一种用电负荷实时在线监测与识别方法与流程
1.本发明涉及电力信息采集领域,尤其涉及一种用电负荷实时在线监测与识别方法。
背景技术:
2.随着“碳达峰、碳中和”战略的提出,绿色低碳、节能减排将成为常态和主流,其中居民用电负荷的优化管理具有较大的节能减排潜能。
3.通过负荷监测技术获取家用电器负荷的相关细节信息,既有利于电力公司优化电网的运行和管理,又有利于居民用户高效管理用电设备,从而为节能减排提供有力支撑。依据监测方法,目前负荷监测技术主要包括非侵入式(non-intrusive load monitoring,nilm)和侵入式负荷监测(intrusive load monitoring,ilm)两类。传统的负荷监测一般通过在用户的电器设备上安装传感器来记录使用情况,属于侵入式,这种方式需要在电器设备上增加模块,经济成本高且不利于推广应用。相比较而言,非侵入式负荷监测不增加边际成本,一般通过在智能电表处安装监测装置,从而获得整个家庭的能耗数据,并运用事件检测、模式识别等方法准确识别出家庭各用电设备的运行状态。这种方法可操作性好、实施成本低、用户接受度高,容易推广,前景广阔。
4.目前,要想满足实时地负荷在线识别,我们需要一个可以实时处理数据的在线识别系统,该系统需要实时接收数据并存储数据,同时实时在显示区展示波形、实时计算特征、加载模型进行实时电器类别判定。因此需要多线程来实现上述功能,以保证系统不卡顿,满足实时要求,完成实时在线监测和识别任务。
5.相对于传统的单一学习算法,集成学习方法优势更强,目前已形成了boosting、bagging、stacking和voting等方法。其中voting方法是分类问题中常用的一种集成方法,包括绝对多数投票法、相对多数投票法和加权投票法等。该方法有效综合多种基分类器的预测结果,分类识别效果突出。但在研究使用几种较弱的异质基分类器构建一个准确率高且泛化能力强的强学习器的实验过程中,发现voting算法的应用中会出现以下几个问题:
6.(1)相对多数投票法仅需要获取票数最多的选项作为最终结果,但是当多数基分类器预测错误时,集成模型预测结果也是错误的,从而导致集成后的识别准确率低。
7.(2)针对不同场景,各类基分类器的预测准确率不同,也就是基分类器预测结果存在差异性。因此,选择不同的基分类器去投票,得到的投票结果也不一致,有时选择的基分类器组合投票结果甚至不如单一学习器。集成方法中如何选择基分类器是亟待解决的问题。
8.(3)加权投票法是对各个基分类器配置不同的权重,当赋予适合的权重时,加权投票法得到的结果可以优于基分类器,同时得到的结果也优于相对多数投票法。
9.因此需要对现有技术进行改进。
技术实现要素:
10.本发明所要解决的技术问题是:提供一种用电负荷实时在线监测与识别方法。
11.为解决上述技术问题,本发明所采用的技术方案是:
12.一种用电负荷实时在线监测与识别方法,包括如下步骤:
13.s1,使用主线程接收智能电表发送来的原始信号,并根据协议解析得到原始数据;
14.s2,子线程1存储所述原始数据;
15.s3,子线程2将原始数据经显示装置进行实时展示;
16.s4,主线程对原始数据中每个周期的电压和电流数据进行分析,提取特征数据;
17.s5,子线程3存储所述特征数据,实时地将所述特征数据保存到本地;
18.s6,子线程4调用显示函数初始化待显示电器的波形图,所述波形图显示电器的用电特征数据;
19.s7,线程5读取实时特征数据并将特征数据传送给线程4中的显示函数中,更新显示中的特征数据;
20.s8,线程4使用事件检测算法检测事件,根据线程5中的实时特征数据来检测是否有事件发生;所谓事件是指在设定的检测周期内,特征数据的变化值高于设定的变化阈值;
21.s9,当有事件发生时,使用子线程6加载训练好的香农熵加权投票算法模型;
22.s10,子线程6读取实时特征数据,并输入到所述香农熵加权投票算法模型中,实现用电电器类别及工作状态的在线识别。
23.与现有技术相比,本发明具有如下技术效果:
24.通过多线程运行,以保证系统不卡顿,满足实时要求,完成实时在线监测和识别任务。利用香农熵加权投票算法模型实现电器类别和工作状态的在线识别。
25.在上述技术方案的基础上,本发明还可以做如下改进。
26.优选地,步骤s2中所述显示装置以文本格式对原始数据进行展示。
27.优选地,步骤s6中所述的波形包括电压波形、电流波形、有功功率波形、无功功率波形、v-i轨迹和谐波幅值;
