用于人工神经网络的存储器控制器、处理器和系统的制作方法
1.本公开涉及人工神经网络,更具体地,涉及用于人工神经网络的存储器控制器、处理器和人工神经网络的系统。
背景技术:
2.随着人工智能推理能力的发展,例如声音识别、语音识别、图像识别、物体检测、驾驶员睡意检测、危险时刻检测和手势检测之类的各种推理服务被搭载各种电子设备中。具有推理服务的电子设备可以包括例如人工智能扬声器、智能手机、智能冰箱、vr设备、ar设备、人工智能闭路电视、以及人工智能(ai)机器人清洁器、平板电脑、笔记本电脑、自动驾驶汽车、双足机器人、四足机器人和工业机器人之类的设备。
3.最近,随着深度学习技术的发展,基于大数据学习的人工神经网络推理服务的性能得到了发展。人工神经网络的学习和推理服务以海量的学习数据反复训练人工神经网络,并借助训练好的人工神经网络模型对各种复杂的数据进行推理。因此,通过利用人工神经网络技术向上述电子设备提供各种服务。
4.然而,利用人工神经网络的推理服务所需的功能和精度正在逐渐增加。相应地,人工神经网络模型的大小、计算量和学习数据的大小呈指数增长。能够处理人工神经网络模型的推理操作的处理器和存储器所需的性能逐渐提高。此外,人工神经网络推理服务被主动提供给基于云计算的可以轻松处理大数据的服务器。
5.同时,正在积极研究利用人工神经网络模型技术的边缘计算。边缘计算是指进行计算的边缘或外围部分。因此,边缘计算是指直接产生数据的终端或与终端相邻的各种电子设备,并且也可以称为边缘设备。边缘设备可用于立即可靠地执行必要的任务,例如需要在1/100秒内处理大量数据的自动无人机、自动机器人或自动车辆的那些。因此,边缘设备适用于数量正在迅速增加的领域。
技术实现要素:
6.本公开的发明人已经认识到,传统的人工神经网络模型的操作存在功耗高、发热、以及由存储器带宽较低和存储器延迟导致的处理器操作的瓶颈现象等问题。因此,发明人还认识到提高人工神经网络模型的操作处理性能存在各种困难,以及需要开发一种能够改善这些问题的人工神经网络存储器系统。
7.因此,本公开的发明人研究了一种适用于服务器系统和/或边缘计算的人工神经网络(ann)存储器系统。此外,本公开的发明人还研究了一种神经处理单元(npu),其是为处理人工神经网络(ann)模型而优化的ann存储器系统的处理器。
8.首先,本公开的发明人认识到,为了提高人工神经网络的计算处理速度,关键是在人工神经网络模型的计算过程中有效控制存储器。本公开的发明人已经认识到,当人工神经网络模型被训练或推理时,如果没有适当地控制存储器,则没有提前准备必要的数据,从而存储器有效带宽的降低和/或存储器的数据的供应延迟可能经常发生。进一步地,本公开
的发明人已经认识到,在这种情况下,会造成没有向处理器提供待处理数据的饥饿(starvation)或空闲(idle)状态,使得无法执行实际操作,从而导致操作性能的下降。
9.其次,本公开的发明人已经认识到人工神经网络模型的操作处理方法在已知技术的算法层面上的局限性。例如,已知预取算法是一种以概念层单元分析人工神经网络模型以便处理器以每一层单元从存储器读取数据的技术。然而,预取算法无法识别存在于处理器-存储器级别(即硬件级别)的人工神经网络模型的字单元或存储器访问请求单元中的人工神经网络数据局部性。本公开的发明人已经认识到,仅通过预取技术难以在处理器-存储器级别优化数据发送/接收操作。
10.第三,本公开的发明人已经认识到“人工神经网络数据局部性”,其是人工神经网络模型的独特特征。本公开的发明人已经认识到在处理器-存储器级别的字单元或存储器访问请求单元中存在人工神经网络数据局部性,并且有效存储器带宽被最大化并且提供给处理器的数据的延迟通过利用人工神经网络数据局部性最小化,从而提高处理器的人工神经网络学习/推理操作处理性能。
11.具体地,本公开的发明人所认知的人工神经网络模型的“人工神经网络数据局部性”是指处理器对人工神经网络进行计算处理所需的数据的字单元的序列(sequence)信息,其是在处理器处理特定的人工神经网络模型时,按照人工神经网络模型的结构和操作算法执行。此外,本公开的发明人已经认识到,在人工神经网络模型的操作处理序列中,为被提供给处理器的人工神经网络模型的迭代学习和/或推理的操作保持人工神经网络数据局部性。相应地,本公开的发明人认识到,在保持人工神经网络数据局部性时,处理器处理的人工神经网络操作所需的数据的处理序列保持在字单元中,并且提供或分析待用于人工神经网络操作的信息。换言之,处理器的字单元可以指作为待由处理器处理的基本单元的元件单元。例如,当神经处理单元处理n位输入数据与m位核权重相乘时,处理器的输入数据字单元可以是n位,并且权重数据的字单元可以是m位。此外,本公开的发明人已经认识到,处理器的字单元可以根据人工神经网络模型的层、特征图、内核(kernel)、激活函数等分别设置为不同的。相应地,本公开的发明人也认识到精确的存储器控制技术对于以字单元进行的操作是必要的。
12.本公开的发明人注意到,当人工神经网络模型由编译器编译以在特定处理器中执行时,人工神经网络数据局部性被构建。此外,发明人已经认识到可以根据应用于编译器和人工神经网络模型以及处理器的架构的算法的操作特性来构建人工神经网络数据局部性。另外,本公开的发明人已经认识到,即使在相同的人工神经网络模型中,待处理的人工神经网络模型的人工神经网络数据局部性也可以以各种形式构建,具体取决于处理器的人工神经网络模型的计算方法,例如特征图平铺,处理元件的平稳技术,处理器的处理元件数量,处理器中的特征图,例如权重之类的高速缓冲存储器容量,处理器中的存储器分层结构,或者确定处理器的计算操作的序列以计算人工神经网络模型的编译器的算法特征。这是因为即使计算相同的人工神经网络模型,由于上述因素,处理器也会确定时钟单元中每个时刻所需的数据序列是不同的。也就是说,本公开的发明人已经认识到,人工神经网络模型的计算所必需的数据的序列在概念上是人工神经网络的层、单元卷积和/或矩阵乘法的计算序列。而且,本公开的发明人已经认识到,在物理计算所需的数据序列中,人工神经网络模型的人工神经网络数据局部性是在处理器-存储器级别(即硬件级别)以字单元构建的。此外,
本公开的发明人已经认识到人工神经网络数据局部性取决于处理器和用于处理器的编译器。
13.第四,本公开的发明人已经认识到,当提供被构造成被提供人工神经网络数据局部性信息以利用人工神经网络数据局部性的人工神经网络存储器系统时,人工神经网络模型的处理性能可以在处理器-存储器级别最大化。
14.本公开的发明人认识到,当人工神经网络存储器系统精确地计算出人工神经网络模型的人工神经网络数据局部性的字单元时,处理器还发现该字单元的操作处理序列信息,该字单元是处理器处理人工神经网络模型的最小单元。也就是说,本公开的发明人已经认识到,当提供利用人工神经网络数据局部性的人工神经网络存储器系统时,人工神经网络存储器系统可以精确地预测是否在特定时间从存储器中读取特定数据以将特定数据提供给处理器或特定数据是否要由处理器计算以在特定时间以字单元将特定数据存储在存储器中。因此,本公开的发明人已经认识到,提供人工神经网络系统以预先准备待由处理器以字单元请求的数据。
15.换句话说,本公开的发明人已经认识到,如果人工神经网络存储器系统知道人工神经网络数据局部性,则当处理器使用诸如特征图平铺之类的技术计算特定输入数据和特定内核的卷积时,在内核向特定方向移动时所处理的卷积的操作处理序列在字单元中也是已知的。
16.也就是说,认识到,人工神经网络存储器系统通过利用人工神经网络数据局部性来预测哪些数据对于处理器是必要的,从而预测待由处理器请求的存储器读/写入操作,并且待由处理器处理的数据是预先准备好的,以最小化或消除存储器有效带宽的增加和/或存储器的数据供应延迟。此外,发明人已经认识到,当人工神经网络存储器系统提供待由处理器以必要的时序处理的数据时,可以最小化处理器的饥饿或空闲状态。因此,本公开的发明人已经认识到通过人工神经网络存储器系统可以提高操作处理性能并且可以降低功耗。
17.第五,本公开的发明人已经认识到,即使可能没有向人工神经网络存储器控制器提供人工神经网络数据局部性信息,也在将人工神经网络存储器控制器设置在对人工神经网络模型进行处理的处理器和存储器之间的通信通道中之后,当处理器处理特定人工神经网络模型的操作时,分析对存储器的数据访问请求,以推理在处理器和存储器之间的数据访问请求单元中正在被处理器处理的人工神经网络模型的人工神经网络数据局部性。也就是说,本公开的发明人已经认识到每个人工神经网络模型都具有唯一的人工神经网络数据局部性,从而处理器在处理器-存储器级别根据人工神经网络数据局部性产生特定序列的数据访问请求。此外,本公开的发明人已经认识到,存储器中存储的数据的访问队列用于处理器和存储器之间的数据请求是基于在处理器迭代地处理人工神经网络模型的学习/推理操作的同时保持人工神经网络数据局部性。
18.因此,本公开的发明人将人工神经网络存储器控制器设置在操作人工神经网络模型和存储器的处理器的通信通道中。进一步地,发明人观察处理器和存储器之间的数据访问请求以进行一个或多个学习和推理操作,而认识到人工神经网络存储器控制器可以推理数据访问请求单元中的人工神经网络数据局部性。因此,本公开的发明人已经认识到,即使没有提供人工神经网络数据局部性信息,人工神经网络数据局部性也可以由人工神经网络存储器控制器推理。
19.因此,本公开的发明人已经认识到,基于在数据访问请求单元中重构的人工神经网络数据局部性,待由处理器请求的存储器读/写入操作可以被预测,并且可以通过预先准备要由处理器处理的数据,最小化或基本消除存储器有效带宽的增加和/或存储器数据供应的延迟。进一步地,本公开的发明人已经认识到,当人工神经网络存储器系统以必要的时序提供待由处理器处理的数据时,可以最小化处理器的饥饿或空闲状态发生率。
20.因此,本公开要实现的目的是提供一种人工神经网络(ann)存储器系统,该系统通过利用在处理器-存储器级别操作的人工神经网络(ann)模型的人工神经网络(ann)数据局部性来优化处理器的人工神经网络操作。
21.因此,本发明要解决的问题是提供一种人工神经网络存储器系统,其包括人工神经网络存储器控制器,能够通过经由(1)分析由处理器产生的多个数据访问请求和(2)由处理器正在处理的人工神经网络模型的数据局部性模式预先准备将被处理器请求的数据访问请求来减少存储器的延迟。然而,本公开不限于此,本领域技术人员将从以下描述清楚地理解其他问题。
22.根据本公开的一个示例,提供了一种系统。系统包括:处理器,其被配置为输出包括人工神经网络数据局部性的存储器控制信号;以及存储器控制器,其被配置为从所述处理器接收所述存储器控制信号并且控制主存储器,在所述主存储器中存储与所述人工神经网络数据局部性相对应的人工神经网络模型的数据。
23.所述存储器控制器可以被配置为基于所述存储器控制信号控制人工神经网络操作所需的所述主存储器的数据的读取或写入操作。
24.所述存储器控制信号可以包括人工神经网络操作、操作模式、操作类型、域、量化、人工神经网络模型数量和多线程中的至少一种控制信号。
25.所述存储器控制器可以被配置为直接控制所述主存储器的物理地址,使得所述主存储器基于所述人工神经网络数据局部性以顺序突发模式操作。
26.所述存储器控制器被配置为确定是否刷新所述主存储器中存储的所述人工神经网络模型的与所述人工神经网络数据局部性对应的所述数据。
27.所述主存储器还包括多个存储体,所述人工神经网络模型被分布和存储在所述多个存储体中。所述主存储器被配置为基于所述人工神经网络数据局部性控制所述多个存储体的预充电时序中的每一个。
28.所述存储器控制器可以被配置成通过比较所述人工神经网络模型的与所述人工神经网络数据局部性对应的计算处理时间与所述主存储器的刷新阈值时间来停用所述主存储器的刷新操作。
29.所述存储器控制器可以被配置为基于所述存储器控制信号的域信号来控制存储在所述主存储器中的所述人工神经网络模型的与特定域对应的数据的刷新。
30.根据本公开的一个示例,提供了一种处理器。处理器可以被配置为生成存储器控制信号,所述存储器控制信号被配置为基于人工神经网络数据局部性来控制存储人工神经网络模型的数据的主存储器。
31.所述人工神经网络数据局部性可以是由编译器生成的信息。
32.所述存储器控制器可以被配置为基于所述存储器控制信号的域来禁止存储在所述主存储器中的内核数据的刷新。
33.所述存储器控制器可以被配置为基于所述存储器控制信号的域来禁止存储在所述主存储器中的特征图数据的刷新。
34.所述存储器控制器可以被配置成基于人工神经网络数据局部性通过测量相应的人工神经网络模型的推理处理时间来控制存储在所述主存储器中的所述人工神经网络模型的所述数据的刷新。
35.可以基于所述人工神经网络数据局部性确定所述主存储器的存储器映射。
36.根据本公开的一示例,提供了一种存储器控制器。存储器控制器可以被配置为从被配置为处理人工神经网络模型的处理器接收与所述人工神经网络模型对应的人工神经网络数据局部性的当前处理步骤。
37.所述存储器控制器可以包括高速缓冲存储器。所述存储器控制器可以被配置为基于当前处理步骤把将由所述处理器从所述主存储器请求的至少一个后续处理步骤的数据存储到所述高速缓冲存储器。
38.所述人工神经网络数据局部性可以被包括在由所述处理器生成的存储器控制信号中。
39.所述处理器可以被配置为生成包括多线程信息的存储器控制信号,并且基于所述多线程信息设置所述主存储器的存储器映射。
40.所述处理器可以被配置为生成还包括人工神经网络模型数量信息的存储器控制信号,并且基于所述人工神经网络模型数量信息设置所述主存储器的存储器映射。
41.所述处理器可以被配置为生成包括多线程信息的存储器控制信号,并且基于所述多线程信息设置将被共同使用的内核数据的存储器映射。
42.所述处理器可以被配置为生成还包括多线程信息的存储器控制信号,并且基于所述多线程信息设置将被独立使用的特征图数据的存储器映射。
43.根据本公开的示例,在处理人工神经网络的系统中,可以通过人工神经网络数据局部性基本上消除或减少存储器向处理器提供数据的延迟。
44.根据本公开的示例,人工神经网络存储器控制器可以准备在被处理器请求之前在处理器-存储器级别进行处理的人工神经网络模型的数据。
45.根据本公开的示例,缩短了由处理器处理的人工神经网络模型的学习和推理操作处理时间,以提高处理器的操作处理性能,并提高系统级别的操作处理的功率效率。
46.根据本公开的效果不限于以上举例说明的内容,并且本说明书中包括更多的各种效果。
附图说明
47.图1a是根据本公开的示例的人工神经网络存储器系统的示意性框图。
48.图1b是图示用于解释可应用于本公开的各种示例的人工神经网络数据局部性模式的重构的示例性神经处理单元的示意图。
49.图2是根据本公开的示例用于解释人工神经网络数据局部性模式的示图。
50.图3是图示用于解释可应用于本公开的各种示例的人工神经网络数据局部性模式的示例性人工神经网络模型的示意图。
51.图4是根据本公开的示例用于解释通过人工神经网络存储器控制器经由分析图3
的人工神经网络模型而产生的人工神经网络数据局部性模式的示意图。
52.图5是解释与图4的人工神经网络数据局部性模式对应的令牌和识别信息的示图。
53.图6是根据本公开的示例用于解释通过人工神经网络存储器控制器基于人工神经网络数据局部性模式生成的预测的数据访问请求和后续的数据访问请求的示图。
54.图7是根据本公开的示例的人工神经网络存储器控制器的操作的流程图。
55.图8是根据本公开的另一示例的人工神经网络存储器系统的示意性框图。
56.图9是根据本公开的比较实施方案的存储器系统的操作的示意图。
57.图10是图8的存储器系统的操作的示意图。
58.图11是根据本公开的又一示例的人工神经网络存储器系统的示意性框图。
59.图12是数据访问请求的示例性识别信息的示图。
60.图13是用于解释人工神经网络存储器系统的每单元操作的能量消耗的示图。
61.图14是根据本公开的各种示例用于解释人工神经网络存储器系统的示意图。
62.图15是示出基板和安装有存储器的通道的示例图。
63.图16是图示从多存储体结构的存储器读取数据的过程的示例图。
64.图17是图示在传统dram中发生的延迟的示例图。
65.图18是示出根据本公开的顺序访问存储器(sam)的基本构思的示例图。
66.图19是示例性地示出了16层的计算量和数据大小的表。
67.图20是示例性地示出了28层的计算量和数据大小的表。
68.图21是示出根据人工神经网络数据局部性(ann dl)信息中的序列信息来访问存储器的第一示例的表。
69.图22是以简化的方式示出图21的表的示例表。
70.图23示出了sam根据图22的表设置存储器地址映射的示例。
71.图24是示出根据ann dl信息中的序列信息访问存储器的第二示例的表。
72.图25示出了sam根据图24的表设置存储器地址映射的示例。
73.图26是示出根据ann dl信息中的序列信息访问存储器的第三示例的表。
74.图27a和27b示出了根据ann dl信息设置存储器地址映射的示例。
75.图28是图示sam控制器的控制信号的概念图。
76.图29是图示根据图28的边带信号设置存储器地址映射的示例的示例图。
77.图30a示出了根据边带信号设置存储器地址映射的示例,图30b示出了其中仅内核被顺序设置的存储器地址映射的示例。
78.图31a是图示根据本公开的示例通过边带信号发送的read_discard命令的示例图,并且图31b示出了read命令的示例。
79.图32示出了根据本公开的示例以dram的存储器元件的形式实现的示例性sam的电路图的一部分。
80.图33是用于解释图32的sam电路图中的预充电操作的示例图。
81.图34是用于解释图32的sam电路图中的存储器元件访问操作的示例图。
82.图35是用于解释图32的sam电路图中的数据感测操作的示例图。
83.图36是用于解释图32的sam电路图中的read-discard操作的示例图。
84.图37是用于解释图32的sam电路图中的read操作的示例图。
85.图38a是read-discard操作的示例性波形图,图38b是read操作的示例性波形图。
86.图39是示出图21的表的一部分以解释refreash操作的表。
87.图40示出了根据本公开的示例以各种形式实现sam存储器的示例。
88.图41是图示基于ann dl信息映射主存储器的地址的方法的示例的示例图。
89.图42是图示基于ann dl信息映射主存储器的地址的方法的另一示例的示例图。
90.图43是示出根据ann dl信息中的序列信息访问存储器的示例的表。
91.图44是图示其中嵌入了sam控制器的存储器的示例的示例图。
92.图45是图示包括编译器的架构的示例图。
93.图46示出了根据第一示例的架构。
94.图47示出了根据第二示例的架构。
95.图48示出了根据第三示例的架构。
96.图49示出了根据第四示例的架构。
97.图50示出了根据第五示例的架构。
98.图51示出了根据第六示例的架构。
99.图52是图示根据图51中所示的第六示例的操作的示例图。
100.图53a和53b是示出卷积的示例的示例图。
101.图54示出了在将数据从主存储器高速缓存到高速缓存存储器之后基于平铺技术执行操作的另一示例。
102.图55是图示根据本公开的各种示例的人工神经网络存储器系统的示意图。
103.图56示出了图55的sfu的详细配置。
104.图57示出了测量缓冲存储器(高速缓存)和主存储器之间的数据总线的带宽的图。
具体实施方式
105.通过参考下面详细描述的各种示例以及附图,本公开的优点和特征以及实现这些优点和特征的方法将变得清楚。然而,本发明不限于这里公开的示例,而是将以各种形式实现。提供示例是为了使本发明能够被完整地公开并且本发明的范围能够被本领域技术人员容易地理解。因此,本发明将仅由所附权利要求的范围限定。
106.为了描述的方便,可以利用具体的示例参考附图来描述本公开的详细描述,通过具体示例可以作为示例实施本公开。尽管本公开的各种示例的部件彼此不同,但是在特定示例中描述的制造方法、操作方法、算法、形状、工艺、结构和特征可以与其他实施方案组合或包括在其他实施方案中。此外,应当理解,在不脱离本公开的精神和范围的情况下,可以改变每个公开的示例中的各个组成元件的位置或布置。本公开的各个实施方案的特征可以部分地或全部地彼此结合或组合,并且可以以本领域技术人员可以理解的技术上的各种方式互锁和操作,并且实施方案可以彼此独立地执行或者相互关联地执行。
107.在附图中示出的用于描述本公开的示例的形状、尺寸、比率、角度、数量等仅仅是示例,并且本公开不限于此。在整个说明书中,相同的附图标记表示相同的元件。此外,在以下描述中,会省略已知相关技术的详细解释以避免不必要地混淆本公开的主题。在此使用的诸如“包括”、“具有”和“由
……
组成”等术语通常旨在允许添加其他部件,除非这些术语与术语“仅”一起使用。除非另有明确说明,否则引用的任何单数都可以包括复数。即使没有
明确说明,部件也被解释为包括普通的误差范围。当两个元件的位置关系使用例如“在
……
上”、“在
……
上方”、“在
……
下”、“靠近”或“邻近”描述时,一个部件可以位于两个部件之间,除非这些术语是与术语“紧接”或“直接”一起使用,当元件或层设置在另一元件或层“上”时,另一层或另一元件可直接插入另一元件上或它们之间。
108.图1a是根据本公开的示例图示基于人工神经网络数据局部性的人工神经网络存储器系统100。
109.参考图1a,人工神经网络存储器系统100可以被配置为包括至少一个处理器110和至少一个人工神经网络存储器控制器120。也就是说,提供了根据本公开的示例的至少一个处理器110,并且可以使用多个处理器。同时提供根据本公开示例的至少一个人工神经网络存储器控制器120,且可以使用多个人工神经网络存储器控制器。
110.在下文中,为了描述方便,当至少一个处理器110仅包括一个处理器时,可以将其称为处理器110。
111.在下文中,为了描述方便,当至少一个人工神经网络存储器控制器120仅包括一个人工神经网络存储器控制器120时,可以将其称为人工神经网络存储器控制器120。
112.处理器110被配置为处理人工神经网络模型。例如,处理器110处理人工神经网络模型的推理,该人工神经网络模型被训练为执行特定推理功能以根据输入数据提供人工神经网络模型的推理结果。例如,处理器110处理用于执行特定推理功能的人工神经网络模型的学习以提供经过训练的人工神经网络模型。具体的推理功能可以包括可以由人工神经网络推理出的各种推理功能,如物体识别、语音识别、图像处理。
113.处理器110可以被配置为包括中央处理单元(cpu)、图形处理单元(gpu)、应用处理器(ap)、数字信号处理设备(dsp)、算术和逻辑单元(alu)以及人工神经处理单元(npu)中的至少一者。然而,本公开的处理器110不限于上述处理器。
114.处理器110可以被配置为与人工神经网络存储器控制器120通信。处理器110可以被配置为生成数据访问请求。数据访问请求可以被发送到人工神经网络存储器控制器120。这里,数据访问请求可以指访问处理器110处理人工神经网络模型的推理或学习所需的数据的请求。
115.处理器110可以向人工神经网络存储器控制器120发送数据访问请求以被提供来自人工神经网络存储器控制器120的人工神经网络模型的推理或学习所需的数据或向人工神经网络存储器控制器120提供由处理器110处理的人工神经网络的推理或学习结果。
116.处理器110可以提供通过处理特定人工神经网络模型获得的推理结果或学习结果。此时,处理器110可以被配置为以特定的序列处理人工神经网络的用于推理或学习的操作。
117.处理器110之所以需要以特定的序列处理人工神经网络的操作,是因为每个人工神经网络模型都被配置为具有独特的人工神经网络结构。即,每个人工神经网络模型被配置为根据独特的人工神经网络结构具有独特的人工神经网络数据局部性。此外,由处理器110处理的人工神经网络模型的操作序列是根据独特的人工神经网络数据局部性确定的。
118.换句话说,当人工神经网络模型由编译器编译以在特定处理器中执行时,可以配置人工神经网络数据局部性。人工神经网络数据局部性可以根据应用于编译器和人工神经网络模型的算法以及处理器的操作特性来配置。
119.待由处理器110处理的人工神经网络模型可以由处理器110和会考虑人工神经网络模型的算法特性的编译器编译。也就是说,当处理器110的驱动特性在了解人工神经网络模型的结构和算法信息的情况下已知时,编译器可以被配置为以字单元的顺序将人工神经网络数据局部性信息提供给人工神经网络存储器控制器120。
120.例如,可以以层单元计算已知技术的算法级别的特定人工神经网络模型的特定层的权重值。然而,根据本公开的示例的处理器-存储器级别的特定人工神经网络模型的特定层的权重值可以以计划待由处理器110处理的字单元计算。
121.例如,当处理器110的高速缓冲存储器的大小小于待处理的人工神经网络模型的特定层的权重的数据大小时,处理器110可以被编译为不一次处理特定层的所有权重值。
122.也就是说,当处理器110计算特定层的权重值和节点值时,由于权重值太大,因而存储结果值的高速缓冲存储器的空间会不足。在这种情况下,由处理器110产生的数据访问请求可以增加为多个数据访问请求。因此,处理器110可以被配置为以特定顺序处理增加的数据访问请求。在这种情况下,算法级别的操作顺序和根据处理器-存储器级别的人工神经网络数据局部性的操作顺序可以彼此不同。
123.也就是说,通过考虑处理器和存储器的硬件特性,可以通过处理器-存储器级别的人工神经网络数据局部性,重构算法级别的人工神经网络操作序列,以处理相应的人工神经网络模型。
124.存在于处理器-存储器级别的人工神经网络模型的人工神经网络数据局部性可以被定义为基于处理器110向存储器请求的数据访问请求顺序,预测在处理器-存储器级别待由处理器110处理的人工神经网络模型的操作顺序的信息。
125.换句话说,即使在相同的人工神经网络模型中,人工神经网络模型的人工神经网络数据局部性也可以根据处理器110的操作功能而不同地配置,所述操作功能例如特征图平铺技术或处理元件的平稳技术(stationary technique),高速缓冲存储器容量,例如处理器110的处理元件的数量,处理器110中的特征图,和权重,处理器110中的存储器分层结构,以及确定处理器110的计算操作的序列以计算人工神经网络模型的编译器的算法特性。
126.例如,特征图平铺技术是一种人工神经网络技术,其划分卷积并且随着卷积区域被划分,特征图被划分以进行计算。因此,由于平铺卷积,即使是相同的人工神经网络模型也会具有不同的人工神经网络数据局部性。
127.例如,平稳技术是控制神经处理单元中的处理元件(processing elements:pe)的驱动方法的技术。根据平稳技术,要处理的数据类型,例如输入特征图、权重和输出特征图中的一者被固定到要重用的处理元件。因此,由处理器110向存储器请求的数据或序列的类型可以变化。
128.也就是说,即使在相同的人工神经网络模型中,人工神经网络数据局部性也可以根据各种算法和/或技术来重构。因此,人工神经网络数据局部性可以通过各种条件,例如处理器、编译器或存储器来全部或部分地重构。
129.图1b图示了用于解释可应用于本公开的各种示例的人工神经网络数据局部性模式的重构的示例性神经处理单元的示例。
130.参考图1b,图示了当处理器110是神经网络处理单元npu时适用的示例性平稳技术。
131.在npu中可以包括多个处理元件。处理元件pe可以以阵列的形式配置并且每个处理元件可以配置为包括乘法器(
×
)和加法器(+)。处理元件pe可以连接到缓冲存储器或高速缓冲存储器,例如全局缓冲器。处理元件pe可以将输入特征图像素(ifmap像素:i)、滤波器权重w和部分和(psum:p)中的一个数据固定到处理元件pe的寄存器。剩余的数据可以作为处理元件pe的输入数据提供。当部分和p的累加完成时,其可能成为输出特征图像素。然而,多个处理元件可以以单独的驱动形式而不是以阵列形式实现。
