文字资料的筛选关联方法及系统与流程
本发明关于一种文字资料的筛选关联方法及系统;特别运用一种以前后相邻的筛选断词为基础,可快速整理及分析文字资料,并可以对照文字资料分析待比对文字资 料的原创性的文字资料的筛选关联方法及系统。
背景技术:
1、近年来,论文抄袭事件层出不穷,社会大众开始对论文的原创性产生疑虑,虽然目前市面上已有许多论文、文章抄袭比对的检测系统,但这些系统多是在对发表研究 论文的著作权人采取怀疑态度的情况下进行抄袭比对检测,对著作权人是不公平的。 此外,部分单位甚至要求著作权人必须先提交抄袭比对结果,并要求相似程度在一定 比例下,才能让论文著作权人径行发表,因此著作权人需要先用此方法证明自己文件 未抄袭他人,此种做法对著作权人是采取不信任的态度,非常不恰当。发明人认为应 反向思考、正向针对著作权人的论文发表提供检测原创性的工具,为其论文发表的参 考,发表单位并可以制定原创性比例作为论文品质管理的参考依据。
2、关于抄袭比对系统,近年来,在学术研究中,论文抄袭的议题已愈发严重,由于 该议题持续发烧,抄袭检测(plagiarism detection)越来越被重视了,抄袭(plagiarism) 议题主要分为以下种类:1.毫无修改的复制贴上或片段抄袭(copy/paste/cloneplagiarism)。2.段落改写(paraphrasing plagiarism):通过抄袭段落、切换词汇或是改写句子结构或语法风格。3.隐喻抄袭(metaphor plagiarism):通过清晰,更好地表达 别人的想法方式。4.想法抄袭(idea plagiarism):想法或解决方案是从其他来源借来 的,当作自己的研究论文。5.自我抄袭(self/recycled plagiarism):用自己发表过的文 章,当作新的研究结果再发表一次。6.引用抄袭:引用适当来源的参考文献,但是其 描述跟原始内容的用词跟句子,甚至结构语法相似。
3、在这些种类的抄袭中,以“毫无修改的复制贴上或片段抄袭”、“段落改写”最受 大家关注,此两种抄袭方式可通过比对该论文与被抄袭文献资料,即可明显看出抄袭 行为,故该两者最令人诟病。
4、在1995年就有学者进行研究,该论文在数字文件上进行复制检测,而随着自然语言处理以及硬件设备的演进之后,近年来也有很多不同的方法推陈出新,而在抄袭检 测领域上,主要分为数种方法:1.基于字串的方法(character-based methods):此方 法为论文抄袭检测最大宗的方法,待比对论文跟现有论文资料库进行比较,通过寻找 符合字串,进而判断出论文抄袭的比例,也因此可以告诉系统使用者,抄袭段落以及 语句。shrestha以及solorio在2013年发表,通过将停用词、命名实体以及所有词汇以 n-grams的方式,通过考虑该检测论文与文本资料库文章是否有n-gram符合程度过高 的文章,进而检测抄袭。nguyen等人在2016年提出,通过抄袭检测,检测越南文的 文章是否抄袭,该方法通过子字串n-gram的方法。此类的方法有以下三种缺陷:一、 若该论文出现论文资料库没有的文字时,会导致比对不出相似文句,因而检测不出抄 袭论文;二、使用者可以通过更改词汇或是交换词汇顺序,进而避开此种方法检测方 式,导致检测不出相似词句;三、由于此种方法是比较字串,若输入字串长度过长, 容易导致稀释输入论文,进而降低抄袭相似度。2.基于向量的方法(vector-based methods):此方法通过萃取词汇和语法功能,并将其分类为向量而不是字符串。