28.优选地,步骤s4中所述特征数据包括有功功率(p)、无功功率(q)、视在功率(s)、功率因数(λ)、(2g-1)次谐波,其中g为正整数,如1次谐波(har1)、3次谐波(har3)、
…
、63次谐波(har63);
29.优选地,步骤s5中,所述香农熵加权投票算法模型的训练过程如下,
30.a1、
31.将特征数据保存到本地后形成特征数据库,主线程对包括线性判别分析算法(linear discriminant analysis,lda)、朴素贝叶斯分类算法(naive bayes classifier,nb)、k最近邻算法(k-nearest neighbor,knn)、决策树分类算法(decision tree classifier,dt)、支持向量机(support vector machine,svm)、逻辑回归算法(logistic regression,lr)、反馈神经网络(back-propagation neural network,bpnn)七种基础分类算法使用递归特征消除(recursive feature elimination,rfe),从而选择出各算法的有效特征数据,并基于有效特征数据训练前述七种算法,得到各算法的训练后基础算法模型,后续称基分类器,并将7种基分类器从0到6编号。
32.a2、
33.对7种基分类器进行组合,得到120种不同的算法模型组合,使用公式(1)计算各种组合的多样性ent,
[0034][0035]
式(1)中ent为多样性,m为某个算法模型组合里的基分类器的数量,每个算法模型组合对应一个ent,xk是特征数据集x中的第k个样本,k为特征数据集x中总的样本数量,z(xk)是指一个包含m个基分类器的组合中,对于样本xk,能获得正确分类的基分类器个数。
[0036]
a3、
[0037]
利用多样性的最大值、最小值,根据公式(3)计算多样性的最佳范围ent
*
[0038][0039]
式(3)中,σ为ent
*
的半个区间范围,为经验设定值,一般取0-1之间;
[0040]
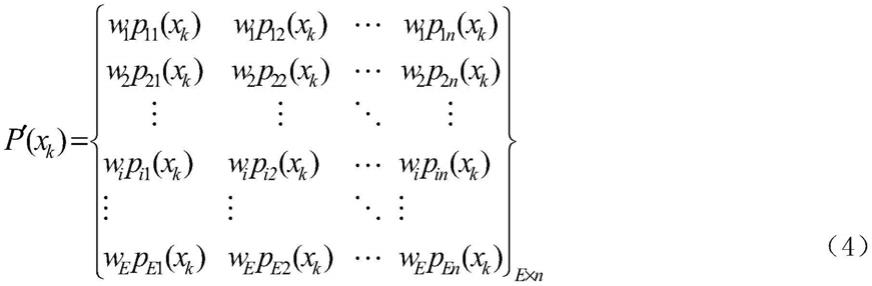
对于选择e种基分类器,针对n种分类类别的情况,根据公式(4)对预测分类概率进行加权融合
[0041][0042]
式(4)中p
en
(xk)代表了对于特征数据样本xk,第e个分类器预测是第n类的后验概率。wi是第i个基分类器对样本xk的融合权重;
[0043][0044]
式(5)中,
[0045]hi
(xk)代表基于特征数据样本xk计算的第i个分类器对所有分类类别的香农熵;
[0046][0047]
j代表分类类别,i是基分类器的序号。
[0048]
a4、
[0049]
对公式(6)计算的所有结果进行相加,实现类别的后验概率加权融合,得到p
″
(xk),如公式(7)所示
[0050][0051]
其为基于一个算法模型组合中,基于数据xk被判定为每个类别的概率。
[0052]
a5、
[0053]
如公式(8)所示,p
″
(xk)中数值最大的元素的列索引就是对样本xk的预测类别class(xk),
[0054]
class(xk)=argmax(p
″
(xk))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(8)
[0055]
arg表示求解数据列表中,数值最大的元素对应的序列。由此得到所有训练样本的预测结果。
[0056]
a6:
[0057]
基于所有训练样本的预测结果和真实结果,求各个算法模型组合的预测准确率acc
se
[0058][0059]
tp
se
、tn
se
、fn
se
、fp
se
表示的是第se个组合对训练样本的预测结果与真实结果不同关系的个数:tp
se
真正,表示真实结果为正类的样本被预测为正类的个数;tn
se
真负,表示真实结果为负类的样本被预测为负类的个数;fp
se
为假正,表示真实结果为负类的样本被预测为正类的个数;fn
se
为假负,表示真实结果为正类的样本被预测为负类的个数;c1是对选定的e个基分类器进行组合得到的算法模型组合的数量。
[0060]
a7:对属于ent
*
范围内的算法模型组合,找到数值最大并且在ent
*
内最靠近中间位置的acc
se
对应的算法模型组合,此算法模型组合即为最佳学习器组合,记为com。此最佳学习器组合com即为训练好的香农熵加权投票算法模型。
