一种应用容器高可用负载平台的制作方法
1.本发明涉及计算机技术领域,特别涉及一种应用容器高可用负载平台。
背景技术:
2.容器服务是基于基础设施提供的docker容器引擎服务平台,覆盖了软件开发过程中的开发、测试、演练、上线等生命周期管理,保持应用系统快速搭建和各环境的一致性。
3.容器集群是将多台物理机抽象为逻辑上单一调度实体的技术,为容器化的应用提供资源调度、服务发现、弹性伸缩、负载均衡等功能,任何例外造成容器集群的运行中断都将造成不可估量的损失,服务的高可用性也越来越重要。
技术实现要素:
4.本发明提供一种应用容器高可用负载平台,实现自动对故障服务节点进行切换,并将修复好的故障容器加入至备用容器集合中,为容器集群的长时间正常运行提供保障。
5.本发明提供一种应用容器高可用负载平台,包括:
6.监测模块,用于监测容器集群中所有服务节点的运行情况,确定故障服务节点;
7.切换模块,用于剔除所述故障服务节点对应的故障容器,并从备用容器集合中选择目标容器自动接入所述容器集群中的故障服务节点所在的位置;
8.恢复模块,用于当所述故障容器恢复正常时,自动接入所述备用容器集合中。
9.在一种可能实现的方式中,
10.所述服务节点的运行情况包括:相邻服务节点之间链路连通情况、整个服务节点异常情况、服务节点内部业务逻辑异常情况。
11.在一种可能实现的方式中,
12.所述监测模块包括:
13.整体监测单元,用于对整个容器集群的整体运行状态进行监测,判断是否出现状态异常情况;
14.节点检测单元,用于当确定出现状态异常情况时,对所述容器集群中的所有服务节点进行检测,确定故障服务节点;
15.节点分析单元,用于对所述故障服务节点进行深度分析,确定节点异常类型。
16.在一种可能实现的方式中,
17.匹配模块,用于从所述备用容器集合中选择目标容器。
18.在一种可能实现的方式中,
19.所述切换模块包括:
20.确定单元,用于根据所述目标容器的设备标识和确定容器接入请求,并根据所述目标容器的位置信息确定容器接入路径;
21.接入单元,用于根据所述容器接入请求和容器接入路径,将所述目标容器接入至所述容器集群中;
22.剔除单元,用于从所述故障服务节点剔除对应的故障容器;
23.配置单元,用于从服务数据库中获取所述故障服务节点的服务数据,并将所述服务数据配置给所述目标容器;
24.发送单元,用于根据所述故障服务节点在所述容器集群中的位置,将所述目标容器发送至所述位置;
25.连接单元,用于建立所述目标容器与所述容器集群中剩余服务节点的连接。
26.在一种可能实现的方式中,
27.所述恢复模块包括:
28.报警单元,用于接收所述故障容器,并进行报警提醒;
29.修复单元,用于在接收到所述报警提醒后,对所述故障容器进行修复;
30.检测单元,用于对修复后的故障容器进行检测,判断所述故障容器是否修复成功;
31.若成功,将所述修复后的故障容器自动接入所述备用容器集合中;
32.否则,进行再次报警提醒,并对所述故障容器进行再次修复。
33.在一种可能实现的方式中,
34.所述节点分析单元包括:
35.确定子单元,用于根据所述容器集群中所有服务节点之间的链路连接信息,确定与所述故障服务节点的链路连接相关联的关联服务节点;
36.获取子单元,用于获取所述故障服务节点和关联服务节点之间的链路连通日志;
37.提取子单元,用于按照预设提取方法从所述链路连通日志中提取关联信息,并基于所述关键信息确定链路连通指标;
38.对比子单元,用于将所述链路连通指标与链路数据库中的标准指标进行对比,获取对比结果;
39.第一判断子单元,用于基于所述对比结果,确定所述链路连接是否出现异常;
40.若是,确定所述故障服务节点的异常类型为链路连通异常;
41.否则,表明所述故障服务节点的链路连接正常;
42.解析子单元,用于当所述链路连接正常时,对所述故障服务节点进行解析,得到多个子节点,并获取每个子节点的运行数据;
