一种改进G-means向量元的变压器绕组故障诊断方法与流程
一种改进g-means向量元的变压器绕组故障诊断方法
技术领域
1.本发明涉及变压器绕组故障诊断技术领域,具体地说是一种改进g-means向量元的变压器绕组故障诊断方法。
背景技术:
2.变压器发生故障将危及电力系统的安全稳定运行,而变压器发生的故障中绕组机械故障占很大比重,因此需要对变压器绕组的状态进行有效感知和故障诊断。想要快速准确的识别变压器绕组的状态信息和实现故障诊断前提是对变压器绕组状态信号进行有效的特征提取。
3.在变压器的使用过程中,流过绕组的负载电流在漏磁场下受到电动力的作用,使绕组产生机械振动,振动通过连接部件传递到变压器表面。目前,基于振动信号分析绕组机械状态是绕组故障诊断的重要手段。已有的信号分析方法有小波奇异性分解、小波包分解等。g-means向量元分解可以将非线性非平稳的信号分解为多个简单的平稳信号之和,每个信号都有一个中心频率,但方法本身也有缺点,可能会产生信号的过分解或者分解不充分的情况,干扰原信号成分的分析。
技术实现要素:
4.本发明的目的在于提供一种改进g-means向量元的变压器绕组故障诊断方法,针对当前故障诊断方法g-means向量元方法实施中向量元中心初始化敏感的问题,通过改进后的沙丁鱼群算法避免g-means算法陷入局部最优的情况,提高了向量元分类准确度和故障诊断准确度。
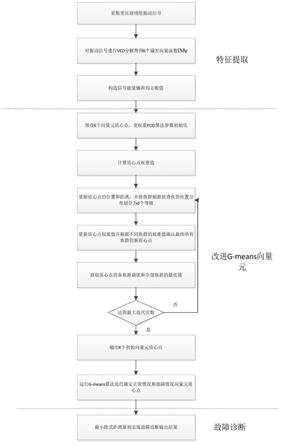
5.本发明解决其技术问题所采取的技术方案是:一种改进g-means向量元的变压器绕组故障诊断方法,其特征在于,它包括以下步骤:
6.1、采集变压器绕组振动信号,对实际测得的变压器绕组振动信号进行g-means向量元分解ved,引入偏差系数γ,得到k个偏差向量函数imγ;
7.2、构造信号特征向量(能量熵和均方根值)
8.引入ved能量熵的概念:变压器绕组振动信号的ved分解得到n个ief分量,相应可计算出对应各自的能量值f1,e2,
…
,en,得到ved能量熵的定义:
[0009][0010]
式中:pi=ei/e为第i个向量函数iefi的能量占总能量的比例;
[0011]
引入信号均方根值rms,信号x(t)的均方根值x
rms
是平均功率的一种度量法,表达式为:
[0012][0013]
3、通过人工沙丁鱼群算法,优化选取g-means算法初始向量元中心;
[0014]
4、运行人工沙丁鱼群算法优化后的g-means算法,利用训练样本确定向量元中心;
[0015]
5、故障诊断
[0016]
计算测试样本与不同向量元中心最小欧式距离,依据最小欧式距离原则实现故障识别。
[0017]
进一步地,优化选取g-means算法初始向量元中心的方法为:
[0018]
i、参数初始化和得到初始解
[0019]
初始化鱼群规模按3∶1∶1∶1的比例分配内围鱼、侦查鱼、管理鱼、外围鱼的数量,初始化食物源位置、藻类量、侦查鱼最大行进次数g
top
和管理鱼最大规模s
limit
;
[0020]
ii、评价每个藻类量的适应度,将每个食物源的最优藻类量ai经处理后作为初始食物源的参数,其中a
averi
为各食物源最优藻类量ai的平均值,σ为分配常数;
[0021]
iii、根据下式更新食物源位置
[0022]
x
m,n
(t+1)=x
m,n
(t)+θ0×vm,n
(t+1),n=1,2,...,d
ꢀꢀ
(3)
[0023][0024]
其中,x
m,,n
(t)为食物源位置函数,θ0为0.5-1.5的常量,v
m,n
(t)为觅食函数,c1为单侦查鱼学习算子,r1为单管理鱼学习算子,c2为群侦查鱼学习算子,r2为群管理鱼学习算子,n