[0061]
进一步地,所述递归特征消除法,使用一个基模型来进行多轮训练,每轮训练后消除若干权值系数的特征,再基于新的特征集进行下一轮训练,同时每一轮训练都对训练集使用10折交叉验证,得到当前特征组合的验证准确率。训练结束后,找到对最终预测结果影响最大的特征数据组合。通过上述过程筛选出对于本基础分类算法来说最重要的特征数据,有助于提高此基础分类算法预测结果的准确度。
[0062]
进一步地,计算有功功率(p)、无功功率(q)、视在功率(s)、功率因数(λ)、1次谐波(har1)、3次谐波(har3)、
…
、63次谐波(har63)的方法如下:
[0063]
首先计算电压有效值,计算方式见公式(9)。
[0064][0065]
式中,n为计算周期内数据点的数量,ud为单个数据点中电压值;
[0066]
电流有效值计算方式见公式(10)。
[0067][0068]
式中id为单个数据点中电流值
[0069]
有功功率p等于数据段内n个测试点的平均功率,见公式(11)。
[0070][0071]
视在功率s等于电压有效值u
rms
和电流有效值i
rms
的乘积,如公式(13)所示。
[0072]
s=u
rms
×irms
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(13)无功功率q的计算方法见公式(12)。
[0073][0074]
功率因数通常用λ表示,是交流电路有功功率p对视在功率s的比值,见公式(14)。
[0075]
λ=p/s
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(14)对采集到的电流数据通过式(15)结合快速傅里叶变换算法作变换计算得到2n+1次谐波,其中n为整数,本发明选择了基波、3次谐波、5次谐波、
…
、63次谐波等共32种奇数次谐波作为特征,分别记为har1、har3、har5、
…
、har63,分别对应谐波频率为50hz、150hz、250hz、
…
、3.15khz。
[0076][0077]
式(15)中ω=2π/t为周期函数的角频率,t为电压的周期,对应中国国内的家用交流电为0.02秒,此处的ω为50hz,h为谐波次数。a0为信号中的直流系数,ah,bh为信号中的交流系数,通过傅里叶变换计算得出。
[0078]
进一步地,对于自测数据集得到的最佳模型组合包括lda、nb、dt、lr四种基分类器。
[0079]
进一步地,对于whited(是全球家庭和行业瞬态数据集,其采样频率为44.1khz,数据集包含130余种电气的电流和电压数据)得到的最佳模型组合包括knn、dt、lr、bpnn四种基分类器。
[0080]
采用上述进一步方案的有益效果是通过最优模型组合,然后将组合中最优的模型后保存到本地以便系统使用过程中随时调用。把实时的特征数据输入到保存好的模型中,实时产生预测结果
附图说明
[0081]
图1是本发明的流程框架图。
[0082]
图2是利用实测数据集时不同算法特征数量和验证集准确率的关系。
[0083]
图3是利用whited数据集时不同算法特征数量和验证集准确率的关系。
[0084]
图4是最佳学习器组合com的寻找流程图。
[0085]
图5是利用实测数据集时的平均准确率和多样性的关系。
[0086]
图6是图5的局部放大图;
[0087]
图7是利用whited数据集的平均准确率和多样性关系。
[0088]
图8是图7的局部放大图;
[0089]
图9是nilm框架图。
[0090]
图10是事件发生前后特征数据示意图。
[0091]
图11是lda、nb、dt、lr和本文算法对实测数据集的测试准确率。
[0092]
图12是knn、dt、lr、bpnn和本文算法对whited数据集的测试准确率。
[0093]
图13是自测数据集的测试集混淆矩阵。
[0094]
图14是电吹风的实时检测结果。
具体实施方式
[0095]
以下结合附图对本发明的原理和特征进行描述,所举实例只用于解释本发明,并非用于限定本发明的范围。
[0096]
实施例1:
[0097]
一种基于多线程的非侵入式负荷数据实时处理与识别方法,通过采集实时的电器用电数据,对电器类型及其运行状态进行实时在线监测与识别,包括以下步骤。
[0098]
步骤s1,使用主线程串口接收智能电表发送的原始信号,并根据协议解析得到原始数据。
