一种基于样本包络多层聚类的数据集平衡化学习方法
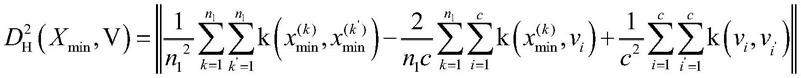
1.本发明涉及人工智能技术领域,尤其涉及一种基于样本包络多层聚类的数据集平衡化学习方法。
背景技术:
2.在数据挖掘和机器学习研究中,一个潜在的严峻挑战是如何处理“不平衡类别”。一类可能包含大量样本,而另一类可能只有少数样本。当遇到类的不平衡时,标准及其学习算法的整体分类精度会过于关注多数类,而降低了少数类样本的分类性能,分类器可能会将少数类中的一些数据点视为离群值,从而产生极高的误分类错误率。因此,数据挖掘任务中的主要关注类通常是少数(或罕见)类,有必要提高少数类实例的识别精度。
3.现有的非平衡过采样算法中,大多数算法旨在解决类间不平衡问题,而忽略了类内不平衡问题,但基于smote的过采样会导致产生噪声实例,因为它不能保证生成的实例分布更接近于原始实例分布。为了解决类内不平衡的问题,采用了聚类算法。在基于聚类的方法中,首先将数据集划分为几个较小的子群,然后在这些子群中使用抽样方法来维持类的平衡。聚类算法可以有效地解决类内不平衡的问题。
4.然而,值得注意的是,目前大多数基于聚类的过采样算法都是基于所有样本或单一类别的样本。这些方法涉及单层聚类,忽略了样本之间信息的多样性。使用这些方法很难探索更多的样本信息。相反,单层聚类严重依赖先验知识,这限制了它的应用,特别是对复杂的数据集。此外,现有机器学习方法仅针对原样本,并未考虑原样本聚类后的新样本,因此,有必要研究以原样本为基础的新样本重构方法。
技术实现要素:
5.本发明提供一种基于样本包络多层聚类的数据集平衡化学习方法,解决的技术问题在于:如何对不平衡样本进行样本重构,以解决少数类样本与多数类样本之间的类内不平衡问题。
6.为解决以上技术问题,本发明提供一种基于样本包络多层聚类的数据集平衡化学习方法,包括步骤:
7.s1、选择不平衡训练集,该不平衡训练集由少数类样本和多数类样本组成;
8.s2、对所述少数类样本和多数类样本通过相似性测度来计算最相似样本、合并原样本,构造对应的包络化少数类样本和包络化多数类样本;
9.s3、采用深度样本包络网络对所述包络化少数类样本进行深度样本变换,得到对应的l层包络化少数类深度样本,l≥1;
10.s4、将所述包络化少数类样本与每层所述包络化少数类深度样本进行融合,得到样本数目与所述包络化多数类样本平衡的包络化少数类平衡样本;
11.s5、将所述包络化少数类平衡样本与所述包络化多数类样本融合,得到平衡训练集。
12.与所述包络化多数类样本平衡的进一步地,所述步骤s3具体包括步骤:
13.s31、基于多层模糊均值聚类及最大平均差异的最小层间差异机制构建深度样本包络网络,所述深度样本包络网络的层数由聚类前后的样本数确定;
14.s32、采用所述深度样本包络网络对所述包络化少数类样本进行深度样本变换,得到每层网络空间的深度包络样本;
15.s33、在目标函数收敛后,将所有深度包络样本输出则得到所述包络化少数类深度样本。
16.进一步地,在所述步骤s31中,若聚类后样本数为聚类前样本数的1/t,则根据计算所述深度样本包络网络的最小层数l,l≥1,其中,n1、n2分别表示所述少数类样本、所述多数类样本的样本数目。
17.进一步地,在所述步骤s32中,进行深度样本变换采用公式:
[0018][0019]
其中,j1(u,v)表示目标函数,minj1(u,v)表示最小化目标函数,c表示聚类的数目,u
ik
表示所述少数类样本x
min
中第k个样本属于第i个簇的隶属程度,m>1表示模糊化系数;d
ik
表示样本与聚类中心vi的欧式距离,u代表所有的隶属程度u
ik
,v代表所有的聚类中心vi,表示x
min
与聚类中心v之间的最大平均差异。
[0020]
进一步地,表示为:
[0021][0022]
其中,表示第k'个少数类样本,v
i'
表示第i'个聚类中心,k(,)为线性核函数,
[0023]
进一步地,在所述步骤s33中,采用以下公式输出包络化少数类深度样本v={v1,v2,...vc}:
[0024][0025]
进一步地,在所述步骤s5后还包括步骤:
[0026]
s6、采用所述平衡训练集训练分类器,得到平衡的分类模型;
[0027]
s7、获取测试数据,并利用训练后的分类模型得到最终的预测结果。
[0028]
优选的,所述分类器采用支持向量机。
[0029]
优选的,所述不平衡训练集和所述测试数据选自keel公共数据库中的yeast1数据集或glass2数据集,每个样本包括多个特征,并且yeast1数据集与glass2数据集在少数类样本和多数类样本的不平衡度上有差异,所述预测结果为待测对象的标签。