43.第二判断子单元,用于基于标准运行数据,判断所述运行数据是否出现异常,并确定出现异常的运行数据对应的子节点;
44.所述第二判断子单元,还用于判断出现异常的子节点在所有子节点中的占比是否大于预设占比,且出现异常的运行数据的异常是否为运行数据缺失异常或运行数据混乱异常;
45.若是,确定所述故障服务节点的异常类型为整体节点异常;
46.否则,表明所述故障服务节点的整体节点运行正常;
47.所述获取子单元,还用于从服务数据库中获取每个子节点的服务任务数据,并确定所述服务任务数据的服务逻辑;
48.匹配子单元,用于对每个子节点下的服务任务的运行数据进行分析,确定运行逻辑,并按照预设逻辑映射关系,将所述服务逻辑于所述运行逻辑进行匹配,获取匹配结果;
49.第三判断子单元,用于基于所述匹配结果,判断子节点下的运行逻辑是否出现异
常;
50.若是,确定所述故障服务节点的异常类型为节点内部逻辑异常;
51.否则,确定所述故障服务节点的异常类型为人为操作异常。
52.在一种可能实现的方式中,
53.所述第二判断子单元包括:
54.划分子单元,用于根据所述标准运行数据中的标准参数及运行顺序,将所述标准运行数据划分多个子序列运行数据;
55.第二匹配子单元,用于将所述出现异常的运行数据与所述多个子序列运行数据进行匹配,获取数据匹配结果;
56.选择子单元,用于根据所述数据匹配结果,获取没有匹配到对应子序列运行数据的异常运行数据,即异常类型为运行数据缺失异常;获取与所述子序列运行数据顺序匹配的异常运行数据,即异常类型为运行数据混乱异常。
57.在一种可能实现的方式中,
58.所述匹配模块包括:
59.接收子模块,用于接收容器替换请求,并从所述替换请求中解析得到所述故障容器的型号类型,并从型号类型历史替换记录中,确定可替换所述故障容器的型号类型的目标型号类型;
60.选择子模块,用于根据所述目标型号类型对应的解析结果,从所述备用容器集合中选择至少两个第一备用容器;
61.提取子模块,用于提取所述第一备用容器的参数指标,并对所述参数指标进行归一化处理,得到标准参数指标;
62.设置子模块,用于根据所述故障服务节点的处理服务任务数据,确定所述故障服务节点对应用容器的指标需求,并基于所述指标需求,为所述标准参数指标设置不同的权重;
63.所述选择子模块,还用于根据所述不同的权重,计算所述第一备用容器的综合性能指数,并从所述第一备用容器中选取所述综合性能指数高于预设指数的第二备用容器;
64.确定子模块,用于根据所述故障服务节点的异常类型,确定所述异常类型对应的所述第二备用容器的接口;
65.生成子模块,用于基于所述故障服务节点的处理服务任务数据,确定所述接口的应用程序,并将所述应用程序接入所述接口上,生成接口日志;
66.检测子模块,用于利用预先建立的接口检测模型对所述接口日志进行检测,得到接口检测结果;
67.选择子模块,还用于选择所述接口检测结果与预期结果最匹配的接口对应的第二备用容器,作为目标容器。
68.在一种可能实现的方式中,
69.所述节点检测单元,包括:
70.预测子单元,用于获取所述容器集群中所有服务节点的历史状态信息,并基于所述历史状态信息预测每个服务节点的第一故障概率;
71.第一计算子单元,用于每隔预设时间检测所述的每个服务节点与相邻服务节点之
间的状态信息,并基于在本次检测中状态信息,计算每个服务节点在本次检测中的第二故障概率;
72.第二计算子单元,用于获取在多次检测中的当前服务节点的第二故障概率,并计算对当前服务节点检测的可信度;
73.节点确定子单元,用于当所述当前服务节点检测的可信度大于预设可信度时,判断所有检测次数中第二故障概率大于预设故障概率的次数,若所述次数大于预设次数,则判定当前服务节点为故障服务节点。
74.本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在所写的说明书、权利要求书、以及附图中所特别指出的结构来实现和获得。