m,n
为侦查鱼行进路线函数;
[0025]
iv、根据下式更新权重值。
[0026][0027]
式中:w
max
为权重系数最大值、w
min
为权重系数最小值,t为当前迭代步数;
[0028]
v、将处理后的每个藻类量的适应度值x
best
与j
best
、h
best
比较,若优于j
best
、h
best
则进行替代;然后比较当前所有的j
best
、h
best
,更新h
best
;x
best
为最佳适应度,h
best
为最优能量熵,j
best
为最优种群算子;
[0029]
vi、如果满足终止条件(达到侦查鱼行进的最大次数),算法终止,输出此时外围鱼数量对应的初始向量元中心,否则返回步骤iii。
[0030]
进一步地,利用训练样本确定向量元中心的方法为:
[0031]
i、初始化:选取人工沙丁鱼群算法得出的样本数据作为初始向量元质心点x;
[0032]
ii、类划分:将初始向量元质心点类比为不同的沙丁鱼群中心,根据侦查鱼的位置分布得到不同鱼群的外围鱼位置,根据不同鱼群的管理鱼逻辑判断结果得到各鱼群的内围鱼数量,根据内围鱼数量和外围鱼位置的不同将各向量元中心从最大权值开始将鱼群平均划分为d个等级,其中:
[0033][0034]
式中:δt为己迭代次数;bh
food
(t)为食物位置向量;bh
sardine
(t)为侦查鱼位置向量;w
max
为权重系数最大值、w
min
为权重系数最小值;t
out
为预设最大迭代次数;
[0035]
iii、重新计算质心点:计算d个等级中各鱼群的位置中心作为各自鱼群的新质心点,再根据各自鱼群的加权值确定最终的全部鱼群的质心点:
[0036][0037]
式中,x
end
为截止位置函数,xi为各食物群位置函数,ωi为各食物群权重值;
[0038]
iv、重复以上步骤直至最终的质心点稳定,算法结束。
[0039]
本发明的有益效果是:本发明提供的一种改进g-means向量元的变压器绕组故障诊断方法,针对当前故障诊断方法g-means向量元方法实施中向量元中心初始化敏感的问题,通过改进后的沙丁鱼群算法避免g-means算法陷入局部最优的情况,提高了向量元分类准确度和故障诊断准确度。
附图说明
[0040]
图1为三种工况下的均方根值和向量元中心位置示意图;
[0041]
图2为本发明改进g-means向量元方法的自适应度曲线图;
[0042]
图3为本发明的算法示意图。
具体实施方式
[0043]
下面对本发明的改进g-means向量元的变压器绕组故障诊断方法进行详细描述。
[0044]
一种改进g-means向量元的变压器绕组故障诊断方法,包括以下步骤:
[0045]
1、采集变压器绕组振动信号,对实际测得的变压器绕组振动信号进行g-means向量元分解ved,引入偏差系数γ,得到k个偏差向量函数imγ。经偏差系数修正后的偏差向量函数具有更好的奥比托克稳定性,利于参与后续经人工沙丁鱼群算法优化的g-means向量元结果的计算。
[0046]
2、构造信号特征向量(能量熵和均方根值)
[0047]
引入ved能量熵的概念:变压器绕组振动信号的ved分解得到n个ief分量,相应可计算出对应各自的能量值e1,e2,
…
,en。由于各个ief分量包含不同的频率组成成分,对应着不同的能量矩阵e={e1,e2,...,en},构成振动信号的能量分布。得到ved能量熵的定义:
[0048][0049]
式中:pi=ei/e为第i个向量函数iefi的能量占总能量的比例。引入信号均方根值rms。信号x(t)的均方根值x
rms
是平均功率的一种度量法,表达式为:
