多核SOC中非阻塞L1Cache的制作方法
多核soc中非阻塞l1 cache
技术领域
1.本发明涉及计算机体系架构技术领域,尤其是指多核soc中非阻塞l1 cache。
背景技术:
2.随着半导体技术的发展,内存的性能远远跟不上处理器地发展,从20世纪80年代初到21世纪初,处理器每年以大约50%的速度快速发展而dram性能提升速度每年只有10%左右,处理器与dram的速度与带宽严重不匹配,且频繁地访问dram会占用大量的总线带宽。计算机程序的局部性原理指明:如果在某一点时访问了存储器的特定位置,则很可能在不久的将来将再次访问相同的位置;如果特定存储位置在特定时间被访问,则很可能在不久的将来访问附近的存储位置。因此在通用处理器cpu中,常常使用一块小而快的缓存用于缓存具有局部性的数据,以减小处理器对dram地访问,在处理具有局部性的程序时,处理器所需要的数据90%以上都能在缓存中命中,dram地访问数量将会得到极大地降低。l1 cache作为直接与处理器核心cpu进行交互的缓存,它的访问效率会直接影响到cpu的主频,对l1 cache的设计一直是计算机架构领域的重点和热点。
技术实现要素:
3.为此,本发明所要解决的技术问题在于克服现有技术中处理器与dram的速度与带宽严重不匹配的问题,从而提供基于riscv指令集的多核soc中非阻塞l1 cache。
4.为解决上述技术问题,本发明的多核soc中非阻塞l1 cache,所述l1 cache包括icache与dcache两个电路模块,icache电路模块设计为8路组相联双bank sram为cpu取指阶段提供数据访问,dcache电路模块设计为8路组相联单bank sram为cpu lsu取指阶段提供数据访问,另外包括:soc处理器核心cpu所需要的数据在cache中缺失时,cpu不会发生阻塞,等待数据准备好,而是将未准备好数据的指令放入缺失处理队列,继续执行下一条指令,当数据从低层存储器取回l1 cache之后,再重新执行该条指令;soc处理器核心cpu对数据进行修改并写回l1 cache中时,对l1 cache中的数据标记为脏数据,同时当soc中其他cpu对该数据申请访问时,由于数据只在写数据的cpu的本地l1 cache进行更新,其他cpu的本地l1 cache并没有该数据的最新副本,需要利用一致性算法将同步该数据。
5.在本发明的一个实施例中,将缺失的操作记录到缓存缺失缓存队列,并在数据取回l1 cache之后通知cpu重新执行对应的指令,包括:将缺失指令的地址记录到缺失缓存队列中,并通知cpu继续执行后续的指令;同时将缺失数据的地址发送到总线,通知下层存储单元传输对应的数据;将所需的数据通过总线取回到l1 cache的sram中,并将之前存储的缺失指令地址从缺失缓存队列中取出,通知cpu再次执行该指令。
6.在本发明的一个实施例中,多核之间的数据一致性的维护,数据在不同核之间会
cache中dcache不仅提供数据访问也提供数据缓存,处理器cpu对数据修改之后会写入缓存中,此时不同处理器cpu的缓存可能有该数据旧的副本且需要访问,此时需要使用一致性协议通过写回策略将该数据传输到目标cpu。同时经过指令重排序之后可以判断出不同指令之间的相关性,当需要访问的数据地址在cache中缺失时,可以继续执行后续不相关的指令,因此dcache的设计通常为非阻塞式。
附图说明
11.为了使本发明的内容更容易被清楚的理解,下面根据本发明的具体实施例并结合附图,对本发明作进一步详细的说明。
12.图1为本发明一个实施提供的icache对应data_array结构图图2为本发明一个实施提供icache架构图。
13.图3为本发明一个实施提供dcache对应data_array结构图。
14.图4为本发明一个实施提供dcache架构图。
15.图5为本发明一个实施提供writeback模块状态机图。
16.图6为本发明也给实施提供prober模块状态机图。
具体实施方式
17.本实施例提供多核soc中非阻塞l1 cache,所述l1 cache包括icache与dcache两个电路模块,icache电路模块设计为8路组相联双bank sram为cpu取指阶段提供数据访问,具体包括:接受cpu流水线中取指阶段的请求;将请求的地址的11-6位划分为idx地址的31-12位划分位tag,idx用于索引对应的组号,tag用于对比是否匹配;通过idx取出对应的有效位以及tag,若有效位有效,则对比8个tag与cpu请求的tag是否匹配,若匹配则判断命中,返回对应的数据;若不匹配则报告缺失;cpu请求数据缺失将会向总线请求缺失的数据;数据从总线返回时将会填入icache对应的存储单元中,同时将有效位设置为1;在缺失这段时间cpu将会循环请求该指令,当数据填充完毕之后将cpu的请求将会命中,执行接下来的指令。