[0099]
步骤s2,使用子线程1存储原始数据。
[0100]
步骤s3,使用子线程2实时展示原始数据到显示装置的显示区,该显示区以文本格式对原始数据进行展示。
[0101]
步骤s4,主线程对原始数据中每个周期电压和电流数据进行分析,提取特征,得到特征数据。
[0102]
步骤s5,使用子线程3存储特征数据,实时地将特征数据保存到本地。
[0103]
步骤s6,使用子线程4调用实时显示函数将待显示电器的波形图进行初始化,该波形包括电压波形、电流波形、有功功率波形、无功功率波形、v-i轨迹和谐波幅值;
[0104]
步骤s7,使用线程5的信号函数将特征数据发送到步骤s6中实时显示函数中,以此来更新显示的特征数据,并以波形形式呈现。
[0105]
步骤s8,子线程4使用事件检测算法检测事件,根据步骤s7呈现出来的实时特征数据来检测是否有事件发生,所述事件是指在设定的检测周期内,特征数据的变化率高于设定的变化阈值;此处用到的特征数据可以是电流数据,也可以是有功功率、无功功率等。
[0106]
步骤s9,使用子线程6来加载训练好的香农熵加权投票算法模型,读取实时特征,并将其输入到所述香农熵加权投票算法模型中,实现用电器类型及工作状态的在线识别。
[0107]
步骤s4中所述特征提取,本发明提取了有功功率(p)、无功功率(q)、视在功率(s)、功率因数(λ)、1次谐波(har1)、3次谐波(har3)、
…
、63次谐波(har63),总共5种类型的36个特征。
[0108]
进一步地负荷特征分为稳态特征和暂态特征,其中稳态特征是负荷处于稳定运行状态下的电气量,暂态特征是暂态过程中的电气量,暂态特征可单独或作为稳态特征的补充特征用以进行非侵入式负荷辨识。
[0109]
表2展示了常见的特征数据,以及各自优缺点。
[0110]
表2常见特征类型
[0111][0112]
计算有功功率(p)、无功功率(q)、视在功率(s)、功率因数(λ)、1次谐波(har1)、3次谐波(har3)、
…
、63次谐波(har63)。
[0113]
首先计算电压有效值,计算方式见公式(9)。
[0114][0115]
电流有效值计算方式见公式(10)。
[0116][0117]
有功功率p等于数据段内n个测试点的平均功率,见公式(11)。
[0118][0119]
无功功率q和有功功率p的平方和是视在功率s的平方,计算方法见公式(12)。
[0120][0121]
视在功率s等于电压有效值u
rms
和电流有效值i
rms
的乘积,如公式(13)所示。
[0122]
s=u
rms
×irms (13)
[0123]
功率因数通常用λ表示,是交流电路有功功率p对视在功率s的比值,见公式(14)。
[0124]
λ=p/s (14)
[0125]
对采集到的电流数据通过式(15)结合快速傅里叶变换算法作变换,本例中选择了基波、3次谐波、5次谐波、
…
、63次谐波等共32种奇数次谐波作为特征,分别记为har1、har3、har5、
…
、har63,分别对应谐波频率为50hz、150hz、250hz、
…
、3.15khz。
[0126][0127]
式(15)中ω=2π/t为周期函数的角频率,此处的ω为50hz,t为周期,此处为0.02秒,h为谐波次数,a0直流系数,ah、bh交流系数,通过傅里叶变换计算得出。
[0128]
为了得到步骤s8所述训练好的香农熵加权投票算法模型,包括以下步骤:
[0129]
步骤a1:特征数据保存到本地形成特征数据库,对包括线性判别分析算法lda、朴素贝叶斯分类算法nb、k最近邻算法knn、决策树分类算法dt、支持向量机svm、逻辑回归算法lr、反馈神经网络bpnn七种算法使用递归特征消除,利用递归特征消除法,从而选择出各算法的有效特征,并基于有效特征训练七种算法,得到训练后的各算法模型,记为基分类器,并将7种基分类器从0到6编号。
[0130]
所述递归特征消除法(recursive feature elimination,rfe),使用一个基模型来进行多轮训练,每轮训练后消除若干权值系数的特征,再基于新的特征集进行下一轮训练,同时每一轮训练都对训练集使用10折交叉验证,得到当前特征组合的验证准确率。训练结束后,找到对最终预测结果影响最大的特征数据组合。
[0131]
图2展示了实测数据集不同特征数量的算法对验证集准确度的影响;
[0132]