[0050][0051]
3、通过人工沙丁鱼群算法,优化选取g-means算法初始向量元中心。
[0052]
人工沙丁鱼群算法(assa)模拟自然界沙丁鱼群确定行进方向和鱼群规模的过程,将沙丁鱼分为四个工种,分别为侦查鱼、外围鱼、内围鱼和管理鱼。其中内围鱼约占鱼群总量的一半,决定了鱼群的规模即加权值,外围鱼对应算法的初始向量元中心,管理鱼负责逻辑判断单条鱼应属于哪个工种,侦查鱼的数量对应食物源的数量,侦查鱼的行进方向代表问题的一个可能解。每个食物源的位置代表优化问题的一个可能解,每个食物源的藻类量对应每个解的适应度。
[0053]
沙丁鱼执行觅食的过程概括为:(1)侦查鱼确定食物源,对其进行标记并通知管理鱼;(2)管理鱼根据食物源位置和藻类量决定内围鱼数量;(3)对应食物源的内围鱼数量最多的鱼群将优先跟随侦查鱼行进,附加于内围鱼的外围鱼群即算法的初始向量元中心。
[0054]
改进人工沙丁鱼群算法(assa)的流程为:
[0055]
i、参数初始化和得到初始解。
[0056]
初始化鱼群规模fze按3∶1∶1∶1的比例分配内围鱼、侦查鱼、管理鱼、外围鱼的数量,初始化食物源位置、藻类量、侦查鱼最大行进次数g
top
和管理鱼最大规模s
limit
。
[0057]
ii、评价每个藻类量的适应度,将每个食物源的最优藻类量ai经处理后作为初始食物源的参数,其中a
averi
为各食物源最优藻类量ai的平均值,σ为分配常数。
[0058]
iii、根据下式更新食物源位置。
[0059]
x
m,n
(t+1)=x
m,n
(t)+θ0×vm,n
(t+1),n=1,2,...,d
ꢀꢀ
(3)
[0060][0061]
其中,x
m,,n
(t)为食物源位置函数,θ0为0.5~1.5的常量,v
m,n
(t)为觅食函数,c1为单侦查鱼学习算子,r1为单管理鱼学习算子,c2为群侦查鱼学习算子,r2为群管理鱼学习算子,n
m,n
为侦查鱼行进路线函数。
[0062]
iv、根据式(5)更新权重值。
[0063][0064]
式中:w
max
为权重系数最大值、w
min
为权重系数最小值,t为当前迭代步数。
[0065]
v、将处理后的每个藻类量的适应度值x
best
与j
best
、h
best
比较,若优于j
best
、h
best
则进行替代。然后比较当前所有的j
best
、h
best
,更新h
best
。x
best
为最佳适应度,h
best
为最优能量熵,j
best
为最优种群算子。
[0066]
vi、如果满足终止条件(达到侦查鱼行进的最大次数),算法终止,输出此时外围鱼数量对应的初始向量元中心,否则返回步骤iii。
[0067]
4、运行人工沙丁鱼群算法优化后的g-means算法,利用训练样本确定向量元中心
[0068]
i、初始化:选取人工沙丁鱼群算法得出的样本数据作为初始向量元质心点x。
[0069]
ii、类划分:将初始向量元质心点类比为不同的沙丁鱼群中心,根据侦查鱼的位置分布得到不同鱼群的外围鱼位置,根据不同鱼群的管理鱼逻辑判断结果得到各鱼群的内围鱼数量,根据内围鱼数量和外围鱼位置的不同将各向量元中心从最大权值开始将鱼群平均划分为d个等级,其中:
[0070][0071]
式中:δt为己迭代次数;bh
food
(t)为食物位置向量;bh
sardine
(t)为侦查鱼位置向量;w
max
为权重系数最大值、w
min
为权重系数最小值;t
out
为预设最大迭代次数。
[0072]
iii、重新计算质心点:计算d个等级中各鱼群的位置中心作为各自鱼群的新质心点,再根据各自鱼群的加权值确定最终的全部鱼群的质心点:
