一种空间数据处理方法及装置与流程
1.本技术涉及数据融合处理技术,尤其涉及一种空间数据处理方法。本技术还提供一种空间数据处理装置。
背景技术:
2.多源的空间数据融合是时空数据处理的难点,多源数据融合技术是通过调查、分析,将获取到的所有信息全部综合到一起,对信息进行统一的评价最后得到统一的地质体信息。多源数据融合技术的目的是将各种不同的数据信息进行综合吸取不同数据源的特点然后从中提取出统一的,比单一数据更好、更丰富的信息。
3.现有技术中,对时空信息进行获取、表达、查询、特征提取、区域划分等处理分析,来获得反映地球表层分布和动态发展对了的地学信息。但是,现有技术通常需要采用人工标注,再由计算机进行数据的采样处理,工作量大,耗时长,且容易出错。
技术实现要素:
4.为了结局上述技术中时空数据融合耗时长且容易出错的问题,本技术提供一种空间数据处理方法。本技术还提供一种空间数据处理装置。
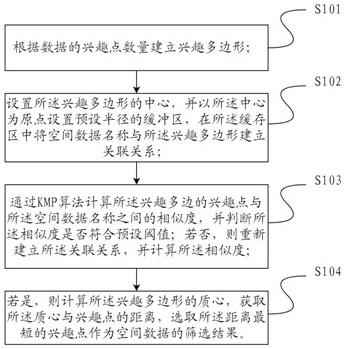
5.本技术提供一种空间数据处理方法,包括:根据数据的兴趣点数量建立兴趣多边形;设置所述兴趣多边形的中心,并以所述中心为原点设置预设半径的缓存区,在所述缓存区中将空间数据名称与所述兴趣多边形建立关联关系;通过kmp算法计算所述兴趣多边形的兴趣点与所述空间数据名称之间的相似度,并判断所述相似度是否符合预设阈值;若否,则重新建立所述关联关系,并计算所述相似度;若是,则计算所述兴趣多边形的质心,获取所述质心与兴趣点的距离,选取所述距离最短的兴趣点作为空间数据的筛选结果。
6.可选的,所述相似度范围是0~1,当所述相似度为0,则所述空间数据与所述兴趣点的属性类别完全不同,当所述相似度为1,则所述空间数据与所述兴趣点的属性类别完全相同。
7.可选的,所述预设阈值为0.85。
8.可选的,所述计算所述兴趣多边形的质心之前,还包括:计算满足所述预设阈值的兴趣点数量,当所述兴趣点数量≤1,则所述空间数据滞空,停止计算,当所述兴趣点数量>1,则进行质心计算。
9.可选的,所述兴趣多边形包括多个层级,不同层级具有不同的数据粒度。
10.本技术还提供一种空间数据处理装置,包括:初始模块,用于根据数据的兴趣点数量建立兴趣多边形;设置模块,用于设置所述兴趣多边形的中心,并以所述中心为原点设置预设半径
的缓存区,在所述缓存区中将空间数据名称与所述兴趣多边形建立关联关系;计算模块,用于通过kmp算法计算所述兴趣多边形的兴趣点与所述空间数据名称之间的相似度,并判断所述相似度是否符合预设阈值;若否,则重新建立所述关联关系,并计算所述相似度;筛选模块,用于当所述判断若是,计算所述兴趣多边形的质心,获取所述质心与兴趣点的距离,选取所述距离最短的兴趣点作为空间数据的筛选结果。
11.可选的,所述相似度范围是0~1,当所述相似度为0,则所述空间数据与所述兴趣点的属性类别完全不同,当所述相似度为1,则所述空间数据与所述兴趣点的属性类别完全相同。
12.可选的,所述预设阈值为0.85。
13.可选的,所述筛选模块还包括:过滤单元,用于计算满足所述预设阈值的兴趣点数量,当所述兴趣点数量≤1,则所述空间数据滞空,停止计算,当所述兴趣点数量>1,则进行质心计算。
14.可选的,所述兴趣多边形包括多个层级,不同层级具有不同的数据粒度。
