一种基于多模型融合Stacking算法的煤质熔点预测方法与流程
一种基于多模型融合stacking算法的煤质熔点预测方法
技术领域
1.本发明涉及煤质灰熔点预测技术领域,尤其涉及一种基于多模型融合stacking算法的煤质熔点预测方法。
背景技术:
2.煤质的灰熔点是煤高温特性的重要测定项目之一,煤质熔融温度在工业上不论是火电厂还是煤气化炉中都具有非常重要的意义。传统煤质灰熔点是通过煤质高温实验测定,步骤较为繁琐,需逐步升温至1500度高温,耗时、耗能、耗力且每次测定的化验样品数有限,不适合大规模化验。
3.随着大数据、机器学习算法等计算机技术的发展,近几年采用算法拟合历史数据库的方法被应用在煤质的灰熔点预测中。但目前常见的灰熔点预测方法也存在一定问题。比如:1、特征工程研究较少,选用的特征变量全而不精,影响预测准确率。
4.2、预测数据和历史数据库未做特征范围匹配,如果预测数据特征变量包含在历史数据库内,准确度较好,如果不包含在历史数据库内,准确度大大降低。
5.3、现有煤质灰熔点预测方法使用单一机器学习算法,拟合度和准确度仍有提高的空间。
技术实现要素:
6.鉴于现有技术中的上述缺陷或不足,期望提供一种基于多模型融合stacking算法的煤质熔点预测方法。
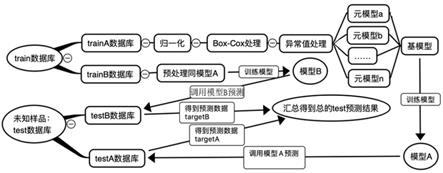
7.本发明提供的一种基于多模型融合stacking算法的煤质熔点预测方法,包括如下步骤:步骤一:使用机器算法预测数据,首先确定煤质流动温度ft是目标变量;确定煤质中氧化物含量及新构造的特征参数是特征变量,所述特征变量为v0至v12共13个,分别对应为na2o、mgo、al2o3、sio2、k2o、cao、p2o5、tio2、fe2o3、so3、k2o+na2o、sio2/al2o3及煤质黏结指数rhj;步骤二:将煤质灰熔点历史数据库命名为train数据库,其中含有13个所述特征变量和1个所述目标变量;将等待预测的数据库命名为test数据库,其中含有13个所述特征变量;步骤三:根据特征变量分布情况将test数据库拆分成testa数据库及testb数据库,testa保留全部13个所述特征变量,testb删除超出范围的特征变量;构建其对应的traina数据库及trainb数据库;具体办法如下:对train数据库和test数据库的13个所述特征变量逐一进行数据分布探索,筛选出test数据库的特征变量均在train数据库范围内的数据集,命名为testa数据库,所述testa数据库仍为13个所述特征变量;如果test数据库内的数据集的某些特征变量超出
train数据库范围,则将这部分数集删除超出范围的特征变量组成testb数据库;减少数据分布偏差大的特征变量影响预测准确度,提高模型的泛化性;步骤四:对traina数据和testa数据库的特征变量和目标变量进行最大最小归一化处理;trainb数据库及testb数据库也同样处理;公式为x’=(x
‑
xmin)/(xmax
‑
xmin);步骤五:对train数据库a和testa数据库的特征变量和目标变量进行box
‑
cox变换,改善数据的正态性、对称性和方差相等性;box
‑
cox数学公式如下:公式中y(λ)为经box
‑
cox变换后得到的新变量,y为原始连续因变量,λ为变换参数;步骤六:对traina数据库和testa数据库的特征变量和目标变量异常值处理;trainb数据库及testb数据库也同样处理;将数据进行正态化处理,此处采用“3σ准则”剔除异常值;步骤七:选择以线性回归、随机森林及svm模型作为基模型,以线性回归作为元模型;首先将训练得到前三个基模型,然后再以基模型的输出作为线性回归的输入训练元模型,最后以线性回归的输出作为真正的分类结果;步骤八:数据经过预处理后,使用traina数据库训练融合stacking模型;选用随机森林、adaboost模型、gboost回归模型、extratrees 模型、linear回归、xgboost回归模型、lgb回归模型作为基模型,选用linear回归模型、lgb 回归模型作为元模型;基模型分别进行单独训练,训练方法如下:交叉验证(cross validation)方法使用k折交叉验证,各模型调参使用网格搜索(grid search)法;单独训练后进行融合,用linear回归模型和lgb 回归模型对新的特征进行拟合训练,得到最终模型a;步骤九:使用步骤八训练的模型a预测testa数据库的灰熔点,同样使用模型b预测testb数据库的灰熔点。