18.dcache电路模块设计为8路组相联单bank sram为cpu lsu取指阶段提供数据访问,具体包括:接受cpu的数据访问与存储请求;将请求的地址的11-6位划分为idx地址的31-12位划分位tag,idx用于索引对应的组号,tag用于对比是否匹配。
19.通过idx取出对应的权限meta以及tag,若有权限与需要进行的操作匹配,则对比8个tag与cpu请求的tag是否匹配,若匹配则进行cpu请求的操作,返回对应的数据;若不匹配则报告缺失。
20.对权限为dirty的数据进行主动或被动的写回;当远端请求访问的数据在本地为脏数据时,需要进行一致性维护;
当前需要访问的数据在本地缺失时,将缺失数据对应的指令操作存储缺失缓存队列,同时向总线请求缺失的数据,等待数据从下层存储返回后通知cpu重新执行该指令;内部lr/sc一致性模型解决原子访存指令。
21.另外包括:soc处理器核心cpu所需要的数据在cache中缺失时,cpu不会发生阻塞,等待数据准备好,而是将未准备好数据的指令放入缺失处理队列,继续执行下一条指令,当数据从低层存储器取回l1 cache之后,再重新执行该条指令;soc处理器核心cpu对数据进行修改并写回l1 cache中时,对l1 cache中的数据标记为脏数据,同时当soc中其他cpu对该数据申请访问时,由于数据只在写数据的cpu的本地l1 cache进行更新,其他cpu的本地l1 cache并没有该数据的最新副本,需要利用一致性算法将同步该数据。
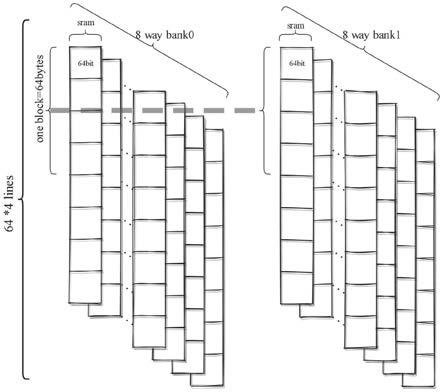
22.将缺失的操作记录到缓存缺失缓存队列,并在数据取回l1 cache之后通知cpu重新执行对应的指令,包括:将缺失指令的地址记录到缺失缓存队列中,并通知cpu继续执行后续的指令;同时将缺失数据的地址发送到总线,通知下层存储单元传输对应的数据;将所需的数据通过总线取回到l1 cache的sram中,并将之前存储的缺失指令地址从缺失缓存队列中取出,通知cpu再次执行该指令。
23.多核之间的数据一致性的维护,数据在不同核之间会有不同的数据权限,该一致性协议定义了4种不同的权限,分别为没有本地数据,本地存在数据但只有读取权限,本地有数据且有读写权限,本地有数据且有读写权限,同时为脏数据,具体包括:当本地没有所需要的数据且当前请求为读取数据时,需要向总线发送请求从远端读取数据;当请求远端的数据没有标记为脏数据时,向请求端返回请求的数据,此时本地与远端都有最新的副本;当请求远端的数据标记为脏数据时,需要先将脏数据写回到下层存储器,同时将数据返回到本地缓存,此时远端与本地都有最新的数据副本;当本地没有所需要的数据且当前请求为写入数据时,需要向总线发送数据请求从远端读取数据;当请求远端的数据没有标记为脏数据时,将数据副本返回到请求端,当本地进行写之后本地的数据副本为脏数据同时将远端的数据副本无效;当请求远端的数据标记为脏数据,需要先将数据副本写回同时将数据返回到请求端,此时远端数据副本变为branch或者trunk,当请求端进行写数据后,本地数据标记为脏数据,同时将远端得数据无效;当本地存在数据副本时,说明所有核的本地缓存没有数据为脏数据,当需要对数据进行读取时,直接通过本地缓存进行读取;当数据需要进行写入时,先判断本地数据对应的权限是否足够,若权限足够直接对数据进行写入,否者需要对数据权限进行升级之后再对数据进行写入,同时将其他核心数据无效化,修改本地数据权限为dirty。
24.需要对dirty数据进行写回处理,写回有两种方式,一种是根据权利3所述一致性维护时对数据进行写回处理,另一种是cpu主动将dirty的数据写回,包括:当一致性维护涉及脏数据时,需要再一致性维护的同时将数据写回到下一级存储器;当脏数据在本地积累太多时,cpu会主动将所有的脏数据一次性进行流水化处理。
25.需要设计独立的缓存icache为cpu取指阶段提供指令,包括:cpu流水线中取指if阶段需要程序计数器pc对应的指令时,将会从icache中取出相应地址对应的指令返回给cpu;icache仅需要对取指阶段为cpu提供数据访问,cpu没有返回给icache的数据,icache的数据全来自下层存储器通过总线对icache的写入,数据不存在数据被cpu写入后变为脏数据,因此不需要对icache提供一致性维护以及数据写回的支持。
26.进一步地,icache设计位8路组相联的双bank结构,有三个存储结构分别为vb_array,tag_array,data_array分别用于存储有效位、tag数据、具体的指令数据。每个数据的有效位仅需要1位来表示,vb_array的大小设计为64x8 bits;每个tag有20位数据,因此tag的大小设计为64x8x20 bits;data_array为存储具体数据的存储结构,如图1所示,分为两个bank的设计用于加快数据的存取延时,在每个bank中分为8个单体的sram,每个bank中对应的一个sram组合起来为一路,每个sram中一行的大小设计为64 bits,4行组成一个bank中的一个block,因此sram的大小为64x4x8x2x64 bits。
