一种基于TextCNN的主题爬虫方法及系统与流程
一种基于textcnn的主题爬虫方法及系统
技术领域
1.本技术涉及计算机技术领域,具体涉及一种基于textcnn的主题爬虫方法及系统,可应用于网络数据主题爬虫的爬取过程。
背景技术:
2.在爬虫架构中,待爬取url优先队列设计影响着主题爬虫系统爬取效率。主题爬虫根据用户指定的主题,按照指定的爬取策略爬取互联网中的网页。在爬虫获取到的网页链接中混杂着无关网页链接,对爬取效率和资源造成一定的影响。在主题爬虫系统中,待抓取url队列是很重要的一部分。待抓取url队列中的url以什么样的方式分发来爬取的顺序也是目前研究的一个很重要的问题。如何提供一种围绕指定主题,尽量避免无关网页的下载,高效精准的爬虫系统和方法是本领域技术人员亟需解决的问题。
3.目前主题爬虫系统在应用流程中也存在较多可优化的地方:
4.对于基于网页结构的搜索爬取策略,目前,相对于宽度优先遍历策略,深度优先遍历策略是比较流行的爬虫搜索策略。深度优先遍历策略是url优先队列种子分发的一种方法,其思想是按照深度优先的思想,将网页中提出得到的url按照抓取网页的先后顺序添加到url待抓取优先队列的末尾。url优先队列种子按照先进后出,每次从队列尾部取出url进行分发。但是,该爬取策略缺点是没有考虑不同页面的重要程度,会爬取无关的网页,不仅仅浪费爬取资源,也降低爬取效率。
5.对于基于文本内容的搜索爬取策略,主要有fish search搜索策略和sharksearch搜索策略。相对于结构的搜索爬取策略,文本内容的搜索爬取策略考虑了网页文本中的文本信息,如锚文本,文档关键词,利用这些特征为种子url进行高低分评价;但网页有区别去普通文本,它有网页结构特征,即网页不是孤立存在的,它有上下级链接关系。
技术实现要素:
6.本技术的目的是提供一种基于textcnn的主题爬虫方法及系统,以克服传统方法因爬取与主题无关的网页而造成的爬取效率低的问题,提高了网页的爬取效率。
7.为了实现上述任务,本技术采用以下技术方案:
8.根据本技术的第一方面,提供了一种基于textcnn的主题爬虫方法,包括:
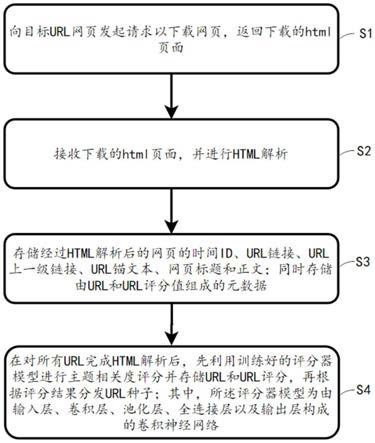
9.向目标url网页发起请求以下载网页,返回下载的html页面;
10.接收下载的html页面,并进行html解析;
11.存储经过html解析后的网页的时间id、url链接、url上一级链接、url锚文本、网页标题和正文;同时存储由url和url评分值组成的元数据;
12.在对所有url完成html解析后,先利用训练好的评分器模型进行主题相关度评分并存储url和url评分,再根据评分结果分发url种子;其中,所述评分器模型为由输入层、卷积层、池化层、全连接层以及输出层构成的卷积神经网络。
13.进一步地,所述评分器模型中,输入层的输入值为网页特征的锚文本特征向量:
14.针对解析后的html页面,提取当前网页的url、上一级网页url、url的锚文本、url的标题作为特征词;
15.对于特征词中的url的锚文本、url的标题,进行以下的预处理过程:
16.中文分词:将特征词中的url的锚文本、url的标题进行中文分词;
17.去停用词和文本填充:将中文分词后获得的特征词中没有语义含义的停用词,并将删除后的停用词采用空格进行填充;该步骤处理后的特征词,与当前网页的url、上一级网页url共同作为网页特征;
18.向量空间表示:对网页特征进行向量化表示,得到锚文本特征向量。
19.进一步地,所述评分器模型中:
20.输入层的输入值为网页特征的锚文本特征向量;
21.卷积层用于对锚文本特征向量进行特征提取,该卷积层设计有6*4个卷积核,分别使用filter window size(2,3,4,5,6,7)个词数作为卷积核的大小,经过该层卷积后的向量vector的shape分别为198*1,197*1,196*1,195*1,194*1,193*1的向量;