8.优选的,所述煤质黏结指数rhj的计算公式为:rhj=na2o*(fe2o3+cao+mgo+k2o+na2o)/(sio2+al2o3+tio2)。
9.优选的,所述λ最初为未知数,为了使变换后样本y(λ)正态性最好,通过计算机程序计算比较不同的λ下y(λ),找出最优的λ值;有了λ值,将原变量数据y通过box
‑
cox数学公式转换成新的y(λ);v0原skew为2.9017,v0转换skew为
‑
0.2724,转换后的v0更加符合正态分布。
10.相对于现有技术而言,本发明的有益效果是:(1)本发明的煤质熔点预测方法,能够准确、快速、廉价的测定或推测煤质的灰熔点;(2)本发明的煤质熔点预测方法,相比传统实验测定灰熔点,解决了耗时、耗能、耗力的弊端,能对大规模样品进行预测。相比其他机器学习算法预测方法,模型的泛化性强,能够处理特征变量超出数据库的数据预测;(3)本发明的煤质熔点预测方法,使用最新的融合stacking算法训练模型,模型拟
合度高且避免模型过度拟合,预测的准确率高,预测数据方差较小,稳定性好。
11.应当理解,发明内容部分中所描述的内容并非旨在限定本发明的实施例的关键或重要特征,亦非用于限制本发明的范围。本发明的其它特征将通过以下的描述变得容易理解。
附图说明
12.通过阅读参照以下附图所作的对非限制性实施例所作的详细描述,本发明的其它特征、目的和优点将会变得更明显:图1为本发明实施例提供的融合stacking算法的预测流程示意图;图2为拆分test数据库的示意图;图3为拆分test数据库的示例表;图4为v0转换skew前后对比图;图5为采用“3σ准则”数据处理示意图;图6为训练方法示意图;图7为融合stacking算法(ensemble)示意图;图8为某一融合stacking模型a拟合指标;图9为testb数据库的灰熔点的预测数据的评价指标。
具体实施方式
13.下面结合附图和实施例对本发明作进一步的详细说明。可以理解的是,此处所描述的具体实施例仅仅用于解释相关发明,而非对该发明的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与发明相关的部分。
14.需要说明的是,在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。下面将参考附图并结合实施例来详细说明本发明。
15.请参考图1~图9,本发明的实施例提供了一种基于多模型融合stacking算法的煤质熔点预测方法,包括如下步骤:步骤一:使用机器算法预测数据,首先确定煤质流动温度ft加入说明书中是目标变量,灰熔点变形温度、软化温度、半球温度预测方法雷同;确定煤质中氧化物含量及新构造的特征参数是特征变量,特征变量为v0至v12共13个,分别对应为na2o、mgo、al2o3、sio2、k2o、cao、p2o5、tio2、fe2o3、so3、k2o+na2o、sio2/al2o3及煤质黏结指数rhj;其中,k2o+na2o是k2o含量与na2o含量之和,sio2/al2o3是sio2含量除以al2o3含量;步骤二:将煤质灰熔点历史数据库命名为train数据库,其中含有13个特征变量和1个目标变量;将等待预测的数据库命名为test数据库,其中含有13个特征变量;步骤三:请参考图2~图3,根据特征变量分布情况将test数据库拆分成testa数据库及testb数据库,testa保留全部13个特征变量,testb删除超出范围的特征变量;构建其对应的traina数据库及trainb数据库;具体办法如下:对train数据库和test数据库的13个特征变量逐一进行数据分布探索,筛选出test数据库的特征变量均在train数据库范围内的数据集,命名为testa数据库,testa数据库仍为13个特征变量;如果test数据库内的数据集的某些特征变量超出train数据库范围,
则将这部分数集删除超出范围的特征变量组成testb数据库;减少数据分布偏差大的特征变量影响预测准确度,提高模型的泛化性;在此为方便理解,举实例说明,假如test数据库内的数据集的v5,v9特征变量超出train数据库范围,则删除这2个特征变量,组成不含v5,v9的testb数据库,相对应训练模型的数据trainb也删除v5,v9,提高trainb训练出来模型的泛化性。testa, traina则保留全部的v0,v1