[0030]
本发明提供的一种基于样本包络多层聚类的数据集平衡化学习方法,首先对少数类样本和多数类样本分别构建包络化少数类样本和包络化多数类样本,再基于多层模糊均值聚类及最大平均差异的最小层间差异机制,采用深度样本包络网络对不平衡的包络化少数类样本进行深度样本变换得到新的包络化少数类深度样本,并将包络化少数类深度样本与包络化少数样本进行融合,得到包络化少数类平衡样本,从而将少数类样本与多数类样本平衡,最后将包络化多数类样本与包络化少数类平衡样本融合得到平衡训练集进行训练和学习。本发明基于多层模糊均值聚类及最大平均差异的最小层间差异机制构建深度样本包络网络,使少数类样本与多数类样本数量相同,增加了少数类样本的多样性,提高了少数类样本的质量,从而有效增加了模型对少数类样本的学习能力,提升了其分类或预测的准确性。
附图说明
[0031]
图1是本发明实施例提供的一种基于样本包络多层聚类的数据集平衡化学习方法的流程图;
[0032]
图2是本发明实施例提供的对不平衡数据集进行包络化的流程图;
[0033]
图3是本发明实施例提供的深度样本包络网络模型的展示图;
[0034]
图4是本发明实施例提供的原样本(a)和包络化少数类深度样本(b)的对比示意
图;
[0035]
图5为本发明实施例提供的实验分类效果图。
具体实施方式
[0036]
下面结合附图具体阐明本发明的实施方式,实施例的给出仅仅是为了说明目的,并不能理解为对本发明的限定,包括附图仅供参考和说明使用,不构成对本发明专利保护范围的限制,因为在不脱离本发明精神和范围基础上,可以对本发明进行许多改变。
[0037]
为了对不平衡训练集能够进行平衡化学习,本发明实施例提供一种基于样本包络多层聚类的数据集平衡化学习方法,如图1的流程图所示,包括步骤:
[0038]
s1、选择不平衡训练集,该不平衡训练集由少数类样本和多数类样本组成;
[0039]
s2、对少数类样本和多数类样本通过相似性测度来计算最相似样本、合并原样本,构造对应的包络化少数类样本和包络化多数类样本;
[0040]
s3、采用深度样本包络网络对包络化少数类样本进行深度样本变换,得到对应的l层包络化少数类深度样本,l≥1;
[0041]
s4、将包络化少数类样本与每层包络化少数类深度样本进行融合,得到样本数目与包络化多数类样本平衡的包络化少数类平衡样本;
[0042]
s5、将包络化少数类平衡样本与包络化多数类样本融合,得到平衡训练集;
[0043]
s6、采用平衡训练集训练分类器,得到平衡的分类模型;
[0044]
s7、获取测试数据,并利用训练后的分类模型得到最终的预测结果。
[0045]
在步骤s1中,本实施例以不平衡样本分类为目的作详细介绍,选用来自keel数据库(https://sci2s.ugr.es/keel/category.php?cat=clas)的两个不平衡数据集,一个是yeast1数据,另一个是glass2数据。如表1所示,yeast1数据集样本数目为1484,其中包括1055个多数类样本,429个少数类样本,每个样本包括8个特征,不平衡度为2.46;glass2数据集样本数目为214,其中包括197个多数类样本,17个少数类样本,每个样本包括9个特征,不平衡度为11.59。
[0046]
表1数据集的基本信息
[0047]
数据集样本数特征数/样本少数类样本数多数类样本数不平衡度yeast11484842910552.46glass221491719711.59
[0048]
注:不平衡度=多数类样本数/少数类样本数
[0049]
在步骤s2中,如图2所示,原样本空间为离散的各个样本,通过样本拼接后,将最相似的几个样本拼接在一起成为一个包络样本,比如a样本的2个最近邻样本为b、c,则其包络样本为[a,b,c],比如b样本的2个最近邻样本为a、c,则其包络样本为[b,a,c],如此得到对应的包络化少数类样本和包络化多数类样本。
[0050]
进一步地,步骤s3具体包括步骤:
[0051]
s31、基于多层模糊均值聚类及最大平均差异的最小层间差异机制构建深度样本包络网络,深度样本包络网络的层数由聚类前后的样本数和不平衡度确定;
[0052]
s32、采用深度样本包络网络对包络化少数类样本进行深度样本变换,得到每层网络空间的深度包络样本;
[0053]
s33、在目标函数收敛后,将所有深度包络样本输出则得到包络化少数类深度样本。
[0054]
