一种风洞故障文本知识的实体关系抽取方法
:
1.本发明涉及风洞故障诊断及实体关系抽取技术领域,特别是一种风洞故障文本知识的实体关系抽取方法,是基于双向门控循环网络(bidirectional gate recurrent unit,缩写为bigru)和多头注意力机制(multi-head attention)的风洞故障知识的实体关系抽取方法。
背景技术:
2.风洞是研究飞行器空气动力学特征的重要试验设备,其健康状态对试验结果可靠性及试验人员安全性至关重要。风洞的设计、制造、使用、维修等部门在长期的生产实践过程中累积了大量的故障相关文本知识,对风洞设备的健康状态监测及故障诊断极具利用价值。
3.目前这些文本知识通常以非结构化的形式存储,不利于计算机处理和理解,仅由人工查阅分析,耗费人力,且存在着严重的故障知识无法高效复用的问题。
4.关系抽取作为知识抽取的主要任务之一,其目的是从非结构化文本中抽取实体之间显式或隐式的语义关联,解决关系分类问题。最终将文本知识转化成计算机能够处理的三元组数据。
5.目前,实体关系抽取在问答系统、信息检索、机器翻译等多种自然语言处理任务中都发挥着重要作用。然而与新闻、旅游等常见公共领域的知识抽取任务相比,故障知识抽取目前尚不存在大规模的成熟语料,致使其他领域的关系抽取算法较难在故障关系抽取任务中表现出良好效果。且风洞故障知识中存在大量专业术语,关系抽取难度较大。目前尚未有针对风洞故障文本知识的关系抽取的方法。
6.目前常见的关系抽取方法包括基于模式的方法,统计方法和最新的神经网络模型,但在实际应用过程中,基于模式的方法和统计方法存在需要大量人工干预、抽取效率低等缺点。神经网络关系提取模型能够自动提取语义特征,有效地获取文本信息,是目前研究的热点。
7.在基于神经网络的关系抽取方法中,文本可以直观地被表示为序列数据。recurrent neural network(rnn)是一类用于处理序列数据的神经网络,在自然语言处理任务中有较好的应用。但在文本中有用信息距离当前处理信息较远时,传统rnn易产生梯度消失或梯度爆炸。针对这一现象,研究者对传统rnn进行改进,提出长短期记忆网络(lstm)。此后,有研究者又将lstm改进为bilstm,并将其用于关系分类。但lstm具有训练时间长、参数较多、内部计算复杂的缺陷。针对这一问题,结构更加简单的gru模型被提出,gru保持了lstm效果,且具有更加简单的结构、更少的参数、更好的收敛性。
8.近年来,注意力机制也成功应用到关系分类任务中,取得了较好的效果。其中,多头注意力机制允许模型在不同的表示子空间里学习相关信息,克服单头注意机制直接取平均可能导致某些重要信息被掩盖的弊端。
9.目前市场需要一种风洞故障文本知识的实体关系抽取方法,通过从风洞故障文本
中抽取知识,实现非结构化故障数据向结构化数据的转化,提高文本知识在风洞健康监测及故障诊断过程中的利用效率。
技术实现要素:
10.本发明的目的在于提出一种风洞故障文本知识的实体关系抽取方法,针对当前风洞故障文本知识通常以非结构化的形式存储,不利于计算机处理和理解,无法高效复用的问题,提出了一种有效的风洞故障实体关系抽取方法,具体是公开一种基于双向gru网络(bigru)和多头注意力机制(multi-head attention)的风洞故障知识的实体关系抽取方法。
11.本发明的目的是以如下技术方案来实施的:
12.一种风洞故障文本知识的实体关系抽取方法,该方法基于双向gru网络(bigru)和多头注意力机制(multi-head attention),具体步骤如下:
13.步骤一、根据知识抽取的目的,对风洞故障知识结构进行定义;
14.步骤二、风动故障文本训练集和风动故障文本测试集:选取部分风洞故障知识文本,划分为训练集和测试集;
15.步骤三、实体标注:对训练集进行实体标注一和测试集进行实体标注二;
16.步骤四、关系标注:对训练集进行关系标注一和测试集进行关系标注二;
17.步骤五、训练集预处理和测试集预处理:对标注好的训练集和测试集文本知识进行预处理;
18.步骤六、词嵌入:将预处理后的训练集输入关系抽取模型的词嵌入(embedding)层,训练词向量,得到词嵌入矩阵;
19.步骤七、文字级特征提取:将训练集的词嵌入矩阵输入关系抽取模型的双向gru网络层,提取文字级特征向量;
