基于深度学习的交通灯识别方法与流程
1.本发明属于无人驾驶技术领域,涉及一种基于深度学习的交通灯识别方法。
背景技术:
2.交通灯信号灯的识别是无人驾驶重要环节,目前基于yolov3的算法在检测交通信号灯时存在检测不准确,置信度低的问题,对交通灯的识别产生极大错误后,一旦给出交通灯错误边界框,就会导致车辆做出错误判断。近几年随着无人驾驶研究的兴起,对于车辆准确识别物体的技术成为重点,特别是对于交通灯的识别显得至关重要;准确识别交通灯对于自动驾驶及路径规划有着重要意义。
技术实现要素:
3.有鉴于此,本发明的目的在于提供一种基于深度学习的交通灯识别方法。
4.为达到上述目的,本发明提供如下技术方案:
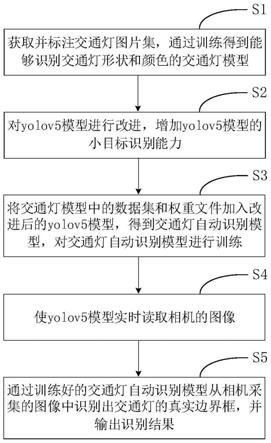
5.一种基于深度学习的交通灯识别方法,包括以下步骤:
6.步骤s1、获取并标注交通灯图片集,通过训练得到能够识别交通灯形状和颜色的交通灯模型;
7.步骤s2、对yolov5模型进行改进,增加yolov5模型的小目标识别能力;
8.步骤s3、将训练好的交通灯模型中的数据集和权重文件加入改进后的yolov5模型,得到交通灯自动识别模型,对交通灯自动识别模型进行训练,使交通灯自动识别模型先识别出交通灯边界框,再从交通灯边界框中识别出交通灯对应的id号;
9.步骤s4、使yolov5模型实时读取相机的图像;
10.步骤s5、通过训练好的交通灯自动识别模型从相机采集的图像中识别出交通灯的真实边界框,并输出识别结果。
11.进一步的,在所述步骤s1中,将交通灯根据形状和颜色的分别划分id号,在标注交通灯图片集时,先在交通灯图片上交通灯的位置处标注出边界框,再标注各边界框中交通灯的形状和颜色对应的id号。
12.进一步的,在所述步骤s2中,对yolov5模型进行改进包括:
13.在其原始特征提取层之后增加多尺度特征提取层和特征融合层,在其目标检测层之前增加小目标检测层,将原始特征提取层输出的特征信息分别送给多尺度特征提取层和特征融合层,所述多尺度特征提取层用于对原始特征提取层输出的特征信息进行过滤,提取出明显的特征信息;所述特征融合层用于将原始特征提取层输出的特征信息和多尺度特征提取层输出的特征信息进行融合;所述小目标检测层用于通过上采样加强小目标的细粒度特征。
14.进一步的,在所述步骤s2中,对yolov5模型进行改进还包括:
15.在yolov5模型的panet架构中,将bottleneckcsp模块替换为ghostbottleneck模块,并将ghostbottleneck模块的子模块的顺序从前至后依次设置为ghostmodule 1模块、
depthwise模块、semodule模块、ghostmodule2模块、identity mapping模块。
16.进一步的,去除ghostmodule2模块的relu函数。
17.进一步的,在所述步骤s4中,读取相机采集的图片后还进行滤波去噪处理,滤波去噪处理的方法为:
18.首先通过灰度图像转换,把彩色图像转化为灰度图,然后进行二值化处理,最后进行高斯滤波去噪处理;滤波函数选择fir windowed filter ptbypt vi。
19.进一步的,在所述步骤s3中,模型训练的公式为:
20.t
x
=(g
x-p
x
)
21.ty=(g
y-py)
22.tw=log(gw/pw)
23.th=log(gh/ph)
24.式中,g
x
表示标注的边界框的中心点的横坐标;gy表示标注的边界框的数据中心点的纵坐标;gw表示标注的边界框的宽;gh表示标注的边界框的高;p
x
表示预测边界框的中心点的横坐标;py表示预测边界框的中心点的纵坐标;pw表示预测边界框的宽;ph表示预测边界框的高;t
x
表示模型训练输出的横向偏移量;ty表示模型训练输出的纵向偏移量;tw表示模型训练输出的横向缩放尺度;th表示模型训练输出的纵向缩放尺度。
25.进一步的,在所述步骤s5中,输出的识别结果包括图片中识别出的边界框的数量、各边界框四个角点的位置信息、各边界框中交通灯信息对应的id号、以及各边界框的置信度。