……
v12完整的特征变量;如图3所示。
16.步骤四:对traina数据和testa数据库的特征变量和目标变量进行最大最小归一化处理;trainb数据库及testb数据库也同样处理;公式为x’=(x
‑
xmin)/(xmax
‑
xmin);步骤五:对train数据库a和testa数据库的特征变量和目标变量进行box
‑
cox变换,改善数据的正态性、对称性和方差相等性;box
‑
cox数学公式如下:公式中y(λ)为经box
‑
cox变换后得到的新变量,y为原始连续因变量,λ为变换参数;步骤六:请参考图5,对traina数据库和testa数据库的特征变量和目标变量异常值处理;trainb数据库及testb数据库也同样处理;将数据进行正态化处理,此处采用“3σ准则”剔除异常值;图中白色圆圈及白色长条为异常值;步骤七:请参考图6
‑
图7,选择以线性回归、随机森林及svm模型作为基模型,以线性回归作为元模型;首先将训练得到前三个基模型,然后再以基模型的输出作为线性回归的输入训练元模型,最后以线性回归的输出作为真正的分类结果;图7中前三幅为基模型,第四幅为融合分类的结果,明显融合了前三个模型的部分划分,这种多模型融合stacking算法可以集各种机器学习算法之所长,训练拟合度高;步骤八:数据经过预处理后,使用traina数据库训练融合stacking模型;选用随机森林、adaboost模型、gboost回归模型、extratrees 模型、linear回归、xgboost回归模型、lgb回归模型作为基模型,选用linear回归模型、lgb 回归模型作为元模型;基模型分别进行单独训练,训练方法如下:交叉验证(cross validation)方法使用k折交叉验证,各模型调参使用网格搜索(grid search)法;单独训练后进行融合,用linear回归模型和lgb 回归模型对新的特征进行拟合训练,得到最终模型a;trainb数据库和testb数据库也同样处理,得到模型b;请参考图8,某一融合stacking模型a拟合指标的r2= 0.999527248113362,rmse= 0.8000445992757509,mse= 0.6400713608302968,std= 52.227526873070374,拟合度明显优于其他模型;步骤九:请参考图9,使用步骤八训练的模型a预测testa数据库的灰熔点,同样使用模型b预测testb数据库的灰熔点。
17.在一优选实施例中,煤质黏结指数rhj的计算公式为:rhj=na2o*(fe2o3+cao+mgo+k2o+na2o)/(sio2+al2o3+tio2)。
18.在一优选实施例中,λ最初为未知数,为了使变换后样本y(λ)正态性最好,通过计算机程序计算比较不同的λ下y(λ),找出最优的λ值;有了λ值,将原变量数据y通过box
‑
cox
数学公式转换成新的y(λ);v0原skew为2.9017,v0转换skew为
‑
0.2724,转换后的v0更加符合正态分布。
19.本发明的煤质熔点预测方法能够准确、快速、廉价的测定或推测煤质的灰熔点。
20.在本说明书的描述中,术语“连接”、“安装”、“固定”等均应做广义理解,例如,“连接”可以是固定连接,也可以是可拆卸连接,或一体地连接;可以是直接相连,也可以通过中间媒介间接相连。对于本领域的普通技术人员而言,可以根据具体情况理解上述术语在本技术中的具体含义。
21.在本说明书的描述中,术语“一个实施例”、“一些实施例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或特点包含于本技术的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或实例。而且,描述的具体特征、结构、材料或特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
22.以上仅为本技术的优选实施例而已,并不用于限制本技术,对于本领域的技术人员来说,本技术可以有各种更改和变化。凡在本技术的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本技术的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1