27.图2中虚线指示的位置为流水线寄存器,icache设计为2级流水线,分为3个阶段,第0阶段为接受cpu的请求以及总线的refill请求。当req_fire信号有效时,cache开始命中判断逻辑,将地址划分之后分别传输给tag_array与data_array;当总线的d通道的d_fire有效时,将会进入refill逻辑,refill逻辑的优先级高于cpu请求逻辑,否则缺失的请求将会永远缺失。总线的位宽为128 bits,每次refill的大小为一个cache block的大小64b,因此一个block需要4个周期将对应的数据refill到替换算法给出的替换路中,当refill_cnt计数器从0计数到3,传输完成时将会把对应的tag写入tag_array以及将vb_array中对应的位设置为1。invalidated信号表示的是使得当前整个icache无效,是为了配合ifence指令使用的,ifence指令将限制指令执行前后的顺序,会将将icache清空以避免之前指令的影响。
28.icache流水线第1阶段将会得到从sram中读出的tag数据以及data数据,利用读出的20x8的tag以及有效位标识与cpu请求的tag进行比较,若相等则命中, s1_hit拉高进入hit逻辑,否者进入cache miss逻辑。
29.icache流水线的第3阶段将将会返回cpu对应的数据或向总线请求缺失的数据。当为命中逻辑时,将从data_array中读取返回给cpu;若位缺失逻辑将会把缺失数据的地址通过总线的b通道向下层存储器请求缺失的数据,同时通过替换算法生成需要替换的路记忆将缺失地址放入寄存器中,当数据从总线返回之后将通过通过替换路以及缺失地址将对应的数据写入data_array以及tag_array中。
30.需要设计独立的缓存dcache为cpu的slu阶段提供数据的访问与缓存,包括:当指令load指令时需要将请求地址对应的数据提供给cpu,当执行save指令时需要将对应的数据缓存到对应的地址,同时将该数据在dcache中的权限设置为dirty;由于lsu模块不仅需要对dcache进行访问,还需要写入数据,从而导致dcache中的数据变为脏数据,因此对dcache需要加入一致性维护与写回模块,同时为了提高cpu的性能,当lsu需要访问的数据不在dcache中时,cpu不会因为该数据缺失而进入等待状态,而是转去取执行其他与该条指令不相关的指令,因此需要加入缺失缓存处理机制。
31.进一步地,dcache设计为8路组相联的单bank结构,内置三个缓存分别为meta_
array,tag_array以及data_array本别保存权限数据、标签数据以及访存数据。该缓存中设有4个权限分别为nothing、branch、trunk、dirty分别表示为缓存中没有对应数据、缓存中有对应数据但只能进行读取不能进行写入、缓存中有对应数据可以进行读取写入、缓存中有对应数据且已经被cpu写入,因此每个block需要2 bits的数据来表示对应的权限,meta_array的大小设计为2x8x64bits;tag_array的设计跟icache中一致,设计为20x8x64 bits;data_array为单bank设计,如图3所示,由8个sram组成,每个sram中一行为128 bits,4行组成一个cache block,因此dcache的大小为128x8x4x64 bits,大小与icache中的大小一致。
32.图4中虚线指示的位置为流水线寄存器,dcache设计为5级流水线,分为6个阶段。前两级流水线用于处理非原子操作,后三级流水线主要用于处理原子操作。在dcache中由6个数据流,分别为lsu_req, writeback, prober, prefetch, mshr_read, replay。s0阶段主要是数据路径选择, 然后将需要读取数据的地址仲裁器模块, 通过仲裁器判断最后将地址交给meta权限数据存存取模块以及data数据存取模块进行权限与数据的读取。
33.在s1阶段会得到meta信息以及tag信息,该阶段可以利用meta以及tag的信息判断req的操作是否在cache中命中,s1_tag_eq_way为hit logic模块生成的8位one-hot信号,hit logic模块将req的tag与meta中读取出的tag比较,当coh为有效时,s1_tag_eq_way对应的位变为1。s1_tag_eq_way,s1_replay_way_en,s1_wb_way_en, s1_meta_read_way_en都是one-hot信号,way_en select模块将会根据s1_type的类型从中选择一个作为s1_match_way。同时lsu模块也会在该阶段传入分支预测的结果,若分支预测错误则取消该指令的执行,不进行后续流水线的操作以节省能耗。