图3展示了whited数据集不同特征数量的算法对验证集准确度的影响。
[0133]
通过特征优化能够筛选出最重要的特征,有助于提高预测结果准确度。
[0134]
对上述七种基分类器进行组合,得到120种不同的算法模型组合。
[0135]
步骤a2:对上述得到的120种算法模型组合,使用公式(1)计算多样性;
[0136][0137]
步骤a3:通过公式(2)计算平均准确率。
[0138][0139]
为了衡量平均准确率中的acci,各基模型利用各自的最佳特征组合训练模型,通过公式(16)计算测试集经基分类器预测的准确率。
[0140][0141]
其中真正(true positive,tp)表示的是携带正类标签的数据被预测为正类的个数,真负(true negative,tn)表示携带负类标签的数据被预测为负类的个数,假正(false positive,fp)表示携带负类标签的数据被预测为正类的个数,假负(false negative,fn)表示携带正类标签的数据被预测为负类的个数。
[0142]
步骤a4:利用多样性的最大值、最小值、中点根据公式(3)计算多样性的最佳范围ent
*
。
[0143][0144]
步骤a5:根据公式(4)对预测分类概率进行加权融合。
[0145]
所述香农熵加权投票算法是对于n种类别的分类问题,采用e种分类器进行加权融合,公式(4)中xk是特征数据集x中的一个样本,p
en
(xk)代表了第e分类器预测xk是第n类的后验概率。wi是第i个分类器对样本xk的融合权重,wi根据公式(5)计算,公式(5)中的hi(xk)代表第i个分类器对所有分类类别的香农熵,hi(xk)按照公式(6)进行计算。
[0146][0147][0148][0149]
步骤a6:对公式(4)中的各列相加,实现类别的后验概率加权融合,得到p
″
(xk),如公式(7)所示,p
″
(xk)中最大的列索引就是对样本xk的预测类别,如公式(8)所示。
[0150][0151]
class(xk)=argmax(p
″
(xk))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(8)
[0152]
对属于ent
*
范围内的组合,计算香农熵加权投票的准确率,记为acc
se
。找到最大acc
se
并且ent
*
内越靠近中间位置的组合,此时的组合为最佳学习器组合,记为com,即为香农熵加权投票算法模型。
[0153]
最佳学习器组合com的寻找流程见图4,通过计算的多样性并确定多样性的最佳范围,找到最佳范围内的组合,假设包含c1种。计算这c1种学习器组合的香农熵加权投票准确率,并结合最佳范围内,找到靠近中间位置且香农熵加权投票准确率最大的组合com。
[0154]
对于本例中采用的实测数据集,见图5,其多样性ent
max
和ent
min
分别是0.495和0.0078。查看范围ent
*
的中点为0.2514,设置范围增量σ为0.033。实测数据集的最佳学习器组合[0,1,3,5],其中0、1、3、5分别代表的是lda、nb、dt、lr。
[0155]
当数据集采用whited数据集时,见图6,其多样性ent
max
和ent
min
分别是0.0473和0.0013,多样性查看范围ent
*
的中点为0.0243,范围增量σ设置为0.003。whited数据集的最佳组合为[2,3,5,6],代表knn、dt、lr、bpnn四种基分类器。
[0156]
本发明对于自测数据集得到的最佳模型组合包括lda、nb、dt、lr四种基分类器,对于whited得到的最佳模型组合包括knn、dt、lr、bpnn四种基分类器。基分类器在两个数据集上提取的特征及特征数量采用的最佳特征见表1。
[0157]
表1基分类器在两个数据集上提取的特征及特征数量
[0158][0159]
可见,采用不同的数据集,则得到的分类算法最佳组合com是不同的,但是利用本方法必然可以得到对应的最佳组合。
[0160]
实施例2:
[0161]
本例使用图7所示非侵入式负荷监测(nilm)框架获取原始数据,使用自测数据集和whited公共数据集测试本发明算法的鲁棒性。
[0162]
在nilm框架中,智能电表工频为50hz,采样频率为6.4khz,因此每0.02秒即可获得一个周期数据,每个周期包含128个电流数据点和电压数据点,根据采样频率可以把数据分为高频数据和低频数据。低频数据是频率低于1hz的数据,高频数据是高于1hz的数据,因此本例采用的数据是高频数据。