132.图1b中的视图(a)示出了权重平稳(ws)技术。根据ws技术,滤波器权重w0至w7固定到处理元件pe的各个寄存器文件中,并且并行输入到处理元件pe的输入特征图像素i从第零个输入特征图像素i0移动到第八个输入特征图像素i8来执行操作。部分和p0到p8可以在串联连接的处理元件pe中累积。部分和p0至p8可依序移至后续处理元件。所有使用固定滤波器权重w0到w7的乘法和累加(mac)操作都需要映射到相同的处理元件pe以进行串行处理。
133.根据上述配置,在寄存器文件中滤波器权重w的卷积运算期间,滤波器权重w的重用被最大化以最小化滤波器权重w的访问能量消耗。
134.需要注意的是,由于在编译步骤中将ws技术应用于人工神经网络模型,因此重构人工神经网络模型的人工神经网络数据局部性以在处理器-存储器级别针对ws技术进行优化。例如,根据ws技术,为了操作的效率,滤波器权重w0至w7可以优先存储在处理元件pe中。相应地,人工神经网络数据局部性可以按照滤波器权重w、输入特征图像素i和部分和p的顺序重构,从而可以根据重构的人工神经网络数据局部性来确定由处理器110生成的数据访问请求序列。
135.图1b的视图(b)示出了输出平稳(os)技术。根据os技术,部分和p0到p7固定到要累加的处理元件pe的各个寄存器文件中,并且并行输入到处理元件pe的滤波器权重w从第零输入滤波器权重w0移动到第七滤波器权重w7来执行操作。输入特征图像素i0至i7可以移动到串联连接的处理元件pe。每个部分和p0到p7需要固定到每个待被映射的处理元件pe以执行乘法和累加(mac)操作。
136.根据上述配置,在处理元件pe中的滤波器权重w的卷积运算期间,部分和p被固定到处理元件pe的寄存器文件以最大化部分和p的重用并且根据部分和p的移动来最小化能量消耗。当固定部分和p的累加完成时,其可以成为输出特征图。
137.应当注意,当处理器110应用输出平稳os技术时,人工神经网络模型的人工神经网络数据局部性被重构以在处理器-存储器级别针对输出平稳os技术进行优化。例如,根据输出平稳os技术,为了操作的效率,部分和p0至p7优先存储在处理元件pe中。据此,可以按照部分和p、滤波器权重w和输入特征图像素i的顺序重构人工神经网络数据局部性,从而可以根据重构的人工神经网络数据局部性确定由处理器110产生的数据访问请求序列。人工神经网络模型编译器接收处理器110和存储器的硬件特性信息,以将其转换为人工神经网络模型在处理器-存储器级别操作的代码。此时,将人工神经网络模型转换为由处理器执行的代码,从而可以将人工神经网络模型转换为低级别代码。
138.也就是说,根据上述因素,即使处理相同的人工神经网络模型,处理器110也可以在时钟单元中改变每时每刻所需的数据的顺序。因此,人工神经网络模型的人工神经网络数据局部性可以被配置为在硬件级别上不同。
139.然而,当人工神经网络数据局部性的配置完成时,处理器110的操作顺序和操作所需的数据处理顺序可以在相应的人工神经网络模型的每次学习操作或推理操作时准确地重复。
140.在下文中,根据本公开的示例的上述人工神经网络存储器系统100可以被配置为基于由人工神经网络数据局部性提供的准确操作顺序来预测待由处理器110请求的下一个数据,以改善存储器延迟问题和存储器带宽问题,从而提高人工神经网络的操作处理性能,降低功耗。
141.根据本公开的示例的人工神经网络存储器控制器120被配置为被提供待由处理器110处理的人工神经网络模型的人工神经网络数据局部性信息,或被配置为分析正在由处理器110处理的人工神经网络模型的人工神经网络数据局部性。
142.人工神经网络存储器控制器120可以被配置为接收由处理器110生成的数据访问请求。
143.人工神经网络存储器控制器120可以被配置为监控或记录从处理器110接收到的数据访问请求。人工神经网络存储器控制器120观察由正在处理人工神经网络以精确地预测稍后将请求的数据访问队列的处理器110输出的数据访问请求。一个数据访问请求可以被配置为包括至少一个字单元数据。
144.人工神经网络存储器控制器120可以被配置为顺序地记录或监控从处理器110接收的数据访问请求。
145.人工神经网络存储器控制器120记录的数据访问请求可以以各种形式(例如日志文件、表格或列表)存储。然而,根据本公开的示例的人工神经网络存储器控制器120不限于数据访问请求的记录类型或形式(formant)。
146.由人工神经网络存储器控制器120监控的数据访问请求可以存储在人工神经网络存储器控制器120中的任意存储器中。然而,根据本公开的示例的人工神经网络存储器控制器120不限于数据访问请求的监控方法。
147.人工神经网络存储器控制器120可以被配置为进一步包括用于记录或监控数据访问请求的任意存储器。然而,根据本公开的示例的人工神经网络存储器控制器120不限于此并且可以被配置为与外部存储器通信。
148.人工神经网络存储器控制器120可以被配置为监控或记录从处理器110接收的数据访问请求以分析数据访问请求。
149.也就是说,人工神经网络存储器控制器120可以被配置为分析接收到的数据访问请求以分析由处理器110正在处理的人工神经网络模型的人工神经网络数据局部性。
150.也就是说,人工神经网络存储器控制器120可以被配置为分析被编译以在处理器-存储器级别操作的人工神经网络模型的人工神经网络数据局部性。
151.也就是说,人工神经网络存储器控制器120可以被配置为基于人工神经网络模型的处理器-存储器级别的人工神经网络数据局部性,分析人工神经网络在由处理器产生的存储器访问请求的单元中的操作处理顺序,以分析人工神经网络模型的人工神经网络数据局部性。
152.根据上述配置,人工神经网络存储器控制器120可以分析在处理器-存储器级别重构的人工神经网络数据局部性。
153.在一些示例中,编译器可以被配置为分析人工神经网络模型在字单元中的人工神经网络数据局部性。
154.在一些示例中,至少一个人工神经网络存储器控制器可以被配置为以字单元提供有由编译器分析的人工神经网络数据局部性。此处,字单元可以根据处理器110的字单元而变化为8位、16位、32位、64位等。此处,字单元可以根据编译的人工神经网络模型的内核、特征图等的量化算法而设定为不同的字单元,例如2位、3位或5位。
155.人工神经网络存储器控制器120可以被配置为包括特殊函数寄存器。特殊函数寄存器可以被配置为存储人工神经网络数据局部性信息。
156.人工神经网络存储器控制器120可以被配置为根据人工神经网络数据局部性信息是否被存储以不同的模式操作。
157.如果人工神经网络存储器控制器120存储人工神经网络数据局部性信息,则人工神经网络存储器控制器120可以以字单元顺序提前预测待由处理器110处理的人工神经网络模型的数据处理顺序,使得人工神经网络存储器控制器120可以被配置成不记录单独的数据访问请求。然而,不限于此,并且人工神经网络存储器控制器120可以被配置为在比较存储的人工神经网络数据局部性信息和由该处理器生成的数据访问请求时,验证所存储的人工神经网络数据局部性是否存在错误。
158.如果人工神经网络存储器控制器120没有被提供有人工神经网络数据局部性信息,则人工神经网络存储器控制器120可以被配置为观察处理器110产生的数据访问请求以在一种模式中操作,在该模式中预测处理器110处理的人工神经网络模型的人工神经网络数据局部性。
159.在一些示例中,人工神经网络存储器系统可以被配置为包括处理器、存储器和高速缓冲存储器,并且基于人工神经网络数据局部性信息提前生成包括要由处理器请求的数据的预测的数据访问请求。预测的数据访问请求可以被称为基于ann dl预测的数据访问请求,或者待被请求的数据访问请求。为了下面的描述方便,可以将预测的数据访问请求称为预先准备的数据访问请求。人工神经网络存储器系统可以被配置为在处理器的请求之前将与来自存储器的预测的数据访问请求相对应的数据存储在高速缓冲存储器中。此时,人工神经网络存储器系统可以被配置为以被配置为通过接收人工神经网络数据局部性信息来操作的第一模式和被配置为通过观察由处理器产生的数据访问请求以预测人工神经网络数据局部性信息来操作的第二模式中的任何一种模式来操作。根据上述配置,当人工神经网络存储器系统被提供有人工神经网络数据局部性信息时,待由处理器请求的数据以字单元被提前预测和准备。此外,即使没有提供人工神经网络数据局部性信息,由处理器产生的数据访问请求也会在预定时间段内被监控,以预测数据访问请求单元中处理器正在处理的人工神经网络数据局部性。此外,即使提供了人工神经网络数据局部性信息,人工神经网络存储器系统也独立监控数据访问请求以重构人工神经网络数据局部性以验证所提供的人工神经网络数据局部性。因此,可以感测人工神经网络模型的变化或误差。
160.在一些示例中,至少一个人工神经网络存储器控制器和至少一个处理器可以被配置为彼此直接通信。根据上述配置,人工神经网络存储器控制器可以直接接收来自处理器的数据访问请求,从而可以消除处理器与人工神经网络存储器控制器之间的系统总线引起的延迟。换言之,对于处理器与人工神经网络存储器控制器的直接通信,还可以包括专用总
线,或者还可以包括专用通信通道,但本公开不限于此。
161.在一些示例中,人工神经网络数据局部性信息可以被配置为选择性地存储在处理器110和/或人工神经网络存储器控制器120中。人工神经网络数据局部性信息可以被配置为被存储在处理器110和/或人工神经网络存储器控制器120中包括的特殊函数寄存器中。然而,不限于此,并且人工神经网络数据局部性信息可以被配置为存储在可与人工神经网络存储器系统通信的任意存储器或寄存器中。
162.图2根据本公开的示例图示了人工神经网络数据局部性模式。在下文中,将参考图2描述人工神经网络模型的人工神经网络数据局部性和人工神经网络数据局部性模式。
163.人工神经网络存储器控制器120被配置为根据顺序记录或监控从处理器110接收到的数据访问请求。
164.人工神经网络存储器控制器120被配置为生成人工神经网络数据局部性模式,该模式包括正在由处理器110处理的人工神经网络模型的数据局部性。即,人工神经网络存储器控制器120可以被配置为分析与由处理器110生成的人工神经网络模型相关联的数据访问请求以生成重复的特定模式。也就是说,当观察到数据访问请求时,可以将人工神经网络数据局部性信息存储为人工神经网络数据局部性模式。
165.参考图2,以人工神经网络存储器控制器120中依次记录十八个数据访问请求为例。每个数据访问请求被配置为包括识别信息。
166.包括在数据访问请求中的识别信息可以被配置为包括各种信息。
167.例如,识别信息可以被配置为至少包括存储器地址值和操作模式值。
168.例如,存储器地址值可以被配置为包括与所请求的数据对应的存储器地址值,但是本公开不限于此。
169.例如,存储器地址值可以被配置为包括与所请求的数据对应的存储器地址的起始值和结束值。根据上述配置,考虑在存储器地址的起始值和结束值之间顺序地存储数据。因此,可以减少用于存储存储器地址值的容量。也就是说,当触发值被激活时,存储器也可以在突发模式下运行。
170.例如,存储器地址值可以被配置为包括与所请求的数据对应的存储器地址的起始值和数据连续读取触发值。根据上述配置,可以从存储器地址的起始值开始连续读取数据,直到连续读取触发值改变为止。根据上述配置,可以连续读取数据,从而可以增加存储器有效带宽。
171.例如,存储器地址值可以被配置为包括与所请求的数据相对应的存储器地址的起始值和关于数据数量的信息。可以基于存储器容量的单元来确定数据数量的单元。例如,单元可以是8位的1个字节、4个字节的1个字、1024个字节的1个字块中的一种,但本公开不限于此。根据上述配置,可以从与设置的单元大小的数据数量一样多的存储器地址的起始值连续读取数据,从而可以增加存储器有效带宽。
172.例如,当存储器是非易失性存储器时,存储器地址值还可以包括物理逻辑地址映射表或闪存转换层信息,但本公开不限于此。
173.例如,操作模式可以被配置为包括读取模式和写入模式。读取和写入操作还可以包括突发模式。
174.例如,操作模式可以被配置为进一步包括覆盖(overwrite),但是本公开不限于
此。
175.人工神经网络存储器控制器120可以被配置为确定每个数据访问请求的识别信息是否相同。
176.例如,人工神经网络存储器控制器120可以被配置为确定每个数据访问请求的存储器地址和操作模式是否相同。换言之,人工神经网络存储器控制器120可以被配置为检测具有相同存储器地址值和相同操作模式的数据访问请求值。
177.例如,当第一数据访问请求的存储器地址值和操作模式与第十数据访问请求的存储器地址值和操作模式相同时,人工神经网络存储器控制器120被配置为生成与对应的存储器地址值和操作模式对应的人工神经网络数据局部性模式。
178.人工神经网络数据局部性模式被配置为包括其中依次记录数据访问请求的存储器地址的数据。
179.也就是说,人工神经网络存储器控制器120可以被配置为检测具有相同存储器地址值和操作模式的数据访问请求的重复周期,以生成由具有重复的存储器地址值和操作模式的数据访问请求配置的人工神经网络数据局部性模式。
180.也就是说,人工神经网络存储器控制器120可以被配置为通过检测包括在数据访问请求中的存储器地址的重复模式来生成人工神经网络数据局部性模式。
181.参考图2,当人工神经网络存储器控制器120识别出第一数据访问请求的存储器地址值和操作模式与第十数据访问请求的存储器地址值和操作模式相同时,人工神经网络存储器控制器120可以被配置为在相同的数据访问请求中从起始数据访问请求到重复数据访问请求的预测的数据访问请求生成一个人工神经网络数据局部性模式。在这种情况下,人工神经网络存储器控制器120可以被配置为生成包括第一数据访问请求到第九数据访问请求的人工神经网络数据局部性模式。
182.也就是说,参考图2描述的人工神经网络数据局部性模式可以被配置为按照第一数据访问请求、第二数据访问请求、第三数据访问请求、第四数据访问请求、第五数据访问请求、第六数据访问请求、第七数据访问请求、第八数据访问请求和第九数据访问请求的顺序包括存储器地址值和操作模型值。
183.由人工神经网络存储器控制器120生成的人工神经网络数据局部性模式可以以各种形式(例如日志文件、表格或列表)存储。根据本公开的示例的人工神经网络存储器控制器120不限于人工神经网络数据局部性模式的记录类型或格式。
184.由人工神经网络存储器控制器120生成的人工神经网络数据局部性模式可以存储在人工神经网络存储器控制器120的任意存储器中。根据本公开的示例的人工神经网络存储器控制器120不限于存储人工神经网络数据局部性模式的存储器的结构或方法。
185.人工神经网络存储器控制器120可以被配置为进一步包括用于存储人工神经网络数据局部性模式的任意存储器。然而,根据本公开的示例的人工神经网络存储器控制器120不限于此并且可以被配置为与外部存储器通信。
186.也就是说,根据本公开的示例的人工神经网络存储器系统100可以被配置为包括至少一个处理器110和人工神经网络存储器控制器120,该至少一个处理器110被配置为生成与人工神经网络操作相对应的数据访问请求,并且该人工神经网络存储器控制器120被配置为依次记录数据访问请求以生成人工神经网络数据局部性模式。
187.当人工神经网络存储器控制器120生成人工神经网络数据局部性模式时,人工神经网络存储器控制器120可以被配置为确定从处理器110接收到的数据访问请求的存储器地址值和操作模式值是否匹配包括在先前生成的人工神经网络数据局部性模式中的存储器地址值和操作模式值中的任何一个。
188.参考图2,当人工神经网络存储器控制器120从处理器110接收第十数据访问请求时,人工神经网络存储器控制器120可被配置为确定接收到的数据访问请求是否具有与包含在人工神经网络数据局部性模式中的存储器地址值相同的存储器地址值。
189.参考图2,当人工神经网络存储器控制器120接收到第十数据访问请求时,人工神经网络存储器控制器120可以被配置为检测作为第十数据访问请求的存储器地址值的开始值[0]和结束值[0
×
1000000]与第一数据访问请求的的开始和结束存储器地址值相同,并且可以被配置为检测第十数据访问请求的操作模式的读取模式值与第一数据访问请求的操作模式的读取模式值相同。因此,人工神经网络存储器控制器120确定第十数据访问请求与第一数据访问请求相同,并且第十数据访问请求为人工神经网络操作。
[0190]
当人工神经网络存储器控制器120接收到第十一数据访问请求时,人工神经网络存储器控制器120可以被配置为检测作为第十一数据访问请求的存储器地址值的开始值[0
×
1100000]和结束值[0
×
1110000]与第二数据访问请求的开始和结束存储器地址值相同,并且可以被配置为检测第十一数据访问请求的操作模式的写入模式值与第二数据访问请求的操作模式的写入模式值相同。因此,人工神经网络存储器控制器120确定第十一数据访问请求与第二数据访问请求相同,并且第十一数据访问请求为人工神经网络操作。
[0191]
也就是说,人工神经网络存储器控制器120可以区分人工神经网络数据局部性模式的开始和结束。此外,即使在人工神经网络数据局部性模式结束之后没有特殊命令,人工神经网络存储控制器120也可以预先准备人工神经网络数据局部性模式的开始。因此,当重复相同的操作时,通过基于当前推理的结束预测下一次推理的开始,具有可以在下一次推理开始之前准备数据的效果。因此,当重复相同的人工神经网络数据局部性模式时,可以防止或减少开始和结束的延迟时间。
[0192]
再次参考图2,人工神经网络存储器控制器120从第一数据访问请求到第九数据访问请求不生成人工神经网络数据局部性模式。在这种情况下,人工神经网络存储器控制器120被初始化,或者处理器110不执行人工神经网络操作。因此,人工神经网络存储器控制器120不检测模式与第九数据访问请求的匹配。人工神经网络存储器控制器120可以在第十次数据访问请求时确定第一数据访问请求的身份,生成人工神经网络数据局部性模式,并且记录模式是否匹配。第十数据访问请求到第十八数据访问请求与第一数据访问请求到第九数据访问请求相同,从而人工神经网络存储器控制器120可以确定第十数据访问请求到第十八数据访问请求的模式匹配人工神经网络数据局部性模式。
[0193]
也就是说,人工神经网络存储器控制器120可以被配置为通过利用人工神经网络数据局部性模式来确定由处理器110正在处理的操作是否是人工神经网络操作。根据上述配置,即使人工神经网络存储器控制器120仅接收包括由处理器110生成的存储器地址值和操作模式值的数据访问请求,人工神经网络存储器控制器120也可以确定处理器110正在处理人工神经网络操作。因此,人工神经网络存储器控制器120可以基于人工神经网络数据局部性模式确定处理器110当前是否正在执行人工神经网络操作,而无需单独的附加识别信
息。
[0194]
正如将参考图2进行另外描述的那样,每个数据访问请求可以被配置为存储为令牌。例如,可以对每个人工神经网络的数据访问请求进行令牌化以进行存储。例如,可以基于识别信息对每个人工神经网络的数据访问请求进行令牌化。例如,可以基于存储器地址值对每个人工神经网络的数据访问请求进行令牌化。然而,本公开的示例不限于此,令牌可以被称为代码、标识符等。例如,可以按字、数据访问请求或ann dl定义令牌。
[0195]
例如,第一数据访问请求可以被存储为令牌[1]。第四数据访问请求可以存储为令牌[4]。第七数据访问请求可以存储为令牌[7]。例如,人工神经网络数据局部性模式可以存储为令牌[1-2-3-4-5-6-7-8-9]。例如,第十数据访问请求与令牌[1]具有相同的存储器地址值和相同的操作模式值,从而可以将第十数据访问请求存储为令牌[1]。第十三数据访问请求与令牌[4]具有相同的存储器地址值和相同的操作模式值,从而可以将第十三数据访问请求存储为令牌[4]。因此,当人工神经网络存储器控制器120检测到与人工神经网络数据局部性模式的令牌相同的令牌时,人工神经网络存储器控制器可以被配置为确定相应的数据访问请求是人工神经网络操作。
[0196]
根据上述配置,人工神经网络存储器控制器120可以通过利用令牌化的人工神经网络数据局部性模式来容易且快速地识别和区分数据访问请求。此外,即使在数据访问请求中进一步添加额外的识别信息和/或数据时,人工神经网络存储器控制器使用相同的令牌来利用令牌,即使在数据访问请求的附加信息增加到容易且快速地识别和区分数据访问请求时也如此。
[0197]
在一些示例中,可以消除或初始化存储在人工神经网络存储器控制器中的人工神经网络数据局部性模式。例如,在人工神经网络数据局部性模式在预定时间到期时未被使用前,例如,当在特定时间没有产生匹配人工神经网络数据局部性模式的数据访问请求时,人工神经网络存储器控制器确定人工神经网络数据局部性模式的使用频率较低,以消除或初始化人工神经网络数据局部性模式。
[0198]
根据上述配置,可以提高存储人工神经网络数据局部性模式的存储器的存储空间的可用性。
[0199]
在一些示例中,人工神经网络存储器控制器可以被配置为存储人工神经网络数据局部性模式的更新模式和先前模式以确定人工神经网络模型是否改变。也就是说,当存在多个人工神经网络模型时,人工神经网络存储器控制器可以被配置为进一步生成与人工神经网络模型的数量对应的人工神经网络数据局部性模式。
[0200]
例如,当第一人工神经网络数据局部性模式是令牌[1-2-3-4-5-6-7-8-9]并且第二人工神经网络数据局部性模式是令牌[11-12-13-14-15-16-17-18]时,如果处理器产生与令牌[1]对应的数据访问请求,则人工神经网络存储器控制器可以被配置为选择第一人工神经网络数据局部性模式。替代地,如果处理器生成与令牌[11]对应的数据访问请求,则人工神经网络存储器控制器可以被配置为选择第二人工神经网络数据局部性模式。
[0201]
根据上述配置,人工神经网络存储器控制器可以存储多个人工神经网络数据局部性模式,并且当由处理器处理的人工神经网络模型改变为另一人工神经网络模型时,可以快速应用先前存储的人工神经网络数据局部性模式。
[0202]
在一些示例中,人工神经网络存储器控制器可以被配置为确定数据访问请求是一
个人工神经网络模型的请求还是多个人工神经网络模型的请求的混合。此外,人工神经网络存储器控制器可以被配置为预测与多个人工神经网络模型中的每一个的人工神经网络数据局部性相对应的数据访问请求。
[0203]
例如,处理器可以同时处理多个人工神经网络模型,且在这种情况下,处理器生成的数据访问请求可以是对应于多个人工神经网络模型的混合数据访问请求。
[0204]
例如,当第一人工神经网络数据局部性模式是令牌[1-2-3-4-5-6-7-8-9],并且第二人工神经网络数据局部性模式是令牌[11-12-13-14-15-16-17-18]时,处理器110可以按照[1-11-2-3-12-13-14-4-5-6-15-16-7-8-9]的顺序生成对应于数据访问请求的令牌。
[0205]
人工神经网络存储器控制器知道每个人工神经网络数据局部性模式,使得即使生成令牌[1],并且然后生成令牌[11],人工神经网络存储器控制器可以预测令牌[2]接下来将生成。因此,人工神经网络存储器控制器可以提前生成与令牌[2]对应的预测的数据访问请求。此外,即使在生成令牌[11]之后生成令牌[2],人工神经网络存储器控制器也可以预测接下来将生成令牌[12]。因此,人工神经网络存储器控制器可以提前生成与令牌[12]对应的预测的数据访问请求。
[0206]
根据上述配置,人工神经网络存储器控制器120针对每个人工神经网络模型预测将由处理多个人工神经网络模型的处理器110生成的数据访问请求,以预测和准备将由处理器110请求的数据。
[0207]
在一些示例中,人工神经网络存储器控制器可以被配置为存储多个人工神经网络数据局部性模式。
[0208]
例如,当处理器处理两个人工神经网络模型时,人工神经网络存储器控制器可以被配置为存储每个人工神经网络模型的人工神经网络数据局部性模式。
[0209]
根据上述配置,当处理每个人工神经网络模型的操作时,可以预测对应于每个模型的实际的数据访问请求,从而根据本公开的示例,人工神经网络操作的处理速度可能会得到提高。
[0210]
在一些示例中,人工神经网络存储器控制器可以被配置为进一步包括人工神经网络模型,人工神经网络模型被配置为机器学习人工神经网络数据局部性模式。
[0211]
根据上述配置,人工神经网络存储器控制器的人工神经网络模型可以被配置为对处理器产生的数据访问请求实时执行强化学习。进一步地,人工神经网络存储器控制器的人工神经网络模型可以是通过利用已知的人工神经网络模型的人工神经网络数据局部性模式作为学习数据训练的模型。因此,人工神经网络存储器控制器可以从各种人工神经网络模型中提取人工神经网络数据局部性模式。具体地,当多种人工神经网络模型被多个用户(例如服务器)的请求处理时,这种方法可能是有效的。
[0212]
正如将参考图2进行另外描述的那样,人工神经网络存储器控制器120可以被配置为动态且实时地监控由处理器110处理的人工神经网络模型,并且确定人工神经网络模型是否发生变化。
[0213]
例如,人工神经网络存储器控制器120可以被配置为统计上利用人工神经网络数据局部性模式的模式匹配频率来确定人工神经网络数据局部性模式的可靠性。其可以被配置为使得随着人工神经网络数据局部性模式的模式匹配频率增加,人工神经网络数据局部性模式的可靠性增加,并且使得随着人工神经网络数据局部性模式的模式匹配频率减少,
人工神经网络数据局部性模式的可靠性降低。
[0214]
根据上述配置,当处理器110重复处理特定人工神经网络模型时,人工神经网络存储器控制器120可以提高特定人工神经网络模型的人工神经网络数据局部性的预测可靠性。
[0215]
图3是图示了用于解释适用于本公开的各种示例的人工神经网络数据局部性模式的示例性人工神经网络模型。
[0216]
正在由如图3所示的处理器110处理的示例性人工神经网络模型1300可以是被训练来执行特定的推理功能的任意的人工神经网络模型。为了描述的方便,已经示出了其中所有节点全连接的人工神经网络模型,但是本公开不限于此。
[0217]
尽管图3未示出,但适用于本公开的人工神经网络模型可以是卷积神经网络(cnn),其是深度神经网络(dnn)中的一种。示例性的人工神经网络模型可以是例如以下模型:具有vgg、vgg16、densenet和编码器-解码器结构的全卷积网络(fcn),深度神经网络(dnn),例如segnet、deconvnet、deeplabv3+、或u-net、或squeezenet、alexnet、resnet18、mobilenet-v2、googlenet、resnet-v2、resnet50、resnet101和inception-v3,或基于至少两种不同模型的集成模型,但本公开的人工神经网络模型不限于此。
[0218]
上述示例性人工神经网络模型可以被配置为具有人工神经网络数据局部性。
[0219]
再次参考图3,对由处理器110处理的人工神经网络模型的人工神经网络数据局部性进行详细说明。
[0220]
示例性的人工神经网络模型1300包括输入层1310、第一连接网络1320、第一隐藏层1330、第二连接网络1340、第二隐藏层1350、第三连接网络1360和输出层1370。
[0221]
人工神经网络的连接网络具有相应的权重值。连接网络的权重值与输入节点值相乘,并且相乘值的累加值存储在相应的输出层的节点中。
[0222]
换句话说,人工神经网络模型1300的连接网络由线表示,而权重由符号表示。
[0223]
换句话说,可以附加地提供各种激活函数以向累积值赋予非线性。激活函数例如可以是sigmoid函数、双曲正切函数、elu函数、hard-sigmoid函数、swish函数、hard-swish函数、selu函数、celu函数、gelu函数、tanhshrink函数、softplus函数、mish函数、非线性函数的分段插值近似或relu函数,但本公开不限于此。
[0224]
示例性的人工神经网络模型1300的输入层1310包括输入节点x1和x2。
[0225]
示例性的人工神经网络模型1300的第一连接网络1320包括具有六个权重值的连接网络,其连接输入层1310的节点和第一隐藏层1330的节点。
[0226]
示例性人工神经网络模型1300的第一隐藏层1330包括节点a1、a2和a3。第一连接网络1320的权重值与对应输入层1310的节点值相乘,并且相乘值的累加值被存储在第一隐藏层1330中。