其中,在步骤s31中,若聚类后样本数为聚类前样本数的1/t,则根据计算深度样本包络网络的最小层数l,l≥1,其中,n1、n2分别表示少数类样本、多数类样本的样本数目。
[0055]
在步骤s32中,进行深度样本变换采用公式:
[0056][0057]
其中,j1(u,v)表示目标函数,minj1(u,v)表示最小化目标函数,c表示聚类的数目,u
ik
表示少数类样本x
min
中第k个样本属于第i个簇的隶属程度,m>1表示模糊化系数;d
ik
表示样本与聚类中心vi的欧式距离,u代表所有的隶属程度u
ik
,v代表所有的聚类中心vi,表示求x
min
与聚类中心v之间的最大平均差异。
[0058]
具体的,表示为:
[0059][0060]
其中,表示第k'个少数类样本,v
i'
表示第i'个聚类中心,k(,)为线性核函数,
[0061]
具体的,在步骤s33中,采用以下公式输出包络化少数类深度样本v={v1,v2,...vc}:
[0062]
[0063]
公式(1)结合了多层模糊均值聚类(mlfcm)和基于最大平均差异的最小层间差异机制(midmd)。深度神经网络可以通过多层转换提取高质量的特征。同样地,多层聚类可以用于多次迭代的采样。在聚类的时候,层间的多样性可以被平滑化,聚类数量的初始化设置变得不那么重要。因此,有必要考虑多层聚类。结合步骤s3的融合,得到与多数类样本平衡的少数类平衡样本。
[0064]
图3为深度样本包络网络的整体流程图,首先基于原样本构造包络样本,再通过式(3)建立样本之间的变换关系,使得聚类前后的样本分布一致,更有利于后续少数类样本的分类。图4为原样本和进行深度变换后的包络样本进行对比的示意图,除了上述包络样本构造方法,原样本还可以通过深度样本包络网络构造l层样本空间,第i个原样本对应这l-1个样本空间里的聚类中心,得到以该样本为中心的l个样本的包络集合(记为样本包络),从而将原样本转化为对应的包络样本。
[0065]
在本次试验中,每种类型的数据样本按7:3比例被随机均分为训练集、测试集10次,得到10组样本。计算机操作系统为windows 7,64位,8gb内存;实验平台是matlab,r2018b。为了便于后续分析和说明,本例将步骤s2、s3的样本变换算法,简称为mlfc&idmd&il,传统的过采样算法简称为smote。本发明提出的方法可以结合不同的分类模型,特征选择算法,实例优化算法,评估标准,从而转化为其他各种具体的算法。本实施例采用支持向量分类器,并且使用线性核函数和默认参数。采用准确率acc、f1值(f-m)、auc和g-mean(g-m)值来评价预测算法的性能,具体为:
[0066][0067][0068][0069][0070]
tp(真阳性)是正确预测的阳性(少数类)实例数;tn(真阴性)是正确预测的阴性(多数类)实例数;fp(假阳性)是错误预测为阳性的阴性实例数;fn(假阴性)是错误预测为阴性的阳性实例数。
[0071]
实验结果如表2所示,结果为10组测试集的平均值以及标准差。
[0072]
表2两个数据集分类结果对比
[0073][0074]
从表2可以看出,对于两个数据集,采用本发明所提方法比传统方法在4个指标上的效果都要好,说明本方法生成的新样本更有利于分类。
[0075]
图5显示的是表2的柱状图。它主要显示了本方法在acc、auc、f-m、g-m得到的分类结果。从图5可以看出,两个数据集通过本方法得到的acc、auc、f-m、g-m的值更高,说明深度样本包络网络mlfc&idmd生成的新样本质量更好。
[0076]
综上,本发明实施例提供的一种基于样本包络多层聚类的数据集平衡化学习方法,首先对少数类样本和多数类样本分别构建包络化少数类样本和包络化多数类样本,再基于多层模糊均值聚类及最大平均差异的最小层间差异机制,采用深度样本包络网络对不平衡的包络化少数类样本进行深度样本变换得到新的包络化少数类深度样本,并将包络化少数类深度样本与包络化少数样本进行融合,得到包络化少数类平衡样本,从而将少数类样本与多数类样本平衡,最后将包络化多数类样本与包络化少数类平衡样本融合得到平衡训练集进行训练和学习。本发明实施例基于多层模糊均值聚类及最大平均差异的最小层间差异机制构建深度样本包络网络,使少数类样本与多数类样本数量相同,增加了少数类样本的多样性,提高了少数类样本的质量,从而有效增加了模型对少数类样本的学习能力,提升了其分类或预测的准确性。
[0077]
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1