[0163]
根据图1所示多线程框架,本方法采用多线程处理,包括主线程和六个子线程。启动多线程时,使用信号函数和槽函数发送和处理数据。主线程通过串口接收仪表的原始信号数据解析得到原始数据,并启动子线程1将原始数据实时保存在本地。
[0164]
同时,子线程2被启动,将原始数据显示到显示装置的文本框中。原始数据被传递给协议解析模块,然后解析出的电压和电流被传递给特征提取模块,得到特征数据。
[0165]
同时,启动子线程3,将获得的实时特征数据保存在本地,以记录设备运行时的特征。
[0166]
同时在主线程运行时,子线程4被启动,用于显示图像,
[0167]
子线程5用于实时抓取最新的特征数据并将其发送到子线程4的实时可视化数据进行显示。
[0168]
通过这种方式,实时更新的特征数据经显示装置进行实时展现。在线程4对数据的处理任务中,第一步是检测事件,第二步是启动线程6并通过信号6发送最新特征数据。
[0169]
线程6加载训练好的算法并结合接收到的最新特征数据实现用电设备的在线识别功能。
[0170]
所述事件检测算法,本发明采用的算法是双边累加和算法(two-sided cumulative sum,cusum),算法原理,见图8。w1窗口用来计算采样序列均值μ0;w2窗口是判断是否有事件发生的依据。当w2内f
k+
逐渐累加,超过一定阈值h,便认为存在负荷事件。若未检测到负荷事件,则w2内的f
k+
值变化不大,此时w1和w2窗口向右滑动到新的采样点,继续进行检测。
[0171]
如公式(16)所示,该算法抗噪声干扰强,准确率高,通过该算法可准确的识别稳态事件。
[0172][0173]
其中xk表示当前采用序列,μ0为序列的平均值,通常是已知或者可估计的;θ是随机噪声。序列处于稳态时,统计量f
k+
和f
k-在0值附近随机波动。
[0174]
本例中采集了表3中的真实电器以及其组合类型的真实数据和whited数据集,并且在whited数据集数据下验证本发明方法的效果。
[0175]
对whited中30个具有稳态电流波形的电器进行分类识别,通过对比基于决策树的adaboost算法、随机森林算法和基于多层感知器(mlp)的stacking算法,最终验证本发明所提方法的鲁棒性。
[0176]
对于实测数据集,检测系统解析好数据后,单个周期会获得128个数据点,保存数据后,本发明获得38种电器类型,见表3。
[0177]
表3实际测试的电器及其混合情况类别
[0178]
[0179][0180]
每一种电器均经过10秒的采样获得500个周期的电压和电流波形数据,每个周期包含128个采样点。对表1中的每个编号的样本采集20次并将20次的稳态期间电压和电流数据取平均以降低噪声。如此重复测量,获得上述38种电器组合的共38
×
500
×
128的电流数据以及同样大小的电压数据用于训练,其中每个周期的数据作为一个训练样本。
[0181]
另外额外采集1秒的数据用于测试,保证测试数据对于训练数据来说是新鲜的,也就是测试集包含38
×
50
×
128的电流数据和同样大小的电压数据。
[0182]
接下来进行特征提取,本发明共采集36个特征,接下来进行详细叙述。
[0183]
根据公式(11)计算有功功率作为第33个特征。
[0184]
根据公式(12)计算无功功率作为第34个特征。
[0185]
根据公式(13)计算视在功率s=u
rms
×irms
,作为第35个特征。
[0186]
根据公式(14)计算功率因数λ=p/s,作为第36个特征。
[0187]
根据公式(15)计算各个奇数次谐波幅值,总共有32次谐波,作为第1到32个特征。
[0188]
本发明对获取到的每周期的电流和电压波形提取了视在功率、有功功率、无功功率、功率因数和信号的32个谐波作为特征,将原始数据训练集转换为38
×
500
×
36的向量,每种测试编号的电器包含500个样本,每个样本包含36个特征。同理,测试集转换成38
×
50
×
36的向量,每种编号的电器包含50个样本。
[0189]
所有数据分析使用戴尔inspiron7591电脑计算,i5-9300hcpu,主频2.40ghz。采用python3.7作为编程环境。
[0190]