75.下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
附图说明
76.附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
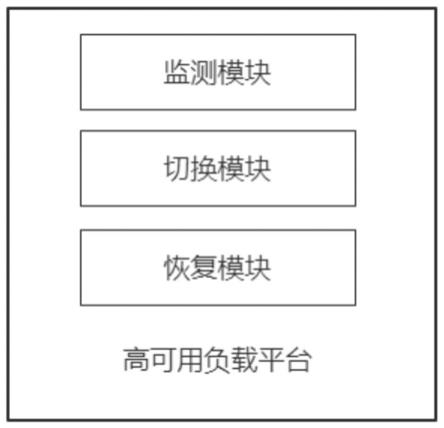
77.图1为本发明实施例中一种应用容器高可用负载平台的结构图;
78.图2为本发明实施例中监测模块的结构图;
79.图3为本发明实施例中恢复模块的结构图。
具体实施方式
80.以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。
81.实施例1
82.本发明实施例提供一种应用容器高可用负载平台,如图1所示,包括:
83.监测模块,用于监测容器集群中所有服务节点的运行情况,确定故障服务节点;
84.切换模块,用于剔除所述故障服务节点对应的故障容器,并从备用容器集合中选择目标容器自动接入所述容器集群中的故障服务节点所在的位置;
85.恢复模块,用于当所述故障容器恢复正常时,自动接入所述备用容器集合中。
86.在该实施例中,所述容器集群为由多个容器组成,实现用户私有集群的容器化管理,每个服务节点对应一个容器,服务节点依靠所述容器实现用户请求事务的处理。
87.在该实施例中,所述高可用的意思为尽可能采取措施减少系统服务中断时间,进而提高业务程序持续对外提供服务的能力。
88.上述设计方案的工作原理是:监测模块监测整个服务节点的运行情况,当发现出现故障服务节点时,从备用容器集合中选择合适的目标容器,利用切换模块自动接入容器集群中的故障服务节点所在的位置,并剔除故障服务节点对应的故障容器,同时,当检测到所述故障容器被修复成功时,自动将所述故障容器恢复至所述备用容器集合中,作为备用容器,保证容器集群的正常运行。
89.上述设计方案的有益效果是:通过监测容器集群的运行情况,实现自动对故障服务节点进行切换,保证了集群容器的长时间正常运行,同时,将修复好的故障容器加入至备
用容器集合中,为容器集群的长时间正常运行提供保障。
90.实施例2
91.基于实施例1的基础上,本发明实施例提供一种应用容器高可用负载平台,所述服务节点的运行情况包括:相邻服务节点之间链路连通情况、整个服务节点异常情况、服务节点内部业务逻辑异常情况。
92.上述设计方案的有益效果是:通过确定服务节点的异常情况,为后面选择目标容器提供了数据基础,保证了选择备用的目标容器的可用性,从而实现容器集群的高可用。
93.实施例3
94.基于实施例1的基础上,本发明实施例提供一种应用容器高可用负载平台,如图2所示,所述监测模块包括:
95.整体监测单元,用于对整个容器集群的整体运行状态进行监测,判断是否出现状态异常情况;
96.节点检测单元,当确定出现状态异常情况时,对所述容器集群中的所有服务节点进行检测,确定故障服务节点;
97.节点分析单元,用于对所述故障服务节点进行深度分析,确定节点异常类型。
98.在该实施例中,用于所述节点异常类型包括链路连通异常、整体节点异常、节点内部逻辑异常。
99.上述设计方案的有益效果是:通过先对整个容器集群的整体运行状态进行监测,当确定出现状态异常情况时,对所述容器集群中的所有服务节点进行检测,确定故障服务节点,避免了直接对所有服务节点进行检测,提高了检测效率和异常检测的精度,为后面选择目标容器提供了数据基础,从而实现容器集群的高可用。
100.实施例4
101.基于实施例1的基础上,本发明实施例提供一种应用容器高可用负载平台,还包括:匹配模块,用于从所述备用容器集合中选择目标容器。
102.上述设计方案的有益效果是:通过匹配模块来选择合适的目标容器,使选择的目标容器能够胜任所述服务节点的需求,实现容器集群高可用。
103.实施例5
104.基于实施例1的基础上,本发明实施例提供一种应用容器高可用负载平台,所述切换模块包括:
105.确定单元,用于根据所述目标容器的设备标识和确定容器接入请求,并根据所述目标容器的位置信息确定容器接入路径;
106.接入单元,用于根据所述容器接入请求和容器接入路径,将所述目标容器接入至所述容器集群中;
107.剔除单元,用于从所述故障服务节点剔除对应的故障容器;
108.配置单元,用于从服务数据库中获取所述故障服务节点的服务数据,并将所述服务数据配置给所述目标容器;
109.发送单元,用于根据所述故障服务节点在所述容器集群中的位置,将所述目标容器发送至所述位置;
110.连接单元,用于建立所述目标容器与所述容器集群中剩余服务节点的连接。
111.在该实施例中,先将所述目标容器接入所述容器集群后,在对所述故障容器进行剔除,节省了对服务节点中容器的切换时间,使容器集群更好的运行。
112.上述设计方案的有益效果是:通过确定目标容器的容器接入请求和容器接入路径、服务数据配置、与其他服务节点的连接,保证了接入目标容器的正常运行,实现容器集群的长时间运行。
113.实施例6
114.基于实施例1的基础上,本发明实施例提供一种应用容器高可用负载平台,如图3所示,所述恢复模块包括:
115.报警单元,用于接收所述故障容器,并进行报警提醒;
116.修复单元,用于在接收到所述报警提醒后,对所述故障容器进行修复;
117.检测单元,用于对修复后的故障容器进行检测,判断所述故障容器是否修复成功;
118.若成功,将所述修复后的故障容器自动接入所述备用容器集合中;
119.否则,进行再次报警提醒,并对所述故障容器进行再次修复。
120.上述设计方案的有益效果是:通过将修复好的故障容器加入至备用容器集合中,作为备用容器,来保障容器集群的长时间运行。
121.实施例7
122.基于实施例3的基础上,本发明实施例提供一种应用容器高可用负载平台,所述节点分析单元包括:
123.确定子单元,用于根据所述容器集群中所有服务节点之间的链路连接信息,确定与所述故障服务节点的链路连接相关联的关联服务节点;
124.获取子单元,用于获取所述故障服务节点和关联服务节点之间的链路连通日志;
125.提取子单元,用于按照预设提取方法从所述链路连通日志中提取关联信息,并基于所述关键信息确定链路连通指标;
126.对比子单元,用于将所述链路连通指标与链路数据库中的标准指标进行对比,获取对比结果;
127.第一判断子单元,用于基于所述对比结果,确定所述链路连接是否出现异常;
128.若是,确定所述故障服务节点的异常类型为链路连通异常;
129.否则,表明所述故障服务节点的链路连接正常;
130.解析子单元,用于当所述链路连接正常时,对所述故障服务节点进行解析,得到多个子节点,并获取每个子节点的运行数据;
131.第二判断子单元,用于基于标准运行数据,判断所述运行数据是否出现异常,并确定出现异常的运行数据对应的子节点;
132.所述第二判断子单元,还用于判断出现异常的子节点在所有子节点中的占比是否大于预设占比,且出现异常的运行数据的异常是否为运行数据缺失异常或运行数据混乱异常;
133.若是,确定所述故障服务节点的异常类型为整体节点异常;
134.否则,表明所述故障服务节点的整体节点运行正常;
135.所述获取子单元,还用于从服务数据库中获取每个子节点的服务任务数据,并确定所述服务任务数据的服务逻辑;
136.匹配子单元,用于对每个子节点下的服务任务的运行数据进行分析,确定运行逻辑,并按照预设逻辑映射关系,将所述服务逻辑于所述运行逻辑进行匹配,获取匹配结果;
137.第三判断子单元,用于基于所述匹配结果,判断子节点下的运行逻辑是否出现异常;
138.若是,确定所述故障服务节点的异常类型为节点内部逻辑异常;
139.否则,确定所述故障服务节点的异常类型为人为操作异常。
140.在该实施例中,所述关联服务节点为与所述故障服务节点存在链路连接的节点。