22.池化层采用最大值池化方法,用于对卷积层提取后的特征进行文本维度的降低以及特征统一;
23.全连接层用于对池化层输出的特征向量进行拼接,然后提交给输出层;
24.输出层用于对拼接后的特征向量进行分类任务,采用交叉熵作为损失函数;在使用交叉熵的时候直接使用其类别索引0或1。
25.进一步地,所述html解析包括:使用python语言包beautifulsoup将html文本转换成节点树数据结构,然后进行数据清洗去除javascript脚本、缺失的html标签、字符编码和网页广告;最后提取网页中《a》标签内的锚文本、网页中《title》标签内的网页标题和《href》属性节点值url,及提取网页正文content。
26.进一步地,对于存入的元数据,采用不重复存储;在第一次存储元数据时,需要初始化,以存储根url;根url设为目标网站首页url。
27.进一步地,根据url评分高低进行url种子的分发,得分高的url种子优先分配。
28.一种基于textcnn的主题爬虫系统,包括:
29.下载器,用于向目标url网页发起请求以下载网页,返回下载的html页面;
30.解析器,用于接收下载的html页面,并进行html解析;
31.存取器,包括网页文本内容存储器和种子存储器;其中,网页文本内容存储器用于存储经过html解析后的网页的时间id、url链接、url上一级链接、url锚文本、网页标题和正文;种子存储器是一个redis数据库,用于存储由url和url评分值组成的元数据;
32.评分器模块,用于在对所有url完成html解析后,先利用训练好的评分器模型进行主题相关度评分,并将url和url评分存储到种子存储器;种子存储器根据评分结果分发url种子;其中,所述评分器模型为由输入层、卷积层、池化层、全连接层以及输出层构成的卷积神经网络。
33.一种url种子分发方法,包括:
34.步骤1,输入一个或若干个起始网页根url链接,由下载器发送网络请求,下载并返回html页面;
35.步骤2,判断种子存储器中待爬队列是否空或用户是否停止执行,如是则结束爬
取,反之,执行步骤3;
36.步骤3,按照评分值优先队列顺序,从待爬取队列头部取出url;
37.步骤4,向取出的url指向的网页地址发送http请求抓取网页内容并解析网页获取网页url、父网页url及url锚文本,网页标题这些网页特征;
38.步骤5,将网页特征构建特征向量拼接,放入上述评分器模型进行url打分;
39.步骤6,将url和url评分值作为元数据,按照分值高低添加到种子存储器中待爬队列中;其中队列按照分值高低排序。
40.第三方面,本技术提供了一种终端设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,处理器执行计算机程序时实现前述第一方面的基于textcnn的主题爬虫方法的步骤。
41.第四方面,本技术提供了一种计算机可读存储介质,计算机可读存储介质存储有计算机程序,计算机程序被处理器执行时实现前述第一方面的基于textcnn的主题爬虫方法的步骤。
42.与现有技术相比,本技术具有以下技术特点:
43.1.具有高准确率。该主题爬虫爬取的是基于文本内容分析高度相关的网页,网页爬取准确率,取决于模型训练的结果。本技术与最新的textcnn深度学习文本分析融合,大大提高了网页爬取准确度。
44.2.具有高效率性。与传统的主题爬虫系统相比,我们增设了评分器模型。该模型不仅考虑了网页结构特征,还结合了网页文本内容。能够减少对与主题无关的url链接爬取,提高主题爬虫效率。
45.3.具有易拓展性。与传统的textcnn模型相比,我们的模型可以适应网页多维度特征。目前,我们仅考虑了两个网页结构特征,两个文本内容特征。但我们提出的模型是很容易拓展.的。按不同需求,可以添加自定义特征,如文档内关键词,文章摘要,网页超链接数等。
附图说明
46.图1为本技术基于textcnn的主题爬虫方法的流程示意图;