[0227]
示例性人工神经网络模型1300的第二连接网络1340包括具有九个权重值的连接网络,其连接第一隐藏层1330的节点和第二隐藏层1350的节点。
[0228]
示例性的人工神经网络模型1300的第二隐藏层1350包括节点b1、b2和b3。第二连接网络1340的权重值与对应的第一隐藏层1330的节点值相乘,并且相乘值的累加值被存储在第二隐藏层1350中。
[0229]
示例性的人工神经网络模型1300的第三连接网络1360包括具有六个权重值的连
接网络,其连接第二隐藏层1350的节点和输出层1370的节点。
[0230]
示例性人工神经网络模型1300的输出层1370包括节点y1和y2。第三连接网络1360的权重值与对应的第二隐藏层1350的输入节点值相乘,并且相乘值的累加值被存储在输出层1370中。
[0231]
根据上述人工神经网络模型1300的结构,认识到需要依次执行每一层的操作。也就是说,可能存在的问题是,当人工神经网络模型的结构确定后,需要确定每一层的操作顺序,并且当以不同的顺序进行操作时,推理结果可能不准确。根据人工神经网络模型的结构的操作顺序或数据流的顺序可以被定义为人工神经网络数据局部性。
[0232]
此外,为了便于描述,在图2中,尽管描述了层单元,但是本公开的示例不限于层单元。根据本公开的示例的处理器110基于人工神经网络数据局部性处理数据,使得处理器可以以字单元或以数据访问请求单元进行操作,而不是以层单元进行操作。这里,数据访问请求的数据大小可以小于或等于对应层的数据大小。
[0233]
再次参考图3,例如,对于第一连接网络1320的权重值与输入层1310的节点值的乘法操作,处理器110可以以层单元产生数据访问请求。
[0234]
然而,第一连接网络1320的权重值和输入层1310的节点值的层操作不被处理为一个数据访问请求,而是可以根据处理器110的特征图划分卷积、处理元件的平稳技术、处理器的处理元件的数量、处理器110的高速缓冲存储器容量、处理器110的存储器分层结构和/或处理器110的编译器算法被处理为多个被划分的的顺序数据访问请求。
[0235]
当待由处理器110请求的数据访问请求被划分为多个数据访问请求时,请求被划分的数据访问请求的顺序可以由人工神经网络数据局部性确定。此时,人工神经网络存储器控制器120可以被配置为具有将被准备的人工神经网络数据局部性,以提供与待由处理器110请求的实际数据访问请求相对应的数据。“实际数据访问请求”可以被称为“在预测的数据访问请求之后由处理器生成的数据访问请求”。替代地,人工神经网络网络存储器控制器120可以被配置为预测将被准备的人工神经网络数据局部性,以提供与待由处理器110请求的后续数据访问请求相对应的数据。
[0236]
将对在图3所示的人工神经网络模型1300的人工神经网络操作期间由处理器110生成的数据访问请求和人工神经网络数据局部性进行描述。
[0237]
处理器110生成第一数据访问请求以读取人工神经网络模型1300的输入层1310的输入节点值。第一数据访问请求包括第一存储器地址值和读取模式值。第一数据访问请求可以存储为令牌[1]。
[0238]
接下来,处理器110生成第二数据访问请求以读取人工神经网络模型1300的第一连接网络1320的权重值。第二数据访问请求包括第二存储器地址值和读取模式值。第二数据访问请求可以存储为令牌[2]。
[0239]
接着,处理器110产生第三数据访问请求,以用于储存第一隐藏层1330的节点值,该节点值是通过将人工神经网络模型1300的第一连接网络1320的权重值与输入层1310的节点值相乘且累加所得到的。第三数据访问请求包括第三存储器地址值和写入模式值。第三数据访问请求可以存储为令牌[3]。
[0240]
接下来,处理器110生成第四数据访问请求以读取存储在人工神经网络模型1300的第一隐藏层1330中的节点值。第四数据访问请求包括第三存储器地址值和读取模式值。
第四数据访问请求可以存储为令牌[4]。
[0241]
接下来,处理器110生成第五数据访问请求以读取人工神经网络模型1300的第二连接网络1340的权重值。第五数据访问请求包括第五存储器地址值和写入模式值。可以将第五数据访问请求存储为令牌[5]。
[0242]
接着,处理器110产生第六数据访问请求,以用于储存第二隐藏层1350的节点值,所述节点值是通过将人工神经网络模型1300的第二连接网络1340的权重值与第一隐藏层1330的节点值相乘且累加得到的。第六数据访问请求包括第六存储器地址值和写入模式值。第六数据访问请求可以存储为令牌[6]。
[0243]
接下来,处理器110生成第七数据访问请求以读取存储在人工神经网络模型1300的第二隐藏层1350中的节点值。第七数据访问请求包括第六存储器地址值和读取模式值。第七数据访问请求可以存储为令牌[7]。
[0244]
接下来,处理器110生成第八数据访问请求以读取人工神经网络模型1300的第三连接网络1360的权重值。第八数据访问请求包括第八存储器地址值和读取模式值。第八数据访问请求可以存储为令牌[8]。
[0245]
接下来,处理器110生成第九数据访问请求,以用于存储通过将人工神经网络模型1300的第三连接网络1360的权重值与第二隐藏层1350的节点值相乘和累加而获得的输出层1370的节点值。第九数据访问请求包括第九存储器地址值和写入模式值。第九数据访问请求可以存储为令牌[9]。节点值可以是特征图、激活图等,但不限于此。权重值可以是内核窗口,但不限于此。
[0246]
也就是说,处理器110需要为示例性人工神经网络模型1300的推理生成第一到第九数据访问请求。如果由处理器110生成的数据访问请求的序列是混合的,则人工神经网络模型1300的人工神经网络数据局部性被破坏,从而可能导致人工神经网络模型1300的推理结果出现错误或影响精度。例如,处理器110可能先计算第二层,然后计算第一层。因此,处理器110可以被配置为基于人工神经网络数据局部性顺序地生成数据访问请求。因此,假设当处理器110操作人工神经网络时,人工神经网络存储器控制器120可基于人工神经网络数据局部性顺序地产生数据访问请求。
[0247]
然而,如上所述,可以根据处理器的硬件特性在处理器-存储器级别重新解释每个数据访问请求。在上述示例中,已经描述了处理器的高速缓冲存储器的可用容量是足够的,并且节点值的数据大小和权重值的数据大小小于高速缓冲存储器的可用容量。因此,描述了在一个数据访问请求单元中处理每一层。如果人工神经网络模型的诸如权重值、特征图、内核、激活图等数据大小大于处理器的高速缓冲存储器的可用容量,则相应的数据访问请求可能被划分为多个数据访问请求,并且在这种情况下,可以重构人工神经网络模型的人工神经网络数据局部性。
[0248]
根据本公开的示例的人工神经网络存储器控制器120可以生成人工神经网络数据局部性模式,使得人工神经网络存储器控制器可以操作以对应于待由处理器主动处理的人工神经网络模型的人工神经网络数据局部性。
[0249]
也就是说,即使不知道处理器110正在处理的人工神经网络模型的实际人工神经网络数据局部性,人工神经网络存储器控制器120也可以通过分析记录的数据访问请求来实际分析人工神经网络数据局部性。
[0250]
也就是说,即使没有提供由处理器110正在处理的人工神经网络模型的结构信息,人工神经网络存储器控制器120也可以通过分析记录的数据访问请求来实际分析人工神经网络数据局部性。
[0251]
在一些示例中,人工神经网络存储器控制器可以被配置为具有在处理器-存储器级别提前生成的人工神经网络数据局部性模式。
[0252]
图4根据本公开的示例示出了通过由人工神经网络存储器控制器分析图3的人工神经网络模型而获得的人工神经网络数据局部性模式1400。图5图示了与图4的人工神经网络数据局部性模式对应的令牌和识别信息1500。也就是说,图5图示了与对应于图4的人工神经网络数据局部性模式1400的令牌对应的识别信息1500。
[0253]
图4所示的人工神经网络数据局部性模式1400为了描述方便而被显示为令牌。参考图1a至图4,人工神经网络模型1300的人工神经网络数据局部性模式1400被存储为令牌[1-2-3-4-5-6-7-8-9]。
[0254]
每个数据访问请求被配置为包括识别信息。每个数据访问请求都可以用令牌来表示,但这种表示仅仅是为了描述方便。也就是说,本公开不限于令牌。
[0255]
根据人工神经网络数据局部性模式1400,人工神经网络存储器控制器120可以顺序地预测将在当前令牌之后生成的令牌的顺序。
[0256]
例如,人工神经网络数据局部性模式1400可以被配置为具有循环类型模式,其中顺序是从最后令牌连接到开始令牌,但是本公开不限于此。
[0257]
例如,人工神经网络数据局部性模式1400可由具有重复循环特性的存储器地址配置,但本公开不限于此。
[0258]
例如,人工神经网络数据局部性模式1400可以被配置为进一步包括用于识别人工神经网络模型的操作的开始和结束的识别信息,但是本公开不限于此。
[0259]
例如,人工神经网络数据局部性模式1400的开始和结束可以被配置为区分为模式的开始令牌和最后令牌,但是本公开不限于此。
[0260]
根据上述配置,当处理器110重复推理特定人工神经网络模型时,由于人工神经网络数据局部性模式1400是循环型模式,即使特定人工神经网络模型的当前推理结束,也可以预测下一推理的开始。
[0261]
例如,在人工神经网络模型以30ips(推理/秒)的速度识别安装在自动驾驶汽车中的前置摄像头的图像对象的情况下,相同的推理以特定的循环连续地重复。因此,当利用上述循环型人工神经网络数据局部性模式时,可以预测重复的数据访问请求。
[0262]
当附加地描述识别信息作为示例时,人工神经网络数据局部性模式1400的令牌[3]和令牌[4]具有相同的存储器地址值但具有不同的操作模式。因此,即使存储器地址值相同,操作模式也不同,从而人工神经网络存储器控制器120可以被配置为将第三数据访问请求和第四数据访问请求分类为不同的令牌。然而,本公开的示例的识别信息不限于操作模式,而是可以被配置为仅利用存储器地址值来预测人工神经网络数据局部性模式。
[0263]
人工神经网络存储器控制器120可以被配置为基于神经网络数据局部性模式1400生成对应的预测的数据访问请求(即提前的数据访问数据访问请求)。
[0264]
人工神经网络存储器控制器120可以被配置为基于人工神经网络数据局部性模式1400生成对应的预测的数据访问请求。
[0265]
人工神经网络存储器控制器120可以被配置为基于人工神经网络数据局部性模式1400依次进一步提前生成预测的数据访问请求。
[0266]
根据上述配置,当处理器110生成包括在人工神经网络数据局部性模式1400中的特定数据访问请求时,人工神经网络存储器控制器120可在特定的数据访问请求之后顺序地预测至少一个数据访问请求。例如,当处理器110产生令牌[1]时,人工神经网络存储器控制器120可以预测随后产生与令牌[2]对应的数据访问请求。例如,当处理器110产生令牌[3]时,人工神经网络存储器控制器120可以预测随后产生与令牌[4]对应的数据访问请求。例如,当处理器110产生令牌[1]时,人工神经网络存储器控制器120可以预测按照令牌[2-3-4-5-6-7-8-9]的顺序产生对应的数据访问请求。
[0267]
换句话说,当处理器110处理多个人工神经网络模型时,未被预测的数据局部性模式可能会介入人工神经网络数据局部性模式1400的令牌之间。例如,在令牌之后[2],新的令牌[4]可能会被中断。然而,即使在这种情况下,人工神经网络存储器控制器120也可以预测并准备处理器110在令牌[2]之后生成令牌[3]。
[0268]
例如,当处理器110生成令牌[9]时,人工神经网络存储器控制器120可以预测处理器110生成令牌[1]。
[0269]
图6根据本公开的示例图示了通过人工神经网络存储器控制器基于人工神经网络数据局部性模式生成1600预测的数据访问请求和实际的(下一)实际数据访问请求。
[0270]
根据本公开的示例的人工神经网络存储器控制器120可以被配置为利用人工神经网络数据局部性模式来预测待由处理器110随后请求的实际的数据访问请求以提前生成预测的数据访问请求。
[0271]
参照图6,数据访问请求令牌是指与由人工神经网络存储器控制器120从处理器110接收的数据访问请求对应的令牌。预测的数据访问请求令牌是与通过以下方式获得的数据访问请求对应的令牌:基于人工神经网络数据局部性模式,由人工神经网络存储器控制器120预测待由处理器110后续请求的数据访问请求。实际的数据访问请求令牌是在生成预测的数据访问请求令牌之后立即由处理器110实际生成的数据访问请求令牌。本公开的令牌只是为了描述方便的示例;也就是说,本公开不限于该令牌。
[0272]
将由处理器生成的数据访问请求和在处理器生成之前由人工神经网络存储器控制器预测的预测数据访问请求可以对应于特定的数据访问请求令牌。在这种情况下,匹配特定数据访问请求令牌的数据访问请求和预测的数据访问请求可以被配置为具有相同的存储器地址。也就是说,数据访问请求和预测的数据访问请求可以被配置为包括相同的存储器地址。
[0273]
例如,当数据访问请求令牌为[3]且预测的数据访问请求令牌为[3]时,每个令牌的存储器地址值可以相同。也就是说,数据访问请求和预测的数据访问请求可以被配置为包括相同的操作模式值。例如,当数据访问请求令牌为[3]且预测的数据访问请求令牌为[3]时,每个令牌的操作模式值可以相同。
[0274]
参考图6,当处理器110产生对应于令牌[1]的数据访问请求时,人工神经网络存储器控制器120产生对应于令牌[2]的预测的数据访问请求。处理器110在生成预测的数据访问请求后,生成与令牌[2]对应的后续(实际)数据访问请求。人工神经网络存储器控制器120被配置为确定预测的数据访问请求是否准确地预测了实际的数据访问请求。相同的令
牌对应于预测的数据访问请求和实际的数据访问请求,从而人工神经网络存储器控制器120可以确定模式匹配。
[0275]
接着,例如,当处理器110产生对应于令牌[2]的数据访问请求时,人工神经网络存储器控制器120产生对应于令牌[3]的预测的数据访问请求。处理器110在生成预测的数据访问请求之后生成与令牌[3]对应的后续(实际)数据访问请求。人工神经网络存储器控制器120被配置为确定预测的数据访问请求是否准确地预测了后续(实际)数据访问请求。相同的令牌对应于预测的数据访问请求和后续(实际)数据访问请求,使得人工神经网络存储器控制器120可以确定模式匹配。
[0276]
例如,当处理器110产生对应于令牌[9]的数据访问请求时,人工神经网络存储器控制器120产生对应于令牌[1]的预测的数据访问请求。处理器110在生成预测的数据访问请求后,生成与令牌[9]对应的后续的(实际的)数据访问请求。人工神经网络存储器控制器120被配置为确定预测的数据访问请求是否准确地预测了后续(实际)数据访问请求。相同的令牌对应于预测的数据访问请求和后续(实际)数据访问请求,从而人工神经网络存储器控制器120可以确定模式匹配。
[0277]
当处理器110在人工神经网络存储器控制器120产生预测的数据访问请求之后产生后续(实际)数据访问请求时,人工神经网络存储器控制器120可以被配置为确定预测的数据访问请求和后续(实际)数据访问请求是否是相同的请求。
[0278]
根据上述配置,人工神经网络存储器系统100可以检测由处理器110处理的人工神经网络模型的人工神经网络数据局部性的变化。因此,即使人工神经网络模型发生了改变,人工神经网络存储器控制器120也可以分析改变的人工神经网络数据局部性。
[0279]
当人工神经网络存储器控制器120确定预测的数据访问请求和后续(实际)数据访问请求是相同的请求时,人工神经网络存储器控制器120可以被配置为保持人工神经网络数据局部性模式。
[0280]
根据上述配置,人工神经网络存储器系统100检测由处理器110处理的人工神经网络模型被重复使用,以更快地准备或提供由处理器110请求的数据。
[0281]
当人工神经网络存储器控制器120确定预测的数据访问请求和后续(实际)数据访问请求不同时,人工神经网络存储器控制器120可以被配置为更新人工神经网络数据局部性模式或进一步生成新的人工神经网络数据局部性模式。
[0282]
根据上述配置,人工神经网络存储器系统100可以检测由处理器110处理的人工神经网络模型的变化以生成与变化的人工神经网络模型对应的预测的数据访问请求.
[0283]
在一些示例中,人工神经网络存储器控制器可以被配置为生成连续的预测的数据访问请求。
[0284]
例如,当数据访问请求令牌为[2]时,由人工神经网络存储器控制器生成的预测的数据访问请求可以是与令牌[3]对应的数据访问请求。然而,不限于此,例如,由人工神经网络存储器控制器产生的预测的数据访问请求可以是与令牌[3-4]对应的多个数据访问请求。然而,不限于此,例如,由人工神经网络存储器控制器产生的预测的数据访问请求可以是与令牌[3-4-5-6]对应的多个数据访问请求。
[0285]
根据上述配置,人工神经网络存储器控制器可以基于人工神经网络数据局部性模式生成预测连续重复的数据访问请求的整个顺序的预测的数据访问请求。
[0286]
根据上述配置,人工神经网络存储器控制器可以基于人工神经网络数据局部性模式生成预测至少一些数据访问请求的顺序的预测的数据访问请求。
[0287]
图7根据本公开的示例图示了人工神经网络存储器控制器的操作。
[0288]
参考图7,对于人工神经网络操作处理,处理器110可以被配置为基于人工神经网络数据局部性生成与人工神经网络模型对应的数据访问请求。
[0289]
人工神经网络存储器控制器120顺序地记录在处理器110中产生的数据访问请求以产生人工神经网络数据局部性模式。
[0290]
人工神经网络存储器控制器120将生成的人工神经网络数据局部性模式与由处理器110生成的数据访问请求进行比较,以提前生成对应于将由处理器110生成的后续数据访问请求的预测的数据访问请求。
[0291]
根据本公开的示例的人工神经网络存储器系统100可以被配置为包括至少一个处理器110,该至少一个处理器110被配置为生成与人工神经网络操作相对应的数据访问请求(s710),并且可以被进一步配置为通过顺序记录数据访问请求生成人工神经网络操作的人工神经网络数据局部性模式(s720)。人工神经网络存储器系统100可以被配置为包括至少一个人工神经网络存储器控制器120,该至少一个人工神经网络存储器控制器120被配置为生成预测的数据访问请求,该预测的数据访问请求基于人工神经网络数据局部性模式来预测由至少一个处理器110生成的数据访问请求的后续数据访问请求。
[0292]
也就是说,至少一个人工神经网络存储器控制器120在生成后续数据访问请求之前生成预测的数据访问请求(s730)。
[0293]
也就是说,至少一个处理器110被配置为将数据访问请求发送到至少一个人工神经网络存储器控制器120,并且至少一个人工神经网络存储器控制器120可以被配置为输出与数据访问请求对应的预测的数据访问请求。
[0294]
根据本公开的一个示例的人工神经网络存储器系统100可以被配置为包括至少一个处理器110和至少一个人工神经网络存储器控制器120,该至少一个处理器110被配置为生成与人工神经网络操作相对应的数据访问请求,而该至少一个人工神经网络存储器控制器120被配置为通过顺序地记录由至少一个处理器110产生的数据访问请求来产生人工神经网络操作的人工神经网络数据局部性模式,并且基于人工神经网络数据局部性模式产生预测由至少一个处理器110生成的数据访问请求的后续(实际)数据访问请求的预测的数据访问请求。
[0295]
根据上述配置,人工神经网络存储器控制器120基于人工神经网络数据局部性模式预测待通过正由处理器110处理的人工神经网络模型生成的后续(实际)数据访问请求,从而有利的是,可以提前准备好相应的数据以在处理器110的请求之前提供。
[0296]
人工神经网络存储器控制器120可以被配置为将生成的预测的数据访问请求与由处理器110在生成预测的数据访问请求之后生成的后续数据访问请求进行比较,以确定人工神经网络数据局部性模式是否匹配(s740)。
[0297]
根据上述配置,人工神经网络存储器控制器120在生成将被准备以预先提供数据的后续数据访问请求之前生成预测的数据访问请求。因此,人工神经网络存储器控制器120可以基本上消除或减少当数据被提供给处理器110时可能产生的延迟。
[0298]
图8根据本公开的另一示例图示了人工神经网络存储器系统200。
[0299]
参考图8,人工神经网络存储器系统200可以被配置为包括处理器210、人工神经网络存储器控制器220和存储器230。
[0300]
图8的人工神经网络存储器系统200和图1a的人工神经网络存储器系统100基本相同,不同的是,人工神经网络存储器系统200还包括存储器230。因此,为了描述的方便,将省略多余的描述。
[0301]
人工神经网络存储器系统200包括被配置为与人工神经网络存储器控制器220通信的存储器230,并且存储器230可以被配置为根据从人工神经网络存储器控制器220输出的存储器访问请求进行操作。
[0302]
处理器210可以被配置为与人工神经网络存储器控制器220通信。处理器210可以被配置为生成要发送到人工神经网络存储器控制器220的数据访问请求。数据访问请求可以基于正在被处理的人工神经网络模型的人工神经网络数据局部性生成。处理器210被配置为被提供有与来自人工神经网络存储器控制器220的数据访问请求对应的数据。
[0303]
人工神经网络存储器控制器220可以被配置为接收由处理器210生成的数据访问请求。人工神经网络存储器控制器220可以被配置为通过分析由处理器210正在处理的人工神经网络模型的人工神经网络数据局部性来生成人工神经网络数据局部性模式。
[0304]
人工神经网络存储器控制器220可以被配置为通过生成存储器访问请求来控制存储器230。人工神经网络存储器控制器220可以被配置为生成与数据访问请求对应的存储器访问请求。也就是说,人工神经网络存储器控制器220可以被配置为产生与由处理器210产生的数据访问请求相对应的存储器访问请求。例如,当人工神经网络存储器控制器220不产生人工神经网络数据局部性模式时,人工神经网络存储器控制器220可以被配置为基于由处理器210生成的数据访问请求来生成存储器访问请求。在这种情况下,存储器访问请求可以被配置为包括在数据访问请求中包含的识别信息中的存储器地址值和操作模式值。
[0305]
人工神经网络存储器控制器220可以被配置为生成对应于预测的数据访问请求的存储器访问请求。也就是说,人工神经网络存储器控制器220可以被配置为基于基于人工神经网络数据局部性模式生成的预测的数据访问请求来生成存储器访问请求。例如,当人工神经网络存储器控制器220生成人工神经网络数据局部性模式时,人工神经网络存储器控制器220可以被配置为基于预测的数据访问请求来生成存储器访问请求。
[0306]
根据上述配置,人工神经网络存储器控制器220可以通过存储器访问请求向存储器230发送数据和从存储器230接收数据,并且当基于预测的数据访问请求生成存储器访问请求时,人工神经网络存储器系统200可以更快地将数据提供给处理器210。
[0307]
人工神经网络存储器控制器220可以被配置为基于由处理器210产生的数据访问请求和由人工神经网络存储器控制器220产生的预测的数据访问请求中的一者来产生存储器访问请求。也就是说,由人工神经网络存储器控制器220生成的存储器访问请求可以基于数据访问请求或预测的数据访问请求来选择性地生成。
[0308]
人工神经网络存储器控制器220可以被配置为生成存储器访问请求,该存储器访问请求包括在数据访问请求和预测的数据访问请求中包括的识别信息的至少一部分。例如,由处理器210产生的数据访问请求可以包括存储器地址值和操作模式值。此时,由人工神经网络存储器控制器220产生的存储器访问请求可以被配置为包括对应的数据访问请求的存储器地址值和操作模式值。
[0309]
也就是说,数据访问请求、预测的数据访问请求和存储器访问请求中的每一个可以被配置为包括对应的存储器地址值和操作模式值。操作模式可以被配置为包括读取模式和写入模式。例如,由人工神经网络存储器控制器220生成的存储器访问请求可以被配置为具有与数据访问请求或预测的数据访问请求具有相同配置的数据类型。因此,从存储器230的角度来看,即使不区分数据访问请求和预测的数据访问请求,也可以根据人工神经网络存储器控制器220的指令执行存储器访问请求任务。
[0310]
根据上述配置,无论由人工神经网络存储器控制器220产生的存储器访问请求是基于数据访问请求还是基于预测的数据访问请求,存储器230都可以操作。因此,即使人工神经网络存储器控制器220基于人工神经网络数据局部性进行操作,人工神经网络存储器控制器也可以操作为与各种类型的存储器兼容。
[0311]
人工神经网络存储器控制器220将存储器访问请求发送到存储器230,并且存储器230执行与存储器访问请求相对应的存储器操作。
[0312]
根据本公开的示例的存储器可以以各种形式实现。存储器可以由易失性存储器和非易失性存储器来实现。
[0313]
易失性存储器可以包括动态ram(dram)和静态ram(sram)。非易失性存储器可以包括可编程只读存储器(prom)、可擦除prom(eprom)、电可擦除prom(eeprom)、闪存、铁电ram(fram)、磁ram(mram)和相变存储器设备(相变ram),但本公开不限于此。
[0314]
存储器230可以被配置为存储正在由处理器210处理的人工神经网络模型的推理数据、权重数据和特征图数据中的至少一种。推理数据可以是人工神经网络模型的输入信号。
[0315]
存储器230可以被配置为从人工神经网络存储器控制器220接收存储器访问请求。存储器230可以被配置为执行与接收到的存储器访问请求相对应的存储器操作。控制存储器操作的操作模式可以包括读取模式或写入模式。
[0316]
例如,当接收到的存储器访问请求的操作模式是写入模式时,存储器230可以将从人工神经网络存储器控制器220接收的数据存储在相应的存储器地址值中。
[0317]
例如,当接收到的存储器访问请求的操作模式是读取模式时,存储器230可以将存储在相应存储器地址值中的数据传输到人工神经网络存储器控制器220。人工神经网络存储器控制器220可以被配置为再次将接收到的数据发送到处理器210。
[0318]
存储器230可能具有延迟。存储器230的延迟可以指人工神经网络存储器控制器220处理存储器访问请求时发生的延迟时间。也就是说,当存储器230接收到来自人工神经网络存储器控制器220的存储器访问请求时,实际请求的数据在特定时钟周期的延迟之后从存储器230输出。
[0319]
为了处理存储器访问请求,存储器230可以访问包括在存储器访问请求中的存储器地址值。因此,访问存储器地址值的时间是必要的,并且该时间可以被定义为存储器延迟。例如,ddr4 sdrm存储器的cas延迟约为10ns。当在延迟期间没有向处理器210提供数据时,处理器210处于空闲状态,使得处理器不执行实际操作。
[0320]
另外,在作为存储器230的一种类型的dram的情况下,根据存储器230的行地址消耗多个时钟周期来激活字线(wordline)和位线,消耗多个时钟周期以激活列线,消耗多个时钟周期以允许数据通过将数据发送到存储器230外部所穿过的路径。此外,在nand闪存存
储器的情况下,一次激活的单元是大的,使得可以额外消耗多个时钟周期来搜索其中所需地址的数据。
[0321]
存储器230可以具有带宽。存储器230的数据传输率可以定义为存储器带宽。例如,ddr4 sdram存储器的带宽约为4gbyte/sec。随着存储器带宽更高,存储器230可以更快地将数据传输到处理器210。
[0322]
也就是说,人工神经网络存储器系统200的处理速率受在提供待由处理器210处理的数据时产生的延迟和存储器230的带宽性能的影响,超过了受处理器210的处理性能的影响。
[0323]
换句话说,存储器的带宽逐渐增加,但与带宽的改善速度相比,存储器的延迟改善相对缓慢。具体地,每当产生存储器访问请求时,都会产生存储器230的延迟,使得频繁的存储器访问请求可能是人工神经处理速度慢的重要原因。