这 个的相似度通常都是用雅卡尔系数(jaccard coefficient)、权等骰子系数(dice coefficient)、重迭系数(overlap coefficient)或余弦相似度(cosinesimilarity)等方 法来衡量论文以及论文之间的相似程度。mahdavi等人发表,通过向量空间模型检测 波斯文章是否抄袭,通过将文章转为tf-idf的方法,比较其中的文章相似度。jiffriya 等人在2013年提出,将文章转为向量再通过k-means演算法进行分群,分群完后,将 文章基于tri-gram进行抄袭检测。此种方法的缺点,是通过词频来衡量文章中的一个词的重要性,有时候重要的词出现的次数可能不够多,会导致比对出的结果差,而此 种计算无法体现位置信息与词在上下文的重要性。3.基于语法的方法(syntax-basedmethods):此种方法通过使用句法特征像是词性、句子的相依树以及字在不同的陈 述来检测抄袭,使用词性来呈现字词架构并且计算相似度。此种方法可以找到语句结 构类似的段落,但是找不到段落改写、抽换词汇以及转换文句结构的抄袭。基于语法 的方法有几种缺陷,一、中文语法相较英文语法复杂许多,若是将我们中文的抄袭系 统通过语法的方式来检测论文抄袭,会导致比对结果极差;二、此种方法通过句法的 特征来检测抄袭的内容,会导致找到相似句法特征,但是没有抄袭的文字,仅句法相 同,导致判别错误。4.基于语义的方法(semantic-based methods):此方法通过让系 统了解段落语意,将文章转为向量,可以用来检测换顺序、换主被动,但是该方法不 能找到抄袭的段落以及句子。torres于2009年提出通过建立字典的方式协助进行检测 抄袭,resnik在1999通过外部的资源协助使用语意来检测抄袭。通过语意的方式解决 检测抄袭会找到相似语意的论文,但是无法得知抄袭的段落及词汇,没办法进行验证 抄袭。
5、发明人有鉴于此,乃苦思细索,积极研究,加以多年从事相关产品研究的经验, 并经不断试验及改良,终于发展出本发明。
技术实现思路
1、本发明的目的在于提供一种可快速整理出文字资料的简要信息的文字资料的筛选关联方法。
2、本发明达成上述目的的方法包括下列步骤:s11.以一断词词汇库为基础,对一文字资料进行断词处理以产生一断词信息;s12.对该断词信息进行筛选处理以产生一筛 选断词信息;该筛选断词信息具有二个以上的筛选断词;s13.对该筛选断词信息进行 关联性处理以产生多个关联性序列信息;所述多个关联性序列信息分别由二个以上的 前后相邻的筛选断词所组成。
3、较佳者,在进行该步骤s11之前,可先进行一步骤s110;该步骤s110为:收集该 文字资料中的作者自订关键词以建立一专业关键词词汇库,并将该专业关键词词汇库 汇入该断词词汇库,借以获得更贴近文字资料的本意的关联性序列信息。
4、较佳者,在该步骤s12中,在筛选处理以后,可先进行同义字词处理,再进行后 续步骤;该同义字词处理为:对该筛选处理后的筛选断词进行文字同义检查,将同义 字、同义词转换成标准文字。
5、本发明的又一目的在于提供一种可快速整理出文字资料的简要信息的文字资料的筛选关联系统。
6、本发明达成上述目的的结构包括:一储存模块,用于储存一断词词汇库;一断词处理模块,用于对一文字资料进行断词处理以产生一断词信息;一筛选处理模块,用 于并对该断词信息进行筛选处理以产生一筛选断词信息;一关联性处理模块,用于对 该筛选断词信息进行关联性处理以产生多个关联性序列信息。