[0073][0074]
式中,x
end
为截止位置函数,xi为各食物群位置函数,ωi为各食物群权重值。
[0075]
iv、重复以上步骤直至最终的质心点稳定,算法结束。
[0076]
5、故障诊断
[0077]
计算测试样本与不同向量元中心最小欧式距离,依据最小欧式距离原则实现故障识别。
[0078]
下面提供一种具体的算例对本发明进行详细说明,本发明选取了变压器绕组三种工况下的5组处理得到的ved熵值和均方根值,如表1所示。
[0079]
表1
[0080][0081]
本发明利用改进的g-means向量元分析将均方根值及ved熵这两个维度相结合,来
表征故障类型的差异性。根据改进g-means向量元方法将均方根值和ved熵进行二维向量元,得到三个初始簇中心,分别表征变压器绕组正常振动信号、绕组松动故障信号、绕组绝缘脱落振动信号。
[0082]
由图1可知,三种工况下的振动信号被进行了有效的分类。由改进后的g-means向量元分析求得的三个向量元中心分别为(1.001,0.201),(0.97,0.373),(1.074,0.1334)。
[0083]
分析以上结果如下:
[0084]
使用欧氏距离计算测试样本与三个向量元中心的距离,即
[0085][0086]
式中,(c
j1
,c
j2
)表示的是c1,c2,c3的坐标;d1表示测试样本与绕组松动故障信号中心c1的距离;d2表示测试样本与绕组绝缘脱落振动信号中心c2的距离;d3表示测试样本与绕组正常工作振动信号中心c3的距离。
[0087]
对剩余的各20组测试样本,利用最小欧式距离原则对按照正常状态、绕组松动故障、绝缘脱落故障顺序组成的60组测试样本进行判断。定义的最小欧氏距离dj:
[0088][0089]
求解第n个样本的dj值,对应样本属于第j类状态,识别结果如表2所示验证了改进g-means向量元算法的有效性。
[0090]
表2
[0091][0092]
为说明改进e-means算法的优越性,本发明利用广泛使用的iris数据集对向量元算法的准确度进行验证,同时与传统的g-means算法向量元结果进行了对比。试验中,本发明所提向量元算法的各项参数设定如下,总鱼群数150、侦查鱼因子为1.5、管理鱼因子为2、可变权重的权重最大值为0.9、最小值为0.4、最大迭代次数为2000。如图2所示,为本发明改进向量元方法的自适应度曲线图,从图中可以看出,算法在初期适应度值下降的很快,迅速陷入了局部最优解,在经历了一段时间后,在第一绿色箭头处跳出了局部最优解,一段时间后再一次跳出了局部最优解。因此本发明所涉及算法能够有效避免出现局部最优解的现象,使算法的整体寻优能力得以增强。
[0093]
表3
[0094]
算法数据部样本数错误数准确率传统g-meansiris1501490.7%改进g-meansiris1501093.3%
[0095]
表3为传统g-means算法与本发明向量元方法测试结果对比,能够看出本文向量元方法有更高的分类准确度。因此,变权重g-means算法有效的实现了对于g-means向量元的优化,提高了整个算法的全局搜索能力,一定程度上解决了g-means向量元容易陷入局部最优的问题,提高了最终的分类准确度。
[0096]
本发明提供的一种改进g-means向量元的变压器绕组故障诊断方法,针对当前故障诊断方法g-means向量元方法实施中向量元中心初始化敏感的问题,通过改进后的沙丁鱼群算法避免g-means算法陷入局部最优的情况,提高了向量元分类准确度和故障诊断准确度。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1