15.本技术相较于现有技术的优点是:本技术提供一种空间数据处理方法,包括:根据数据的兴趣点数量建立兴趣多边形;设置所述兴趣多边形的中心,并以所述中心为原点设置预设半径的缓存区,在所述缓存区中将空间数据名称与所述兴趣多边形建立关联关系;通过kmp算法计算所述兴趣多边形的兴趣点与所述空间数据名称之间的相似度,并判断所述相似度是否符合预设阈值;若否,则重新建立所述关联关系,并计算所述相似度;若是,则计算所述兴趣多边形的质心,获取所述质心与兴趣点的距离,选取所述距离最短的兴趣点作为空间数据的筛选结果。通过筛选相似集再通过质心位置进行过滤排序,得出最优结果进行融合补充,使数据可信度大大提升,降低需求数据缺失率。
附图说明
16.图1是本技术中空间数据处理流程图。
17.图2是本技术中空间数据处理逻辑图。
18.图3是本技术中空间数据处理装置示意图。
具体实施方式
19.在下面的描述中阐述了很多具体细节以便于充分理解本技术。但是本技术能够以很多不同于在此描述的其它方式来实施,本领域技术人员可以在不违背本技术内涵的情况下做类似推广,因此本技术不受下面公开的具体实施的限制。
20.本技术提供一种空间数据处理方法,包括:根据数据的兴趣点数量建立兴趣多边形;设置所述兴趣多边形的中心,并以所述中心为原点设置预设半径的缓存区,在所述缓存区中将空间数据名称与所述兴趣多边形建立关联关系;通过kmp算法计算所述兴趣多边形的兴趣点与所述空间数据名称之间的相似度,并判断所述相似度是否符合预设阈值;若否,则重新建立所述关联关系,并计算所述相似度;若是,则计算所述兴趣多边形的质心,获取所述质心与兴趣点的距离,选取所述距离最短的兴趣点作为空间数据的筛选结果。通过筛
选相似集再通过质心位置进行过滤排序,得出最优结果进行融合补充,使数据可信度大大提升,降低需求数据缺失率。
21.图1是本技术中空间数据处理流程图,图2是本技术中空间数据处理逻辑图。
22.请参照图1所示,s101根据数据的兴趣点数量建立兴趣多边形。
23.本技术中,所述兴趣多边形是指将数据的属性特征作为点,将多个所述属性特征连接成闭环形成的兴趣多边形。优选的,所述属性特征是属性名称,所述属性名称与空间数据的名称具有对应关系。
24.所述建立兴趣多边形是指,将空间数据的属性特征列出,形成多个属性特征集合,此时所述兴趣多边形是正兴趣多边形,该兴趣多边形的每一个兴趣点是一个属性特征。
25.请参照图1所示,s102设置所述兴趣多边形的中心,并以所述中心为原点设置预设半径的缓存区,在所述缓存区中将空间数据名称与所述兴趣多边形建立关联关系。
26.所述兴趣多边形建立后,属于初始化的兴趣多边形,该兴趣多边形的每个兴趣点,也就是属性特征是在所述兴趣多边形中的地位是一样的。在此基础上,以所述兴趣多边形的中心为原点,设置一个预设半径距离的缓存区,所述缓存区用于分布所述空间数据。
27.请参照图2所示,优选的,本技术设置所述预设半径为70m,在所述预设半径内,输入所述空间数据,并分别规定所述兴趣多边形的每个兴趣点的方向,形成一个由多条放射性从一个原点平均切分半径为70m圆的初始化空间数据分布图,其中每个扇面都表示一个兴趣点。
28.根据所述空间数据的名称与所述兴趣多边形的兴趣点的属性特征,计算所述空间数据名称与所述兴趣多边形的兴趣点之间的关联关系,并将所述兴趣点分布在所述缓存区内。例如,“北京市,朝阳区”这个数据,既可分布在属性特征为地址的兴趣点中。进一步的,所述兴趣多边形包括多个层级,不同层级具有不同的数据粒度。还以“北京市,朝阳区”这个数据为例,关于地址的所述兴趣点中还可以确定“北京市”为一级层级,而所述“朝阳区”为二级层级。通过该步骤,每个空间数据都建立了和所述兴趣多边形的关联关系。优选的,本技术采用自然语言识别对所述空间数据的名称进行识别,并根据所述识别结果建立和所述兴趣多边形的关联关系。