47.图2为本技术中评分器模型的网络构架图;
48.图3为网页文本特征向量化流程图;
49.图4为主题爬虫系统url种子分发器流程图;
50.图5为主题爬虫系统的结构示意图;
51.图6为终端设备的结构示意图。
具体实施方式
52.下面将结合本技术实施例中的附图,对本技术实施例中的技术方案进行清晰地描述。显然所描述的实施仅仅是本技术一部分实施例,而不是全部实施例。基于本技术中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本技术保护的范围。
53.本技术提供了一种基于textcnn的主题爬虫方法及系统,在url分发前之前,针对
不同需求,用textcnn文本分析的方法同时考虑了网页的文本内容和网页结构特征,训练出种子打分器,并进行主题相关性打分,按照打分值高低优先队列进行url种子分发进行主题爬虫爬取。这很大程度上可以克服传统方法因爬取与主题无关的网页而造成的爬取效率低的问题,大大提高了网页的爬取效率。
54.本技术的第一方面提供了一种基于textcnn的主题爬虫方法,包括以下步骤:
55.s1,向目标url网页发起请求以下载网页,返回下载的html页面;其中在下载网页时,设定最大超时连接时间,例如为60s。
56.s2,接收下载的html页面,并进行html解析;其中,html解析包括:使用python语言包beautifulsoup将html文本转换成节点树数据结构,然后进行数据清洗去除javascript脚本、缺失的html标签、字符编码和网页广告;最后提取网页中《a》标签内的锚文本、网页中《title》标签内的网页标题和《href》属性节点值url,及提取网页正文content。
57.s3,存储经过html解析后的网页的时间id、url链接、url上一级链接、url锚文本、网页标题和正文;同时存储由url和url评分值组成的元数据;对于存入的元数据,采用不重复存储;在第一次存储元数据时,需要初始化,以存储根url;根url一般设为目标网站首页url。
58.s4,在对所有url完成html解析后,先利用训练好的评分器模型进行主题相关度评分并存储url和url评分,再根据评分结果分发url种子;具体是根据url评分高低进行url种子的分发,得分高的url种子优先分配。
59.采用评分器模型能有效提高传统的主题爬虫的爬取效率。评分器模型进行主题相关度评分为两个阶段:特征词提取阶段和评分器打分阶段。
60.4.1特征词提取阶段包括:
61.针对解析后的html页面,提取当前网页的url、上一级网页(父网页)url、url的锚文本、url的标题作为特征词。
62.对于特征词中的url的锚文本、url的标题,进行以下的预处理过程:
63.中文分词:使用python语言包jieba将特征词中的url的锚文本、url的标题进行中文分词。
64.去停用词和文本填充:将中文分词后获得的特征词中没有语义含义的停用词,例如的、地、得等进行删除,并将删除后的停用词采用空格进行填充;该步骤处理后的特征词,与当前网页的url、上一级网页url共同作为网页特征。
65.向量空间表示:采用word2vec向量表示法对网页特征进行向量化表示,得到锚文本特征向量;该锚文本的特征向量将作为评分器模型的输入值。具体来说,对于url的锚文本、url的标题、当前网页的url、上一级网页url,使用word2vec向量化,其中每个特征若长度不足max_length,使用0补齐,最后把所有特征向量拼接在一起。
66.4.2评分器打分阶段
67.本方案中的评分器模型采用的textcnn评分器模型,其网络结构包括:
68.输入层:输入层的输入值为网页特征的锚文本特征向量,锚文本特征向量表示为一个n*k的矩阵,其中n为锚文本的单词数,k是每个词对应的嵌入(embedding)的词向量维度。在本实施例中利用word2vec将特征词向量化,在这里每个单词会被300维的向量表示,故k=300,句子不足max_length的单词的后面用0表示。因此特征词会被表示成max_