141.在该实施例中,所述链路连通日志用于记录链路连通情况,例如连通时间、链路信号强度等,所述链路连通指标包括连通具体时间、链路信号峰值、链路信号平均值等。
142.在该实施例中,所述每个子节点的运行数据为子节点处理事务的数据。
143.在该实施例中,若出现异常的子节点在所有子节点中的占比大于预设占比,表明多数子节点出现异常,由此可知,为整体节点出现异常导致了多数子节点的异常。
144.在该实施例中,所述服务任务数据的服务逻辑为所述服务任务的顺序和任务的任务参数的合理数据等。
145.在该实施例中,所述运行逻辑为执行服务任务时的执行顺序和运行状态下的参数数据。
146.在该实施例中,所述预设逻辑映射关系为所述服务逻辑和运行逻辑之间的映射关系,例如所述服务逻辑为挂号、问诊、取药,则对应的运行逻辑为出号、诊断、出药。
147.在该实施例中,若所述故障服务节点的异常类型为人为操作异常,例如可以是误关闭容器集群。
148.在该实施例中,所述链路连通、整体节点和节点内部逻辑为从上到下的,例如当故障节点出现链路连通异常时,无需再对整体节点和节点内部逻辑进行检测,出现整体节点异常时,无需再对和节点内部逻辑进行检测。
149.上述设计方案的有益效果是:通过从故障节点的链路连通、整体节点和节点内部逻辑从外到内进行依次检测,确定出故障节点的异常类型,为后续从备用容器集合中选取合适的备用容器提供基础,最终,保证了容器集群的高可用性。
150.实施例8
151.基于实施例7的基础上,本发明实施例提供一种应用容器高可用负载平台,所述第二判断子单元包括:
152.划分子单元,用于根据所述标准运行数据中的标准参数及运行顺序,将所述标准运行数据划分多个子序列运行数据;
153.第二匹配子单元,用于将所述出现异常的运行数据与所述多个子序列运行数据进行匹配,获取数据匹配结果;
154.选择子单元,用于根据所述数据匹配结果,获取没有匹配到对应子序列运行数据的异常运行数据,即异常类型为运行数据缺失异常;获取与所述子序列运行数据顺序匹配的异常运行数据,即异常类型为运行数据混乱异常。
155.上述设计方案的有益效果是:通过基于标准运行数据,对出现异常的运行数据进行检测,通过划分标准运行数据,提高了对每个节点异常检测的精确性,最终,提高了故障服务节点异常类型的判断精度。
156.实施例9
157.基于实施例1的基础上,本发明实施例提供一种应用容器高可用负载平台,所述匹配模块包括:
158.接收子模块,用于接收容器替换请求,并从所述替换请求中解析得到所述故障容器的型号类型,并从型号类型历史替换记录中,确定可替换所述故障容器的型号类型的目标型号类型;
159.选择子模块,用于根据所述目标型号类型对应的解析结果,从所述备用容器集合中选择至少两个第一备用容器;
160.提取子模块,用于提取所述第一备用容器的参数指标,并对所述参数指标进行归一化处理,得到标准参数指标;
161.设置子模块,用于根据所述故障服务节点的处理服务任务数据,确定所述故障服务节点对应用容器的指标需求,并基于所述指标需求,为所述标准参数指标设置不同的权重;
162.所述选择子模块,还用于根据所述不同的权重,计算所述第一备用容器的综合性能指数,并从所述第一备用容器中选取所述综合性能指数高于预设指数的第二备用容器;
163.确定子模块,用于根据所述故障服务节点的异常类型,确定所述异常类型对应的所述第二备用容器的接口;
164.生成子模块,用于基于所述故障服务节点的处理服务任务数据,确定所述接口的应用程序,并将所述应用程序接入所述接口上,生成接口日志;
165.检测子模块,用于利用预先建立的接口检测模型对所述接口日志进行检测,得到接口检测结果;
166.选择子模块,还用于选择所述接口检测结果与预期结果最匹配的接口对应的第二备用容器,作为目标容器。
167.在该实施例中,所述参数指标包括内存指标、节流指标、网络指标、磁盘指标等。
168.在该实施例中,所述指标需求,例如可以是所述处理服务任务数据的数据量较大,则对内存指标的需求就大一些。