公共数据集whited,依然采用50hz工频,其采样频率是44.1khz,每个周期包含882个数据点。采用上述原理,得到whited中30个具有稳态电流波形的电器数据,并经过特征转换。其中谐波特征选取了前32种奇数次谐波,从而得到30
×
500
×
36的训练集向量。同理,得到30
×
50
×
36的测试集向量。
[0191]
当特征保存到本地形成特征数据库后,本发明对包括线性判别分析算法lda、朴素贝叶斯分类算法nb、k最近邻算法knn、决策树分类算法dt、支持向量机svm、逻辑回归算法lr、反馈神经网络bpnn七种算法使用递归特征消除,递归特征消除法rfe,从而选择出针对各算法的最有效的特征数据,并基于有效特征分别训练七种算法,得到训练后的算法模型,获得编号0-6的7个基分类器。
[0192]
即基分类器:lda 0、nb 1、knn 2、svm 3、dt 4、lr 5、bpnn 6七种基分类器,各基分类器通过调用scikit-learn库实现。
[0193]
其中lda模型,参数默认。
[0194]
其中nb模型,参数默认。
[0195]
knn算法是一种近邻算法,是分类算法中最简单的方法之一,采用线性扫描方式,k值设置为5,树的叶子节点数量阈值设置为30。
[0196]
svm算法采用线性核函数,惩罚值代表对分错样本的惩罚程度,设置为1.0。
[0197]
dt算法是一种树形结构,采用gini作为特征选择准则,树的深度为150,并使用best作为划分准则,来寻找最优划分点。
[0198]
其中lr模型,参数默认。
[0199]
bpnn模型包括一个输入层,两个隐藏层和一个输出层。对于实测数据集,输入层设置36个节点,两个隐藏层都设置80个节点,输出层设置的38个节点代表投入使用的38种电器类别,采用relu作为激活函数,学习率为0.03,迭代320次,采用adam优化损失。对于whited数据集,输入层和隐藏层不变,输出层设置为30,代表whited数据集中选择的30个电器种类。
[0200]
对上述七种模型相互组合,得到从两两组合到七七组合的120种不同的模型组合。
[0201]
使用非经典熵公式(1)计算多样性,
[0202][0203]
m为某个算法模型组合里的基分类器的数量,k为特征数据集x中样本的总量;z
(xk)代表算法模型组合中,对于特征数据样本xk,预测结果与真实结果保持一致的基学习器的个数;
[0204]
通过平均准确率公式(2)计算平均准确率
[0205][0206]
m为某个算法模型组合里的基分类器的数量;
[0207]
为了衡量平均准确率中的acci,各基模型利用各自的最佳特征组合训练模型,通过公式(16)计算测试集准确率。
[0208][0209]
利用多样性的最大值ent
max
、最小值ent
min
,根据公式(3)
[0210][0211]
计算多样性的最佳范围ent
*
。
[0212]
所述香农熵加权投票算法是对于n种类别的分类问题,采用e种分类器进行加权融合,如公式(4)所示
[0213][0214]
其中xk是数据集x中一个样本,p
en
(xk)代表了第e分类器预测是第n类的后验概率。其中wi是第i个分类器对样本xk的融合权重,根据公式(5)所示
[0215]
其中对样本xk,hi(xk)的计算方法如公式(6)所示,其代表第i个分类器对所有类别的香农熵,j表示第j个分类类别。
[0216][0217]
对公式(4)的各列相加,实现类别的后验概率加权融合,得到p
″
(xk),如公式(7)所示,
[0218][0219]
p
″
(xk)中最大的列索引就是对样本xk的预测类别,如公式(8)所示
[0220]
class(xk)=argmax(p
″
(xk))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(8)。
[0221]
最佳学习器组合com的寻找流程见图4,对属于ent
*
范围内的组合,计算香农熵加权投票的准确率,记为acc
se
。找到最大acc
se
并且ent
*
内越靠近中间位置的组合,此时的组合为最佳学习器组合,记为com,具体算法见算法1。
[0222]
[0223][0224]
对于实测数据集,见图5,其多样性ent
max
和ent
min
分别是0.495和0.0078。查看范围ent
*
的中点为0.2514,设置范围增量σ为0.033。实测数据集的最佳学习器组合[0,1,3,5],其中0、1、3、5分别代表的是lda、nb、dt、lr。