20.步骤八、句子级特征提取:将文字级特征向量集合输入关系抽取模型的多头注意力层,生成权重向量,将文字级特征向量权重向量相乘,得到句子级特征;
21.步骤九、关系分类:将句子级特征向量输入关系抽取模型的输出层,得到关系类别。
22.步骤十、模型迭代训练:对关系抽取模型进行迭代训练。
23.步骤十一、模型测试:使用测试集预处理的词嵌入数据对训练好的关系抽取模型进行测试,并评估测试结果,得到最终的关系抽取模型。
24.进一步的,步骤五所述的训练集预处理和测试集预处理具体如下:
25.(1)根据实体标注结果,将文本进行语句切分;
26.(2)将训练集整理为“实体1实体2关系句子”的形式,其中句子需要包含实体1和实体2;
27.(3)将测试集整理为“实体1实体2句子”的形式,其中句子需要包含实体1和实体2。
28.由于采取了以上技术方案,本发明的一种风洞故障文本知识的实体关系抽取方法与现有技术相比,具有如下优点与积极效果:
29.(1)本发明所提出的风洞故障文本实体关系抽取方法,能够有效挖掘风洞故障文本实体之间的关联关系,进而将非结构化的风洞故障文本知识转化成计算机能够处理的“实体-关系-实体”三元组数据,从而实现非结构化风洞故障文本知识的结构化存储。
30.(2)本发明基于bigru构建关系抽取模型,bigru可以从正反两个方向学习上下文特征,较好地捕捉双向的长距离语义依赖关系,其采用的gru网络单元相较于传统循环神经网络单元和lstm单元来说,参数更少,不易产生过拟合,具有更高的关系抽取精度。
31.(3)本发明在关系模型构建中引入multi-head attention机制,能够允许模型在不同的位置关注来自不同表征子空间的信息,克服了单头注意力机制可能导致某些重要信息被掩盖的弊端,具有更高的关系抽取精度。
32.附图简要说明
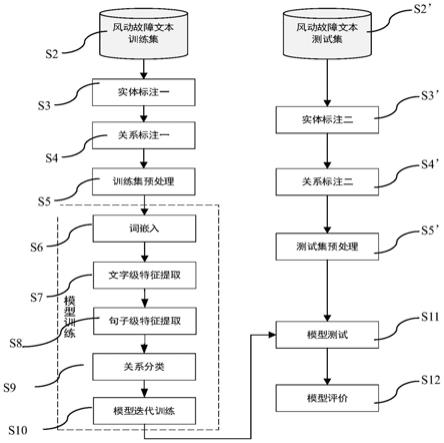
33.图1为本发明风洞故障文本关系抽取方法流程图,
34.图2为本发明步骤五的分步骤流程图,
35.图3为本发明基于bigru和多头注意力机制的关系抽取模型架构图,
36.图4为本发明实体标注及关系标注示意图。
具体实施方式
37.为了方便理解本发明所提出的风洞故障文本关系抽取方法,以下结合附图,通过具体实施例对本发明进行详细说明,以下的说明不以任何方式限制本发明的权利要求的范围。
38.图1为本发明风洞故障文本关系抽取方法流程图,如图1所示。
39.该方法具体步骤如下:
40.步骤一、利用专家知识对风洞设备故障知识文本进行分析,确定风洞故障文本中可能存在的实体类型和关系类型,定义风洞故障知识结构;
41.步骤二、风洞故障文本训练集s2和风洞故障文本测试集s2’:选取部分风洞故障知识文本,划分为训练集和测试集,划分比例为8:2;
42.步骤三、实体标注一s3和实体标注二s3’:利用标注工具分别对训练集和测试集进行实体标注;
43.步骤四、关系标注一s4和关系标注二s4’:利用标注工具对训练集和测试集进行关系标注,其中训练集的关系标签用于关系抽取模型的训练,测试集的关系标签用于关系抽取模型的评价;
44.步骤五、训练集预处理s5和测试集预处理s5’:对标注好的训练集和测试集文本进行预处理。预处理方法为:
45.s51:以句号、问号、感叹号为标识符对文本进行语句切分,切分后的每个自然句中实体个数须大于等于2,否则对相邻自然句进行拼接;
46.s52:将训练集整理为“实体1实体2关系句子”的四元素拼接形式,元素间以空格为标识,其中句子元素需要包含实体1和实体2;
47.s53:将测试集整理为“实体1实体2句子”的三元素形式,元素间以空格为标识,其中句子元素需要包含实体1和实体2。
48.图3为本发明基于bigru和多头注意力机制的关系抽取模型架构图,图中:input layer为模型的输入层,输入预处理后的故障文本;embedding layer为词嵌入层;bigru layer为双向gru层;atention layer为多头注意力层;output layer为输出层,输出关系标
签。
49.步骤六、词嵌入s6:将预处理后的训练集输入关系抽取模型的embedding层,训练词向量,得到词嵌入矩阵:
50.对于一个至少包含两个实体的句子s={x1,x2,
…
,x
t
},使用word2vec将每一个字xi转换为实数向量ei。对于s中的每一个字来说,首先存在一个向量矩阵w
