基于IGA-BP神经网络的土壤调理时间序列预测方法和系统与流程
基于iga-bp神经网络的土壤调理时间序列预测方法和系统
技术领域
1.本发明涉及土壤调理技术领域,具体涉及一种基于iga-bp神经网络的土壤调理时间序列预测方法、系统、存储介质和电子设备。
背景技术:
2.任何一种作物都可将整个生长发育过程划分为若干子周期,如草莓的全生长周期可以划分为开始生长期、开花和结果期、旺盛生长期和花芽分化期。由于每个周期内作物所需的营养物质均存在差异,因此通过海量作物生长发育数据,结合当下特定种植作物和土壤墒情,预测土壤时间序列演变规律,在研究土壤演化速率与方向、建立土壤养分发生演化模型上具有重要的价值,并且能为土壤发生学理论的验证提供宝贵的信息。例如借助遗传算法优化bp神经网络可以明确作物种植区土壤调理时间序列的趋势。所述土壤调理时间序列是指在海量土壤数据的基础上,预测未来一段时间土壤养分的演变规律,并结合具体作物生长特征和当地土壤养分等级评级体系双向匹配出最佳土壤调理成分,便于为进一步实现作物精准施肥提供科学方案。
3.bp神经网络(back propagation net-work,bp)是目前应用最广的一种神经网络,基于最陡坡降法来实现误差函数的最小化,通过误差的反向传递实现对算法结果的逐步修正,以此实现对土壤养分的精准预测。
4.遗传算法(genetic algorithm,ga)是一类借鉴生物界的进化规律演化而来的随机化搜索方法,其主要特点是直接对结构对象进行操作,不存在求导和函数连续性的限定;具有内在的隐并行性和更好的全局寻优能力;采用概率化的寻优方法,能自动获取和指导优化的搜索空间,自适应地调整搜索方向,不需要确定的规则。
5.但是,常见的遗传算法优化bp神经网络将隐含层神经节点与对应的权值和阈值剥离开,从而造成了土壤调理时间序列预测结果不准确。
技术实现要素:
6.(一)解决的技术问题
7.针对现有技术的不足,本发明提供了一种基于iga-bp神经网络的土壤调理时间序列预测方法和系统,解决了土壤调理时间序列预测结果不准确的技术问题。
8.(二)技术方案
9.为实现以上目的,本发明通过以下技术方案予以实现:
10.一种基于iga-bp神经网络的土壤调理时间序列预测方法,包括:
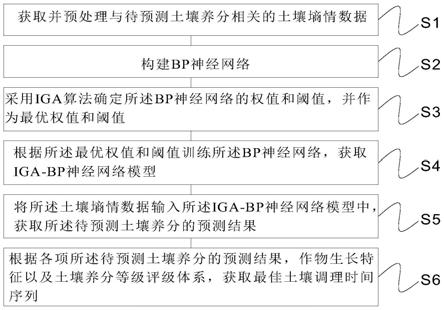
11.s1、获取并预处理与待预测土壤养分相关的土壤墒情数据;
12.s2、构建bp神经网络;
13.s3、采用iga算法确定所述bp神经网络的权值和阈值,并作为最优权值和阈值;
14.s4、根据所述最优权值和阈值训练所述bp神经网络,获取iga-bp神经网络模型;
15.s5、将所述土壤墒情数据输入所述iga-bp神经网络模型中,获取所述待预测土壤
养分的预测结果;
16.s6、根据各项所述待预测土壤养分的预测结果,作物生长特征以及土壤养分等级评级体系,获取最佳土壤调理时间序列。
17.优选的,所述s1中采用相关性检验方法获取与待预测土壤养分相关的土壤墒情数据,所述待预测土壤养分包括有机质、钙、镁或者硫元素。
18.优选的,所述s2中bp神经网络的构建过程具体包括:
19.将所述与待预测土壤养分相关的土壤墒情数据作为输入参数;将所述待预测土壤养分作为输出参数,确定所述bp神经网络的输入层节点数和输出层节点数;
20.根据所述输入层节点数和输出层节点数,确定所述bp神经网络的隐含层节点数;
21.初始化所述bp神经网络的隐含层阈值、输出层阈值、隐含层到输入层和输出层的连接权值。
22.优选的,所述s3具体包括:
23.s31、根据多组所述bp神经网络的隐含层阈值、输出层阈值、隐含层到输入层和输出层的连接权值,采用实数编码获取初始种群;
24.s32、确定适应度函数,计算当前种群中所有个体的适应度值;
25.s33、判断是否满足迭代终止条件,若是,转入s37;否则,转入s34;
26.s34、采用排序选择方法从当前种群中随机选择父代染色体;
27.s35、按照预设的交叉概率,结合多点交叉算子,将两条所述父代染色体执行交叉操作获取对应的子代染色体,所述多点交叉算子通过结合线性交叉与凸交叉构建;
28.s36、按照预设的变异概率,结合变异算子,将两条所述子代染色体执行变异操作,更新当前种群后转入s32;
29.s37、从当前种群中选择最优个体,将所述最优个体对应的权值和阈值作为所述最优权值和阈值。
30.优选的,所述s32中适应度函数为相对适应度函数,通过第一适应度函数确定;
31.所述第一适应度函数:
[0032][0033][0034]
所述相对适应度函数:
[0035][0036]
其中,e表示每个样本对应当前种群中每个个体,基于所述bp神经网络的学习误差;m表示包括所述待预测土壤养分及其相关的土壤墒情数据的训练样本容量;ol表示所述输出节点数;则表示第k个样本的标签值相对于第i个输出单元的输出之间的误差;fitness
l
表示第l个个体的第一适应度值,l=1,2,
…
,popnum;fitness
max
、fitness
min
分别表示当前种群中最大第一适应度值和最小第一适应度值。
[0037]
优选的,所述s35具体包括:
[0038]
定义所述交叉概率为pc,构建一条与所述父代染色体有效长度相同的交叉选择个
体x
rs
,所述交叉选择个体x
rs
的各基因位随机取值0或1,当取基因位x
rsc
为0时,所述父代染色体不发生交叉;
[0039]
当取基因位x