[0225]
对应whited数据集,见图6,其多样性ent
max
和ent
min
分别是0.0473和0.0013,多样性查看范围ent
*
的中点为0.0243,范围增量σ设置为0.003。whited数据集的最佳组合为[2,3,5,6],代表knn、dt、lr、bpnn四种基分类器。
[0226]
图中纵坐标为学习器组合的平均准确率avg,横坐标为其多样性ent,一个圆点是一种基分类器组合。同时计算了该基分类器组合的香农熵加权投票准确率,图中用星形表示。待选择的学习器组合应该尽量保持ent
*
范围内测试集平均准确率高的同时也要保证多样性高,同时组合的香农熵加权投票算法准确率也达到最高。因此最佳组合的选择一般靠近中间部分,在图中用三角形表示香农熵加权投票算法准确率最高的组合,此时该组合对应的菱形是平均准确率和多样性处于平衡的平衡点,也是所求的最佳学习器组合。
[0227]
对于自测数据集,lda、nb、dt、lr四种分类器和香农熵加权算法在测试集上的平均准确率分别为98.6%、98.6%、97.8%、53.8%和99.5%,见图9。
[0228]
对于whited数据集,knn、dt、lr、bpnn四种分类器和香农熵加权算法在测试集上的平均准确率分别为98.7%、99.1%、95.8%、98.5%和100%,见图10。
[0229]
对于两种数据集,分类器根据特征选择得到各自的最佳特征组合,表1展示了四种
分类器的特征组合。
[0230]
表2基分类器在两个数据集上提取的特征及特征数量
[0231][0232]
本发明算法在实测数据集的测试混淆矩阵见图11,可以看出有类别26(台式机+笔记本+煮蛋器+电热风2档)中有7个样本被预测成为19(台式机+煮蛋器+电热风2档)。类别27(台式机+笔记本+煮蛋器+电热毯2档)中有3个样本被预测为类别16(台式机+笔记本+煮蛋器)。查看这10个样本在四种基分类器中的测试情况,发现他们均被分类错误,因而在集成后仍然被分类错误。
[0233]
进一步将本文提出的香农熵加权投票算法与其他加权算法(见表4)进行对比,结果见表5,是可以看出香农熵加权投票算法的准确率更高,说明了本文算法的鲁棒性高于其他权重方法。
[0234]
表4常见的4种权重
[0235]
[0236][0237]
表5不同权重的算法准确率对比
[0238][0239]
进一步,将本文提出的香农熵加权集成算法与当前文献中常用的其它集成学习算法进行了对比,主要包括基于决策树的adaboost算法、随机森林和元模型为mlp算法的stacking算法。计算了它们对实测数据集和whited公共数据集的测试准确率。使用的各算法的参数和准确率结果见表6。可以看出,本文提出的基于香农熵加权投票的算法在两种数据集上的测试准确率都有明显提升。
[0240]
表6实测数据的多模型的准确率对比
[0241][0242][0243]
通过上述原理,得到了关于自测数据集的最佳模型组合。接下来要对保存,本发明采用“joblib”来保存模型,让模型持久化。
[0244]
模型读取与预测,本发明在子线程6种采用“joblib”来加载模型,并且把实时更新的特征序列输入到模型中,预测分类结果。
[0245]
根据表7,显示了五个耗时的操作所需的时间。如果使用单线程,所消耗的总时间是它们的总和,即44ms。
[0246]
在多线程的情况下,消耗的总时间主要取决于主线程,是前两个线程的总和,即6ms。根据表8,对于实测数据,lda、nb、dt、lr四种算法的多线程总消耗时间都很小。然而,根据识别精度,基于香农熵加权投票算法的精度是最高的。
[0247]
很多国家的工业频率是50hz,对于一个周期的数据需要0.02s,需要的算法运行时间小于0.02,由于算法时间需要小于20ms,所以单线程明确地超时了。
[0248]
表7耗时操作的所用时间
[0249][0250]
表8五种算法在单线程和多线程情况下的时间对比
[0251][0252]
实时检测过程见图12,在检测到事件后,通过稳态数据分析结果是电吹风,可视化数据是通过展示有功功率波形图的方式得到。
[0253]
本发明基于香农熵加权投票算法提出的一种基于多线程的非侵入式负荷实时在线监测与识别系统可以满足实时任务的要求,具有较高的识别精度。
[0254]
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1