26.进一步的,在所述步骤s5中,从相机采集的图像中识别出交通灯的方法为:
27.先将交通灯图像划分为sxs的网格,然后依次对每个网格进行识别,预测出边界框;再计算边界框的置信度,并根据预测边界框的置信度和非极大抑制筛选出各交通灯置信度最高的预测边界框;最后识别出交通灯的真实边界框,并输出识别结果。
28.真实边界框的计算公式如下:
29.b
x
=σ(t
x
)+c
x
30.by=σ(ty)+cy[0031][0032][0033]
式中,b
x
表示真实边界框的中心点的横坐标;by表示真实边界框的中心点的纵坐标;σ()表示sigmoid函数;c
x
表示一个为网格宽度的倍数;bw表示真实边界框的宽度;bh表示真实边界框的宽度。
[0034]
进一步的,预测边界框的置信度的计算公式为:
[0035][0036]
其中,d
conf
为预测边界框的置信度;p(o)为被检测目标的概率,如果目标的中心落在网格内,则p(o)为1,否则为0;为预测边界框与真实边界框的交并比。
[0037]
本发明中,采用了基于yolov5的交通灯识别方法,并通过对yolov5的改进,解决了传统识别方法识别图像速度慢,准确低的问题;并增强了对小目标的识别能力,目标识别精
度高,实时性强,操作简单,该交通灯识别方法非常适合应用于无人驾驶技术。
附图说明
[0038]
为了使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作优选的详细描述,其中:
[0039]
图1为本发明基于深度学习的交通灯识别方法的一个优选实施例的流程图。
[0040]
图2为yolov5模型增加多尺度特征提取层和特征融合层后的结构框图。
[0041]
图3为yolov5模型的panet架构改进后的示意图。
[0042]
图4为训练过程中的训练数据集map变化曲线图。
[0043]
图5为预测边界框和真实边界框的示意图。
具体实施方式
[0044]
以下通过特定的具体实例说明本发明的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。需要说明的是,以下实施例中所提供的图示仅以示意方式说明本发明的基本构想,在不冲突的情况下,以下实施例及实施例中的特征可以相互组合。
[0045]
如图1所示,基于深度学习的交通灯识别方法的一个优选实施例包括以下步骤:
[0046]
步骤s1、获取并标注交通灯图片集,采用卷积神经网络进行对标注后的交通灯图片集进行训练,得到符合现实场景的交通灯模型。下面以在labview软件环境下对交通灯进行识别为例进行说明。
[0047]
首先,在labview软件中,搭建open camera.vi,将外接相机读取进来,实现yolov5(人脸识别模型)实时读取图像;然后对相机采集到的交通灯图片进行滤波去噪音处理,得到更清晰图像。滤波去噪音处理的方法为:首先通过灰度图像转换,把彩色图像转化为灰度图,然后进行二值化处理,最后进行高斯滤波去噪处理;滤波函数选择fir windowed filter ptbypt vi。
[0048]
之后,将各个交通灯信息分别划分id号,例如,可以用id号“1”表示右转形状的红灯、用id号“2”表示左转形状的红灯、用id号“3”表示直行形状的红灯、用id号“4”表示右转形状的绿灯、用id号“5”表示左转形状的绿灯、用id号“6”表示直行形状的绿灯、用id号“7”表示右转形状的黄灯、用id号“8”表示左转形状的黄灯、用id号“9”表示直行形状的黄灯。当然,也可以用其他id号来表示上述形状和颜色的交通灯,还可以增加表示其他形状的交通灯的id号(例如,还可增加id号用于表示“调头”的交通灯)。在标注交通灯图片集时,先在交通灯图片上交通灯的位置处标注出边界框,再标注各边界框中交通灯信息(即交通灯的颜色和形状代表的信息)对应的id号。通过训练,得到能够识别出交通灯的形状和颜色,并输出对应的id号的交通灯模型。