[0324]
也就是说,即使处理器210的操作处理速度很快,如果产生延迟以获取操作所需的数据,则处理器210可能处于不执行操作的空闲状态。因此,在这种情况下,处理器210的操作处理速度会变慢。
[0325]
因此,根据本公开的示例的人工神经网络存储器系统可以被配置为提高存储器230的带宽和/或延迟。
[0326]
图9根据本公开的比较实施方案图示了存储器系统的操作。
[0327]
参考图9,处理器产生数据访问请求,并且已知的存储器系统可以将与数据访问请求对应的存储器访问请求发送到存储器。此时,存储器具有延迟,以便可以在等待延迟时段后从存储器向处理器提供所请求的数据。
[0328]
例如,已知的存储器系统接收由处理器产生的数据访问请求[1],并将与数据访问请求[1]对应的存储器访问请求[1']发送到存储器。存储器可以在延迟之后将数据[1”]发送到存储器系统。因此,在每次数据访问请求时,处理器的处理时间可能延迟与存储器的延迟一样多。因此,人工神经网络的推理操作的时间可能与存储器延迟一样多。具体地,随着处理器产生更多的数据访问请求,已知的存储器系统的人工神经网络推理操作时间可能会进一步延迟。
[0329]
图10图解了根据图8的存储器系统的操作。
[0330]
参考图10,处理器210生成数据访问请求[1],并且人工神经网络存储器控制器220可以将与基于人工神经网络数据局部性模式生成的预测的数据访问请求相对应的存储器访问请求发送到存储器230。此时,即使存储器230有延迟,处理器210也会产生对应于预测的数据访问请求的存储器访问请求,使得当处理器210产生后续数据访问请求时,人工神经网络存储器控制器220可直接将由处理器210请求的数据提供给处理器210。
[0331]
例如,由处理器210生成的数据访问请求[1]被人工神经网络存储器控制器220接收以生成预测的数据访问请求[2]并且将对应于预测的数据访问请求[2]的存储器访问请求[2']发送到存储器230。存储器230可以在延迟之后将数据[2”]发送到人工神经网络存储器控制器220。然而,由存储器230提供的数据[2”]是对应于基于预测的数据访问请求[2]的存储器访问请求[2']的数据。因此,当处理器210产生后续数据访问请求[2]时,人工神经网络存储器控制器220可以立即将数据[2”]提供给处理器210。
[0332]
如果基于预测的数据访问请求的存储器访问请求和后续数据访问请求之间的时
间长于存储器230的延迟,则一旦从处理器210接收到后续数据访问请求,人工神经网络存储器控制器220就可以将数据提供给处理器210。在这种情况下,人工神经网络存储器控制器220可以基本上消除存储器230的延迟。
[0333]
换句话说,当基于预测的数据访问请求的存储器访问请求被发送到存储器230时,存储器230的延迟可以短于或等于从预测的数据访问请求的生成到后续数据访问请求的生成的时间。在这种情况下,一旦处理器210产生后续数据访问请求,人工神经网络存储器控制器220就可以立即提供数据而不会引起延迟。
[0334]
即使基于预测的数据访问请求的存储器访问请求和后续数据访问请求之间的时间比存储器230的延迟短,存储器230的延迟也会显著减少,即减少与在存储器访问请求和后续数据访问请求之间的时间一样多。
[0335]
根据上述配置,人工神经网络存储器控制器220可以基本上消除或减少待提供给处理器210的数据的延迟。
[0336]
在一些示例中,人工神经网络存储器系统的人工神经网络存储器控制器可以被配置为测量存储器的延迟或被提供有来自存储器的存储器的延迟值。
[0337]
根据上述配置,人工神经网络存储器控制器可以被配置为基于存储器的延迟,确定基于预测的数据访问请求生成存储器访问请求的时序。因此,人工神经网络存储器控制器可基于实质上最小化存储器的延迟的预测的数据访问请求来生成存储器访问请求。
[0338]
在一些示例中,人工神经网络存储器系统的存储器可以是被配置为包括更新存储器元件(即存储器元件阵列)的电压的刷新功能的存储器。人工神经网络存储器控制器可以被配置为选择性地控制对对应于与预测的数据访问请求对应的存储器访问请求的存储器的存储器地址区域的刷新。例如,存储器可以是包括刷新功能的sam或dram。
[0339]
如果dram不刷新存储单元的电压,则存储单元缓慢放电,使得存储的数据可能丢失。因此,存储器元件的电压需要在每个特定周期进行刷新。如果人工神经网络存储器控制器的存储器访问请求的时序与刷新时序重叠,则人工神经网络存储器系统可被配置为提前或延迟刷新存储器元件的电压的时序。
[0340]
人工神经网络存储器系统可基于人工神经网络数据局部性模式预测或计算生成存储器访问请求的时序。因此,人工神经网络存储器系统可以被配置为在存储器访问请求操作期间限制存储器元件的电压刷新。
[0341]
换句话说,人工神经网络操作的推理操作以精度的概念操作,使得即使存储的数据由于存储器元件的电压的延迟刷新而部分丢失,推理精度的降低可能基本上可以忽略不计。
[0342]
根据上述配置,可以通过调整存储器元件的电压刷新周期,根据来自存储器的存储器访问请求来向人工神经网络存储器系统提供数据。因此,可以提高人工神经网络根据存储器元件的电压刷新而降低的操作速度,而不会显著降低推理精度。
[0343]
在一些示例中,人工神经网络存储器系统的存储器可以被配置为进一步包括预充电功能,该预充电功能用特定电压对存储器的全局位线(bitline)充电。此时,人工神经网络存储器控制器可以被配置为选择性地向对应于与预测的数据访问请求对应的存储器访问请求的存储器的存储器地址区域提供预充电。
[0344]
在一些示例中,人工神经网络存储器控制器可以被配置为预充电或延迟存储器的
位线,该位线执行与基于人工神经网络数据局部性模式的预测的数据访问请求相对应的存储器任务。
[0345]
通常,存储器通过接收存储器访问请求来执行预充电操作以执行读取操作或写入操作。当一个存储器操作完成时,信号会留在执行数据读写操作的位线和每条数据输入/输出线中,使得只有当上述线被预充电到预定电平时,才能顺利执行后续的存储器操作。然而,由于预充电所需的时间相当长,当产生存储器访问请求的时序与预充电的时序重叠时,预充电时间可能会延迟存储器操作。因此,会延迟处理由处理器请求的数据访问请求的时间。
[0346]
人工神经网络存储器控制器可以基于人工神经网络数据局部性模式预测以特定顺序在特定存储器的位线上执行存储器操作。因此,人工神经网络存储器控制器可以提前或延迟预充电时间,以便预充电时序和在特定位线上执行存储器操作的时间不重叠。
[0347]
换句话说,人工神经网络模型的推理操作以精度的概念进行操作,使得即使存储的数据由于延迟预充电而部分丢失,推理精度的降低基本上可以忽略不计。
[0348]
换句话说,人工神经网络是通过模拟生物系统的大脑神经网络来建模的数学模型。称为神经元的人类神经细胞通过神经细胞之间的称为突触的连接处交换信息,神经细胞之间的信息交换非常简单,但是聚集了大量的神经细胞来创造智能。这种结构的优点在于,即使某些神经细胞传递错误信息,也不会影响整体信息,使得其对于小错误具有很强的鲁棒性。因此,由于上述特性,即使存储人工神经网络模型的数据的存储器的预充电和刷新功能被选择性地限制,人工神经网络模型的精度也基本上不会引起问题并且由于预充电或刷新导致的存储器延迟会减少。
[0349]
根据上述配置,可以改进根据预充电的人工神经网络的操作速度降低而基本上不降低推理精度。
[0350]
在一些示例中,人工神经网络存储器控制器可以被配置为基于人工神经网络数据局部性模式独立地控制存储器的刷新功能和预充电功能。
[0351]
图11根据本公开的又一示例图解了人工神经网络存储器系统300。
[0352]
参考图11,人工神经网络存储器系统300可以被配置为包括处理器310、包括高速缓冲存储器322的人工神经网络存储器控制器320和存储器330。
[0353]
可以包括在本公开的各种示例中的存储器330可以是专门用于人工神经网络操作的存储器,并且可以被称为顺序访问存储器(sam)。然而,本公开不限于此,并且本公开的各个示例的存储器可以指专用于可以基于人工神经网络数据局部性进行控制的人工神经网络操作的存储器设备。
[0354]
人工神经网络存储器系统300和人工神经网络存储器系统200基本相同,不同的是,人工神经网络存储器系统300还包括高速缓冲存储器322。因此,为了描述方便,将省略多余的描述。
[0355]
人工神经网络存储器系统300可以被配置为包括人工神经网络存储器控制器320,人工神经网络存储器控制器320包括高速缓冲存储器322,高速缓冲存储器322被配置为存储由存储器330响应于基于预测的数据访问请求的存储器访问请求而发送的数据。
[0356]
根据上述配置,人工神经网络存储器控制器320可以响应于基于来自存储器330的预测的数据访问请求的存储器访问请求读取数据并且将数据存储在高速缓冲存储器322
中。因此,当处理器310产生后续数据访问请求时,人工神经网络存储器控制器320可以立即将存储在高速缓冲存储器322中的数据提供给处理器310。
[0357]
高速缓冲存储器322的延迟比存储器330的延迟短得多。高速缓冲存储器322的带宽高于存储器330的带宽。
[0358]
包括高速缓冲存储器322的人工神经网络存储器系统300的人工神经网络模型处理性能可以优于人工神经网络存储器系统200。
[0359]
将参考图3的人工神经网络模型1300描述人工神经网络存储器系统300。
[0360]
人工神经网络模型1300可由特定编译器编译以在处理器310中操作。编译器可被配置为向人工神经网络存储器控制器320提供人工神经网络数据局部性模式。
[0361]
为了推理人工神经网络模型1300,处理器310可以被配置为根据基于人工神经网络数据局部性的顺序生成数据访问请求。因此,人工神经网络存储器控制器320可以监控数据访问请求以生成人工神经网络数据局部性模式1400。替代地,人工神经网络存储器控制器320可以存储已经提前生成的人工神经网络数据局部性模式1400。
[0362]
在下文中,将描述不生成人工神经网络数据局部性模式1400的示例。
[0363]
首先,处理器310可以产生对应于输入层1310的节点值读取模式的令牌[1]的数据访问请求。因此,人工神经网络存储器控制器320产生令牌[1]的存储器访问请求以将从存储器330发送的输入层1310的节点值发送到处理器310。
[0364]
接下来,处理器310可以生成与第一连接网络1320的权重值相对应的令牌[2]的数据访问请求。因此,人工神经网络存储器控制器320生成令牌[2]的存储器访问请求,以将从存储器330发送的第一连接网络1320的权重值发送到处理器310。
[0365]
接下来,处理器310接收输入层1310的节点值和第一连接网络1320的权重值以计算第一隐藏层1330的节点值。也就是说,处理器310可以生成对应于第一隐藏层1330的节点值写入模式的令牌[3]的数据访问请求。因此,人工神经网络存储器控制器320生成令牌[3]的存储器访问请求以将第一隐藏层1330的节点值存储在存储器330中。
[0366]
接下来,处理器310可以生成与第一隐藏层1330的节点值读取模式相对应的令牌[4]的数据访问请求。因此,人工神经网络存储器控制器320生成该令牌[4]的存储器访问请求,以将从存储器330发送的第一隐藏层1330的节点值发送到处理器310。
[0367]
接下来,处理器310可以生成与第二连接网络1340的权重值相对应的令牌[5]的数据访问请求。因此,人工神经网络存储器控制器320生成令牌[5]的存储器访问请求,以将从存储器330发送的第二连接网络1340的权重值发送到处理器310。
[0368]
接下来,处理器310接收第一隐藏层1330的节点值和第二连接网络1340的权重值以计算第二隐藏层1350的节点值。也就是说,处理器310可以生成对应于第二隐藏层1350的节点值写入模式的令牌[6]的数据访问请求。因此,人工神经网络存储器控制器320生成令牌[6]的存储器访问请求以将第二隐藏层1350的节点值存储在存储器330中。
[0369]
接下来,处理器310可以生成与第二隐藏层1350的节点值读取模式相对应的令牌[7]的数据访问请求。因此,人工神经网络存储器控制器320生成令牌[7]的存储器访问请求,以将从存储器330发送的第二隐藏层1350的节点值发送到处理器310。
[0370]
接下来,处理器310可以生成与第三连接网络1360的权重值相对应的令牌[8]的数据访问请求。因此,人工神经网络存储器控制器320生成令牌[8]的存储器访问请求,以将从
存储器330发送的第三连接网络1360的权重值发送到处理器310。
[0371]
接下来,处理器310接收第二隐藏层1350的节点值和第三连接网络1360的权重值以计算输出层1370的节点值。也就是说,处理器310可以生成对应于输出层1370的节点值写入模式的令牌[9]的数据访问请求。因此,人工神经网络存储器控制器320生成令牌[9]的存储器访问请求以将输出层1370的节点值存储在存储器330中。
[0372]
因此,人工神经网络存储器系统300可以将人工神经网络模型1300的推理结果存储在输出层1370中。
[0373]
在上述示例中,在人工神经网络存储器控制器320中尚未生成人工神经网络数据局部性模式1400。因此,根据上述示例,不能生成预测的数据访问请求。因此,由于人工神经网络存储器控制器320没有提前提供数据,所以在每次存储器访问请求中都可能导致存储器330的延迟。
[0374]
然而,由于人工神经网络存储器控制器320记录了数据访问请求,因此当处理器310再次生成对应于输入层1310的节点值读取模式的令牌[1]的数据访问请求时,可以生成人工生成神经网络数据局部性模式1400。
[0375]
在下文中,参考图4描述了人工神经网络数据局部性模式1400的生成。
[0376]
在以下示例中,生成人工神经网络数据局部性模式1400并且处理器310重复推理人工神经网络模型1300,但本公开不限于此。
[0377]
处理器310检测令牌[1]的重复数据访问请求以生成人工神经网络数据局部性模式1400。换言之,由于人工神经网络存储器控制器320从令牌[1]顺序地存储到令牌[9],因而当人工神经网络存储器控制器320再次检测到令牌[1]时,可以确定人工神经网络数据局部性。
[0378]
然而,如上所述,根据本公开的示例的人工神经网络存储器控制器不限于令牌。令牌仅用于描述方便,并且本公开的示例可以通过包括在数据访问请求和存储器访问请求中的识别信息来实现。
[0379]
例如,当处理器310产生对应于令牌[9]的数据访问请求时,人工神经网络存储器控制器320产生令牌[1]的预测的数据访问请求。相应地,人工神经网络存储器控制器320生成令牌[1]的存储器访问请求以将输入层1310的节点值提前存储在高速缓冲存储器322中。
[0380]
也就是说,如果令牌[9]的数据访问请求是人工神经网络模型1300的最后一步,则人工神经网络存储器控制器320可以预测作为人工神经网络模型1300的开始步骤的令牌[1]的数据访问请求将生成。
[0381]
接下来,当处理器310产生令牌[1]的数据访问请求时,人工神经网络存储器控制器320确定令牌[1]的预测的数据访问请求和令牌[1]的数据访问请求是否相同。当确定请求相同时,可以立即将存储在高速缓冲存储器322中的输入层1310的节点值提供给处理器310。
[0382]
此时,人工神经网络存储器控制器320生成令牌[2]的预测的数据访问请求。
[0383]
相应地,人工神经网络存储器控制器320生成令牌[2]的存储器访问请求,以将第一连接网络1320的权重值提前存储在高速缓冲存储器322中。
[0384]
接下来,当处理器310产生令牌[2]的数据访问请求时,人工神经网络存储器控制器320确定令牌[2]的预测的数据访问请求和令牌[2]的数据访问请求是否相同。当确定请
求相同时,可以立即将高速缓冲存储器322中存储的第一连接网络1320的节点值提供给处理器310。
[0385]
此时,人工神经网络存储器控制器320生成令牌[3]的预测的数据访问请求。
[0386]
接着,处理器310接收输入层1310的节点值和第一连接网络1320的权重值以计算第一隐藏层1330的节点值。当处理器310生成令牌[3]的数据访问请求时,人工神经网络存储器控制器320判断令牌[3]的预测的数据访问请求和令牌[3]的数据访问请求是否相同。当确定请求相同时,可以将计算出的第一隐藏层1330的节点值存储在存储器330和/或高速缓冲存储器322中。
[0387]
将另外描述高速缓冲存储器322。当相同的数据作为令牌[3]的存储器访问请求存储在存储器330中而没有高速缓冲存储器322,然后从存储器330中读取作为令牌[4]的存储器访问请求时,存储器330的延迟可以加倍。
[0388]
在这种情况下,人工神经网络存储器控制器320存储基于连续令牌的存储器地址值相同并且前一个令牌的操作模式为写入模式的事实而计算出的层的节点值,后续令牌的操作模式为读取模式,并且确定使用对应的节点值作为后续层的输入值。
[0389]
也就是说,当令牌[3]的数据存储在高速缓冲存储器322中时,可以在高速缓冲存储器322中处理与令牌[3]和令牌[4]对应的数据访问请求。因此,人工神经网络存储器控制器320可以被配置为不产生与令牌[3]的数据访问请求和令牌[4]的数据访问请求相对应的存储器访问请求。根据上述配置,可以通过令牌[3]的存储器访问请求和令牌[4]的存储器访问请求消除存储器330对存储器330的延迟。特别地,可以基于人工神经网络数据局部性模式1400来执行高速缓冲存储器322操作策略。
[0390]
此时,人工神经网络存储器控制器320生成令牌[4]的预测的数据访问请求。
[0391]
接着,当处理器310产生令牌[4]的数据访问请求时,人工神经网络存储器控制器320确定令牌[4]的预测的数据访问请求和令牌[4]的数据访问请求是否相同。当确定请求相同时,可以立即将高速缓冲存储器322中存储的第一隐藏层1330的节点值提供给处理器310。
[0392]
此时,人工神经网络存储器控制器320生成令牌[5]的预测的数据访问请求。
[0393]
相应地,人工神经网络存储器控制器320生成令牌[5]的存储器访问请求,以将第二连接网络1340的权重值提前存储在高速缓冲存储器322中。
[0394]
接着,当处理器310产生令牌[5]的数据访问请求时,人工神经网络存储器控制器320确定令牌[5]的预测的数据访问请求和令牌[5]的数据访问请求是否相同。当确定请求相同时,可以立即将高速缓冲存储器322中存储的第二连接网络1340的权重值提供给处理器310。
[0395]
此时,人工神经网络存储器控制器320生成令牌[6]的预测的数据访问请求。
[0396]
接着,处理器310接收第一隐藏层1330的节点值和第二连接网络1340的权重值以计算第二隐藏层1350的节点值。当处理器310产生令牌[6]的数据访问请求时,人工神经网络存储器控制器320确定令牌[6]的预测的数据访问请求和令牌[6]的数据访问请求是否相同。当确定请求相同时,可以将计算出的第二隐藏层1350的节点值存储在存储器330和/或高速缓冲存储器322中。
[0397]
此时,人工神经网络存储器控制器320生成令牌[7]的预测的数据访问请求。
[0398]
接着,当处理器310产生令牌[7]的数据访问请求时,人工神经网络存储器控制器320确定令牌[7]的预测的数据访问请求和令牌[7]的数据访问请求是否相同。当确定请求相同时,可以立即将高速缓冲存储器322中存储的第二隐藏层1350的节点值提供给处理器310。
[0399]
此时,人工神经网络存储器控制器320生成令牌[8]的预测的数据访问请求。
[0400]
相应地,人工神经网络存储器控制器320生成令牌[8]的存储器访问请求,以将第三连接网络1360的权重值提前存储在高速缓冲存储器322中。
[0401]
接下来,当处理器310产生令牌[8]的数据访问请求时,人工神经网络存储器控制器320确定令牌[8]的预测的数据访问请求和令牌[8]的数据访问请求是否相同。当确定请求相同时,可以立即将高速缓冲存储器322中存储的第三连接网络1360的权重值提供给处理器310。
[0402]
此时,人工神经网络存储器控制器320生成令牌[9]的预测的数据访问请求。
[0403]
接着,处理器310接收第二隐藏层1350的节点值和第三连接网络1360的权重值,以计算输出层1370的节点值。当处理器310产生令牌[9]的数据访问请求时,人工神经网络存储器控制器320确定令牌[9]的预测的数据访问请求和令牌[9]的数据访问请求是否相同。当确定请求相同时,可以将计算出的输出层1370的节点值存储在存储器330和/或高速缓冲存储器322中。
[0404]
因此,人工神经网络存储器系统300可以将人工神经网络模型1300的推理结果存储在输出层1370中。
[0405]
即使人工神经网络模型1300的推理以人工神经网络数据局部性模式1400结束,人工神经网络存储器系统300也可以准备好立即开始下一个推理。
[0406]
也就是说,图11的人工神经网络存储器系统300可以被配置为基于人工神经网络数据局部性生成预测的数据访问请求,确定提前数据访问请求与实际数据访问请求是否相同,以及如果请求相同,则进一步生成下一个预测的数据访问请求。根据上述配置,人工神经网络存储器控制器320可以在处理数据访问请求时消除或减少存储器330的延迟。
[0407]
在一些示例中,人工神经网络存储器控制器可以被配置为通过生成至少一个预测的数据访问请求来操作以最小化高速缓冲存储器的可用空间。
[0408]
也就是说,人工神经网络存储器控制器比较高速缓冲存储器的存储器可用空间和要存储的数据值的大小,并且当高速缓冲存储器的存储器可用空间存在时,生成至少一个预测的数据访问请求以最小化高速缓冲存储器的可用空间。
[0409]
也就是说,人工神经网络存储器控制器可以被配置为根据高速缓冲存储器的容量产生多个预测的数据访问请求。
[0410]
也就是说,人工神经网络存储器控制器可以被配置为基于高速缓冲存储器的剩余容量顺序地生成至少一个存储器访问请求以最小化高速缓冲存储器的剩余容量。
[0411]
将参考图2至6描述该示例。当处理器产生令牌[1]的数据访问请求时,人工神经网络存储器控制器产生令牌[2]的预测的数据访问请求以将第一连接网络1320的权重值提前存储在高速缓冲存储器中。接下来,人工神经网络存储器控制器可以提前将用于存储和读取与令牌[3]和令牌[4]对应的第一隐藏层1330的节点值计算结果的空间分配给高速缓冲存储器。接下来,人工神经网络存储器控制器可以提前将与令牌[5]对应的第二连接网络
1340的权重值存储在高速缓冲存储器中。当高速缓冲存储器中有余量时,人工神经网络存储器控制器可以被配置成进一步根据人工神经网络数据局部性模式依次生成预测的数据访问请求。也就是说,当高速缓冲存储器的容量有余量时,人工神经网络存储器控制器可以被配置为根据人工神经网络数据局部性模式提前将权重值存储在高速缓冲存储器中或提前确保用于存储人工神经网络操作结果的区域。
[0412]
如果高速缓冲存储器的容量足够,则人工神经网络模型1300的所有连接网络的权重值可以存储在高速缓冲存储器中。具体来说,在完成学习的人工神经网络模型的情况下,权重值是固定的。因此,当权重值驻留在高速缓冲存储器中时,可以消除通过存储器访问请求来读取权重值所引起的存储器延迟。
[0413]
根据上述配置,基于人工神经网络数据局部性存储高速缓冲存储器所需的数据以优化高速缓冲存储器的操作效率并且提高人工神经网络存储器系统300的处理速度。
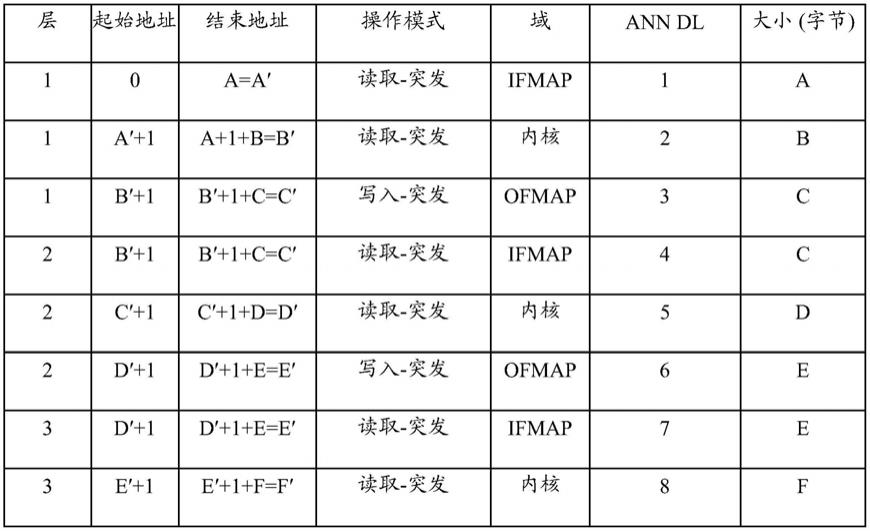
[0414]
根据上述配置,考虑到人工神经网络数据局部性模式和高速缓冲存储器的容量两者,高速缓冲存储器顺序地生成预测的数据访问请求,使得人工神经网络存储器系统的处理速度可以改进。
[0415]
根据上述配置,当处理器生成包括在人工神经网络数据局部性模式1400中的特定数据访问请求时,人工神经网络存储器控制器可以在该特定数据访问请求之后顺序地预测至少一个数据访问请求。例如,当处理器产生令牌[1]的数据访问请求时,人工神经网络存储器控制器可以预测对应的数据访问请求是按照令牌[2-3-4-5-6-7-8-9]的顺序产生的。
[0416]
根据上述配置,人工神经网络存储器控制器320可以使特定权重值驻留在高速缓冲存储器中持续特定时间段。例如,当处理器通过利用人工神经网络模型以每秒30次的速度进行推理时,特定层的权重值可以驻留在高速缓冲存储器中。在这种情况下,人工神经网络存储器控制器可以为每次推理重新利用存储在高速缓冲存储器中的权重值。因此,可以选择性地删除相应的存储器访问请求。因此,可以消除根据存储器访问请求的延迟。
[0417]
在一些示例中,高速缓冲存储器可以由多个分层的高速缓冲存储器配置。例如,高速缓冲存储器可以包括被配置为存储权重值的高速缓冲存储器或被配置为存储特征图的高速缓冲存储器。
[0418]
在一些示例中,当生成人工神经网络数据局部性模式1400时,人工神经网络存储器控制器可以被配置为基于包括在数据访问请求中的识别信息来预测权重值和节点值。因此,人工神经网络存储器控制器可以被配置为识别与权重值对应的数据访问请求。具体地,当假设完成学习使得连接网络的权重值固定时,在人工神经网络数据局部性模式1400中,权重值可以被配置为仅在读取模式下操作。因此,人工神经网络存储器控制器可以将令牌[2]、令牌[5]和令牌[8]确定为权重值。换句话说,令牌[1]是推理的开始步骤,使得可以将其确定为输入节点值。换句话说,令牌[9]是推理的最后一步,因此可以将其确定为输出节点值。换句话说,令牌[3]和[4]具有相同存储器地址值的写入模式和读取模式的顺序,使得令牌[3]和[4]可以被确定为隐藏层的节点值。然而,它可以根据人工神经网络模型的人工神经网络数据局部性而变化。
[0419]
人工神经网络存储器控制器可以被配置为分析人工神经网络数据局部性模式以确定数据访问请求是否是人工神经网络模型的权重值、内核窗口值、节点值、激活图值等。
[0420]
在一些示例中,人工神经网络存储器系统包括:处理器,其被配置为生成与人工神
经网络操作相对应的数据访问请求;人工神经网络存储器控制器,其被配置为存储由编译器生成的人工神经网络数据局部性模式并且生成预测的数据访问请求,该预测的数据访问请求基于人工神经网络数据局部性模式预测由处理器生成的数据访问请求的后续数据访问请求;以及存储器,其被配置为与人工神经网络存储器控制器通信。存储器可以被配置为根据从人工神经网络存储器控制器输出的存储器访问请求来操作。
[0421]
根据上述配置,人工神经网络存储器控制器可以被配置为具有从编译器生成的人工神经网络数据局部性模式。在这种情况下,人工神经网络存储器控制器可以允许由处理器正在处理的人工神经网络模型的数据访问请求基于由编译器生成的人工神经网络数据局部性模式提前在高速缓冲存储器中准备。具体地,由编译器生成的人工神经网络数据局部性模式可能比通过监控人工神经网络数据局部性生成的人工神经网络数据局部性模式更准确。
[0422]
换句话说,人工神经网络存储器控制器可以被配置为分别存储由编译器生成的人工神经网络数据局部性模式和通过独立监控数据访问请求而产生的人工神经网络数据局部性模式。
[0423]
图12图示了数据访问请求的示例性识别信息。
[0424]
由根据本公开的示例的处理器生成的数据访问请求可以被配置为进一步包括至少一条附加识别信息。附加识别信息也可以称为边带信号或边带信息。
[0425]
由处理器产生的数据访问请求可以是具有特定结构的接口信号。也就是说,数据访问请求可以是用于处理器和人工神经网络存储器控制器通信的接口信号。数据访问请求可以被配置为进一步包括附加位以附加提供人工神经网络操作所需的识别信息,但本公开不限于此,附加识别信息可以以各种方式提供。
[0426]
在一些示例中,人工神经网络存储器系统的数据访问请求可以被配置为进一步包括识别信息以识别其是否为人工神经网络操作,但本公开的示例不限于此.