29.请继续参考图1所示,s103通过kmp算法计算所述兴趣多边形的兴趣点与所述空间数据名称之间的相似度,并判断所述相似度是否符合预设阈值;若否,则重新建立所述关联关系,并计算所述相似度。
30.所述kmp算法是指字符串查找算法,可在一个字符串内查找一个词的出现位置。一个词在不匹配时本身就包含足够的信息来确定下一个匹配可能的开始位置,此算法利用这一特性以避免重新检查先前匹配的字符。
31.如图2所示,本技术利用所述kmp算法计算并匹配所述空间数据名称和兴趣点的相似度。在本技术中,所述相似度范围是0~1,当所述相似度为0,则所述空间数据与所述属性类别完全不同,当所述相似度为1,则所述空间数据与所述属性类别完全相同。优选的,本技术所述预设阈值为0.85。
32.计算满足所述预设阈值的兴趣点数量,当所述兴趣点数量<1,则所述空间数据滞空,停止计算,当所述兴趣点数量=1,则需要补充数据,当所述兴趣点数量>1,则进行质心计算。
33.当计算得到所述空间数据和所述兴趣点之间的相似度后,判断所述相似度的是否符合所述预设阈值的要求,既所述相似度是否>所述预设阈值。
34.若否,则重新为所述空间数据与所述兴趣多边形建立关联关系,并计算相似度,若是,则进行下一步。
35.请继续参照图1所示,s104若是,则计算所述兴趣多边形的质心,获取所述质心与兴趣点的距离,选取所述距离最短的兴趣点作为空间数据的筛选结果。
36.如图2所示,通过上述步骤的处理,所述空间数据分布在所述兴趣多边形内,并且每个所述空间数据都与兴趣点计算了相似度,接下来,则根据所述相似度分别计算每个和所述兴趣点具有相似度的所述空间数据分布范围内的质心,获取所述兴趣点与所述质心的距离。
37.具体的,可通过如下公式计算所述质心a:其中,所述是数据在所述兴趣多边形中心为原点的极坐标系中的每个空间数据角度平均值,所述l是每个所述空间数据距离所述兴趣多边形的平均距离。所述n是每个兴趣点具有相似性的空间数据的个数。
38.所述a点是所述空间数据的每个兴趣点的质心,而每个兴趣点的为啥是预先设置的,接下来计算所述质心到所述兴趣点的距离。为所述距离排序,选取所述距离最短的兴趣点作为空间数据的筛选结果。该筛选结果是所述空间数据的最优可信属性。
39.本技术还提供一种空间数据处理装置,包括:初始模块,设置模块,计算模块,筛选模块。
40.图3是本技术中空间数据处理装置示意图。
41.请参照图3所示,初始模块201,用于根据数据的兴趣点数量建立兴趣多边形。
42.本技术中,所述兴趣多边形是指将数据的属性特征作为点,将多个所述属性特征连接成闭环形成的兴趣多边形。优选的,所述属性特征是属性名称,所述属性名称与空间数据的名称具有对应关系。
43.所述建立兴趣多边形是指,将空间数据的属性特征列出,形成多个属性特征集合,此时所述兴趣多边形是正兴趣多边形,该兴趣多边形的每一个兴趣点是一个属性特征。
44.请参照图3所示,设置模块202,用于设置所述兴趣多边形的中心,并以所述中心为原点设置预设半径的缓存区,在所述缓存区中将空间数据名称与所述兴趣多边形建立关联关系。
45.所述兴趣多边形建立后,属于初始化的兴趣多边形,该兴趣多边形的每个兴趣点,也就是属性特征是在所述兴趣多边形中的地位是一样的。在此基础上,以所述兴趣多边形的中心为原点,设置一个预设半径距离的缓存区,所述缓存区用于分布所述空间数据。