7、本发明的再一目的在于提供一种,可快速整理出多份对照文字资料的简要信息,并将各对照文字资料的简要信息整合在一起,进而可方便分析待比对文字资料的原创 性的文字资料的筛选关联方法。
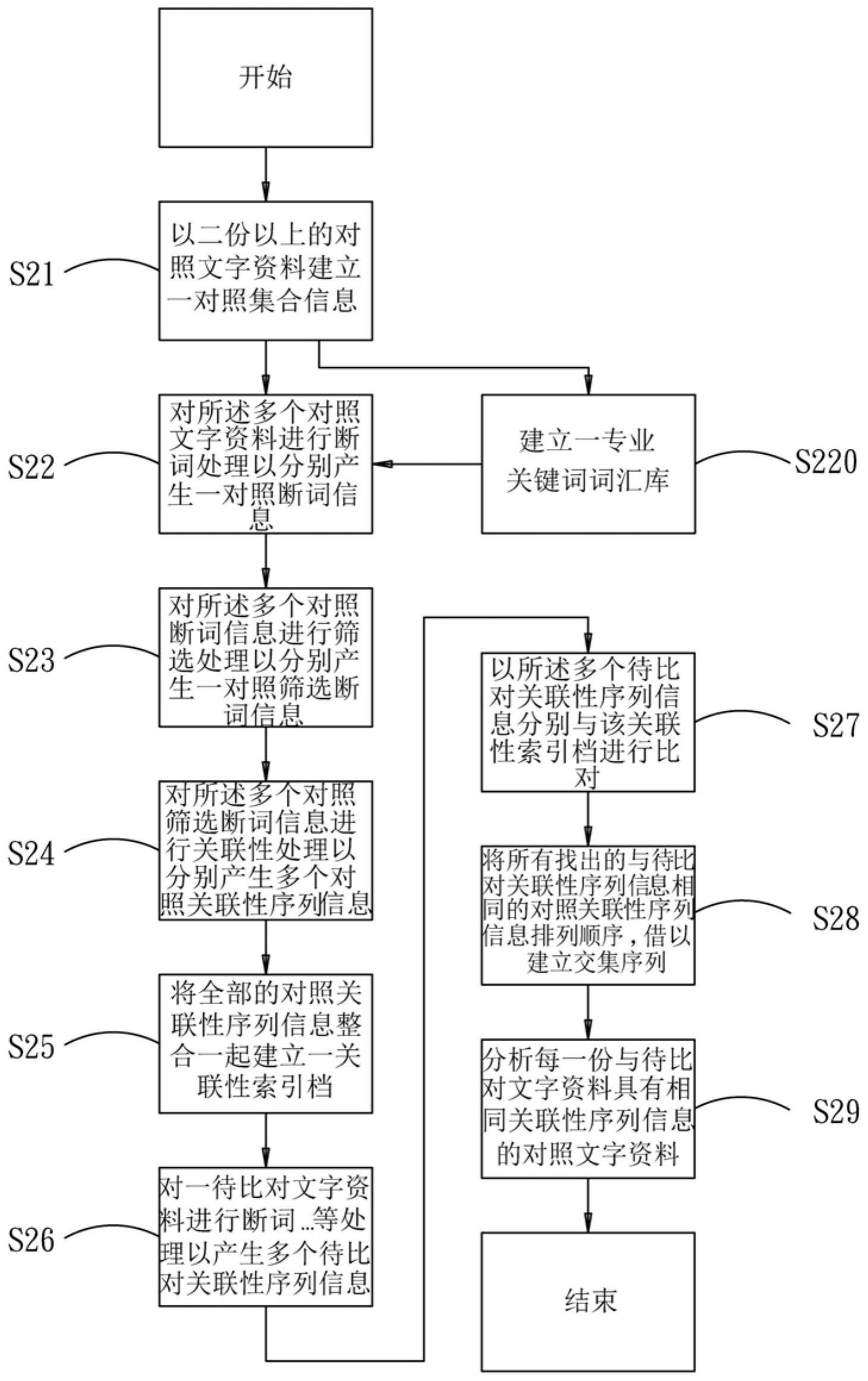
8、本发明达成上述目的的方法包括下列步骤:s21.以二份以上的对照文字资料建立一对照集合信息;s22.以一断词词汇库为基础,对所述多个对照文字资料进行断词处 理以分别产生一对照断词信息;s23.对所述多个对照断词信息进行筛选处理以分别产 生一对照筛选断词信息;所述多个对照筛选断词信息分别具有二个以上的筛选断词; s24.对所述多个对照筛选断词信息进行关联性处理以分别产生多个对照关联性序列 信息;所述多个对照关联性序列信息分别由二个以上的前后相邻的筛选断词所组成; s25.将全部的对照关联性序列信息整合一起建立一关联性索引档。
9、较佳者,在进行该步骤s22之前,先进行一步骤s220;该步骤s220为:收集所述 多个对照文字资料及该待比对文字资料中的一部分或全部的作者自订关键词以建立 一专业关键词词汇库,并将该专业关键词词汇库汇入该断词词汇库,借以获得更贴近 文字资料的本意的关联性索引档。
10、较佳者,在该步骤s25以后,进行步骤s26~s29;步骤s26为:对一待比对文字资 料进行断词处理、筛选处理及关联性处理以产生多个待比对关联性序列信息;步骤s27 为:以所述多个待比对关联性序列信息分别与该关联性索引档进行比对,找出具有与 所述多个待比对关联性序列信息相同的对照关联性序列信息的各个对照文字资料;步 骤s28为:建立交集序列,将所有与待比对关联性序列信息相同的对照关联性序列信 息排列顺序;步骤s29为:分析每一份与待比对文字资料具有相同关联性序列信息的 对照文字资料,借以分析待比对文字资料的原创性。
11、较佳者,在该步骤s23中,在筛选处理以后,可先进行同义字词处理,再进行后 续步骤,可增加关联性比对效果。
12、本发明的又一目的在于提供一种,可快速整理出多份对照文字资料的简要信息,并将各对照文字资料的简要信息整合在一起,进而可方便分析待比对文字资料的原创 性的文字资料的筛选关联系统。
13、本发明达成上述目的的结构包括:一储存模块,用于储存一断词词汇库及一对照集合信息;
14、一断词处理模块,用于对该对照集合信息的各个对照文字资料进行断词处理以分别产生一对照断词信息;一筛选处理模块,用于并对所述多个对照断词信息进行筛选 处理以分别产生一对照筛选断词信息;一关联性处理模块,用于对所述多个对照筛选 断词信息进行关联性处理以分别产生多个对照关联性序列信息;一整合模块,用于将 全部的对照关联性序列信息整合一起建立一关联性索引档。
15、较佳者,该断词处理模块、筛选处理模块及关联性处理模块对一待比对文字资料进行断词处理、筛选处理及关联性处理以产生多个待比对关联性序列信息,且该文字 资料的筛选关联系统更包括:一比对模块,以所述多个待比对关联性序列信息分别与 该关联性索引档进行比对,找出具有与所述多个待比对关联性序列信息相同的对照关 联性序列信息的各个对照文字资料;一交集模块,将所有与待比对关联性序列信息相 同的对照关联性序列信息排列顺序,借以建立交集序列;一分析模块,分析每一份与 待比对文字资料具有相同关联性序列信息的对照文字资料。
16、本发明为达到上述及其他目的,其所采取的技术手段、元件及其功效,兹采一较佳实施例配合图示说明如下。
- 还没有人留言评论。精彩留言会获得点赞!