length*300的锚文本特征向量。以相同的方式处理当前网页的url,上一级网页url,url的锚文本,url的标题。最后的把4个特征向量拼接得到的一个feature,进行输入。在此,需要强调的是传统的textcnn模型只考虑text一个维度;在本方案中,结合网页特征,考虑了url,及父网页url,及网页的标题title等多个特征。值得注意的是,其中url信息中的隐藏了网页的结构层级特征;此外url的标题的文本信息也是对url的anchor锚文本一个很有用的信息补充。因此当前网页的url,上一级网页url,url的锚文本,url的标题等特征的选择都是对当前网页的主题分类具有很好的区分度。
69.卷积层c1:卷积层用于对锚文本特征向量进行特征提取,该卷积层设计有24(6*4)个卷积核,分别使用filter window size(2,3,4,5,6,7)个词数作为卷积核的大小,所以经过该层卷积后的向量vector的shape(sentence length-filter window size+1)分别为198*1,197*1,196*1,195*1,194*1,193*1的向量。在这里考虑多个filter window size的原因是不同的卷积kernel可以捕获不同范围的词的联系,原理跟n-gram类似,如两个词可能是一种特征,三个词可能是另外一种特征。对于每种size(2,3,4,5,6,7)的filter使用24个卷积核进行卷积是从同一个窗口学习词相互之间互补的特征。
70.池化层s1:池化层用于对卷积层提取后的特征进行文本维度的降低以及特征统一;在池化层中,参考常见的几种池化操作,比如均值池化,最大值池化等。在这里使用的是最大值池化。因为最大值池化能够更好的提取邻域内网页文本特征及提取纹理信息。在此架构添加池化层的作用有,能够更好的降低文本维度,及池化操作能将卷积层后得到的文本特征图中的特征进行统一化。
71.全连接层:全连接层用于对池化层输出的特征向量进行拼接,然后提交给输出层。
72.输出层:输出层用于对全连接层输出的拼接后的特征向量进行分类任务,采用交叉熵作为损失函数。因为在损失函数中包含了log(softmax)的计算,所以可以直接将网络全连接层的输出交给交叉熵损失函数计算。此外,值得注意的是,在使用交叉熵的时候target不是one-hot vector,而是需要直接使用其类别索引0或1。
73.4.3评分器模型的训练
74.(1)样本采集
75.在搭建好评分器模型后,需要进行样本采集。首先本方案需要先确定数据集的正负样本,以便模型进行合理而有效的分类;在本方案分类任务中,需要识别出哪些是主题类网站,在此,以新闻类的网站为例。本方案可以通过使用url-pattern人工来标记数据集,共标记了上百万条urls.标记规则如下:
76.url中符合如下规则的标记为新闻类网页,并复制label字段为1:
77.含有“article
‑”
、“detail”、“doc
‑”
、“docid”、“blog_”、“weibook”等字符。
78.url中符合如下规则的标记为非新闻类网页,并复制label字段为0:
79.域名长度少于3的,即一级页面和二级页面;含有“login”、“product_id”、“wanwan”、“weather”、“game”等字符。
80.(2)模型参数设置
81.本实施例中利用pytorch作为本方案的实践案例,在该案例中,评分器模型的参数设置如下:
82.模型参数:
83.filter_sizes:2,3,4,5,6,7
84.input_channel:1
85.num_filters:128,每个filter size拥有的filters的数量
86.dropout_keep_prob:0.5,随机drop关闭/丢弃神经元参数的概率
87.l2_reg_lambda:0.0,l2正则化lambda(default:0.0)