[0427]
例如,人工神经网络存储器系统在数据访问请求中添加一位识别码,以识别由人工神经网络存储器控制器接收到的数据访问请求是否为与人工神经网络操作相关的数据访问请求。然而,根据本公开的示例的识别码的位数不受限制并且可以根据要识别的对象的情况的数量进行调整。
[0428]
例如,当识别码为[0]时,人工神经网络存储器控制器可以确定相应的数据访问请求与人工神经网络操作相关。
[0429]
例如,当识别码为[1]时,人工神经网络存储器控制器可以确定相应的数据访问请求与人工神经网络操作无关。
[0430]
在这种情况下,人工神经网络存储器控制器可以被配置为通过基于包括在数据访问请求中的识别信息仅记录与人工神经网络操作相关的数据访问请求来生成人工神经网络数据局部性模式。根据上述配置,人工神经网络存储器控制器可以不记录与人工神经网络操作无关的数据访问请求。通过这样做,可以提高通过记录数据访问请求生成的人工神经网络数据局部性模式的精度,但是本公开的示例不限于此。
[0431]
在一些示例中,人工神经网络存储器系统的数据访问请求可以被配置为进一步包括识别信息以识别人工神经网络操作是用于学习的操作还是用于推理的操作,但是本公开的示例不限于此。
[0432]
例如,人工神经网络存储器系统在数据访问请求中添加一位识别码,使得通过人工神经网络存储器控制器接收到的数据访问请求被配置成识别人工神经网络模型的操作类型是学习还是推理。然而,根据本公开的示例的识别码的位数不受限制并且可以根据要识别的对象的情况的数量进行调整。
[0433]
例如,当识别码为[0]时,人工神经网络存储器控制器可以确定对应的数据访问请求是学习操作。
[0434]
例如,当识别码为[1]时,人工神经网络存储器控制器可以确定相应的数据访问请求是推理操作。
[0435]
在这种情况下,人工神经网络存储器控制器可以被配置为通过单独记录学习操作的数据访问请求和推理操作的数据访问请求来生成人工神经网络数据局部性模式。例如,在学习模式中,还可以包括更新人工神经网络模型的每一层和/或内核窗口的权重值,并且确定训练后的人工神经网络模型的推理精度的评估步骤。因此,即使人工神经网络模型的结构相同,在学习操作和推理操作中待由处理器处理的人工神经网络数据局部性也可能不同。
[0436]
根据上述配置,人工神经网络存储器控制器可以被配置为分别生成特定人工神经网络模型的学习模式的人工神经网络数据局部性模式和推理模式的人工神经网络数据局部性模式。通过这样做,可以提高通过由人工神经网络存储器控制器记录数据访问请求而生成的人工神经网络数据局部性模式的精度,但是本公开的示例不限于此。
[0437]
在一些示例中,人工神经网络存储器系统的数据访问请求可以被配置有包括识别信息的操作模式,以识别存储器读取操作和存储器写入操作,但不限于此,使得人工神经网络存储器系统的数据访问请求可以配置有操作模式,该操作模式还包括用于识别覆盖操作和/或保护操作的识别信息,但是本公开的示例不限于此。
[0438]
例如,在人工神经网络存储器系统的数据访问请求中增加一位识别码,以包括读取操作和写入操作。替代地,在人工智能网络存储器系统的数据访问请求中增加两位识别码,用于识别读取操作、写入操作、覆盖操作和保护操作。然而,根据本公开的示例的识别码的位数不受限制并且可以根据要识别的对象的情况的数量进行调整。
[0439]
换句话说,对于人工神经网络存储器系统的操作,数据访问请求需要包括识别信息以识别存储器地址值和读取操作,以及写入操作。人工神经网络存储器控制器接收数据访问请求以产生对应的存储器访问请求以执行存储器操作。
[0440]
例如,当识别码为[000]时,人工神经网络存储器控制器可以被配置为将相应的数据访问请求确定为读取操作。
[0441]
例如,当识别码为[001]时,人工神经网络存储器控制器可以被配置为将相应的数据访问请求确定为写入操作。
[0442]
例如,当识别码为[010]时,人工神经网络存储器控制器可以被配置为将相应的数据访问请求确定为覆盖操作。
[0443]
例如,当识别码为[011]时,人工神经网络存储器控制器可以被配置为将相应的数据访问请求确定为保护操作。
[0444]
例如,当识别码为[100]时,人工神经网络存储器控制器可以被配置为将相应的数据访问请求确定为读取-突发操作。
[0445]
例如,当识别码为[001]时,人工神经网络存储器控制器可以被配置为将对应的数据访问请求确定为写入-突发操作。然而,本公开的示例不限于此。
[0446]
根据上述配置,人工神经网络存储器控制器根据读取模式或写入模式控制存储器以向该存储器提供人工神经网络模型的各种数据或将该数据存储在该存储器中。
[0447]
根据上述配置,人工神经网络存储器控制器可以在人工神经网络的学习操作期间通过覆盖操作更新特定层的权重值。具体地,更新后的权重值存储在相同的存储器地址值中,从而可以不分配新的存储器地址。因此,在学习操作期间覆盖模式可能比写入模式更有效。
[0448]
根据上述配置,人工神经网络存储器控制器可以通过保护模式来保护存储在特定存储器地址中的数据。具体来说,在多个用户同时访问的环境(如服务器)中,人工神经网络模型的数据不能随意消除。此外,可以通过保护模式来保护结束学习的人工神经网络模型的权重值。
[0449]
在一些示例中,人工神经网络存储器系统的数据访问请求可以被配置为进一步包括能够识别推理数据的识别信息、权重、特征图、学习数据集、评估数据集等等,但本公开的示例不限于此。
[0450]
例如,人工神经网络存储器系统可以被配置为向数据访问请求添加3位识别码以使得人工神经网络存储器控制器能识别要访问的数据的域。然而,根据本公开的示例的识别码的位数不受限制并且可以根据要识别的对象的情况的数量进行调整。
[0451]
例如,当识别码为[000]时,人工神经网络存储器控制器可以确定对应的数据是与人工神经网络模型无关的数据。
[0452]
例如,当识别码为[001]时,人工神经网络存储器控制器可以确定对应的数据为人工神经网络模型的推理数据。
[0453]
例如,当识别码为[010]时,人工神经网络存储器控制器可以确定对应的数据为人工神经网络模型的特征图。
[0454]
例如,当识别码为[011]时,人工神经网络存储器控制器可以确定对应的数据为人工神经网络模型的权重。
[0455]
例如,当识别码为[100]时,人工神经网络存储器控制器可以确定对应的数据为人工神经网络模型的学习数据集。
[0456]
例如,当识别码为[101]时,人工神经网络存储器控制器可以确定对应的数据为人工神经网络模型的推理数据集。
[0457]
根据上述配置,人工神经网络存储器控制器可以被配置为识别人工神经网络模型的数据的域并且分配存储与域对应的数据的存储器的地址。例如,人工神经网络存储器控制器可以设置分配给域的存储器区域的起始地址和结束地址。根据上述配置,可以存储分配给域的数据以对应于人工神经网络数据局部性模式的顺序。
[0458]
例如,人工神经网络模型的域的数据可以顺序地存储在分配给该域的存储器区域中。此时,存储器可以是支持读取突发功能的存储器。根据上述配置,当人工神经网络存储器控制器从存储器读取特定域的数据时,特定数据可以被配置为根据人工神经网络数据局部性模式被存储以针对读取突发功能进行优化。也就是说,人工神经网络存储器控制器可以被配置为考虑到读取突发功能来设置存储器的存储区域。
[0459]
在一些示例中,存储器还包括读取突发功能,并且至少一个人工神经网络存储器控制器可以被配置为考虑到读取突发功能来写入至少一个存储器的存储区域。
[0460]
在一些示例中,人工神经网络存储器系统的数据访问请求可以被配置为进一步包括识别信息以识别人工神经网络模型的量化,但是本公开的示例不限于此。
[0461]
例如,当数据访问请求至少包括存储器地址值、域和量化识别信息时,人工神经网络存储器系统可以被配置为识别域的数据的量化信息。
[0462]
例如,当识别码为[00001]时,人工神经网络存储器控制器可以确定对应的数据是量化为一位的数据。
[0463]
例如,当识别码为[11111]时,人工神经网络存储器控制器可以确定对应的数据是量化为32位的数据。
[0464]
在一些示例中,可以在数据访问请求中选择性地包括各种识别信息。
[0465]
根据上述配置,人工神经网络存储器控制器分析数据访问请求的识别码以生成更准确的人工神经网络数据局部性模式。进一步地,计算出每个识别信息以选择性地控制存储器的存储策略。
[0466]
例如,当识别学习和推理时,可以生成每个人工神经网络数据局部性模式。
[0467]
例如,当识别出数据的域时,建立将人工神经网络数据局部性模式的数据存储在特定存储器区域的策略,以提高存储器操作的效率。
[0468]
在一些示例中,当人工神经网络存储器系统被配置为处理多个人工神经网络模型时,人工神经网络存储器控制器可以被配置为进一步生成人工神经网络模型的识别信息,例如,附加识别信息,例如第一个人工神经网络模型或第二个人工神经网络模型。此时,人工神经网络存储器控制器可以被配置为基于人工神经网络模型的人工神经网络数据局部性来区分人工神经网络模型,但本公开不限于此。
[0469]
图12所示的边带信号和人工神经网络(ann)数据局部性信息可以选择性地集成或分离。
[0470]
人工神经网络计算:可以确定是否在sam存储器控制器(sam memory controller)中执行了相应数据的ann操作。
[0471]
操作类型:可以在sam存储器控制器中确定相应的数据是训练还是推理(推理模式下权重值更新的时间表)。
[0472]
操作模式:可以在sam存储器控制器中控制ram(在内核情况下,其可以看域刷新,而在特征图情况下,其可以被读取-丢弃)
[0473]
域(domain):其可以是sam存储器控制器中的存储器映射(memory map)设置所需的信息。(域可以根据ann数据局部性信息将相同的数据分配到特定区域。)
[0474]
量化:sam存储器控制器可以提供相应数据的量化信息。
[0475]
ann模型#:sam存储器控制器可以根据ann数据局部性信息将每个模型分配给memory map。可以确保最小ann的总数据大小。
[0476]
多线程(multi-thread):sam存储器控制器可以共享内核并分别根据每个ann模型的线程数分配单独的特征图。
[0477]
ann数据局部性:其是意指ann数据局部性信息的特定处理阶段的信息。
[0478]
另一方面,所有边带信号都可以实现为packet。
[0479]
图13是用于说明人工神经网络存储器系统的每单元操作的能量消耗的示图。
[0480]
参考图13,在表中,示意性地说明了人工神经网络存储器系统300的每单元操作消耗的能量。能量消耗可以解释为分配到存储器访问、加法操作和乘法操作。
[0481]“8b add”是指加法器的8位整数加法操作。8位整数加法操作可能消耗0.03pj的能量。
[0482]“16b add”是指加法器的16位整数加法操作。16位整数加法操作可能消耗0.05pj的能量。
[0483]“32b add”是指加法器的32位整数加法操作。32位整数加法操作可能消耗0.1pj的能量。
[0484]“16b fp add”是指加法器的16位浮点加法操作。16位浮点加法操作可能消耗0.4pj的能量。
[0485]“32b fp add”是指加法器的32位浮点加法操作。32位浮点加法操作可能消耗0.9pj的能量。
[0486]“8b mult”是指乘法器的8位整数乘法操作。8位整数乘法操作可能消耗0.2pj的能量。
[0487]“32b mult”是指乘法器的32位整数乘法操作。32位整数乘法操作可能消耗3.1pj的能量。
[0488]“16b fp mult”是指乘法器的16位浮点乘法操作。16位浮点乘法操作可能消耗1.1pj的能量。
[0489]“32b fp mult”是指乘法器的32位浮点乘法操作。32位浮点乘法操作可能消耗3.7pj的能量。
[0490]“32b sram read”指的是当人工神经网络存储器系统300的高速缓冲存储器322是静态随机存取存储器(sram)时的32位数据读取访问。将32位数据从高速缓冲存储器322读取到处理器310可能会消耗5pj的能量。
[0491]“32b dram read”是指当人工神经网络存储器系统300的存储器330是dram时的32位数据读取访问。将32位数据从存储器330读取到处理器310可能消耗640pj的能量。能量单位是皮焦耳(pj)。
[0492]
当比较由人工神经网络存储器系统300执行的32位浮点乘法和8位整数乘法时,每单元操作消耗的能量的差异约为18.5倍。当从由dram构成的存储器330读取32位数据和从由sram构成的高速缓冲存储器322读取32位数据时,每单元操作所消耗的能量的差异约为128倍。
[0493]
也就是说,从功耗的角度来看,数据的位大小越大,功耗越大。此外,当使用浮点操作时,功耗比整数操作增加更多。此外,当从dram读取数据时,功耗迅速增加。
[0494]
在根据本公开的又一示例的人工神经网络存储器系统300中,高速缓冲存储器322的容量可以被配置为足以存储人工神经网络模型1300的所有数据值。
[0495]
根据示例的高速缓冲存储器不限于sram。能够像sram一样执行高速操作的静态存储器的示例包括sram、mram、stt-mram、emram、ost-mram等。此外,mram、stt-mram、emram和ost-mram是具有非易失性特性的静态存储器。因此,当人工神经网络存储器系统300的电源被关闭,然后重新启动时,人工神经网络模型1300不需要再次从存储器330中提供,但是根
据本公开的示例不限于此。
[0496]
根据上述配置,当人工神经网络存储器系统300基于人工神经网络数据局部性模式1400执行人工神经网络模型1300的推理操作时,由于存储器330的读取操作引起的功耗会显著减少。
[0497]
图14是用于解释根据本公开的各种示例的人工神经网络存储器系统的示意图。
[0498]
在下文中,将参照图14描述根据本公开的各种示例。图14可以解释可以执行根据本公开的各种示例的各种情况的数量。
[0499]
根据本公开的各种示例,人工神经网络存储器系统400包括至少一个处理器、至少一个存储器和至少一个人工神经网络存储器控制器amc,该至少一个人工神经网络存储器控制器amc被配置为包括至少一个处理器并接收来自至少一个处理器的数据访问请求,以向至少一个存储器提供该存储器访问请求。至少一个amc可以被配置为与示例性人工神经网络存储器控制器120、220和320基本相同。然而,不限于此,并且所述人工神经网络存储器系统400的一个人工神经网络存储器控制器可以被配置为不同于其他人工神经网络存储器控制器。在下文中,为描述方便起见,将省略人工神经网络存储器控制器411、412、413、414、415、416和517以及上述人工神经网络存储器控制器120、220和320的重复描述。
[0500]
至少一个人工神经网络存储器控制器被配置为连接至少一个处理器和至少一个存储器。此时,在至少一个处理器和至少一个存储器之间的数据传输路径中,可能存在对应的人工神经网络数据局部性。因此,位于数据传输路径中的人工神经网络存储器控制器可以被配置为提取相应的人工神经网络数据局部性模式。
[0501]
每个amc可以被配置为监控每个数据访问请求以生成人工神经网络数据局部性模式。人工神经网络存储器系统400可以被配置为包括至少一个处理器。至少一个处理器可以被配置为单独或与其他处理器合作处理人工神经网络操作。
[0502]
人工神经网络存储器系统400可以被配置为包括至少一个内部存储器。人工神经网络存储器系统400可以被配置为连接到至少一个外部存储器。内部存储器或外部存储器可以包括动态ram(dram)、高带宽存储器(hbm)、静态ram(sram)、可编程rom(prom)、可擦除prom(eprom)、电可擦除prom(eeprom)、闪存、铁电ram(fram)、闪存、磁ram(mram)、硬盘、相变存储器件(相变ram)等,但本公开不限于此。
[0503]
外部存储器(external mem1、external mem2)或内部存储器(internal mem1、internal mem2)可以通过相应的存储器接口(external mem i/f)与人工神经网络存储器系统400进行通信。
[0504]
处理器(processor 1)可以包括与系统总线通信的总线接口单元(biu)。
[0505]
人工神经网络存储器系统400可以包括连接到外部存储器(external mem)的外部存储器接口。外部存储器接口将存储器访问请求传送到人工神经网络存储器系统400的至少一个外部存储器,并且可以响应于来自至少一个外部存储器的存储器访问请求而接收数据。示例性人工神经网络存储器控制器120、220和320中公开的配置和功能被分布到将设置在人工神经网络存储器系统400的特定位置的多个人工神经网络存储器控制器411、412、413、414、415、416和517。在一些示例中,处理器可以被配置为包括人工神经网络存储器控制器。
[0506]
在一些示例中,存储器可以是dram,并且在这种情况下,人工神经网络存储器控制
器可以被配置为包括在dram中。
[0507]
例如,人工神经网络存储器控制器411、412、413、414、415、416和517中的至少一个可以被配置为包括高速缓冲存储器。此外,高速缓冲存储器可以被配置为包括在处理器、内部存储器和/或外部存储器中。
[0508]
例如,人工神经网络存储器控制器411、412、413、414、415、416和517中的至少一个可以被配置为分布在存储器和处理器之间的数据传输路径中。
[0509]
例如,可以在人工神经网络存储器系统400中实现的人工神经网络存储器控制器可以由以下项中的一项配置:独立配置的人工神经网络存储器控制器411;包括在系统总线中的人工神经网络存储器控制器412;被配置作为处理器的接口的人工神经网络存储器控制器413;包括在内部存储器的存储器接口和系统总线之间的包装块中的人工神经网络存储器控制器414;包括在内部存储器的存储器接口中的人工神经网络存储器控制器;包括在内部存储器中的人工神经网络存储器控制器415;包括在与外部存储器对应的存储器接口中的人工神经网络存储器控制器;包括在外部存储器的存储器接口和系统总线之间的包装块中的人工神经网络存储器控制器416和/或包括在外部存储器中的人工神经网络存储器控制器517。然而,根据本公开的示例的人工神经网络存储器控制器不限于此。
[0510]
例如,由第一人工神经网络存储器控制器411和第二人工神经网络存储器控制器412生成的个体人工神经网络数据局部性模式可以彼此相同或不同。
[0511]
换句话说,第一人工神经网络存储器控制器411可以被配置为通过系统总线连接第一处理器(processor 1)和第一内部存储器internal mem1。此时,在第一处理器(processor 1)与第一内部存储器internal mem1之间的数据传输路径中,可能存在第一人工神经网络数据局部性。
[0512]
在这种情况下,在所述路径中示出了第三人工神经网络存储器控制器413。然而,这仅仅是说明性的并且可以省略第三人工神经网络存储器控制器413。也就是说,当处理器和存储器之间设置至少一个人工神经网络存储器控制器时,可以生成由处理器处理的人工神经网络模型的人工神经网络数据局部性模式。
[0513]
换言之,第二人工神经网络存储器控制器412可以被配置为连接第二处理器(processor 2)和第一外部存储器external mem1。此时,在第二处理器(processor 2)与第一外部存储器external mem1之间的数据传输路径中,可能存在第二人工神经网络数据局部性。
[0514]
例如,由第一处理器(processor 1)处理的第一人工神经网络模型可以是对象识别模型,而由第二处理器(processor 2)处理的第二人工神经网络模型可以是语音识别模型。因此,人工神经网络模型可能彼此不同,对应的人工神经网络数据局部性模式也可能彼此不同。
[0515]
也就是说,由人工神经网络存储器控制器411、412、413、414、415、416和517产生的人工神经网络数据局部性模式可以根据由相应的处理器产生的数据访问请求的模式特征来确定。
[0516]
也就是说,即使人工神经网络存储器系统400的人工神经网络存储器控制器设置在任意处理器和任意存储器之间,人工神经网络存储器控制器也可以提供适应性以在相应位置生成人工神经网络数据局部性模式。换言之,当两个处理器协作以并行处理一个人工
神经网络模型时,可以将人工神经网络模型的人工神经网络数据局部性模式划分以分配给每个处理器。例如,第一层的卷积运算由第一处理器处理,第二层的卷积运算由第二处理器处理,以分配人工神经网络模型的操作。
[0517]
在这种情况下,即使人工神经网络模型相同,由各个处理器处理的人工神经网络模型的人工神经网络数据局部性也可以在数据访问请求的单元中进行重构。在这种情况下,每个人工神经网络存储器控制器可以提供适应性以生成与由人工神经网络存储器控制器处理的处理器的数据访问请求相对应的人工神经网络数据局部性模式。
[0518]
数据访问请求可以按字线产生。人工神经网络的ann dl可以根据数据访问请求进行配置。
[0519]
根据上述配置,即使多个人工神经网络存储器控制器分布在多个处理器和多个存储器之间,人工神经网络存储器系统400的性能也可以通过被生成以适合每种情况的人工神经网络数据局部性模式进行优化。也就是说,每个人工神经网络存储器控制器在其位置分析人工神经网络数据局部性,以针对实时可变处理的人工神经网络操作进行优化。
[0520]
在一些示例中,人工神经网络存储器控制器411、412、413、414、415、416和517中的至少一个可以被配置为确认存储器数量、存储器类型、存储器有效带宽、存储器延迟、和存储器大小中的至少一个信息。
[0521]
在一些示例中,人工神经网络存储器控制器411、412、413、414、415、416和517中的至少一个可以被配置为测量响应于存储器访问请求的存储器的有效带宽。这里,存储器可以是至少一个存储器,并且每个人工神经网络存储器控制器可以测量与每个存储器通信的通道的有效带宽。有效带宽可以通过测量人工神经网络存储器控制器产生存储器访问请求和存储器访问请求结束的时间和数据传输位率来计算。
[0522]
在一些示例中,人工神经网络存储器控制器411、412、413、414、415、416和517中的至少一个可以被配置为具有响应于存储器访问请求的至少一个存储器的必要带宽。
[0523]
在一些示例中,人工神经网络存储器系统400包括多个存储器,并且至少一个人工神经网络存储器控制器可以被配置为测量多个存储器的有效带宽。
[0524]
在一些示例中,人工神经网络存储器系统400包括多个存储器并且至少一个人工神经网络存储器控制器可以被配置为测量多个存储器的延迟。
[0525]
也就是说,至少一个人工神经网络存储器控制器可以被配置为执行与其连接的存储器的自动校准。自动校准可以被配置为在人工神经网络存储器系统启动时或在特定周期时执行。至少一个人工神经网络存储器控制器可以被配置为通过自动校准来收集诸如与其相连的存储器的数量、存储器的类型、存储器的有效带宽、存储器的延迟和存储器的大小等信息。
[0526]
根据上述配置,人工神经网络存储器系统400可以知道对应于人工神经网络存储器控制器的存储器的延迟和有效带宽。
[0527]
根据上述配置,即使独立的人工神经网络存储器控制器连接到系统总线,正由处理器处理的人工神经网络模型的人工神经网络数据局部性也被生成以控制存储器。
[0528]
在一些示例中,人工神经网络存储器系统400的至少一个人工神经网络存储器控制器可以被配置为计算将人工神经网络数据局部性模式重复一次所花费的时间以及计算数据大小,以计算人工神经网络操作所需的有效带宽。具体地,当人工神经网络数据局部性
模式中包含的数据访问请求全部处理完毕后,确定处理器完成人工神经网络模型的推理。人工神经网络存储器系统400可以被配置为基于人工神经网络数据局部性模式测量执行一次推理所花费的时间,以计算每秒推理(ips)的次数。此外,人工神经网络存储器系统400可以被提供有来自处理器的每秒目标推理数信息。例如,特定应用需要30ips作为特定人工神经网络模型的推理率。如果测量的ips低于目标ips,则人工神经网络存储器控制器400可以被配置为操作以提高处理器的人工神经网络模型处理速度。
[0529]
在一些示例中,人工神经网络存储器系统400可以被配置为包括被配置为控制人工神经网络存储器控制器、处理器和存储器的通信的系统总线。进一步地,至少一个人工神经网络存储器控制器可以被配置为具有系统总线的主控权。
[0530]
换句话说,人工神经网络存储器系统400可能不是用于人工神经网络操作的专用设备。在这种情况下,人工神经网络存储器系统400的系统总线可以连接各种外围设备,例如wifi设备、显示器、相机或麦克风。在这种情况下,人工神经网络存储器系统400可以被配置为控制系统总线的带宽,以使人工神经网络操作稳定。
[0531]
在一些示例中,至少一个人工神经网络存储器控制器可以操作以在存储器访问请求的处理时间优先处理人工神经网络操作,并在其他(剩余)时间处理人工神经网络操作以外的操作。
[0532]
在一些示例中,至少一个人工神经网络存储器控制器可以被配置为确保系统总线的有效带宽,直到至少一个存储器完成存储器访问请求。
[0533]
在一些示例中,至少一个人工神经网络存储器控制器设置在系统总线中,并且系统总线可以被配置为基于在该系统总线中生成的人工神经网络数据局部性模式来动态地改变系统总线的带宽。
[0534]
在一些示例中,至少一个人工神经网络存储器控制器设置在系统总线中,并且至少一个人工神经网络存储器控制器可以被配置为将系统总线的控制权限增加到高于当没有存储器访问请求系时的控制权限,直到至少一个存储器完成对存储器访问请求的响应。
[0535]
在一些示例中,至少一个人工神经网络存储器控制器可以被配置为设置多个处理器中处理人工神经网络操作的处理器的数据访问请求的优先级为高于处理人工神经网络操作以外的操作的处理器的数据访问请求的优先级。
[0536]
在一些示例中,人工神经网络存储器控制器可以被配置为直接控制存储器。
[0537]
在一些示例中,人工神经网络存储器控制器被包括在存储器中,并且人工神经网络存储器控制器可以被配置为生成至少一个访问队列。人工神经网络存储器控制器可以被配置为单独生成专用于人工神经网络操作的访问队列。
[0538]
在一些示例中,多个存储器中的至少一个可以是sam或dram。在这种情况下,至少一个人工神经网络存储器控制器可以被配置为重新调整存储器访问请求的访问队列。访问队列重新调整可以是访问队列重新排序。
[0539]
在一些示例中,人工神经网络存储器控制器可以被配置为包括多个存储器访问请求的访问队列。在这种情况下,第一访问队列可以是专用于人工神经网络操作的访问队列,而第二访问队列可以是用于人工神经网络操作以外的操作的访问队列。人工神经网络存储器控制器可以被配置为通过根据优先级设置选择每个访问队列来提供数据。
[0540]
在一些示例中,至少一个人工神经网络存储器控制器可以被配置为计算系统总线
所需的特定带宽以基于人工神经网络数据局部性模式处理特定存储器访问请求,以及至少一个人工神经网络存储器控制器可以被配置为基于特定带宽控制系统总线的有效带宽。
[0541]
根据上述配置,人工神经网络存储器系统400可以被配置为基于人工神经网络数据局部性模式降低各种外围设备的存储器访问请求的优先级或提高提前数据访问请求的优先级。
[0542]
根据上述配置,人工神经网络存储器控制器重新调整系统总线的数据访问请求的处理顺序,以在处理人工神经网络操作的同时充分利用系统总线的带宽,并且在没有人工神经网络操作时,产生其他外围设备的处理数据的带宽。
[0543]
根据上述配置,人工神经网络存储器控制器可以基于人工神经网络数据局部性模式重新调整数据访问请求的处理顺序。此外,人工神经网络存储器控制器基于包含在数据访问请求中的识别信息重新调整优先级。也就是说,从人工神经网络操作的角度来看,系统总线的有效带宽是动态变化的,从而可以提高有效带宽。因此,可以提高系统总线的操作效率。因此,从人工神经网络存储器控制器的观点来看,可以提高系统总线的有效带宽。
[0544]
在一些示例中,至少一个人工神经网络存储器控制器可以被配置为执行数据访问请求的机器学习。也就是说,至少一个人工神经网络存储器控制器还可以包括人工神经网络模型,该人工神经网络模型被配置为机器学习人工神经网络数据局部性模式。也就是说,人工神经网络数据局部性模式是机器学习的,以便学习特定模式(从而根据实际人工神经网络数据局部性在数据访问请求处理过程中中断另一个数据访问请求),以进行预测。
[0545]
当产生预测的数据访问请求时,可以对嵌入人工神经网络存储器控制器中的人工神经网络模型进行机器训练,以将系统总线的控制权限提高到高于预测的数据访问请求未生成时的控制权。
[0546]
在一些示例中,至少一个人工神经网络存储器控制器还包括多个分层高速缓冲存储器,并且至少一个人工神经网络存储器控制器可以被配置为在多个分层高速缓冲存储器的层之间执行数据访问请求的机器学习。
[0547]
在一些示例中,至少一个人工神经网络存储器控制器可以被配置为具有多个分层高速缓冲存储器的每一层的有效带宽、功耗和延迟信息中的至少一个。
[0548]
根据上述配置,人工神经网络存储器控制器可以被配置为通过机器学习产生人工神经网络数据局部性模式,并且经机器学习的人工神经网络数据局部性模式可以是在与人工神经网络操作无关的各种数据访问请求以特定模式生成时提高预测特定模式发生的概率。进一步地,通过强化学习来预测由处理器处理的各种人工神经网络模型和其他操作的特性,以提高人工神经网络操作的效率。
[0549]
在一些示例中,至少一个人工神经网络存储器控制器可以被配置为基于多个存储器中的每一个的有效带宽和延迟来划分和存储要存储在多个存储器中的数据。
[0550]
例如,数据由l位的位组配置,并且多个存储器包括第一存储器和第二存储器。第一存储器被配置为基于第一有效带宽或第一延迟将来自l位的位组的m位数据进行划分并存储,并且第二存储器被配置为基于第二有效带宽或第二延迟将来自l位的位组中的n位数据进行划分和存储。m位和n位的总和可以被配置为小于或等于l位。进一步地,所述多个存储器还包括第三存储器,并且所述第三存储器被配置为基于第三有效带宽或第三延迟存储来自l位的位组的o位数据,以及m位、n位和o位的总和可以被配置为等于l位。
[0551]
例如,数据由p个数据包构成,并且多个存储器包括第一存储器和第二存储器。第一存储器被配置为基于第一有效带宽或第一延迟存储p个数据包中的r个数据包,第二存储器被配置为基于第二有效带宽或第二延迟存储p个数据包中的s个数据包。r和s的和可以被配置为小于或等于p。另外,多个存储器还包括第三存储器,并且第三存储器被配置为基于第三有效带宽或第三延迟存储来自p个数据包的t个数据包,r、s和t之和可配置为等于p。
[0552]
根据上述配置,当一个存储器的带宽较低时,人工神经网络存储器控制器可以分配要存储或读取的数据,从而可以提高存储器的有效带宽。例如,人工神经网络存储器控制器可以被配置为将量化的权重值的8位划分以在第一存储器中存储或读取4位以及在第二存储器中存储或读取4位。因此,从人工神经网络存储器控制器的角度来看,可以提高存储器的有效带宽。
[0553]
人工神经网络存储器控制器可以被配置为进一步包括高速缓冲存储器,该高速缓冲存储器被配置为合并和存储被划分以存储在多个存储器中的数据。也就是说,至少一个人工神经网络存储器控制器还包括高速缓冲存储器,并且可以被配置为合并被分布以存储在多个存储器中的数据以将合并的数据存储在高速缓冲存储器中。因此,可以向处理器提供合并的数据。
[0554]
为了合并划分的数据,至少一个人工神经网络存储器控制器可以被配置为存储被划分以存储在多个存储器中的数据的划分信息。本公开的各种示例将描述如下。
[0555]
根据本公开的一个示例,人工神经网络存储器系统可以被配置为包括:至少一个处理器,其被配置为生成对应于人工神经网络操作的数据访问请求;和至少一个人工神经网络存储器控制器,其被配置为通过顺序记录数据访问请求来生成人工神经网络操作的人工神经网络数据局部性模式,并且基于人工神经网络数据局部性模式生成预测的数据访问请求,该提前数据访问请求预测由至少一个处理器生成的数据访问请求的后续数据访问请求。这里,人工神经网络数据局部性是在处理器-存储器级别重构的人工神经网络数据局部性。
[0556]
根据本公开的示例,人工神经网络存储器系统可以被配置为包括:至少一个处理器,其被配置为处理人工神经网络模型;和至少一个人工神经网络存储器控制器,其被配置为存储人工神经网络模型的人工神经网络数据局部性信息,并且基于人工神经网络数据局部性信息预测待由至少一个处理器请求的数据,以生成预测的数据访问请求。