wrd
,可以将xi转化为其向量的表示:
51.ei=w
wrd
viꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
52.其中,vi是一个大小为|v|的one-hot向量,在下标为ei处为1,其他位置为0。于是,句子s将被转化为一个实数矩阵:es={e1,e2,...,e
t
},并传递给模型的下一层。
53.基于bigru和多头注意力机制的关系抽取模型架构如图3所示。
54.步骤七、文字级特征提取s7:将训练集的词嵌入矩阵es输入关系抽取模型的双向gru网络层,利用前向gru层和后向gru层分别计算字向量的前文信息与后文信息,得到包含前后文信息的文字级特征向量;
55.本发明中使用的bigru模型接收每个句子的向量表示,得到句子中每个字对应的隐藏状态作为输出。gru是lstm网络的一种变体,同样可以解决rnn网络中的长期依赖问题。它较lstm网络具有更加简单的结构、更少的参数。gru cell由更新门和重置门两个门组成。更新门用于控制前一时刻的状态信息被带入到当前状态中的程度,重置门用于控制忽略前一时刻的状态信息的程度。bigru的原理如下:
56.(1)对于每个gru单元,给定字向量ei和上一文字隐藏状态h
i-1
,重置门r
t
和更新门z
t
的计算如下:
57.r
t
=σ(eiw
er
+h
i-1whr
+br)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
58.z
t
=σ(eiw
ez
+h
i-1whz
+bz)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
59.其中w
er
,w
ez
和w
hr
,w
hz
是权重矩阵,br,bz是偏置项。σ代表激活函数sigmoid函数。
60.sigmoid函数可以将元素的值变换到0和1之间。因此,ri和i的值域都是[0,1]。如果ri的值接近0,则意味着重置对应隐藏状态的值为0,即丢弃上一字向量的隐藏状态。如果ri值接近1,则表示保留上一个字向量的隐藏状态。
[0061]
(2)计算候选隐藏状态,为隐藏状态的计算提供辅助。给定字向量ei的候选隐藏状态的计算公式为:
[0062][0063]
其中w
eh
和w
hh
是权重矩阵,bh是偏置项,tanh为激活函数,
⊙
denotes the element-wise multiplication
[0064]
(3)输出,字向量ei的隐藏状态hi的计算使用当前的更新门z
t
来对上一时间步的隐藏状态h
i-1
和当前候选隐藏状态做组合:
[0065][0066]
由于文本信息是按照从前往后依次传播,gru只能依据前文信息来学习当前文字的特征,但在关系抽取任务中,当前文字与下文也存在语义联系。本发明使用bidirectional gru从正反两个方向进行学习,实现上下文信息的融合。利用bigru处理句子s时,第i个字的输出如式:
[0067][0068]
步骤八、句子级特征提取s8:将bigru层输出的文字级特征向量集合输入关系抽取模型的多头注意力(multi-head attention)层,生成权重向量。将文字级特征向量权重向量相乘,得到句子级特征;
[0069]
具体地,将bigru层的输出向量集合表示为h
′
={h
′1,h
′2,...,h
′i},multi-head attention层处理h
′
的步骤如公式(7)-(11)所示:
[0070]
m=tanh(h
′
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(7)
[0071]
α=softmax(wim)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(8)
[0072]e′
=h
′
α
t
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(9)
[0073]
r=tanh(e
′
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(10)
[0074]r′
=concat(r1,r2,...,rn)