34.在s2阶段会得到data_array读取的数据,该若为lsu_req数据路径,则判断是否命中,命中则执行相应的写入或则将读取的数据返回到lsu模块,若数据缺失则将缺失操作记录到mshr单元,mshr向总线发送缺失数据的地址,等待总返回对应的数据后记录到对应的缓存中,同时通知lsu进入replay数据;若为replay数据路径,则数据一定在cache中,将在s2阶段给lsu单元返回对应的信息;若为prefetch数据路径,则会将需要预取的地址发送给mshr单元,通过mshr单元向总线请求数据读取;若为writeback数据路径,则发送向总写写回需要写回的数据,同时改变对应数据的权限;若为prober数据路径,则会调用writeback将对应的数据写到总线,同时修改对应数据的权限;若为mshr_read逻辑将会把mshr单元需要读取的数据送入mshr模块。
35.在s2阶段还会对原子操作进行判断,在进行原子操作之前,需要获取对应的锁lr/sc指令就是获取对应锁的过程。lr(load-reserved)为互斥读指令,指令将会用于从存储器(堵住为rs1寄存器的值指定)中读取成出一个32(在译码的过程中,lr_w与lr_d译码成相同的指令,w表示4b对齐,d表示8b对齐)位的数据,存放在rsd寄存器中。sc(load-reserved)为互斥写指令,用于想存储器(地址为rs1寄存器的值指定)中写入一个32位的数据(在译码过程中sc_w与sc_d译码成相同的指令,w表示4b对齐,d表示8b对齐),数据的值来至于rs2寄存器中的值。sc指令不一定能执行成功,只有满足以下条件,sc指令才能执行成功:1、lr与sc指令成对的访问相同的地址;2、lr与sc指令之间没有任何其他操作访问过同样的地址;3、lr与sc指令之间没有任何中断异常发生;4、lr与sc指令之间没有执行mret指令。具体执行步骤为:1、使用lr指令将锁中的值读出;2、对读取的值进行判断,如果发现锁中的值为1,意味着锁正在被其他的核占用,继续返回步骤1重复在读,如果发现锁中的值为0,意味着当前
锁中的值已经为空,进入步骤3;3、使用sc向锁中写入1,试图对其上锁,然后对指令结果返回进行判断,如果返回结果表示互斥写指令执行成功,意味着上锁成功,否则意味着上锁失败。由于第一次读跟第二次写之间没有将总线锁定, 因此其他的核也可能访问锁, 并且其他的核可能发现锁中的值为0,并向锁中写入数值1试图上锁,但系统中的监测会保证先进行互斥写的核才能成功,后进行互斥写的核会失败,从而保证每一次智能有一个核上锁成功。
36.writeback模块为写回模块,该模块由状态机进行控制,writeback的状态机有5个状态,分别为s_invalid,s_fill_buffer,s_lsu_release,s_active,s_grant。状态转移图5所示。s_invalid为初始状态,当req的fire信号有效时,启动状态机,跳转到s_fill_buffer,同时初始化一个data_req_cnt的计数器为0,acked设为0;s_fill_buffer在该状态下,将req地址指向的块读入wb_buffer中,wb_buffer为一个4x128 bits的寄存器,因为在sram中数据存储为128bits为一行,4行为一个block。meta权限数据的读取地址直接为req_idx,但需要注意data的读取地址为{req_idx, data_req_cnt[1:0]}。当对应的仲裁器的ready信号拉高时, wb_io_data_req的ready信号才会有效,当仲裁器的ready信号为1时表示的是相应的数据已经被接收,即数据已经被成功从存储器中,此时将data_req_cnt的值+1表示读取data的下一行数据。需要注意的是wb_buffer赋值时需要打两拍,这是从读取地址进入存储器到数据到输出端需要两个时钟周期的时间,此处需要等到r2_data_req_fire为1的时候写入wb_buffer[r2_data_cnt]为io_data_resp的数据,当wb_buffer缓存完毕之后,进入s_lsu_release状态,同时将data_req_cnt赋值为0。s_lsu_release状态下, wb_buffer的数据已经缓存好为req的数据,此时通过probeack_data函数将数据转化为一个tlbundlec的结构体,交给输出io_lsu_release,当io_lsu_release的数据被正确接收之后,进入s_active状态。