88.训练参数:
89.batch size:512,批处理大小
90.epochs:100,训练的epochs
91.learning rate,0.01。
92.(3)训练过程
93.在训练模型中,使用小批次数据集训练,并采用bceloss,衡量目标和输出之间的二进制交叉熵的标准。具体的,损失loss函数可以表示为:
94.l(x,y)=l={l1,
…
,ln}
95.其中,
96.ln=-wn[yn*logxn+(1-yn)*log(1-xn)]
[0097]
这里n为batch size,xn为评分器模型的输出,yn为实际值,wn表示权值。
[0098]
在训练模型中,每次加载数据训练时,先打乱数据的顺序,然后按照训练集跟测试集为9:1的比例切割数据集;其中打乱数据的顺序是为了保证数据的随机性。为了防止过拟合问题,及测试训练出来的分类器模型的泛化能力,本方案需要对数据集进行划分;本方案使用留一法对数据集进行分割。
[0099]
为了检验本方案的评分器模型,可以将其看成是一个分类问题,主题相关的url可以看成是正类;对于分类算法的性能评估指标主要有两个:召回率和准确率。召回率是指爬取到的网页与新闻类相关的数量与互联网中所有与新闻类相关网页的比值。其计算公式为:
[0100]
recall=(d/s)*100
[0101]
其中d表示已经下载好的与新闻类相关的网页;s表示互联网中与新闻类相关的所有网页。
[0102]
准确率(precision)是指爬虫程序爬取下来的与新闻类相关的页面与爬虫程序爬取的网页总数的比值,其计算公式与上述公式类似,相应的d表示已经下载下来的与新闻类相关的网页,s表示下载的页面总数。
[0103]
由于很难估计互联网中存在多少与新闻类相关的网页,故很难使用召回率对评分器,进行性能评估,本方案提出了两个基于采用主题爬虫的爬取准确率的衡量指标。
[0104]
衡量指标一:利用自定义的url的标记规则来识别新闻类网页数,统计前后爬取的新闻类网页数占总网页数的比例,该比例越大,效果越好。
[0105]
衡量指标二:统计页面内的正文数/页面的链接数,一般来说,新闻类的正文数比普通网页要多,而链接数较少;若正文数/页面的链接数值越大,说明该网页是新闻类网页可能性越大。
[0106]
为了优化本技术,在训练好模型之后进行保存,以便添加到主题爬虫的调度器中,模型的保存有两种形式,一是保存神经网络及对应的参数,这种方法会占用较大的储存空
间。另外一种是只保存神经网络的参数,这种方法在模型加载之前需要先定义网络。在此,本技术建议只保存神经网络的参数。然后在主题爬虫系统定义网络并加载模型。
[0107]
根据本技术的第二方面,提供了一种基于textcnn的主题爬虫系统1,如图5所示,包括:
[0108]
下载器11,用于向目标url网页发起请求以下载网页,返回下载的html页面;其中在下载网页时,设定最大超时连接时间,例如为60s。
[0109]
解析器12,用于接收下载的html页面,并进行html解析;其中,html解析包括:使用python语言包beautifulsoup将html文本转换成节点树数据结构,然后进行数据清洗去除javascript脚本、缺失的html标签、字符编码和网页广告;最后提取网页中《a》标签内的锚文本、网页中《title》标签内的网页标题和《href》属性节点值url,及提取网页正文content。
[0110]
存取器13,包括网页文本内容存储器和种子存储器;其中,网页文本内容存储器用于存储经过html解析后的网页的时间id、url链接、url上一级链接、url锚文本、网页标题和正文;种子存储器是一个redis数据库,用于存储由url和url评分值组成的元数据;对于存入的元数据,采用不重复存储;种子器存储器在第一次爬取,需要初始化,以存储根url;根url一般设为目标网站首页url。
[0111]