⊙
wrꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(11)
[0075]
以上公式中,α表示注意力权重矩阵,wi,wr是训练所得的参数矩阵,α
t
是α的transpose,e
′
表示完成加权变换后所得的句子向量,r表示单一注意力头得到的输出特征,假设一共进行n次注意力计算,concat表示向量拼接,最终得到的输出为r
′
。
[0076]
步骤九、关系类别s9:将句子级特征向量输入关系抽取模型的输出层,得到关系类别。
[0077]
具体地,本发明使用softmax分类器作为模型输出层,用于预测关系标签。该分类器将注意力层得到的r
′
作为输入,计算过程如下:
[0078]
p(y|r
′
)=softmax(w
pr′
)+b
p
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(12)
[0079][0080]
其中,是概率最大的关系类别,即模型输出。w
p
是训练所得的参数矩阵,b
p
是偏置项。
[0081]
步骤十、模型迭代训练s10:对关系抽取模型进行迭代训练。
[0082]
为了优化模型,迭代训练过程中本发明采用带有l2惩罚项的cross entropy损失作为目标函数,如式(14):
[0083][0084]
其中,θ为模型参数,m为样本数,t
l
是正样本的one-hot表示,y
l
是softmax计算出的每个关系类别的概率,λ是l2正则化超参数。
[0085]
步骤十一、模型测试s11:使用测试集预处理的词嵌入数据对训练好的关系抽取模型进行测试,并评估测试结果,得到最终的关系抽取模型。
[0086]
本发明测试结果评价采用准确率(p)、召回率(r)以及f值(f)作为评价指标,计算公式如下:
[0087][0088][0089]
[0090]
其中,tp表示混淆矩阵中的true positive,fp表示false positive,fn表示false negative.
[0091]
实施例
[0092]
1.试验数据及知识定义
[0093]
本案例使用的数据来自风洞实际运行过程中的专家经验知识。将该文档中部分语料划分为训练集和测试集,用于关系抽取模型的训练和测试。该文档部分内容如下:
[0094][0095]
故障知识的价值在于能够有效辅助现场人员分析故障致因,并能够给出故障处理意见。风洞设备故障知识抽取以抽取故障致因和处理方法为目的。根据对故障文本的分析,定义风洞故障知识结构如表1。训练数据与测试数据具有相同的故障知识定义。
[0096]
表1风洞故障知识定义
[0097][0098][0099]
2.数据处理
[0100]
图2为本发明的实体标注及关系标注示意图,利用标注工具brat对训练集和测试集进行实体标注和关系标注,部分标注结果如图4所示:
[0101]
对标注好的训练集和测试集文本进行预处理,处理后的训练集和测试集部分语料如表2所示。
[0102]
表2预处理后的训练集与测试集部分语料
head attention机制后,bigru+multi-head-att的召回率与bigru+att相比明显提高,说明所提方法方法能够关注到更多的信息。
[0115]
综上,本发明所提出的基于bigru和多头注意力机制的关系抽取方法能够有效提取风洞故障文本中的实体关系,进而,可将风洞故障知识文本构建为“实体1-关系-实体2”的三元组数据,实现非结构化数据向结构化数据的转化及在计算机中的有效存储,提高了文本知识在风洞健康监测及故障诊断过程中的利用效率。
[0116]
基于双向gru网络和多头注意力机制的关系抽取模型能够关注来自不同表征子空间的信息,较好地捕捉语义依赖关系,克服了单头注意力机制可能导致某些重要信息被掩盖的弊端,与bigru+att、bigru及bilstm相比,具有更高的关系抽取精度。
[0117]
需要注意的是,本技术公布实施例的目的在于帮助进一步理解本发明,但是本领域的技术人员可以理解:在不脱离本发明及所附权利要求的精神和范围内,各种替换和修改都是可能的。因此,本发明不应局限于实施例所公开的内容,本发明要求保护的范围以权利要求书界定的范围为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1