[0557]
人工神经网络存储器系统可以被配置为进一步包括至少一个存储器和系统总线,该系统总线被配置为控制人工神经网络存储器控制器、至少一个处理器和至少一个存储器的通信。根据本公开的示例,人工神经网络存储器系统包括处理器、存储器和高速缓冲存储器,并且被配置为基于人工神经网络数据局部性信息生成包括待由处理器请求的数据的预测的数据访问请求,并且在处理器请求之前存储与来自在高速缓冲存储器中的存储器的预测的数据访问请求对应的数据。
[0558]
根据本公开的示例,人工神经网络存储器系统可以被配置为以第一模式和第二模式中的任意一者操作,第一模式被配置为通过接收人工神经网络数据局部性信息来操作,而第二模式被配置为通过观察由处理器产生的数据访问请求以预测人工神经网络数据局部性信息来操作。
[0559]
至少一个人工神经网络存储器控制器可以被配置为基于人工神经网络数据局部
性模式依次进一步生成预测的数据访问请求。
[0560]
至少一个人工神经网络存储器控制器可以被配置为在生成后续数据访问请求之前生成预测的数据访问请求。
[0561]
至少一个处理器可以被配置为向至少一个人工神经网络存储器控制器发送数据访问请求。
[0562]
至少一个人工神经网络存储器控制器可以被配置为响应于数据访问请求而输出预测的数据访问请求。
[0563]
数据访问请求可以被配置为进一步包括存储器地址。
[0564]
数据访问请求可以被配置为进一步包括存储器的起始地址和结束地址。
[0565]
至少一个人工神经网络存储器控制器可以被配置为基于由至少一个处理器生成的数据访问请求和由人工神经网络存储器控制器生成的预测的数据访问请求中的一者来生成存储器访问请求。
[0566]
数据访问请求可以被配置为进一步包括存储器的起始地址和连续数据读取触发器。
[0567]
数据访问请求可以被配置为进一步包括存储器的起始地址和连续数据的数量信息。
[0568]
数据访问请求和预测的数据访问请求可以被配置为还包括相同匹配存储器地址的数据访问请求令牌。
[0569]
数据访问请求可以被配置为进一步包括识别信息以识别其是存储器读取命令还是写入命令。
[0570]
数据访问请求可以被配置为进一步包括识别信息以识别其是否是存储器覆盖命令。
[0571]
数据访问请求可以被配置为进一步包括识别信息以识别其是推理数据、权重数据还是特征图数据。
[0572]
数据访问请求可以被配置为进一步包括识别信息以识别其是学习数据还是评估数据。
[0573]
数据访问请求可以被配置为进一步包括识别信息以识别人工神经网络操作是用于学习的操作还是用于推理的操作。
[0574]
当至少一个处理器生成后续数据访问请求时,至少一个人工神经网络存储器控制器可被配置为确定预测的数据访问请求和后续数据访问请求是否是相同的请求。
[0575]
当预测的数据访问请求和后续数据访问请求是相同的请求时,至少一个人工神经网络存储器控制器可以被配置为维护人工神经网络数据局部性模式。
[0576]
当预测的数据访问请求和后续数据访问请求不同时,至少一个人工神经网络存储器控制器可以被配置为更新人工神经网络数据局部性模式。
[0577]
人工神经网络数据局部性模式可以被配置为进一步包括其中顺序记录数据访问请求的存储器的地址的数据。
[0578]
至少一个人工神经网络存储器控制器可以被配置为通过检测包括在数据访问请求中的存储器地址的重复模式来生成人工神经网络数据局部性模式。
[0579]
人工神经网络数据局部性模式可以由具有重复循环特性的存储器地址来配置。
[0580]
人工神经网络数据局部性模式可以被配置为进一步包括用于识别人工神经网络模型的操作的开始和结束的识别信息。
[0581]
至少一个处理器可以被配置为被提供与来自人工神经网络存储器控制器的数据访问请求相对应的数据。
[0582]
至少一个人工神经网络存储器控制器可以被配置为进一步包括人工神经网络模型,该人工神经网络模型被配置为机器学习人工神经网络数据局部性模式。
[0583]
至少一个人工神经网络存储器控制器可以被配置为存储人工神经网络数据局部性模式的更新模式和提前模式以确定人工神经网络模型是否改变。
[0584]
至少一个人工神经网络存储器控制器可以被配置为确定数据访问请求是一个人工神经网络模型的请求还是多个人工神经网络模型的请求的混合。
[0585]
当存在多个人工神经网络模型时,至少一个人工神经网络存储器控制器可以被配置为进一步生成与人工神经网络模型的数量相对应的人工神经网络数据局部性模式。
[0586]
至少一个人工神经网络存储器控制器可以被配置为基于人工神经网络数据局部性模式单独生成对应的预测的数据访问请求。
[0587]
至少一个人工神经网络存储器控制器可以被配置为进一步生成与数据访问请求相对应的数据访问请求。
[0588]
至少一个人工神经网络存储器控制器可以被配置为进一步生成与预测的数据访问请求相对应的数据访问请求。
[0589]
数据访问请求、预测的数据访问请求和存储器访问请求中的每一个都可以被配置为包括对应的存储器地址值和操作模式。
[0590]
至少一个人工神经网络存储器控制器可以被配置为进一步生成存储器访问请求,该存储器访问请求包括被包括在数据访问请求和预测的数据访问请求中的信息的至少一部分。
[0591]
还包括被配置为与至少一个人工神经网络存储器控制器通信的至少一个存储器,并且至少一个存储器可以被配置为响应于从至少一个人工神经网络存储器控制器输出的存储器访问请求而操作。
[0592]
至少一个存储器可以被配置为存储推理数据、权重数据和特征图数据中的至少一种。
[0593]
至少一个神经网络人工神经网络存储器控制器可以被配置为进一步包括高速缓冲存储器,该高速缓冲存储器被配置为存储响应于存储器访问请求而从至少一个存储器发送的数据。
[0594]
当至少一个处理器输出后续数据访问请求时,至少一个人工神经网络存储器控制器确定该预测的数据访问请求和后续(即,下一)数据访问请求是否是相同的请求。如果预测的数据访问请求和后续数据访问请求相同,则至少一个人工神经网络存储器控制器可以被配置为向至少一个处理器提供存储在高速缓冲存储器中的数据,并且如果预测的数据访问请求和后续数据访问请求不同,则至少一个人工神经网络存储器控制器可以被配置为基于后续数据访问请求生成新的存储器访问请求。
[0595]
至少一个人工神经网络存储器控制器基于高速缓冲存储器的剩余容量顺序地生成至少一个存储器访问请求以最小化高速缓冲存储器的剩余容量。
[0596]
至少一个人工神经网络存储器控制器可以被配置为测量响应于存储器访问请求的至少一个存储器的有效带宽。
[0597]
至少一个人工神经网络存储器控制器可以被配置为具有响应于存储器访问请求的至少一个存储器的必要带宽。
[0598]
至少一个人工神经网络存储器控制器可以被配置为通过计算人工神经网络数据局部性模式在特定时间内的重复次数来测量人工神经网络操作的每秒推理(ips)次数。
[0599]
至少一个人工神经网络存储器控制器可以被配置为计算重复人工神经网络数据局部性模式一次所花费的时间并且计算数据大小,以便计算人工神经网络操作所需的有效带宽。
[0600]
至少一个存储器还包括dram,该dram包括更新存储器元件的电压的刷新功能,并且至少一个人工神经网络存储器控制器可以被配置为对应于预测的数据访问请求而选择性地控制与存储器访问请求对应的至少一个存储器的存储器地址区域的刷新。
[0601]
至少一个存储器还包括预充电功能,以使用特定电压对存储器的全局位线充电,并且至少一个人工神经网络存储器控制器可以被配置为对应于预测的数据访问请求而选择性地向与存储器访问请求对应的至少一个存储器的存储器地址区域提供预充电。
[0602]
至少一个存储器还包括多个存储器,并且至少一个人工神经网络存储器控制器可以被配置为分别测量多个存储器的有效带宽。
[0603]
至少一个存储器还包括多个存储器,并且至少一个人工神经网络存储器控制器可以被配置为分别测量多个存储器的延迟。
[0604]
至少一个存储器还包括多个存储器,并且至少一个人工神经网络存储器控制器可以被配置为基于多个存储器中的每个存储器的有效带宽和延迟来划分和存储要存储在多个存储器中的数据。
[0605]
数据由l位的位组配置,并且多个存储器还包括第一存储器和第二存储器。第一存储器被配置为基于第一有效带宽或第一延迟将来自l位的位组的m位数据进行划分并存储,并且第二存储器被配置为基于第二有效带宽或第二延迟将来自l位的位组中的n位数据进行划分和存储。m位和n位的总和可以被配置为小于或等于l位。
[0606]
所述多个存储器还包括第三存储器,并且所述第三存储器被配置为基于第三有效带宽或第三延迟存储来自l位的位组的o位数据,以及m位、n位和o位的总和可以被配置为等于l位。
[0607]
至少一个人工神经网络存储器控制器可以被配置为进一步包括高速缓冲存储器,其被配置为合并和存储被划分以存储在多个存储器中的数据。
[0608]
数据由p个数据包构成,并且多个存储器包括第一存储器和第二存储器。第一存储器被配置为基于第一有效带宽或第一延迟存储p个数据包中的r个数据包,第二存储器被配置为基于第二有效带宽或第二延迟存储p个数据包中的s个数据包。r和s的和可以被配置为小于或等于p。
[0609]
多个存储器还包括第三存储器,并且第三存储器被配置为基于第三有效带宽或第三延迟存储来自p个数据包的t个数据包,r、s和t之和可配置为等于p。
[0610]
至少一个存储器还包括多个存储器,并且至少一个人工神经网络存储器控制器还包括高速缓冲存储器,并且被配置为合并被分布而存储在多个存储器中的数据以将合并的
数据存储在高速缓冲存储器中。
[0611]
至少一个存储器还包括多个存储器,并且至少一个人工神经网络存储器控制器可以被配置为存储被划分以存储在多个存储器中的数据的划分信息。
[0612]
至少一个人工神经网络存储器控制器可以被配置为基于预测的数据访问请求和至少一个存储器的延迟值将一部分数据与延迟一样多地存储在高速缓冲存储器中。
[0613]
至少一个人工神经网络存储器控制器可以被配置为基于至少一个存储器的预测的数据访问请求和所需数据带宽将部分数据存储在高速缓冲存储器中。
[0614]
当至少一个处理器产生后续数据访问请求时,至少一个人工神经网络存储器控制器首先提供存储在高速缓冲存储器中的数据,并以读取突发模式控制来自至少一个存储器的剩余数据,以减少至少一个存储器的延迟。
[0615]
当至少一个处理器基于至少一个存储器的预测的数据访问请求和延迟值生成后续数据访问请求时,至少一个人工神经网络存储器控制器提前与延迟值一样多地以至少一个存储器的读取突发模式开始,以减少至少一个存储器的延迟。
[0616]
可以进一步包括被配置为控制人工神经网络存储器控制器、至少一个处理器和至少一个存储器的通信的系统总线。
[0617]
至少一个人工神经网络存储器控制器可以被配置为具有系统总线的主控权。
[0618]
至少一个人工神经网络存储器控制器还包括人工神经网络模型,并且当产生预测的数据访问请求时,可以对人工神经网络模型进行机器训练,以将系统总线的控制权增加至高于未生成预测的数据访问请求时的控制权。
[0619]
至少一个人工神经网络存储器控制器可以被配置为确保系统总线的有效带宽,直到至少一个存储器完成存储器访问请求。
[0620]
至少一个人工神经网络存储器控制器可以被配置为基于人工神经网络数据局部性模式计算系统总线处理特定存储器访问请求所需的特定带宽,并且至少一个人工神经网络存储器控制器可以被配置为根据特定带宽控制系统总线的有效带宽。
[0621]
至少一个人工神经网络存储器控制器设置在系统总线中,并且系统总线被配置为基于系统总线中生成的人工神经网络数据局部性模式动态地改变系统总线的带宽。
[0622]
至少一个人工神经网络存储器控制器可以操作以在存储器访问请求的处理时间优先处理人工神经网络操作,并在其他时间处理人工神经网络操作以外的操作。
[0623]
至少一个人工神经网络存储器控制器和至少一个处理器可以被配置为彼此直接通信。
[0624]
人工神经网络存储器控制器可以被配置为进一步包括第一访问队列以及第二访问队列,第一访问队列是专用于人工神经网络操作的访问队列,而第二访问队列是除了人工神经网络操作之外的访问队列,并且人工神经网络存储器控制器可以被配置为根据优先级设置来选择访问队列以提供数据。
[0625]
至少一个人工神经网络存储器控制器还包括多个分层高速缓冲存储器,并且至少一个人工神经网络存储器控制器可以被配置为进一步包括人工神经网络模型,该人工神经网络模型被配置为执行多个分层高速缓冲存储器的层之间的数据访问请求的机器学习。
[0626]
至少一个人工神经网络存储器控制器可以被配置为进一步被提供多个分层高速缓冲存储器的每一层的有效带宽、功耗和延迟信息中的至少一者。
[0627]
包括:至少一个处理器,其被配置为生成对应于人工神经网络操作的数据访问请求;至少一个人工神经网络存储器控制器,其被配置为存储从编译器生成的人工神经网络操作的人工神经网络数据局部性模式并且生成预测的数据访问请求,该预测的数据访问请求基于人工神经网络数据局部性模式预测由至少一个处理器生成的数据访问请求的后续数据访问请求;以及至少一个存储器,其被配置为与至少一个人工神经网络存储器控制器通信。至少一个存储器可以被配置为根据从至少一个人工神经网络存储器控制器输出的存储器访问请求来操作。
[0628]
至少一个人工神经网络存储器系统可以被配置为进一步包括至少一个存储器和系统总线,该系统总线被配置为控制人工神经网络存储器控制器、至少一个处理器和至少一个存储器的通信。
[0629]
至少一个人工神经网络存储器控制器设置在系统总线中,并且至少一个人工神经网络存储器控制器可以被配置为将系统总线的控制权限提高到高于没有存储器访问请求时的控制权限,直到至少一个存储器完成对存储器访问请求的响应。
[0630]
至少一个人工神经网络存储器控制器包括一个或多个人工神经网络存储器控制器,其被配置为被包括在dram中。
[0631]
至少一个人工神经网络存储器控制器包括被配置为包括在至少一个处理器中的一个或多个人工神经网络存储器控制器。
[0632]
至少一个存储器进一步包括dram或者至少一个存储器是dram,并且至少一个人工神经网络存储器控制器可以被配置为重新调整存储器访问请求的访问队列。也就是说,至少一个人工神经网络存储器控制器可以被配置为控制dram的存储器控制器的重排序线索。
[0633]
从人工神经网络存储器控制器提供给存储器的存储器控制器的人工神经网络操作相关的存储器访问请求还可以包括可由存储器的存储器控制器解释的优先级信息。
[0634]
根据上述配置,存储器的存储器控制器可以被配置为基于由人工神经网络存储器控制器生成的存储器访问请求中包括的优先级信息对存储器控制器中的存储器访问队列进行重新排序,而不管存储器访问请求是否与人工神经网络操作有关。因此,用于处理人工神经网络操作的存储器访问请求的访问队列可以比另一种类型的存储器访问请求的访问队列更早地被处理。因此,人工神经网络存储器控制器可以增加相应存储器的有效带宽。
[0635]
由dram的存储器控制器确定的存储器访问请求处理顺序可以通过人工神经网络存储器控制器提供的优先级信息进行重新调整。
[0636]
例如,当由人工神经网络存储器控制器产生的存储器访问请求的优先级被设置为紧急时,dram的存储器控制器可以将存储器访问请求的处理序列改变为第一优先级。
[0637]
人工神经网络存储器控制器可以被配置为生成至少一个访问队列。
[0638]
至少一个存储器包括人工神经网络存储器控制器,并且人工神经网络存储器控制器可以被配置为单独生成专用于人工神经网络操作的访问队列。
[0639]
至少一个人工神经网络存储器控制器可以被配置为重新调整存储器访问请求的访问队列。
[0640]
至少一个存储器还包括读取突发功能,并且至少一个人工神经网络存储器控制器可以被配置为考虑到读取突发功能来设置至少一个存储器的存储区域。
[0641]
至少一个存储器还包括读取突发功能,并且至少一个人工神经网络存储器控制器
可以被配置为考虑到读取突发功能来处理在至少一个存储器的存储区域中的写入操作。
[0642]
至少一个处理器还包括多个处理器,并且至少一个人工神经网络存储器控制器可以被配置为将多个处理器中处理人工神经网络操作的处理器的数据访问请求的优先级设置至高于处理人工神经网络操作以外的操作的处理器的数据访问请求的优先级。
[0643]
例如,根据本公开的处理器可以配置有本公开的示例性npu中的一个。例如,根据本公开的soc可以包括人工神经网络存储器系统。稍后将描述npu和soc。
[0644]
至少一个amc可以被配置为基于分别存储在至少一个amc中的ann dl信息而彼此独立地操作。每个amc的ann dl信息可以根据其在系统中的位置彼此相同或不同。对应于每个amc的ann dl信息可以被配置为至少部分地根据其系统的位置而具有相同的信息。详细地说,每个amc被配置为定制正在通过由特定amc控制的特定通信总线处理的ann模型的ann dl信息。换言之,第一总线的第一amc的第一ann dl信息可以不同于总线的第二amc的第二ann dl信息。因此,每个amc具有能够基于其ann dl信息针对特定通信总线独立地操作的优势。
[0645]
图15是示出安装有存储器的基板和通道的示例图。
[0646]
如图所示,用于与存储器总线通信的多个引脚可以形成在安装有存储器的基板上,即,电路板上。
[0647]
存储器的存储器总线可以包括地址总线(例如,17位)、命令和控制总线(例如,6位)和数据总线(例如,64位)。详细地说,也可能的是,存储器总线可以包括图12所示的至少一个边带信号。
[0648]
也就是说,根据添加的边带信号,根据本公开的各种示例的sam控制器可以被配置为选择性地分类和控制存储器的存储器元件区域。然而,本公开不限于此,并且可以实现ip头包(header packet)而不是边带信号。
[0649]
本公开可以提供被配置为根据人工神经网络(ann)数据局部性(dl)操作的存储器,例如顺序访问存储器(sam)和sam控制器。sam可以被称为专用于人工神经网络的存储器。sam控制单元可以指控制sam的存储器控制器。
[0650]
也就是说,根据本公开的示例的sam可以指专门用于人工神经网络处理的存储器(其可以排除dram存储器的随机访问特性),并且被设置为根据ann dl信息顺序操作。然而,sam的存储器元件的结构不限于dram,它可以应用于具有类似于dram的存储器元件结构的存储器。即,基于ann dl信息,可以导出能够顺序访问存储器的地址的顺序访问信息。
[0651]
sam可以被配置为基本上以突发模式处理读取/写入命令。在这种情况下,可以将读取/写入命令设置为在ann dl信息的单元中操作。即,sam控制器可以被配置为向ann dl的单元中的sam请求存储器操作。在这种情况下,sam的存储器地址映射可以被设置为使得ann dl的单元中的存储器操作在没有特定突发模式命令的情况下以基本突发模式操作。这里,ann dl的单元可以表示处理器基于ann dl信息向存储器或amc请求的最小单元的数据访问请求。ann dl的单元的最小大小可以是一个字单元,例如16位、32位、64位等。
[0652]
由于提供了ann dl,sam可以基本上消除存储器的随机访问特性。由于sam基于ann dl信息以基本突发模式操作,因此可以最小化cas延迟和ras延迟的发生频率。
[0653]
换言之,存储器的常规随机访问操作仅在来自处理器的存储器操作序列不可预测的情况下才有效。
[0654]
另一方面,sam可以基于ann dl提前知道由处理器请求的存储器操作请求的序列。因此,sam可以基于ann dl提供具有最小功耗和延迟的存储器操作。
[0655]
sam和sam控制器之间的存储器总线可以进一步包括至少一个边带信号。
[0656]
sam控制器和处理器之间的系统总线可以进一步包括至少一个边带信号。存储器总线和系统总线各自的边带信号的数量可以彼此相同,也可以彼此不同。
[0657]
然而,本公开不限于此,并且可以以包括与边带信号对应的信息的数据包的形式来实现。
[0658]
由于sam排除了存储器的随机访问特性并基于ann dl信息进行操作,因此可以对其进行配置以实现对sam的存储器元件的精确刷新时序控制。动态存储器元件可能需要周期性刷新,并且用sam实现的动态存储器可以被配置为使得基于ann dl控制刷新。
[0659]
由于sam排除了存储器的随机访问特性并且基于ann dl信息进行操作,因此可以将其配置为能够对sam的存储器元件进行精确的预充电时序控制。动态存储器元件可能需要预充电以用于感测放大器操作,并且用sam实现的动态存储器可以被配置为基于ann dl控制预充电。
[0660]
sam可以被配置为为每个ann dl信息或为每个域确定分配的存储器区域。
[0661]
图16是图示从多存储体结构的存储器读取数据的过程的示例图。
[0662]
图16所示的sam可以利用传统dram的部分存储器元件操作。sam可以包括至少一个存储体。
[0663]
参考图16,sam可以被配置为使得矩阵形式的存储器元件具有行地址和列地址。sam的存储体可以通过捆绑多个存储器元件来配置。
[0664]
为了提高sam的带宽,sam可以被配置为在sam的每个存储体中交错存储器元件。
[0665]
为了提高sam的带宽,sam可以被配置为以sam的存储体的单元执行交织。
[0666]
sam的存储器元件的行地址选通(ras)信号和/或列地址选通(cas)信号可以根据ann dl信息直接控制。因此,sam控制器可以控制sam以根据ann dl顺序读取数据或写入数据。
[0667]
参考图12、15或16,根据本公开的示例的sam可以包括多个存储体。在这种情况下,sam可以被配置为基于至少一个边带信号为特定目的分配特定存储体和/或存储器元件的特定区域。
[0668]
例如,根据域,sam的第一存储体可以专门分配给特征图。
[0669]
例如,根据域,sam的第二存储体可能专门分配给内核。
[0670]
根据本公开的示例的sam可以包括至少一个存储体。在这种情况下,sam可以被配置为基于至少一个边带信号为特定目的分配至少一个存储体的特定行。
[0671]
根据本公开的示例的sam可以包括至少一个存储体。在这种情况下,sam可以被配置为基于域为特定目的分配至少一个存储体的特定行。
[0672]
例如,根据域,sam的第二存储体可以专门分配给内核。
[0673]
根据本公开的示例的sam可以包括至少一个存储体。在这种情况下,sam可以被配置为基于至少一个边带信号为特定目的分配至少一个存储体的特定行。
[0674]
例如,sam可以根据域将第一存储体的第一区域的行专门分配给特征图。
[0675]
例如,sam可以根据域将第一存储体的第二区域的行专门分配给权重。
[0676]
再次参考图12或15,根据本公开的示例的sam可以被配置为基于ann model#信号为特定目的分配特定存储体的特定行。根据本公开的示例的sam可以被配置为至少基于ann dl将特定存储体的特定行分配给特定目的。即,sam可以被配置为基于至少一个边带信号为特定目的分配特定存储体或特定行的存储器元件。
[0677]
然而,本公开不限于此,并且即使没有附加边带信号,也可以通过基于ann dl信息直接控制sam的存储器地址来实现sam控制器。
[0678]
图17是图示在传统dram中发生的延迟的示例图。
[0679]
参考图17,示出了cpu、常规存储器控制器和常规dram之间的延迟。
[0680]
传统的cpu使用虚拟存储器,该虚拟存储器利用转换后备缓冲器(tlb)来处理各种操作。因此,存储在常规dram中的人工神经网络数据被分段并存储在dram中。
[0681]
cpu从dram读取数据的操作可以包括步骤a到f。每个过程都会导致延迟。
[0682]
在步骤a中,cpu产生事务请求。在这个过程中,事务请求可能会被临时排列到cpu的队列中,从而可能产生延迟。在步骤b中,cpu可以将事务请求传送到存储器控制器。在步骤c中,存储器控制器可以将事务请求转换为指令序列。在步骤d中,存储器控制器可以将命令序列传送到dram。在步骤e中,dram可以使用单个cas信号、ras信号和cas信号的组合、或者预充电(pre)信号、ras信号和cas信号的组合来处理命令序列。在过程f中,根据事务的数据被传送到cpu。
[0683]
从过程a到过程f的延迟可能包括a+b+c+d+e+f。
[0684]
当与传统dram所请求的数据操作相对应的所有数据被锁存在图31a所示的感测放大器中时,过程e1会发生。
[0685]
当与传统dram所请求的数据操作相对应的数据的一部分在多行的存储器元件中被分段时,过程e2会发生。
[0686]
当与传统dram所请求的数据操作相对应的数据的一部分被分段为存储器元件的多行,并且存储器元件由于各种原因被预充电时,过程e3会发生。
[0687]
这里,ras指的是行地址选通(ras)信号,cas指的是列地址选通(cas)信号,而pre指的是预充电信号。每个信号分别包括相应的延迟。
[0688]
当常规dram和常规存储器控制器处理人工神经网络数据时,不考虑ann dl信息。因此,人工神经网络数据被分段并作为虚拟存储器进行处理。因此,在传统情况下,e2和e3的情况频繁发生而不是e1的情况。因此,使用常规dram可能会造成人工神经网络处理的瓶颈。
[0689]
相比之下,在根据本公开示例的sam的情况下,由于操作是基于ann dl,因此可以通过去除或最小化e2和e3的出现频率来最大化e1的出现频率。因此,可以减少根据cas信号、ras信号和pre信号的延迟。因此,可以提高人工神经网络的处理速度。
[0690]
图18是示出根据本公开的顺序访问存储器(sam)的基本概念的示例图。
[0691]
图18示出了主存储器、sam、sam控制器和处理器。sam控制器设置于处理器与sam之间以控制sam。
[0692]
sam控制器可以与作为主存储器的sam集成在一起,或者可以与sam物理分离地实现。替代地,sam控制器可以嵌入在处理器中。此外,sam控制器可以以各种形式实现。
[0693]
sam控制器可以从处理器接收ann dl信息以处理人工神经网络(ann),例如npu或
编译器。
[0694]
ann dl信息可以包括在用于npu控制的寄存器映射中,或者可以作为单独的寄存器映射或表提供。
[0695]
ann dl信息可以分别提供给处理器(即,npu)和sam控制器。此外,提供给npu和sam控制器的ann dl信息可以彼此相同,或者可以彼此至少部分相同。
[0696]
sam控制器可以用于根据ann dl信息中的序列信息(即顺序访问信息)向作为主存储器的sam发送读取/写入命令,并提供由处理器请求的数据。
[0697]
作为主存储器的sam可以根据ann dl信息中的序列信息确定要请求的数据大小。ann dl信息可以根据处理器(即npu)中的pe数量、处理器(即npu)的高速缓冲存储器的大小、将用于相应层的内核、特征图的大小等等而变化。
[0698]
例如,当数据的大小大于高速缓冲存储器的大小时,处理器可以使用平铺算法。此外,sam控制器可以被配置为根据处理器的处理方法进行操作。
[0699]
例如,对于主存储器的延迟隐藏,可以确定ann dl。换句话说,对于延迟隐藏,也可以设置ann dl,以便首先高速缓存具有对应于最小时钟数的大小的数据。
[0700]
当处理器的处理方法改变时,例如,ann dl信息可以根据权重平稳方法、输入平稳方法或输出平稳方法而改变。
[0701]
除非有特殊情况,否则根据本公开的示例的sam可以被配置为最小化上面参考图17描述的e2或e3延迟的发生频率。也就是说,除非有特殊情况,否则sam的存储器操作可以操作以依次访问存储体的存储器元件的行。因此,如图17所示的延迟e2或e3的发生频率可以最小化。
[0702]
也就是说,sam可以被配置为通过为在ann dl的单元内的每个存储器操作依次寻址存储器元件来操作。与sam的一个存储器元件的一行对应的所有列的存储器元件可以被相应的感测放大器锁存。可以读取感测放大器中锁存的所有数据,而不会产生额外的ras延迟。因此,可以依次读取对应于一行的列的存储器元件。
[0703]
然而,本公开不限于此,感测放大器中锁存的数据的读取顺序可以改变,并且即使在这种情况下,也不会出现单独的ras延迟。
[0704]
换句话说,sam的顺序寻址技术可能意味着在ann dl的单元内处理存储器操作时,存储器元件的行和列的地址逐渐改变。
[0705]
sam控制器可以被配置为直接控制在ann dl的单元内的作为主存储器的sam的地址。因此,sam控制器可以被配置为直接控制用于访问sam的存储器元件的ras信号和cas信号。
[0706]
图19是示例性地示出了16层的计算量和数据大小的表。
[0707]
在图19的示例中,当人工神经网络模型为vgg16时,描述了每16层的输入特征图、输出特征图和内核的结构信息。本公开的各种示例可以被配置为基于至少一种人工神经网络模型生成至少一种ann dl信息。
[0708]
在图19的表中,层1至13是用于卷积的层,并且层14至16包括全连接层。
[0709]
一般情况下,人工神经网络模型应该按照层的顺序进行计算,但是由于各种原因,处理器处理的人工神经网络模型的操作序列的数量可能会增加或减少。
[0710]
理论上,人工神经网络模型的一层可以用一次卷积运算处理。然而,一次卷积运算
可以在各种条件下进行多次分割。也就是说,卷积运算的数量可能会增加与切片(tile)数量一样多。
[0711]
例如,ann dl信息可以根据人工神经网络的层结构、处理器(即npu)的pe阵列结构以及处理器的内部存储器的大小而改变。
[0712]
例如,如果内核的内部存储器的大小为256kb,并且层1的内核的大小为3.2mb,则适用于内核的内部存储器的平铺操作的数量可以是十三。
[0713]
此外,可以确定要由处理器处理的十三个平铺操作的序列。
[0714]
也就是说,ann dl的步骤数可能会根据处理器的内部存储器的大小而变化。因此,也可以增加ann dl的步骤数。另一方面,如果输入特征图的内部存储器的大小为256kb,并且层1的输入特征图的大小为1.7kb,则可能不需要平铺。即使对于层1的输出特征图,也可能不需要平铺。
[0715]
也就是说,当由处理器处理的人工神经网络模型的操作顺序发生变化时,人工神经网络模型的ann dl信息也发生变化。
[0716]
因此,人工神经网络模型的ann dl信息可以被配置为包括由于平铺而改变的序列信息。
[0717]
图20是示例性地示出了28层的计算量和数据大小的表。
[0718]
在图20的示例中,人工神经网络模型为mobilenet v1.0时,针对每28层描述输入特征图、输出特征图、内核的结构信息。本公开的各种示例可以被配置为基于至少一种人工神经网络模型生成至少一种ann dl信息。
[0719]
在图20所示的表中,层1至28包括卷积层、深度(depth-wise)卷积层和点(point-wise)卷积层。
[0720]
一般情况下,人工神经网络模型应该按照层的顺序进行计算,但是由于各种原因,操作的序列可能会发生变化。如果操作的序列改变,则人工神经网络模型的ann dl信息也会改变。
[0721]
例如,当一个处理器处理两个人工神经网络模型时,由一个处理器处理的ann dl信息可以是图19和20以特定的序列所示的每个人工神经网络模型的人工神经网络数据局部性信息的组合。
[0722]
例如,当两个处理器处理一个人工神经网络模型时,可以将这两个处理器处理的ann dl信息分开,使得图19所示的人工神经网络模型的ann dl信息分别由两个处理器处理。
[0723]
图21是示出根据人工神经网络数据局部性(ann dl)信息中的序列信息访问存储器的第一示例的表。
[0724]
在图21所示的第一示例中,当人工神经网络模型为mobilenet v1.0时,sam控制器可以被配置为具有包括84个步骤的ann dl信息,以便处理28层的计算。即,可以基于每个步骤的顺序从sam的行和列地址的角度来确定顺序访问信息。
[0725]
作为主存储器的sam可以被配置为基于包括在sam控制器中的ann dl信息进行操作。
[0726]
这里,ann dl信息是指由编译器或sam控制器在考虑以下条件中的至少一个的情况下生成的处理器的人工神经网络模型的数据处理序列。
[0727]
a.ann模型结构(vgg16或mobilenet v1.0等)。
[0728]
b.处理器的架构(例如,取决于cpu、gpu和npu的架构)。例如,在npu的情况下,pe的数量,例如输入平稳、输出平稳或权重平稳之类的平稳结构等等。
[0729]