评分器模块14,用于在对所有url完成html解析后,先利用训练好的评分器模型进行主题相关度评分,并将url和url评分存储到种子存储器;种子存储器根据评分结果分发url种子;其中,所述评分器模型为由输入层、卷积层、池化层、全连接层以及输出层构成的卷积神经网络。
[0112]
上述下载器、解析器、存储器和评分器模块中对应的实现步骤请参见前述方法实施例的s1至s4,在此不赘述。
[0113]
基于上述爬虫系统,url种子分发的流程包括:
[0114]
步骤1,输入一个或若干个起始网页根url链接,由下载器发送网络请求,下载并返回html页面;
[0115]
步骤2,判断种子存储器中待爬队列是否空或用户是否停止执行,如是则结束爬取,反之,执行步骤3;
[0116]
步骤3,按照评分值优先队列顺序,从待爬取队列头部取出url;
[0117]
步骤4,向取出的url指向的网页地址发送http请求抓取网页内容并解析网页获取网页url、父网页url及url锚文本,网页标题这些网页特征;
[0118]
步骤5,将网页特征构建特征向量拼接,放入上述评分器模型进行url打分;
[0119]
步骤6,将url和url评分值作为元数据,按照分值高低添加到种子存储器中待爬队列中;其中队列按照分值高低排序。
[0120]
该步骤中不对url评分值直接设置过滤值,如直接过滤url,则可能导致网络爬虫空间隧道问题。在这个处理的最好的处理办法是加入监控器,如果长时间内没有url评分值的url加入种子存储器,则发出提醒,及时更换种子。
[0121]
请参阅图6,本技术实施例进一步提供一种终端设备2,该终端设备2可以为计算机、服务器;包括存储器22、处理器21以及存储在存储器22中并可在处理器上运行的计算机程序23,处理器21执行计算机程序23时实现上述基于textcnn的主题爬虫方法的步骤,例
如,前述的s1至s4。
[0122]
计算机程序23也可以被分割成一个或多个模块/单元,一个或者多个模块/单元被存储在存储器22中,并由处理器21执行,以完成本技术。一个或多个模块/单元可以是能够完成特定功能的一系列计算机程序指令段,该指令段用于描述计算机程序23在终端设备2中的执行过程,例如,计算机程序23可以被分割为下载器、解析器、存储器和评分器模块,各模块的功能参见前述系统中的描述,不再赘述。
[0123]
本技术的实施提供了一种计算机可读存储介质,计算机可读存储介质存储有计算机程序,计算机程序被处理器执行时实现上述基于textcnn的主题爬虫方法的步骤,例如,前述的s1至s4。
[0124]
集成的模块/单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本技术实现上述实施例方法中的全部或部分流程,也可以通过计算机程序来指令相关的硬件来完成,计算机程序可存储于一计算机可读存储介质中,该计算机程序在被处理器执行时,可实现上述各个方法实施例的步骤。其中,计算机程序包括计算机程序代码,计算机程序代码可以为源代码形式、对象代码形式、可执行文件或某些中间形式等。计算机可读介质可以包括:能够携带计算机程序代码的任何实体或装置、记录介质、u盘、移动硬盘、磁碟、光盘、计算机存储器、只读存储器(rom,read-only memory)、随机存取存储器(ram,random access memory)、电载波信号、电信信号以及软件分发介质等。需要说明的是,计算机可读介质包含的内容可以根据司法管辖区内立法和专利实践的要求进行适当的增减,例如在某些司法管辖区,根据立法和专利实践,计算机可读介质不包括电载波信号和电信信号。
[0125]
以上实施例仅用以说明本技术的技术方案,而非对其限制;尽管参照前述实施例对本技术进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本技术各实施例技术方案的精神和范围,均应包含在本技术的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1