s_active状态下将数据传输给总线,根据自动还是被动分别选择release_data或者probeack_data函数将数据转换成tlbundlec类型数据传输到总线中,开始时data_req_cnt的值为0, 每当总线成功接收一个数据, data_req_cnt的值+1。当传输完毕之后,根据是否为主动写回分别进入s_grant状态或者s_invalid状态。注意在该状态之下也可以接收mem_grant信号,当收到该信号之后设置acked为1,表示可以直接结束。s_grant状态下等待io_mem_grant信号,当收到grant信号之后,将acked设置为1,当acked为1之后结束。
[0037]
prober模块有11个状态,分别是s_invalid,s_meta_read,s_meta_resp,s_mshr_req,s_mshr_resp,s_lsu_release,s_release,s_writeback_req,s_writeback_resp,s_meta_write,s_meta_write_resp,他们的状态转移图6所示。s_invalid为初始状态当b通道请求probe, state跳转到s_meta_read状态;s_meta_read状态为读取请求地址的权限与tag信息,此时将输出端口meta_read的valid信号拉高,将req请求的地址消息赋值给meta_read结构,等到metareadarb仲裁器处理该请求,当请求处理完毕反馈ready信号拉高时,state跳转到meta_resp状态;s_meta_resp状态为等待meta与tag数据读取状态,一周期之后直接跳转到s_mshr_req状态;s_mshr_req状态下,old_coh寄存器中已经更新数据为请求的数据的meta权限与tag,同时way_en寄存器有效,可以通过按位异或可以判断出请求的probe的块是否在cache中,即得到tag_matches信号的有效值,通过tag_matches是否为1选择old_coh与nothing状态来更新原来的状态,onprobe函数根据req的请求以及原来的状态
得到新的状态new_coh以及是否为dirty位以及需要返回的param参数;s_lsu_lsu_release状态将数据转换为bundlec结构体交给lsu_release接口当数据成功被lsu端接收之后,跳转到s_release状态;在s_release状态下,rep_valid有效与s_lsu_release一样, 将数据转换为bundlec结构体交给rep, 当数据成功被bus接收之后, 根据当前需要probe的数据是否在cache中,分别跳转到s_meta_write或s_invalid状态。在s_writeback_req状态下,若数据存在cache中,需要将对应的block写回,该状态下就是将writeback req的信息提交给writeback的仲裁器且被writeback模块接收之后,进入s_writeback_resp状态等待写回完成;在s_writeback_resp状态下,需要等待io_wb_req_ready为1时跳转到s_meta_write状态,io_wb_req_ready信号跟wbarb仲裁器相连,最终连接到writeback模块的req接口,writeback的req接口的ready信号只有在s_invalid信号才为1,由于上一个状态s_writeback_rep将会导致writeback模块跳出s_invalid状态,这里需要等待ready信号为1相当于等待writeback模块回到s_invalid状态,即该状态的作用是等待writeback写回模块完成一次写回操作;在s_meta_wirte状态下,将req的信息以及new_coh更新到io_meta_write端口,等待meta写入模块接收数据之后,进入s_meta_write_resp,这里不直接进入s_invalid状态是因为写入需要一个周期的时间,为了保证数据顺利写入加入了s_meta_write_resp;在s_meta_write_resp状态下,该状态作用就是等待一个周期将对应的数据写入权限存储器以及tag存储器。
[0038]
显然,上述实施例仅仅是为清楚地说明所作的举例,并非对实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式变化或变动。这里无需也无法对所有的实施方式予以穷举。而由此所引申出的显而易见的变化或变动仍处于本发明创造的保护范围之中。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1