[0049]
训练所采集的图片均来自实际交通图片,从而能够提高对现实交通灯识别的准确率。
[0050]
步骤s2、对yolov5模型进行改进,增加yolov5模型的小目标识别能力。对yolov5模
grab.vi,配置摄像头读取图像合适的格式,以获得图像当前的帧。获得图像当前的帧后,可进行滤波去噪处理,以得到清晰的图像。进行滤波去噪处理的方法与步骤s1中的相同。
[0063]
步骤s5、通过训练好的交通灯自动识别模型从相机采集的图像中识别出交通灯的ground truth box(真实边界框,即最终输出的边界框),并输出识别结果。在labview搭建load_detector.vi,在主程序框图中调用此vi,实现修改后的配置文件和训练好的交通灯文件读取进来,训练交通灯数据集的过程如附图2,优化后架构训练数据集map可达80%。识别过程为:
[0064]
先将交通灯图像划分为s
×
s(例如10
×
10)的网格,通过改进后的yolov5模型和训练好的交通灯数据集和交通灯权重文件依次对每个网格进行识别,预测出边界框;
[0065]
然后计算预测边界框的置信度,预测边界框的置信度的计算公式为:
[0066][0067]
其中,d
conf
为预测边界框的置信度;p(o)为被检测目标的概率,如果目标的中心落在网格内,则p(o)为1,否则为0;为预测边界框与真实边界框的交并比。
[0068]
再根据预测边界框的置信度和非极大抑制(non-maximum suppression)筛选出各交通灯置信度最高的预测边界框。非极大值抑制的工作原理如下:
[0069]
对于一个预测边界框b,模型会计算各个类别的预测概率。设其中最大的预测概率为p,该概率所对应的类别即b的预测类别。我们也将p称为预测边界框b的置信度。在同一图像上,我们将预测类别非背景的预测边界框按置信度从高到低排序,得到列表l。从l中选取置信度最高的预测边界框b1作为基准,将所有与b1的交并比大于某阈值的非基准预测边界框从l中移除。这里的阈值是预先设定的超参数。此时,l保留了置信度最高的预测边界框并移除了与其相似的其他预测边界框。接下来,从l中选取置信度第二高的预测边界框b2作为基准,将所有与b2的交并比大于某阈值的非基准预测边界框从l中移除。重复这一过程,直到l中所有的预测边界框都曾作为基准。此时l中任意一对预测边界框的交并比都小于阈值。最终,输出列表l中的所有预测边界框。通过非极大抑制,每一交通灯都只保留一个置信度最高的预测边界框。
[0070]
最后,根据非极大抑制筛选出的预测边界框识别出交通灯的真实边界框,并输出识别结果。输出的识别结果包括图片中识别出的边界框的数量、各边界框四个角点的位置信息、各边界框中交通灯信息对应的id号、以及各边界框的置信度。如图5所示,真实边界框可直接绘制在图片上,真实边界框的计算公式为:
[0071]bx
=σ(t
x
)+c
x
[0072]by
=σ(ty)+cy[0073][0074][0075]
其中,b
x
表示真实边界框的中心点的横坐标;by表示真实边界框的中心点的纵坐标;σ()表示sigmoid函数;c
x
表示一个为网格宽度的倍数;bw表示真实边界框的宽度;bh表示真实边界框的宽度。通过真实边界框的中心点坐标、宽度和高度即可计算出真实边界框的四个角点坐标。
[0076]
本实施例中,采用了基于yolov5的交通灯识别方法,并通过对yolov5的改进,能够准确识别交通灯的边界框,解决了传统识别方法识别图像速度慢,准确低的问题。另外,还增强了对小目标的识别能力,目标识别精度高,实时性强,操作简单,拓宽了识别交通灯的技术,该交通灯识别方法非常适合应用于无人驾驶技术。
[0077]
最后说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本技术方案的宗旨和范围,其均应涵盖在本发明的权利要求范围当中。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1