c.高速缓冲存储器的大小(当高速缓冲存储器的大小小于数据大小时需要使用平铺算法等)。
[0730]
d.每个域和每个层的数据大小。例如,域可以包括输入特征图ifmap、输出特征图ofmap和内核kernel。
[0731]
e.处理策略。
[0732]
f.数据重用率。例如,可以确定特定域的数据请求序列,例如先读取输入特征图ifmap或先读取内核kernel。
[0733]
策略可以根据处理器的结构或编译器算法而变化。
[0734]
根据本公开的示例的sam控制器可以基于ann dl将sam的存储器元件的行地址和列地址设置为有顺序的。例如,它可以被设置为使得sam的存储器元件的行和列地址在ann dl的单元中是有顺序的。
[0735]
图22是以简化的方式示出图21所示的表的示例表。
[0736]
在图22中,为了便于解释,数据大小和存储器地址由符号表示。
[0737]
参考图22可以看出,sam控制器可以根据ann dl信息中的序列信息建立关于sam的地址分配的策略。更详细地,sam控制器可以被配置为直接控制sam的存储器元件的行地址和列地址。
[0738]
根据ann dl信息中的顺序访问信息,数据的至少一部分或全部可以存储在ann dl的单元内的存储器中。在这种情况下,可以针对突发模式优化和存储数据。
[0739]
ann dl信息可以包括例如模式信息,其顺序为i)读取输入特征图,ii)读取相应的内核,以及iii)写入输出特征图。然而,本公开不限于上述模式,并且公开了各种模式。此外,可以为每一层不同地设置模式。
[0740]
此时,作为主存储器的sam可以根据ann dl信息控制cas信号或ras信号以在突发模式下操作。参考图41或图42的示例,示出了通过控制cas信号、ras信号和地址信号来直接控制行地址解码器和列多路复用器/多路分解器的示例。
[0741]
在这种情况下,sam控制器可以预测处理器将基于ann dl信息中的序列信息以特定序列请求数据。
[0742]
sam控制器可以分析编译出的人工神经网络模型的ann dl信息,并且直接控制sam的cas信号和/或ras信号,使得由处理器请求的数据可以依次排列在sam的存储器元件中。替代地,可以连续重新排列分段的数据。因此,sam可以顺序地向sam控制器提供数据。
[0743]
也就是说,作为主存储器的sam可以被配置为在ann dl的单元内从开始地址到结束地址以突发模式操作。
[0744]
替代地,作为主存储器的sam可以分析编译的ann dl信息,将待由npu请求的数据排列成顺序地址,然后顺序提供数据。
[0745]
因此,根据本公开的示例的sam控制器可以基于ann dl将sam的存储器元件的行地址和列地址设置为有顺序的。
[0746]
每个ann dl的单元可以具有相应的数据大小。例如,第一ann dl的单元可以具有
大小为a的数据,并且可以具有与大小a相对应的起始地址和结束地址。因此,sam的操作模式可以被配置为与dram的突发模式基本相同的操作,并且当sam控制器产生读取命令时,sam基本上可以以突发模式操作。
[0747]
此外,即使当来自处理器的命令是读取模式而不是读取突发模式时,sam也可以基于ann dl以实质的突发模式操作。
[0748]
此外,基于ann dl,所有数据都可以在突发模式下操作。然而,本公开不限于此,也可以将大部分数据设置为突发模式。即,数据的至少一部分可以不在突发模式下操作。
[0749]
图23示出了sam根据图22中所示的表设置存储器地址映射的示例。
[0750]
sam控制器可以基于编译的ann dl信息来控制sam的cas信号和/或ras信号,并且可以布置待由处理器请求的数据以便在存储器映射中是有顺序的。
[0751]
由于sam已经知道处理器将按照什么序列为存储器中特定地址处的特定大小的数据生成读取或写入命令,因此可以按以下序列布置数据。
[0752]
根据如图23所示的示例,a数据到k数据中的每一个都使用顺序地址存储。如此,由于数据是基于ann dl依次存储的,所以至少对于每个ann dl单元可以在突发模式下操作。另外,根据本公开的示例,由于相邻的ann dl单元也可以具有顺序地址,因此多个ann dl单元的突发模式操作也是可能的。在a数据到k数据的每一个中,数据位可以依次存储。因此,sam可以在突发模式下操作。顺序地址可以是指依次增加的存储器元件阵列的列地址和行地址。
[0753]
因此,ann dl单元的每个数据可以在突发模式下被读取,并且以连续地址存储的数据也可以在突发模式下被读取。
[0754]
优选地,从#1到#15的所有ann dl单元可以在突发模式下操作,但是本公开不限于此,并且至少一个ann dl单元的数据可以被配置为在突发模式下操作。
[0755]
在下文中,将描述在基于ann dl信息设置存储器地址映射之后的过程。
[0756]
ann dl单元#1:处理器和/或sam控制器可以请求sam以在读取突发模式下读取a数据。在ann dl单元#1的情况下,由于a数据是依次存储的,因此sam可以在读取突发模式下操作,直到读取a数据。
[0757]
ann dl单元#2:处理器和/或sam控制器可以请求sam以在读取突发模式下读取b数据。在ann dl单元#2的情况下,由于数据是依次存储的,因此它可以在读取突发模式下操作,直到读取b数据。
[0758]
由于a和b数据依次存储在存储器地址映射中,因此a和b数据,即连续的ann dl单元的数据,可以在读取突发模式下操作。
[0759]
ann dl单元#3:处理器和/或sam控制器可以请求sam以在写入突发模式下写入输出特征图ofmap c数据。由于c数据具有在b数据后面的存储器地址,所以可以按照读取突发模式将其写入sam。
[0760]
ann dl单元#4:处理器和/或sam控制器可以请求sam以再次在读取突发模式下读取c数据,其为输入特征图ifmap。
[0761]
ann dl单元#3和ann dl单元#4将被进一步描述。作为第一层的输出特征图的c数据被重用作为在第二层的输入特征图。
[0762]
如上所述,由于人工神经网络模型可以在写入操作后立即再次请求读取操作,其
是相同的数据,因此可以基于ann dl省略在写入和读取操作期间可能发生的存储器元件的刷新操作。因此,可以省略刷新c数据所需的时间并且可以降低功耗。
[0763]
此外,特定人工神经网络模型的特征图可以具有在其ann dl序列通过后不再重用的特性。因此,由于这样的特征图不再需要维护数据,因此即使存储的数据因不刷新而损坏,人工神经网络操作也不会出现错误。
[0764]
ann dl单元#5:处理器和/或sam控制器可以请求sam以在读取突发模式下读取d数据。由于d数据的地址紧跟c数据的地址,因此其可以在读取突发模式下被连续读取。
[0765]
ann dl单元#6:处理器和/或sam控制器可以请求sam以在写入突发模式下写入e数据。由于e数据具有在d数据的地址之后的地址,因此可以将其根据写入突发模式连续写入sam。
[0766]
ann dl单元#7:处理器和/或sam控制器可以请求sam以在读取突发模式下再次读取e数据。
[0767]
将进一步描述ann dl单元#6和ann dl单元#7。d数据(即第二层的输出特征图ofmap)被重用作为在第三层的输入特征图ifmap。这样,由于人工神经网络模型可以在写入相同数据后立即请求再次读取,因此可以基于ann dl省略可能发生在写入和读取之间的对存储器元件执行的刷新操作。因此,可以节省刷新e数据所需的时间并且可以降低功耗。
[0768]
此外,由于人工神经网络模型的性质,当ann dl序列通过时,特定人工神经网络模型的特征图可能不再被重用。因此,由于这样的特征图不再需要维护数据,因此即使不刷新存储器元件,人工神经网络操作也不会出现错误。
[0769]
图24是示出根据ann dl信息中的序列信息访问存储器的第二示例的表。
[0770]
在图24所示的第二示例中,当人工神经网络模型是mobilenet v1.0时,ann dl可以被配置为在输入特征图之前读取内核。为此,ann dl信息中的序列信息可以包括在输入特征图之前读取内核的序列。
[0771]
当特征图的数据大小增加时,该第二示例可能更有效。
[0772]
从sam中读取内核后,只要接收到输入特征图ifmap就可以开始卷积。
[0773]
具体地,根据第二示例的ann dl信息可以包括关于以下序列模式的信息:i)首先读取内核,ii)读取对应的输入特征图,以及3)将输出特征图写入存储器。
[0774]
作为主存储器的sam可以根据ann dl信息控制cas信号和/或ras信号以在突发模式下操作。
[0775]
处理器的数据操作请求的序列基于预设的ann dl序列。
[0776]
sam控制器可以基于编译的ann dl信息控制sam的cas信号和/或ras信号以依次分配由处理器或npu请求的数据,然后在突发模式下依次操作。
[0777]
基于编译的ann dl信息,sam控制器可以通过依次布置由处理器或npu请求的数据来执行优化以在突发模式下操作sam。
[0778]
与图23的第一示例相比,即使处理相同的人工神经网络模型,第二示例的存储器地址映射也可能与第一示例的存储器地址映射不同。
[0779]
图25示出了sam根据图24中所示的表设置存储器地址映射的示例。
[0780]
作为主存储器的sam可以基于编译的ann dl信息来控制cas信号和/或ras信号,使得待由处理器请求的数据被布置,以便在存储器地址映射中是有顺序的。
[0781]
sam控制器可以基于编译的ann dl信息控制sam的cas信号和/或ras信号,以将待由处理器请求的数据依次布置在存储器地址映射中。
[0782]
由于sam控制器知道处理器是否会将特定大小的数据的读取命令或写入命令发送到存储器中的特定地址,因此sam可以知道将按什么序列处理数据。
[0783]
参考图25,a数据到k数据中的每一个是根据顺序存储器地址存储的。由于以这种方式数据是有顺序的,因此sam至少可以在ann dl单元中以突发模式操作。另外,根据本公开的示例,由于相邻的ann dl单元也可以具有顺序地址,因此多个ann dl单元的突发模式操作也是可能的。
[0784]
由于a数据到k数据中的数据位也是依次存储的,所以存储器可以在突发模式下操作。
[0785]
也就是说,也可以以突发模式读取或写入构成每个数据的位,并且由于每个数据彼此连续,因此可以将其以突发模式读取或写入。
[0786]
在下文中,描述了在基于ann dl设置存储器映射(即存储器地址映射)之后的推理步骤的一些解释。
[0787]
i)处理器和/或sam控制器可以请求sam以根据读取突发模式读取数据。由于数据是依次存储的,因此可以在读取a数据的同时执行读取突发模式。
[0788]
ii)处理器和/或sam控制器可以请求sam以根据读取突发模式读取b数据。由于数据是依次存储的,所以可以在读取b数据的同时执行读取突发模式。
[0789]
.由于a和b数据是依次存储的,a和b数据可以在读取突发模式下操作。也就是说,ann dl的连续数据可以在连续读取突发模式下操作。
[0790]
iii)处理器和/或sam控制器可以请求sam以根据写入突发模式写入c数据,其是输出特征图。由于c数据具有在b数据后面的存储器地址,所以可以将其根据写入突发模式写入存储器中。
[0791]
iv)处理器和/或sam控制器可以请求sam以根据读取突发模式读取d数据。
[0792]
v)处理器和/或sam控制器可以请求sam以根据读取突发模式再次读取c数据。也就是说,前一层的输出特征图ofmap可以用作下一层的输入特征图ifmap。由于处理器和/或sam控制器预先知道请求sam以在d数据之后读取c数据,因此可以提前选择性地调度诸如相应存储器元件的预充电和/或刷新之类的操作。
[0793]
vi)处理器和/或sam控制器可以请求sam以根据写入突发模式写入e数据。由于处理器和/或sam控制器预先知道请求sam以在c数据之后写入e数据,因此可以提前有选择地调度相应存储器元件的例如预充电和/或刷新之类的操作。
[0794]
vii)处理器和/或sam控制器可以请求sam以根据读取突发模式读取f数据。由于f数据的地址紧跟e数据的地址,因此可以在读取突发模式下连续操作。
[0795]
处理器和/或sam控制器可以预先预测请求sam以再次从ann dl单元#8读取被写入ann dl单元#6的相同数据。因此,基于ann dl,可以预测或计算何时将处理对应于ann dl单元#6和ann dl单元#8的数据访问请求。对于预测或计算,还可以利用诸如处理器的时钟速度、对应于ann dl单元#6和ann dl单元#8的e数据的大小以及存储器总线的带宽之类的信息。因此,sam控制器或sam可省略诸如对应的存储器元件的预充电和/或刷新之类的任务或以最佳时序调度所述任务。
[0796]
图26是示出根据ann dl信息中的序列信息访问存储器的第三示例的表。
[0797]
在图26所示的第三示例中,可以将存储器中的特定区域设置为输入特征图和输出特征图的公共区域。也就是说,sam和/或sam控制器可以被配置为基于特定域对sam的区域进行分类。
[0798]
由于输入特征图和/或输出特征图可能是一旦使用就不能重用的数据,因此它们可以交替记录在同一区域中。
[0799]
图示的表中的m_fmap表示多个输入特征图和多个输出特征图中的最大特征图的大小。由于每一层的特征图的大小不同,因此如果设置人工神经网络模型的特征图的最大值,就可以防止例如溢出之类的问题。
[0800]
所有读取或写入特征图的起始地址可以相同,结束地址可以根据对应特征图的实际大小而改变。
[0801]
在第三示例中,由于存储器的特定区域被共同使用,所以必须满足以下条件。
[0802]
m_fmap≥c、e、g、i和k(图26中部分省略,但mobilenet v1.0的示例ann dl信息包括84个单元,m_fmap是所有特征图中的最大值)。在存储器中,内核可以依次存储。
[0803]
图27a和27b示出了根据ann dl信息设置存储器地址映射的示例。
[0804]
sam控制器可以基于编译的ann dl信息来控制sam的cas信号和/或ras信号以在存储器地址映射中依次分配待由处理器(例如,npu)请求的数据。
[0805]
如图27a和27b所示,由于sam知道处理器(例如,npu)将命令以将特定大小的数据读取或写入存储器中的特定地址,因此sam知道将按什么序列处理数据。
[0806]
特征图可以记录在存储器中的公共区域的覆盖命令中,并且内核使用依次排列的存储器地址来存储。因此,可以根据突发模式读取或写入连续数据。
[0807]
迄今为止描述的第一到第三示例将简要描述如下。
[0808]
参考第一到第三示例,可以根据ann dl信息设置存储器地址映射。可以根据上述各种条件、性能、算法、ann模型的结构等来设置存储器地址映射。此外,sam可以基于ann dl信息设置存储器地址映射,以便可以通过ann dl信息以突发模式读取或写入数据。
[0809]
根据第一到第三示例,由于sam的顺序特性,因而可以实现内核的性能改进。
[0810]
另一方面,可以按照从写入操作到读取操作的顺序重复特征图操作。
[0811]
当主存储器采用dram的存储器元件结构时,由于dram的固有特性,因此,一旦从存储器元件中读取数据,则存储器元件中的电容器中充入的电荷就会放电,从而导致数据丢失。因此,可以执行用于再充入电荷的恢复操作。也就是说,主存储器的多个动态存储器元件可能具有漏电流特性。
[0812]
当主存储器采用dram的存储器元件结构时,由于dram的固有特性,因此一旦从存储器元件中读取数据,则存储器元件中的电容器中充入的电荷就会放电,从而导致数据丢失。因此,可以执行用于再充入电荷的恢复操作。
[0813]
第一示例是针对序列模式,但由于输入特征图ifmap是先从存储器中读取的,所以可以在读取内核(kernel)后执行卷积运算。
[0814]
在第二示例中,由于首先从存储器中读取内核,因此可以在读取输入特征图ifmap后开始卷积运算。从执行卷积的角度来看,第二示例有优势。
[0815]
在第三示例中,其在主存储器的容量相对较小时可能是有效的。替代地,其在特征
图和内核分离时,例如在主存储器是具有两个通道的存储器时,可能是有效的。
[0816]
由于dram总线通常是单通道的,所以可以按照第一到第三示例的方式发送和接收数据。然而,在另一示例中,使用多个存储器或多个通道,也可以通过区分权重和特征图来实现sam。
[0817]
然而,本公开的示例不限于此,并且图22至27中描述的示例可以根据特征图的大小和每层的内核为人工神经网络模型的每一层而被不同地设置。
[0818]
图28是图示sam控制器的控制信号的概念图。
[0819]
图28显示了存储器、sam控制器和处理器。从处理器传输的信号可能不通过单独的物理线路传输,而是可以是通过一条或多条线路传输的逻辑信号(即,数据包)。然而,本公开不限于此。
[0820]
sam控制器可以包括存储ann dl信息的内部存储器。
[0821]
ann dl信息可以包括被编译以利用处理器(例如,npu)的信息。
[0822]
读取/写入命令:它是指根据ann dl信息中的序列信息传递的读取命令信号或写入命令信号。与每个命令信号对应的存储器地址可以与存储器的起始地址和结束地址或时钟计数信息一起发送。
[0823]
边带信号:可以根据需要选择性地包括用于根据ann dl信息提高处理效率的各种控制信号。
[0824]
reset信号:其可用于在ann模型更改时重置存储器地址映射。
[0825]
enable信号:当enable信号为on时,数据可以传输到处理器。
[0826]
ann dl信息和sideband signal可能有一些冗余信号。然而,根据人工神经网络结构,ann dl信息可以是静态信息,而边带信号可以是用于ann操作的动态控制信号。
[0827]
图29是图示根据图28中所示的边带信号设置存储器地址映射的示例的示例图。
[0828]
如图29所示,存储器地址映射可以被配置为处理多个ann模型。
[0829]
当处理器(例如,npu)按照ann model的#号顺序执行时分操作时,可以按照ann model的#号顺序依次设置存储器地址映射。因此,当ann模型改变时,sam可以在突发模式下操作。可以根据上述第一到第三示例设置用于每个ann模型的存储器地址映射。
[0830]
图30a示出了根据边带信号设置存储器地址映射的示例,图30b示出了其中仅内核被依次设置的存储器地址映射的示例。
[0831]
如图30a所示,可以为特定的ann模型(例如,ann模型#1)设置多个线程。也就是说,当访问多个用户时,存储器地址映射可以被配置为在多线程中处理ann模型。
[0832]
通过使用多个线程,多个用户可以共同使用一个ann模型的内核。每个线程可以被分配用于存储输入特征图和/或输出特征图的存储器地址映射。
[0833]
替代地,当使用多个线程时,可以仅将内核按顺序映射到存储器地址映射中,如图30b所示。随着线程数量的增加,可以额外创建m_fmap的数量。
[0834]
也就是说,无论用户数量如何,都可以联合使用内核的存储器地址,并且可以将特征图的存储器地址配置为与用户数量成比例地增加。
[0835]
图31a是图示根据本公开的示例通过边带信号发送的read_discard命令的示例图,并且图31b示出了read命令的示例。
[0836]
图31b中所示的名称t
ras
表示数据感测(t
rcd
)+数据恢复到dram元件时间。
[0837]
数据感测(t
rcd
)时间是指将数据锁存到感测放大器的时间。对于锁存操作,可能需要预充电、访问和感测操作。
[0838]
对于上述操作,可以参考图32、33和34。
[0839]
此外,还可以参考图17以描述该示例。
[0840]
根据在此提供的示例,可以仅在t
rcd
期间执行read_discard命令,并且可以不执行用于将数据恢复到dram元件的操作。
[0841]
因此,可以减少将数据恢复到dram单元的操作所需的延迟和功率。例如,在根据图25的ann dl信息中的ann dl单元#3将c数据写入存储器之后,然后再次从ann dl单元#5中的存储器中读取c数据,c数据将根据ann dl信息不再使用。因此,无需执行将数据恢复到dram单元的操作。因此,可以使用序列信息和/或域信息来确定所述操作。
[0842]
例如,可以将read_discard命令设置到特定的ann dl单元#。
[0843]
例如,ann dl单元#3的输出特征图(ofmap)可以重用作为下一层(即ann dl单元#5)的输入特征图(ifmap)。也就是说,输入特征图(ifmap)可以利用输入特征图在用内核(kernel)进行卷积后不会被重用的事实。
[0844]
也就是说,当读取输入特征图(ifmap)时,可以将read_discard命令设置到对应的ann dl单元#。
[0845]
例如,当第一层的输出特征图(ofmap)被写入存储器时,相应的数据被用作第二层的输入特征图(ifmap)并从存储器中被读取。但是,由于没有再次使用输入特征图(ifmap),因此即使由于未执行将数据恢复到dram单元而丢失数据,也不会影响ann操作。因此,根据本公开的示例,sam控制器可以被配置为向存储器指示read-discard命令。
[0846]
该原理在图31a中示出,图31a所示的数据感测(t
rcd
)是感测放大器读取存储在特定行的存储器元件中的值的时间。
[0847]
换句话说,可以在存储器行的单元内执行read_discard命令。
[0848]“将数据恢复到dram单元”是指当存储器元件中存储的数据通过使用感测放大器执行读取操作而丢失时使用感测放大器将锁存的数据恢复回存储器元件的操作。
[0849]
图32示出了根据本公开的示例以dram的存储器元件的形式实现的示例性sam的电路图的一部分。
[0850]
图32所示的sam的电路图包括感测电路(即,感测放大器)。sam的感测电路放大提供给位线的参考电压vref与位线上的电压之间的差值,以产生数字信号0或1。
[0851]
sam的感测电路可以通过位线选择性地恢复放电的存储器元件中的电荷。当执行read命令时,还执行恢复操作。在read-discard命令的情况下,可能无法执行恢复操作。
[0852]
sam的感测电路可以充当锁存感测的电压的缓冲存储器。
[0853]
这里,存储器元件的电容器可能具有漏电流特性。
[0854]
图33是用于解释图32的sam电路图中的预充电操作的示例图。
[0855]
在预充电操作中,提供均衡信号eq,并且激活voltage eq.circuit。当提供eq信号时,电压vref=vcc/2通过每个tr施加到位线和(反转的位线)。因此,位线和用vref电压充电。此外,电压均衡电路(voltage eq.circuit)断开位线和使两条线具有相同的电压。
[0856]
图34是用于解释图32所示的sam电路图中的存储器元件访问操作的示例图。
[0857]
在访问操作中,可以按以下顺序对位线充电。
[0858]
i)用vcc+vt的电压(在图34中图示为粗字线)过驱动对应于要访问的预充电位线的字线。将vcc+vt的电压提供给字线以导通要访问的存储器元件的晶体管tr。csl tr关闭,数据输出被阻止。
[0859]
ii)当存储器元件的tr的电容器中存储的值为1(在图34中示为粗位线)时,电容器放电,并且位线的电压从vref上升到vref+。此时,电容器的电压因放电而降低,存储的数据丢失。
[0860]
图35是用于解释图32所示的sam电路图中的数据感测操作的示例图。
[0861]
在感测操作中,感测电路按以下顺序对位线的电压充电。
[0862]
i)当位线以vref+电压充电时(在图35中以粗实线示出),感测电路的左下方晶体管导通。因此,接地电压gnd,即san,被施加到因此,成为gnd电压。因而,右上晶体管导通。
[0863]
ii)如图35的粗线所示,当感测电路的右上晶体管导通时,sap(即vcc电压)被施加到位线。此外,来自vref+的电压vcc被施加到左下晶体管的栅极。因此,应用位线=3v和
[0864]
iii)现在dram中的数据已准备好以读取。当提供csl信号时,可以产生感测电路的输出。
[0865]
图36是用于解释图32所示的sam电路图中的read-discard操作的示例图。
[0866]
在read-discard操作中,提供了列选择线信号csl,并且感测电路相应地输出数据。
[0867]
根据在此提出的示例,在读取存储在存储器元件中的数据之后,不执行用于在相应存储器元件中再充入荷电的恢复,从而可以减少功耗和恢复时间。例如,其在存储输出特征图,然后将输出特征图用作下一层的输入特征图时是适用的。
[0868]
参考图31a和图31b的比较,可以通过t
ras
时间减少存储器延迟。
[0869]
同时,为了防止电容器被充入电荷,可以关闭由vcc+vt驱动的过驱动字线。因此,可以降低功耗。
[0870]
图37是用于解释图32的sam电路图中的read操作的示例图。
[0871]
根据read命令,提供csl信号并且感测电路输出数据。
[0872]
根据在此呈现的示例,在读取存储在存储器元件中的数据之后,可以执行再充入相应存储器元件中的电荷的恢复。
[0873]
参考图31b,恢复需要t
ras
时间。
[0874]
保持字线被激活允许完全驱动的位线电压通过感测电路的相应晶体管恢复电容器。因此,需要根据恢复的功率消耗。
[0875]
图38a是read-discard操作的示例性波形图,图38b是read操作的示例性波形图。
[0876]
与图38b相反,参照图38a,由于没有restore操作,因此tras时间可以被缩短。可以参考图31b和31b以便理解相应操作之间的区别。
[0877]
图39是表示图21的表的一部分的表,以解释refreash操作。
[0878]
图39的表用于概念性地解释使用ann模型执行一次推理的时间。
[0879]
可以基于处理器的处理速度、数据总线的带宽、存储器的操作速度等来测量、计算或预测每个ann dl#单元所需的时间。
[0880]
sam控制器可以基于ann dl信息控制是否刷新存储器的特定区域(例如,域)中的数据。sam控制器可以基于ann dl信息测量推理时间。例如,可以测量ann dl信息中相同ann dl单元#的重复时间。也就是说,在对ann dl单元#1执行操作之后,可以测量ann dl单元#1的操作再次返回的时间。作为另一示例,可以测量在ann dl信息中执行开始单元#和结束单元#所花费的时间。即,从ann dl信息中的单元#1到单元#84,可以测量执行操作所花费的时间。作为另一示例,可以通过在ann dl信息中设置特定时间段来测量处理时间。
[0881]
如果sam控制器确定在阈值时间内完成了一次推理,则可以禁用存储器刷新。例如,如果根据ann dl信息在阈值时间内完成一次推理,则可以禁用存储内核的存储器区域的刷新。
[0882]
这样做的原因如下。当根据ann dl信息完成一次推理操作时,在存储器中完成对ann模型所有内核的“读取”或“写入”一次。在dram的存储器元件结构的情况下,“读取”与刷新基本相同,因此即使不重复执行刷新也可以保留数据。然而,当推理在推理过程中中断,或者超过阈值时间时,sam控制器可能只刷新存储内核的存储器元件(例如,行)。作为另一示例,如果根据ann dl信息在阈值时间内完成一次推理,则sam控制器可以仅对存储特征图的存储器区域禁用刷新。这样做的原因如下。由于特征图不能重用,特征图对数据丢失不敏感,因此可以禁用刷新。再例如,当执行读取-丢弃(read-discard)操作时,由于数据已经丢失,因此禁用刷新可能是有效的。
[0883]
详细地说,由于内核可以是固定值,因此它可以被定期刷新。然而,如上所述,如果可以基于ann dl在阈值时间内预测内核的读取操作的重复,则可以禁用刷新。
[0884]
然而,本公开的示例不限于此,sam的读取、写入和读取-丢弃命令可以基于ann dl、考虑到数据的特性、处理时间、重用等进行适当选择。
[0885]
同时,上述阈值时间可以示例性地设置为刷新阈值时间rt
th
=32ms至64ms。防止数据丢失的推荐时间可能因存储器元件的电容和漏电流特性而异。
[0886]
此外,当满足推理时间(it)《rt
th
时,存储特征图的存储器元件可能不会接收到刷新命令。
[0887]
可以根据ann dl信息不同地设置数据刷新策略。
[0888]
例如,在内核的情况下,可以设置刷新策略以提高数据保护级别,而在特征图的情况下,可以设置刷新策略以降低数据保护级别。
[0889]
通过基于ann dl信息禁用刷新,可以减少存储器操作延迟并降低功耗。
[0890]
当人工神经网络模型的数据分布并存储在存储器中的多个存储体中时,基于ann dl信息,可以分别控制存储体的预充电时间。
[0891]
图40示出了根据本公开的示例以各种形式实现sam存储器的示例。
[0892]
sam存储器可以根据应用领域以各种形式实现。
[0893]
作为amc中的高速缓冲存储器和/或处理器之间的数据传输路径的存储器总线可以实现为单通道或双通道。当通道数增加时,功耗会增加,但有一个优点是,可以分别通过管理内核和/或特征图来提高带宽。当使用两个通道时,带宽比使用一个通道时增加一倍,
因此可以将更多数据传送到amc中的高速缓存和/或处理器。可以基于ann dl来控制操作。
[0894]
多个sam存储器可以按“等级”分组和驱动。
[0895]
每个sam存储器可以包括存储体,其是独立操作的存储器元件阵列的集合。例如,一个存储体可以包括八个存储器元件阵列。交错多个存储器存储体可以使用低带宽设备来实现高带宽存储器总线。每个存储器阵列可以包括行解码器、列解码器、感测放大器和输入/输出缓冲器。“行”是指存储器阵列的一行。“列”是指存储器阵列的一列。
[0896]
图41是图示基于ann dl信息映射主存储器的地址的方法的示例的示例图。
[0897]
参考图41,示出了sam的基本结构。sam包括具有行和列的地址的矩阵结构中的多个存储器元件。sam可以被实现为例如dram。然而,本公开的示例不限于此。
[0898]
感测放大器设置在矩阵结构的多个存储单元的下端。行地址解码器选择特定的行。因此,需要ras延迟以执行相应操作。所选行的存储器元件的数据被锁存在感测放大器中。列地址解码器从感测放大器中锁存的数据中选择必要的数据并将其传输到数据缓冲器。因此,需要cas延迟以执行相应操作。该结构可以被称为dram的存储体。dram可以包括多个存储体。
[0899]
在这种情况下,当dram以突发模式操作时,在存储器元件的地址按顺序增加的同时读取或写入数据。因此,与读取分段的地址数据的情况相比,ras延迟和cas延迟被最小化。
[0900]
换句话说,即使amc或npu向主存储器指示突发模式,如果存储在dram中的数据实际上被分段,ras延迟和cas延迟与分段发生的一样多。因此,如果数据被分段,则仅通过执行突发模式命令很难大幅降低ras延迟和cas延迟。
[0901]
相反,在sram的情况下,数据是否分段基本上不会引起延迟。因此,在由sram组成的缓冲存储器或内部存储器中,由于数据分段而产生的延迟可能不是致命的。
[0902]
参考图41,基于ann dl信息,考虑由npu向dram的存储器元件请求的数据的顺序和大小来设置存储器地址映射。可以基于每个数据大小,基于开始地址和结束地址来设置存储器映射。因此,如果按照sam中ann dl信息的顺序执行存储器操作,则所有存储器操作都可以在突发模式下进行。
[0903]
因此,图41中所示的主存储器可以根据表1所示的存储器地址和操作模式进行控制。表1
[0904]
更详细地,对于表1的域,还可以利用参考图12描述的域信息。详细地说,还可以利用图12中描述的操作模式信息以用于表1的操作模式。
[0905]
因为数据根据ann dl信息被映射到顺序地址,所以可以用突发模式命令处理数据。
[0906]
也就是说,amc可以在npu基于ann dl信息(ann dl)发出请求之前高速缓存必要的数据,并且可以确定所有请求的序列。因此,amc的缓冲存储器的高速缓存命中率理论上可以达到100%。
[0907]
另外,由于主存储器的存储器映射是基于ann dl信息设置的,因此所有存储器操作都可以在突发模式下操作。
[0908]
尽管图29中示例性地示出了单个存储器存储体,因此可以根据存储器的存储体、等级和通道的配置以存储体交错方法执行地址映射。
[0909]
如果不考虑ann dl信息,实际上不可能将npu请求的数据按顺序存储在dram中。也就是说,即使提供了通用的人工神经网络模型信息,如果没有各种示例中描述的ann dl信