46.优选的,本技术设置所述预设半径为70m,在所述预设半径内,分别规定所述兴趣多边形的每个兴趣点的方向,形成一个由多条放射性从一个原点平均切分半径为70m圆的初始化空间数据分布图,其中每个扇面都表示一个兴趣点。
47.根据所述空间数据的名称与所述兴趣多边形的兴趣点的属性特征,计算所述空间数据名称与所述兴趣多边形的兴趣点之间的关联关系,并将所述兴趣点分布在所述缓存区内。例如,“北京市,朝阳区”这个数据,既可分布在属性特征为地址的兴趣点中。进一步的,所述兴趣多边形包括多个层级,不同层级具有不同的数据粒度。还以“北京市,朝阳区”这个数据为例,关于地址的所述兴趣点中还可以确定“北京市”为一级层级,而所述“朝阳区”为二级层级。通过该步骤,每个空间数据都建立了和所述兴趣多边形的关联关系。优选的,本技术采用自然语言识别对所述空间数据的名称进行识别,并根据所述识别结果建立和所述兴趣多边形的关联关系。
48.请继续参考图3所示,计算模块203,用于通过kmp算法计算所述兴趣多边形的兴趣点与所述空间数据名称之间的相似度,并判断所述相似度是否符合预设阈值;若否,则重新建立所述关联关系,并计算所述相似度。
49.所述kmp算法是指字符串查找算法,可在一个字符串内查找一个词的出现位置。一个词在不匹配时本身就包含足够的信息来确定下一个匹配可能的开始位置,此算法利用这一特性以避免重新检查先前匹配的字符。
50.本技术利用所述kmp算法计算并匹配所述空间数据名称和兴趣点的相似度。在本技术中,所述相似度范围是0~1,当所述相似度为0,则所述空间数据与所述属性类别完全不同,当所述相似度为1,则所述空间数据与所述属性类别完全相同。优选的,本技术所述预设阈值为0.85。
51.当计算得到所述空间数据和所述兴趣点之间的相似度后,判断所述相似度的是否符合所述预设阈值的要求,既所述相似度是否>所述预设阈值。
52.若否,则重新为所述空间数据与所述兴趣多边形建立关联关系,并计算相似度,若是,则进行下一步。
53.请继续参照图3所示,筛选模块204,用于当所述判断若是,计算所述兴趣多边形的质心,获取所述质心与兴趣点的距离,选取所述距离最短的兴趣点作为空间数据的筛选结果。
54.本技术所述筛选模块还包括,过滤单元,用于在所述相识度计算之前执行:计算满足所述预设阈值的兴趣点数量,当所述兴趣点数量<1,则所述空间数据滞空,停止计算,当所述兴趣点数量=1,则需要补充数据,当所述兴趣点数量>1,则进行质心计算。
55.通过上述步骤的处理,所述空间数据分布在所述兴趣多边形内,并且每个所述空间数据都与兴趣点计算了相似度,接下来,则根据所述相似度分别计算每个和所述兴趣点具有相似度的所述空间数据分布范围内的质心,获取所述兴趣点与所述质心的距离。
56.具体的,可通过如下公式计算所述质心a:其中,所述是数据在所述兴趣多边形中心为原点的极坐标系中的每个空间数据角度平均值,所述l是每个所述空间数据距离所述兴趣多边形的平均距离。所述n是每个兴趣点具有相似性的空间数据的个数。
57.所述a点是所述空间数据的每个兴趣点的质心,而每个兴趣点的为啥是预先设置的,接下来计算所述质心到所述兴趣点的距离。为所述距离排序,选取所述距离最短的兴趣点作为空间数据的筛选结果。该筛选结果是所述空间数据的最优可信属性。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1