169.在该实施例中,所述异常类型对应的接口,例如可以是链路连通异常对应连接接口,整体节点异常对应节点输入接口,节点内部逻辑异常对应子节点输入接口。
170.在该实施例中,所述应用程序使得所述处理服务任务数据接入所述接口。
171.在该实施例中,所述所述接口日志为所述接口执行所述处理服务任务数据时的各种执行情况记录,例如执行时间、执行结果等。
172.上述设计方案的有益效果是:通过根据所述故障服务节点的处理服务任务数据、备用容器的性能、故障容器的型号类型方面,从备用容器集合中选择最优的目标容器,加入到容器集群中,为容器集群的长时间运行提供了保障。
173.实施例10
174.基于实施例3的基础上,本发明实施例提供一种应用容器高可用负载平台,所述节点检测单元,包括:
175.预测子单元,用于获取所述容器集群中所有服务节点的历史状态信息,并基于所述历史状态信息预测每个服务节点的第一故障概率;
176.第一计算子单元,用于每隔预设时间检测所述的每个服务节点与相邻服务节点之间的状态信息,并基于在本次检测中的状态信息,计算每个服务节点在本次检测中的第二故障概率;
177.其计算公式如下:
[0178][0179]
其中,δ0表示当前服务节点在本次检测中的第二故障概率,q0表示当前服务节点的第一故障概率,n表示与当前服务节点相邻的相邻服务节点的个数,τ
0i
表示当前服务节点与第i个相邻服务节点的之间的状态的关系值,若两者状态相同,关系值取值为1,否则,关系值取值为0,qi表示第i个相邻服务节点的第一故障概率,θ表示服务节点检测的检测精度,取值为(0.5,1);
[0180]
第二计算子单元,用于获取在多次检测中的当前服务节点的第二故障概率,并计算对当前服务节点检测的可信度;
[0181]
其计算公式如下:
[0182][0183]
其中,p表示对所述当前服务节点检测的可信度,m表示对所述当前服务节点检测的次数,δj表示当前服务节点在第j次检测中的第二故障概率,δ
j+1
当前服务节点在第j+1次检测中的第二故障概率,σ表示检测当前服务节点隔预设时间的误差,取值为(0.10,0.40);
[0184]
节点确定子单元,用于当所述当前服务节点检测的可信度大于预设可信度时,判断所有检测次数中第二故障概率大于预设故障概率的次数,若所述次数大于预设次数,则判定当前服务节点为故障服务节点。
[0185]
在该实施例中,所述第一故障概率类似于先验故障概率,第二故障概率类似于后验故障概率。
[0186]
在该实施例中,若当前服务节点与第i个相邻服务节点的状态例如都是信息传输,则关系值为1,若一个为信息传输,另一个为信息处理,则关系值为0。
[0187]
在该实施例中,所述服务节点检测的检测精度与检测时的时间间隔以及检测状态时的精度相关。
[0188]
在该实施例中,对于来说,例如可以是q0=0.98,qi=0.12,τ
0i
=1,θ=0.9,n=10,则=1,θ=0.9,n=10,则最终,δ0=0.50。
[0189]
在该实施例中,δj与δ
j+1
的差值越小,表明每隔预设时间得到的第二故障概率类越接近,其可信度就越高。
[0190]
在该实施例中,对于来说,例如可以是δj=0.50,δ
j+1
=0.60,σ=0.20,最终p=9.1。
[0191]
在该实施例中,若预设可信度为9.0,则基于以上得出的p=9.1满足可信度要求,且q0=0.98满足预设故障概率为0.9的要求,且次数也满足要求时,判定当前服务节点为故障服务节点。
[0192]
上述设计方案的有益效果是:通过多次检测服务节点,确定服务节点的故障概率,然后,根据多次检测的结果,确定服务节点出现故障的可信度,从故障概率和可信度两个方面保证了检测出出现故障服务节点的准确性,便于及时更换备用容器,保证容器集群的高可用性。
[0193]
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1