息,则也不可能知道npu向主存请求的所有数据操作序列。
[0910]
如果amc没有ann dl信息,则amc很难知道npu是首先请求人工神经网络模型第一层的内核还是首先请求人工神经网络模型第一层的输入特征图。因此,考虑到突发模式,在主存储器中设置存储器地址映射是非常困难的。
[0911]
图42是图示基于ann dl信息映射主存储器的地址的方法的另一示例的示例图。
[0912]
由于图42所示的主存储器的结构与图41所示的主存储器基本相同,因此可以省略多余的描述。
[0913]
参考图42,可以基于ann dl信息,考虑到由npu向dram的存储器元件请求的数据的序列和大小来设置存储器映射。可以基于每个数据大小,基于开始地址和结束地址来设置存储器映射。因此,如果在dram中以ann dl信息的序列执行存储器操作,则所有存储器操作都可以在突发模式下操作。
[0914]
因此,图42中所示的主存储器可以基于表2中所示的存储器地址和操作模式进行控制。
[0915]
对应于图42和表2的ann数据局部性信息ann dl是将npu设置为共同使用输入特征图和输出特征图的情况的示例。表2
[0916]
当人工神经网络模型的训练完成时,内核的值是固定的。因此,内核的值具有恒定的特性。另一方面,由于输入特征图和输出特征图可以是例如图像数据、相机、麦克风、雷达、激光雷达等的输入,其一旦被使用,就不能再重复使用。
[0917]
参考图20作为示例,定义了人工神经网络模型的输入特征图和输出特征图的大小。因此,可以在人工神经网络模型的输入特征图和输出特征图中选择最大数据大小(m_fmap)。在图20的人工神经网络模型的情况下,最大尺寸的特征图(m_fmap)为802,816字节。因此,将表2中人工神经网络模型中的每一层的输入特征图和输出特征图设置为具有相同的起始地址。也就是说,输入特征图和输出特征图可以在覆盖相同的存储器地址的方法中操作。如上所述,由于人工神经网络模型的特性,因此当输入特征图和内核进行卷积时,生成输出特征图,并且对应的输出特征图成为下一层的输入特征图。因此,前一层的特征图不再会被重用,而可能会被删除。
[0918]
根据上述配置,可以通过将基于最大特征图设置的存储区域设置为输入特征图和输出特征图的共同区域来减小主存储器的存储器映射的大小。
[0919]
图43是示出根据ann dl信息中的序列信息访问存储器的示例的表。
[0920]
sam控制器可以基于ann dl信息控制突发长度。sam控制器可以通过使用突发终止命令根据ann dl信息有效地控制突发模式。突发长度可以由axi协议定义。
[0921]
1)在ann dl单元#1的情况下,它具有起始地址0和结束地址a'。因此,由sam控制器指示的突发模式的结束命令可以对应数据大小a。
[0922]
2)在ann dl单元#2的情况下,它具有起始地址a'+1和结束地址b'。因此,由sam控制器指示的突发模式的结束命令可以对应数据大小b。
[0923]
3)在ann dl单元#3的情况下,其具有起始地址b'+1和结束地址c'。因此,由sam控制器指示的突发模式的结束命令可以对应于数据大小c。
[0924]
在ann dl单元#4的情况下,其具有起始地址b'+1和结束地址c'。因此,由sam控制器指示的突发模式的结束命令可以对应于数据大小c。
[0925]
5)在ann dl单元#5的情况下,其具有起始地址c'+1和结束地址d'。因此,由sam控制器指示的突发模式的结束命令可以对应于数据大小d。
[0926]
本公开的示例不限于上述内容,并且突发长度可以通过以下方式编程。
[0927]
a.使用较短的固定突发长度。
[0928]
b.明确标识读取或写入命令的突发长度。
[0929]
c.突发长度使用dram熔丝(激光可编程熔丝、电可编程熔丝)进行编程。
[0930]
d.对突发结束命令使用长的固定突发长度。
[0931]
e.其使用bedo类型的协议,其中每个cas/脉冲切换一个数据列(突发模式扩展数据输出;bedo dram)。
[0932]
图44图示了其中嵌入了sam控制器的存储器的示例。
[0933]
在图44中,图示的存储器是用于人工神经网络的改进的专用存储器,并且该存储器可以具有嵌入其中的sam控制器。也就是说,dsam可以指基于dram实现的sam。
[0934]
图45图示了包括编译器的架构。
[0935]
在图45,编译器可以将人工神经网络模型转换成可以在npu中运行的机器代码。
[0936]
编译器可以包括前端和后端。前端和后端之间可能存在中间表示(ir)。这些ir是程序的抽象概念,并且用于程序优化。人工神经网络模型可以转换为各种级别的ir。
[0937]
高级别的ir可以位于编译器的前端。编译器的前端接收有关人工神经网络模型的信息。例如,关于人工神经网络模型的信息可以是图23中例示的信息。编译器的前端可以执行与硬件无关的转换和优化。
[0938]
高级别的ir可以处于图形级别,并且可以优化计算和控制流程。低级别的ir可以位于编译器的末端。
[0939]
编译器的后端可以将高级别的ir转换为低级别的ir。编译器的后端可以进行npu优化、code生成和编译。
[0940]
编译器的后端可以执行优化任务,例如硬件内在映射、存储器分配等。
[0941]
ann数据局部性信息可以在低级别的ir中生成或定义。
[0942]
ann数据局部性信息可以包括待由npu向主存储器请求的所有存储器操作序列信息。因此,amc可以知道npu将请求的所有存储器操作的序列。如上所述,编译器可以生成ann数据局部性信息,或者amc可以通过分析npu从主存储器请求的存储器操作命令的重复模式来生成ann数据局部性信息。
[0943]
ann数据局部性信息可以以寄存器映射或查找表的形式生成。
[0944]
在分析或接收ann数据局部性信息ann dl之后,编译器可以基于ann dl生成amc和/或npu的高速缓存调度。高速缓存调度可以包括npu的片上存储器的高速缓存调度和/或amc的缓冲存储器的高速缓存调度。
[0945]
同时,编译器可以使用优化算法(例如,量化、剪枝、再训练、层融合、模型压缩、转移学习、基于ai的模型优化和其他模型优化)编译人工神经网络模型。
[0946]
此外,编译器可以生成针对npu优化的人工神经网络模型的ann数据局部性信息。ann数据局部性信息可以单独提供给amc,npu和amc也可以分别接收相同的ann数据局部性信息。此外,如上面参考图14所描述的,可以有至少一个amc。
[0947]
ann数据局部性信息可以包括被配置在npu的存储器操作请求的单元内的操作序列、数据域、数据大小、配置用于顺序寻址的存储器地址映射。
[0948]
所示的npu中的调度器可以通过从编译器接收二进制机器代码来控制人工神经网络操作。
[0949]
编译器可以向dma提供顺序分配的主存储器的存储器地址映射信息,dma是ann存储器控制器(amc),amc可以基于顺序存储器地址映射排列或重新排列主存储器中的人工神
经网络模型数据。在npu初始化或运行期间,amc可能会在主存储器中执行数据重新排序操作。
[0950]
在这种情况下,amc可以在执行排列或重新排列时优化读取突发操作。可以在初始化npu操作时执行排列或重新排列。此外,可以在检测到ann dl中的变化时执行排列或重新排列。这些功能可以在npu操作期间在amc中独立执行,而无需编译器。
[0951]
amc和npu可以相互接收或提供ann数据局部性信息。也就是说,编译器可以向amc和npu提供ann数据局部性信息。可以向amc提供关于由npu实时处理的ann数据局部性信息的操作序列的信息。此外,amc可以将ann数据局部性信息与npu同步。
[0952]
如果npu正在处理与令牌#n的ann数据局部性信息相对应的数据,则amc预测将从npu请求与令牌#(n+1)的ann数据局部性信息相对应的数据,考虑主存储器的延迟,并且向主存储器请求与令牌#(n+1)的ann数据局部性信息对应的数据。相应的操作可以由amc在接收到来自npu的存储器操作请求之前独立进行。
[0953]
编译器可以生成高速缓存策略,以根据amc中的缓冲存储器中的ann数据局部性存储预测操作所需的数据。编译器根据dma的缓冲器大小在npu请求之前高速缓存尽可能多的数据。
[0954]
例如,编译器可以向amc提供高速缓存策略以高速缓存高达ann数据局部性信息令牌#(n+m)。这里,m可以是满足以下情况的整数值:ann数据局部性信息令牌#(n+1)至#(n+m)的数据大小小于或等于amc的高速缓冲存储器容量。
[0955]
编译器可以确定当amc的剩余缓存容量大于ann数据局部性信息令牌#(n+m+1)的数据大小时,ann数据局部性信息令牌#(n+m+1)数据可以存储在存储与ann数据局部性信息令牌#(n)对应的数据的区域中。
[0956]
详细地说,高速缓存可以由amc基于存储在amc的ann数据局部性信息管理单元中的ann dl独立地执行,无需npu的命令。
[0957]
编译器可以提供模型轻量化功能。编译器可以进一步优化和轻量化深度学习模型以适应相应的npu架构。
[0958]
图46示出了根据第一示例的系统的架构。
[0959]
参考图46,示出了npu、人工神经网络存储器控制器(amc)和主存储器(其是外部存储器)。在某些情况下,主存储器可以称为外部存储器。
[0960]
为了下面描述的方便,本公开的各种示例的人工神经网络存储器控制器可以被称为amc。
[0961]
npu可以包括npu调度器、内部存储器和pe阵列。
[0962]
本公开的各种示例的pe阵列可以包括多个处理元件(processing elements)。多个处理元件可独立地单独驱动或可成组驱动。pe阵列可以被称为多个处理元件。
[0963]
npu还可包括sfu。
[0964]
pe阵列可以执行人工神经网络的操作。例如,当将输入数据输入时,pe阵列可以通过人工神经网络执行推导推理结果的操作。在一些示例中,多个处理元件可以被配置为彼此独立地操作。
[0965]
npu调度器可以被配置为控制pe阵列的操作以进行npu的推理操作和npu内部存储器的读取和写入序列。此外,npu调度器可以被配置为基于ann数据局部性信息来控制pe阵
列和npu内部存储器。
[0966]
npu调度器可以分析要在pe阵列中操作的人工神经网络模型的结构,或者可以接收所分析的信息。例如,npu的编译器可以被配置为分析人工神经网络数据局部性。人工神经网络模型可以包括的数据至少包括根据人工神经网络数据的局部性的每一层的输入特征图、内核和输出特征图。可以根据层的大小和内部存储器的大小选择性地平铺每一层。
[0967]
ann数据局部性信息可以存储在npu调度器或npu内部存储器内提供的存储器中。npu调度器可以访问主存储器以读取或写入必要的数据。此外,npu调度器可以利用人工神经网络模型的每一层的基于诸如特征图和内核之类的数据的ann数据局部信息或关于其结构的信息。内核也可以称为权重。特征图也可以称为节点数据。例如,在设计、完成训练或编译人工神经网络模型时会生成ann数据局部性。npu调度器可以以寄存器映射的形式存储ann数据局部性信息。然而,本公开不限于此。
[0968]
npu调度器可以根据ann数据局部性信息调度人工神经网络模型的操作序列。
[0969]
npu调度器可以获取存储器地址值,人工神经网络模型的每一层的特征图和内核数据基于ann数据局部性信息存储在该存储器地址值中。例如,npu调度器可以获得存储器地址值,其中人工神经网络模型的层的特征图和内核数据存储在该存储器中。因此,npu调度器可以从主存储器中预取至少一部分待驱动的人工神经网络模型的层的特征图和内核数据,然后及时将其提供给npu内部存储器。每一层的特征图可以有对应的存储器地址值。每个内核数据可以分别具有对应的存储器地址值。
[0970]
npu调度器可以基于ann数据局部性信息,例如人工神经网络模型的人工神经网络的层的数据排列或关于结构的信息来调度pe阵列的操作序列。
[0971]
由于npu调度器基于ann数据局部性信息调度操作,因此它的操作可能与一般cpu调度构思不同。通过考虑公平性、效率、稳定性和响应时间来操作一般cpu的调度以实现最佳效率。也就是说,考虑到优先级和操作时间,安排在同一时间内执行最多的处理。
[0972]
考虑到诸如每个处理的优先级顺序、操作处理时间等数据,传统的cpu使用用于调度任务的算法。
[0973]
也就是说,由于一般cpu的调度是随机的并且难以预测,所以其是基于统计、概率和优先级来确定的。相反,由于人工神经网络操作的顺序是可预测的而不是随机的,因此更有效的调度是可能的。特别是由于人工神经网络计算具有巨大的数据量,可以根据高效调度显著提高人工神经网络的计算处理速度。
[0974]
npu调度器可以基于ann数据局部性信息来确定操作顺序。
[0975]
此外,npu调度器可以基于ann数据局部性信息和/或要使用的npu的数据局部性信息或关于结构的信息来确定操作顺序。
[0976]
根据人工神经网络模型的结构,依次进行每一层的计算。也就是说,当确定人工神经网络模型的结构后,就可以确定每一层的操作序列。根据人工神经网络模型结构的操作顺序或数据流可以定义为人工神经网络模型在算法层面的数据局部性。
[0977]
pe阵列(即多个处理元件)是指其中排列被配置为计算人工神经网络的特征图和内核的多个pe的配置。每个pe可以包括乘法和累加(mac)运算符和/或算术逻辑单元(alu)运算符。然而,根据本公开的示例不限于此。
[0978]
另一方面,npu中的内部存储器可以是静态存储器。例如,内部存储器可以是sram
或寄存器。内部存储器可以同时执行读取操作和写入操作。为此,amc和npu可以通过双端口通信接口连接。替代地,当amc和npu通过单端口通信接口连接时,读取操作和写入操作可以以时分复用(tdm)的方式依次进行。
[0979]
amc可以包括ann数据局部性信息管理单元和缓冲存储器。
[0980]
amc可以通过ann数据局部性信息管理单元监控npu的操作序列信息。
[0981]
ann数据局部性信息管理单元可以根据npu的操作序列对要提供给多个pe的数据进行排序和管理。在向npu提供数据之前,缓冲存储器可以临时存储从主存储器读取的数据。此外,缓冲存储器可以在将从npu提供的输出特征图传输到主存储器之前临时存储从npu提供的输出特征图。
[0982]
amc从主存储器读取待由npu基于ann数据局部性信息请求的数据(然后该npu请求该数据),并将其存储在缓冲存储器中。当npu实际请求相应数据时,amc立即提供缓冲存储器中存储的相应数据。因此,由于提供了amc,通过监控由npu处理的人工神经网络模型的操作序列,可以基本上消除可能由主存储器产生的ras延迟和cas延迟。
[0983]
主存储器可以是动态存储器。例如,主存储器可以是sam或dram。主存储器(其是dram)和amc可以通过系统总线(例如axi接口)连接。系统总线可以实现为单端口。在这种情况下,dram可能无法同时处理读取操作和写入操作。
[0984]
同时,amc可以重新排列主存储器中的数据,以便读取操作变成基于ann数据局部性信息的突发操作。
[0985]
因此,当作为主存储器的dram以突发操作向缓冲存储器提供数据时,缓冲存储器可以将数据流式传输到npu。
[0986]
缓冲存储器可以实现为先入先出(fifo)形式。当缓冲存储器已满时,amc切换到待机状态。当缓冲存储器向npu传输数据时,amc基于ann数据局部性信息从主存储器中读取数据并将数据存储在缓冲存储器中。amc可以交换存储在第一存储器地址中的第一数据和存储在第二存储器地址中的第二数据。
[0987]
如果缓冲存储器的大小较小(例如,1kb),则缓冲存储器可以仅执行高速缓存以隐藏主存储器和npu之间的延迟。在这种情况下,可以根据突发操作在主存储器和npu之间一次传输大量的数据。如果这样充分地执行突发操作,则主存储器的带宽可以被充分地最大化。
[0988]
作为图17的修改示例,amc可以嵌入在npu中,嵌入在主存储器中,或者嵌入在系统总线中。
[0989]
图47示出了根据第二示例的系统的架构。
[0990]
参考图47,显示了npu、amc和主存储器。在第二示例中,为了描述方便,会省略在其他示例中描述的重复描述。其他示例的配置可以选择性地适用于该示例。
[0991]
npu可以包括npu调度器、多个内部存储器和pe阵列。
[0992]
不同于图46,图47的npu中的多个内部存储器可以包括用于内核的第一内部存储器、用于输入特征图的第二内部存储器和用于输出特征图的第三内部存储器。第一至第三内部存储器可以是分配在一个物理存储器中的多个区域。每个内部存储器可以各自设置有能够与pe阵列通信的端口。如果为每个内部存储器提供每个端口,则可以保证每个内部存储器的带宽。
[0993]
可以不时地可变地调整每个内部存储器的大小。例如,每个存储器的总和为1mb,每个内部存储器的大小可以按照a:b:c的比例进行划分。例如,每个内部存储器的大小可以按1:2:3的比例划分。每个内部存储器的比例可以针对人工神经网络模型的每个操作序列,根据输入特征图的大小、输出特征图的大小以及内核的大小进行调整。
[0994]
不同于图46,图47的amc可以包括直接存储器访问(dma)控制器。
[0995]
外部主存储器可以是sam或dram。
[0996]
即使在npu的pe阵列正在执行推理操作时dma控制器没有收到来自npu的命令,数据也可以独立地从主存储器读取并基于ann数据局部性信息存储在缓冲存储器中。
[0997]
dma控制器在来自npu的请求之前从主存储器读取待由npu基于ann数据局部性信息请求的数据,并将其存储在缓冲存储器中。当npu实际请求相应数据时,dma控制器立即提供缓冲存储器中存储的相应数据。因此,由于提供了dma控制器,因此可以基本上消除可能由主存储器引起的ras延迟和cas延迟。
[0998]
图48示出了根据第三示例的系统的架构。
[0999]
参考图48,示出了npu、amc和主存储器。在第三示例中,为了描述方便,会省略在其他示例中描述的重复描述。其他示例的配置可以选择性地适用于该示例。
[1000]
npu可以包括npu调度器、多个内部存储器和pe阵列。
[1001]
不同于图46,图48的npu中的多个内部存储器可以包括用于内核的第一内部存储器、用于输入特征图的第二内部存储器和用于输出特征图的第三内部存储器。第一至第三内部存储器可以是分配在一个物理存储器中的多个区域。
[1002]
不同于图46,图48的amc可以包括ann数据局部性信息管理单元、交换存储器和缓冲存储器。
[1003]
外部主存储器可以是sam或dram。
[1004]
amc中的交换存储器可用于重新排列主存储器中的数据。
[1005]
在主存储器中,数据可能被分段并存储在随机地址处。然而,当数据是随机存储时,必须使用非连续的存储器地址来从主存储器中读取数据。在这种情况下,可能会频繁发生cas延迟和ras延迟。
[1006]
为了解决这个问题,amc可以基于ann数据局部性信息重新排列主存储器中的数据。具体地,amc将至少一部分分段数据从主存储器临时存储到交换存储器。随后,可以重新排列存储在主存储器中的数据以基于ann数据局部性信息启用突发操作。
[1007]
在初始阶段期间,数据重排操作可以只执行一次。然而,本公开不限于此。如果ann数据局部性信息发生变化,则可以基于更改后的ann数据局部性信息再次执行重新排序操作。
[1008]
同时,作为修改,amc可以通过在主存储器中分配交换区域而不使用交换存储器来执行数据重新排列。
[1009]
图49示出了根据第四示例的系统的架构。
[1010]
参考图49,示出了npu、amc和主存储器。在第四示例中,为了描述方便,会省略在其他示例中描述的重复描述。其他示例的配置可以选择性地适用于该示例。
[1011]
npu可以包括npu调度器、多个内部存储器和pe阵列。
[1012]
不同于图46,图49的npu中的多个内部存储器可以包括用于内核的第一内部存储
器、用于输入特征图的第二内部存储器和用于输出特征图的第三内部存储器。
[1013]
amc可以包括ann数据局部性信息管理单元和多个缓冲存储器。
[1014]
不同于图46,图49中所示的多个缓冲存储器可以包括用于内核的第一缓冲存储器、用于输入特征图的第二缓冲存储器和用于输出特征图的第三缓冲存储器。第一至第三缓冲存储器可以是分配在一个物理存储器中的多个区域。
[1015]
npu中的每个内部存储器可以连接到amc中的每个缓冲存储器。例如,第一内部存储器可以直接连接到第一缓冲存储器,第二内部存储器可以直接连接到第二缓冲存储器,而第三内部存储器可以连接到第三缓冲存储器。
[1016]
每个缓冲存储器可以设置有可以分别与npu的每个内部存储器通信的端口。
[1017]
每个缓冲存储器的大小可以可变地调整。例如,每个缓冲存储器的总和为1mb,每个缓冲存储器的大小可以按照a:b:c的比例进行划分。例如,每个缓冲存储器的大小可以按1:2:3的比例划分。每个缓冲存储器的比例可以针对人工神经网络模型的每个操作顺序,根据输入特征图的大小、输出特征图的大小以及内核数据的大小进行调整。
[1018]
amc可以基于ann数据局部性信息在每个缓冲存储器中单独地存储用于npu的操作的数据。
[1019]
另一方面,如可以参考图23所见到的,当人工神经网络模型基于mobilenet v1.0时,深度卷积(depth-wise convolution)和/或点卷积(point-wise convolution)的核(即权重)的大小偏差可能相当大。
[1020]
因此,每个内部存储器的大小可以基于ann数据局部性信息进行调整。类似地,可以调整每个缓冲存储器的大小。
[1021]
图50示出了根据第五示例的系统的架构。
[1022]
参考图50,示出了npu、amc和主存储器。在第五示例中,为了描述方便,会省略在其他示例中描述的重复描述。其他示例的配置选择性地适用于该示例。
[1023]
npu可以包括npu调度器、多个内部存储器和pe阵列。
[1024]
不同于图46,图50中所示的npu中的多个内部存储器可以包括用于内核的第一内部存储器、用于输入特征图的第二内部存储器和用于输出特征图的第三内部存储器。
[1025]
amc可以包括ann数据局部性信息管理单元和缓冲存储器。
[1026]
如在另一个示例中提到的,数据可以在主存储器中随机分段。但是,当数据以这种方式随机存储时,必须使用非连续的存储器地址从主存储器中读取数据。因此,可能会出现cas延迟和ras延迟。
[1027]
为了解决这个问题,amc可以根据ann数据局部性信息重新排列主存储器中的数据。具体地,amc将主存储器中的分段数据的至少一部分临时存储在缓冲存储器中。随后,可以重新排列存储在主存储器中的数据以基于ann数据局部性信息启用突发操作。
[1028]
同时,当重新排列数据时,可以改变存储器地址。因此,amc中的ann数据局部性信息管理单元和npu调度器可以相互通信。具体地,ann数据局部性信息管理单元存储在数据重排后经更新的存储器地址。然后,ann数据局部性信息管理单元可以更新存储在npu调度器中的先前的存储器地址。
[1029]
图51示出了根据第六示例的系统的架构。
[1030]
参考图51,示出了npu、amc和主存储器。在第六示例中,为了描述方便,会省略在其
他示例中描述的重复描述。其他示例的配置选择性地适用于该示例。
[1031]
npu可以包括npu调度器、多个内部存储器和pe阵列。
[1032]
不同于图46,图51中所示的npu中的多个内部存储器可以包括用于权重的第一内部存储器、用于输入特征图的第二内部存储器和用于输出特征图的第三内部存储器。第一至第三内部存储器可以是分配在一个物理存储器中的多个区域。
[1033]
amc可以包括ann数据局部性信息管理单元、转换后备缓冲器(tlb)和缓冲存储器。
[1034]
数据可以随机存储在主存储器中。但是,当数据这样随机存储,以便从主存储器中读取数据时,必须使用非连续的存储器地址,因此可能会出现cas延迟和ras延迟。
[1035]
为了解决这个问题,amc可以基于ann数据局部性信息重新排列主存储器中的数据。具体地,在将主存储器中存储的数据临时存储到缓冲存储器后,amc可以基于ann数据局部性信息重新排列主存储器中存储的数据以启用突发操作。
[1036]
同时,当重新排列数据时,可以改变存储器地址。因此,amc中的tlb可以以表格的形式存储重排前的旧存储器地址和重排后的新存储器地址。
[1037]
当npu中的调度器使用旧存储器地址请求数据时,amc中的tlb可以将旧存储器地址转换为新存储器地址,从主存储器读取数据,并将数据存储在缓冲存储器中。因此,不同于图21,主存储器可以在突发模式下操作,而无需通过tlb更新存储在npu调度器中的存储器地址。
[1038]
在上述各种示例中,amc和npu以单独的配置示出,但是amc可以被配置为包括在npu中。
[1039]
图52是图示根据图51中所示的第六示例的操作的示例图。
[1040]
参考图52可以看出,可以根据ann dl基于表来设置存储器地址映射。在amc的缓冲存储器中,数据按照ann dl信息中的序列预先依次高速缓存。为了不使缓冲存储器溢出,可以基于缓冲存储器的大小删除最旧序列中的数据。
[1041]
图53a和53b是示出卷积运算的示例的示例图。
[1042]
参考图53a,示出了用于执行卷积运算的第一层。输入特征图的大小可以是9
×9×
1,包括权重的内核的大小可以是3
×3×
1,步幅为1,输出特征图的大小可以是7
×7×
1。
[1043]
如果按照如图53a所示的箭头方向从主存储器中读取第一输入特征图,则卷积运算可以相对较快地开始。读取第一输入特征图的方向可以沿竖直扫描箭头方向读取与内核的高度一样多,然后沿水平扫描箭头方向读取。
[1044]
图54示出了在将数据从主存储器高速缓存到缓存存储器之后执行基于平铺技术的操作的另一示例。
[1045]
参考图54,示出了amc中的主存储器和缓冲存储器(即,高速缓冲存储器)。主存储器和缓冲存储器可以通过系统总线相互连接。图54的示例是应用平铺算法的示例。下文中,将描述平铺的示例。
[1046]
可以平铺存储在主存储器中的内核、输入特征图和输出特征图中的至少一者。主存储器的存储器地址映射可以被平铺。
[1047]
可以平铺存储在缓冲存储器中的内核、输入特征图和输出特征图中的至少一者。可以平铺缓冲存储器的存储器地址映射。
[1048]
如图所示,仅为了方便描述,假设第一层的输入特征图的大小为18
×
18
×
1。输入
特征图可以平铺成四个大小为9
×9×
1的输入特征图。
[1049]
也就是说,第一层的第一输入特征图可以是第一输入特征图切片ifmap_1-1、第二输入特征图切片ifmap_1-2、第三输入特征图切片ifmap_1-3、和第四输入特征图切片ifmap_1-4的组合。可以组合四个输入特征图切片以形成第一输入特征图。
[1050]
在这种情况下,可以重用第一层的第一内核(kernel_1)。因此,每个切片的卷积都可以使用相同的内核。在这种情况下,第一内核(kernel_1)可以在npu内部存储器中重用,直到完成四个平铺。
[1051]
也就是说,当第一内核(kernel_1)和第一输入特征图切片(ifmap_1-1)被卷积时,生成第一输出特征图切片(ofmap_1-1)。当第一内核(kernel_1)和第二输入特征图切片(ifmap_1-2)被卷积时,生成第二输出特征图切片(ofmap_1-2)。当第一内核(kernel_1)和第三输入特征图切片(ifmap_1-3)被卷积时,生成第三输出特征图切片(ofmap_1-3)。当第一内核(kernel_1)和第四输入特征图切片(ifmap_1-4)被卷积时,生成第四输出特征图切片(ofmap_1-4)。可以组合四个输出特征图切片以形成第一输出特征图。
[1052]
在这种情况下,可以将主存储器的存储器地址映射设置为基于平铺的ann dl信息以突发模式操作。即,ann dl信息可以根据平铺方法而改变。平铺策略可以进行各种修改。
[1053]
也就是说,ann dl信息可以包括由npu向主存储器请求的数据的序列和根据平铺的序列。
[1054]
例如,ann dl信息可以包括第一输入特征图切片(ifmap_1-1)、第二输入特征图切片(ifmap_1-2)、第三输入特征图切片(ifmap_1-3)以及第四输入特征图切片(ifmap_1-4)的序列。
[1055]
例如,ann dl信息可以包括第四输入特征图切片(ifmap_1-4)、第三输入特征图切片(ifmap_1-3)、第二输入特征图切片(ifmap_1-2)以及第一输入特征图切片(ifmap_1-1)的序列。
[1056]
也就是说,amc的缓冲存储器可以接收或生成ann dl信息,预测npu要请求的序列,并依次高速缓存与该序列对应的数据。
[1057]
图55图示了根据本公开的各种示例的人工神经网络存储器系统。
[1058]
参考图55,npu和一个或多个内部存储器以片上系统(soc)的形式实现。内部存储器可以是sram。因此,npu和内部存储器可以通过sram接口连接。
[1059]
可以在soc和主存储器之间设置amc。设置在主存储器和内部存储器之间的amc可以被配置为基于ann dl信息预测待由npu请求的数据,并在npu请求实际请求之前预先高速缓存存储在主存储器中的数据。
[1060]
内部存储器可以包括用于存储权重的第一内部存储器、用于存储输入特征图的第二内部存储器和用于存储输出特征图的第三内部存储器。三个内部存储器可以是分配在一个物理存储器中的多个逻辑区域。例如,第二内部存储器的大小可以是128kb,第三内部存储器的大小可以是196kb。
[1061]
npu可以包括pe阵列,该pe阵列包括多个pe和特殊函数单元(sfu)。npu可以从第一内部存储器读取权重,可以从第二内部存储器读取输入特征图,然后可以对输入特征图和权重执行卷积运算,然后将输出特征图输出。
[1062]
此外,一个或多个外部主存储器可以存在于soc之外,并且与soc电连接。外部主存
储器可以是sam或dram。因此,一个或多个外部主存储器和soc可以通过dram接口连接。
[1063]
外部主存储器可以包括用于存储权重的第一外部主存储器和用于存储特征图的第二外部主存储器。两个外部主存储器可以是分配在一个物理存储器内的多个区域。
[1064]
soc可以通过读取命令读取第一外部主存储器中的权重和第二外部主存储器中的特征图,并且可以将数据分别存储在第一内部存储器和第二内部存储器中。此外,soc可以通过写入命令将存储在第三内部存储器中的输出特征图存储到第二外部主存储器。
[1065]
图56显示了图55所示的sfu的详细配置。
[1066]
图56的sfu的每个操作配置的示例可以在下表中组织。表3
[1067]
图57示出了测量缓冲存储器(高速缓存)和主存储器之间的数据总线的带宽的图。
[1068]
图57中所示的图示出了测量当缓冲存储器(高速缓存)和主存储器通过axi4接口连接时的带宽的结果。
[1069]
带宽的测量是在一定情况下执行的,在这种情况下,对于每个axi突发长度(1至16),从作为主存储器的dram十次读取2mb的数据到作为缓冲存储器的sram。axi接口可以调整突发长度。
[1070]
图57所示的图可以总结在下表中。表4
[1071]
当地址为线性时,不管突发长度如何,传输带宽,即传输速度都得到提高。
[1072]
如果突发长度相同,则使用线性地址可能会导致更快的传输速率。可能是有利的是,有效地分配作为主存储器的dram的地址以启用读取突发。
[1073]
突发长度是指在突发中一次读取的长度。在线性情况下,即使突发长度很短,由于dram地址是按顺序递增的,因此可以减少ras延迟和/或cas延迟。
[1074]
也就是说,如果主存储器的存储器映射是基于ann数据局部性信息线性设置的,则与随机情况相比,带宽会增加。因此,可以增加主存储器和缓冲存储器之间的有效带宽。
[1075]
在前述实施方案中描述的特征、结构、效果等包括在本公开的一个实施方案中并且不一定限于一个实施方案。此外,本领域技术人员可以对每个实施方案中示出的特征、结构、效果等进行组合或修改以用于待执行的其他实施方案。因此,本公开的组合和修改被解释为包括在本公开的范围内。
[1076]
在上面的描述中,已经基于示例描述了本公开,但是示例用于说明而不是限制本发明,并且本领域技术人员应理解在以上描述中未例示的各种修改和应用可以在不脱离本示例的基本特征的范围的情况下做出。例如,可以修改和执行示例中具体存在的每个构成要素。此外,与修改和应用有关的差异应理解为包含在所附权利要求所限定的本发明的范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1