例中采集了9个健康小鼠个体的食管内窥oct图像组成了实验数据集。模型的训练数据集来自其中7个小鼠个体,共包含10500张小鼠的食管图像(每个个体贡献1500
张);模型的测试数据集来自另外2个小鼠个体,共包含1000张小鼠食管图像(每个个体贡献500张)。测试数据集用于评估模型的生成效果。图像尺寸为256
×
256,像素强度归一化为0-1。
[0104]
如图2所示,图2(a)为从测试数据集中选取的食管内窥oct图像,图2(b)为pggan的生成效果。可以看出,pggan的生成结果能够反映食管的基本结构和纹理,但所生成的图像依然存在伪影和噪声。相比之下,图2(c)为本发明的生成效果,可以看出,所生成的图像视觉上更接近真实图像。
[0105]
本实施例中使用的定量评估指标为:wasserstein距离(wd)、inception score(is)、mode score(ms)、fr
é
chet inception distance(fid)和maximum mean discrepancy(mmd)。其中,is,ms指标越大表示图像的生成质量越好,其余指标则相反。用pggan网络和本发明提出的网络各生成1000个样本,计算上述评价指标,结果如表2所示。其中,计算测试数据中的1000个样本的评价指标作为本实施例的金标准。可以看出,本发明提出的网络生成图像的评价指标均优于pggan,更接近与金标准。
[0106]
表2生成结果的数值评价指标
[0107][0108]
尽管本发明的实施方案已公开如上,但其并不仅仅限于说明书和实施方式中所列运用,它完全可以被适用于各种适合本发明的领域,对于熟悉本领域的人员而言,可容易地实现另外的修改,因此在不背离权利要求及等同范围所限定的一般概念下,本发明并不限于特定的细节。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1