rsc
为1时,父代染色体xr、xs发生交叉,且选定的交叉位为c,对应的交叉基因为分别为x
rc
和x
sc
,交叉后对应的基因分别为x
rc
′
和x
sc
′
;
[0040]
(1)若个体xr优于个体xs,即fitness
′r》fitnesss
′s;
[0041][0042]
x
sc
′
=x
sc
+d*(x
rc-x
sc
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5)
[0043][0044]
(2)若个体xr不优于个体xs,即fitness
′r≤fitness
′s;
[0045][0046][0047]
其中,0《d《1为常数;rand1表示(0,1)之间的随机数;t表示进化代数;t表示最大进化代数;mc、nc为表示约束条件中任意个体的基因xc取值范围的上限和下限;
[0048]
将两条所述父代染色体执行上述交叉操作获取对应的子代染色体。
[0049]
优选的,所述s36具体包括:
[0050]
定义所述变异概率为pm,x
je
表示父代中第j个个体中第e个基因,lenchrom为其有效长度,x
je
′
表示子代中第j个个体中第e个基因,1≤j≤popnum,1≤e≤lenchrom;
[0051][0052]
其中,rand2表示(0,1)之间的随机数,当rand2《pm表示实际发生变异,me、ne为表示约束条件中任意个体的基因xe取值范围的上限和下限。
[0053]
一种基于iga-bp神经网络的土壤调理时间序列预测系统,包括:
[0054]
预处理模块,用于获取并预处理与待预测土壤养分相关的土壤墒情数据;
[0055]
构建模块,用于构建bp神经网络;
[0056]
优化模块,用于采用iga算法确定所述bp神经网络的权值和阈值,并作为最优权值和阈值;
[0057]
第一获取模块,用于根据所述最优权值和阈值训练所述bp神经网络,获取iga-bp神经网络模型;
[0058]
预测模块,用于将所述土壤墒情数据输入所述iga-bp神经网络模型中,获取所述待预测土壤养分的预测结果;
[0059]
第二获取模块,用于根据各项所述待预测土壤养分的预测结果,作物生长特征以
及土壤养分等级评级体系,获取最佳土壤调理时间序列。
[0060]
一种存储介质,其存储有基于iga-bp神经网络的土壤调理时间序列预测的计算机程序,其中,所述计算机程序使得计算机执行如上所述的土壤调理时间序列预测方法。
[0061]
一种电子设备,包括:
[0062]
一个或多个处理器;
[0063]
存储器;以及
[0064]
一个或多个程序,其中所述一个或多个程序被存储在所述存储器中,并且被配置成由所述一个或多个处理器执行,所述程序包括用于执行如上所述的土壤调理时间序列预测方法。
[0065]
(三)有益效果
[0066]
本发明提供了一种基于iga-bp神经网络的土壤调理时间序列预测方法、系统、存储介质和电子设备。与现有技术相比,具备以下有益效果:
[0067]
本发明采用iga算法确定bp神经网络的权值和阈值,并作为最优权值和阈值;根据最优权值和阈值训练bp神经网络,获取iga-bp神经网络模型;将土壤墒情数据输入iga-bp神经网络模型中,获取待预测土壤养分的预测结果;通过选定不同目标土壤成分,预测得出未来一段时间该区域的具体土壤成分演变规律,同时结合具体作物生长特征和当地土壤养分等级评级体系双向匹配出土壤调理时间序列,最终确定最佳土壤调理所需养分。
附图说明
[0068]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0069]
图1本发明实施例提供的一种基于iga-bp神经网络的土壤调理时间序列预测方法的流程示意图;
[0070]
图2为本发明实施例提供的另一种基于iga-bp神经网络的土壤调理时间序列预测方法的流程示意图;
[0071]
图3为本发明实施例提供的一种iga编码方案;
[0072]
图4为本发明实施例提供的一种多点交叉示意图;
[0073]
图5为本发明实施例提供的采用iga算法确定bp神经网络的权值和阈值的结果示意图;
[0074]
图6为本发明实施例提供的基于最优权值和阈值训练bp神经网络的结果示意图;
[0075]
图7为本发明实施例提供的iga-bp神经网络模型与一般bp神经网络模型的效果对比图;
[0076]
图8为本发明实施例提供的另一种基于iga-bp神经网络的土壤调理时间序列预测系统的结构框图。
具体实施方式
[0077]
为使本发明实施例的目的、技术方案和优点更加清楚,对本发明实施例中的技术
方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0078]
本技术实施例通过提供一种基于iga-bp神经网络的土壤调理时间序列预测方法、系统、存储介质和电子设备,解决了土壤调理时间序列预测结果不准确的技术问题。
[0079]
本技术实施例中的技术方案为解决上述技术问题,总体思路如下:
[0080]
本发明实施例采用iga算法确定bp神经网络的权值和阈值,并作为最优权值和阈值;根据最优权值和阈值训练bp神经网络,获取iga-bp神经网络模型;将土壤墒情数据输入iga-bp神经网络模型中,获取待预测土壤养分的预测结果;通过选定不同目标土壤成分,预测得出未来一段时间该区域的具体土壤成分演变规律,同时结合具体作物生长特征和当地土壤养分等级评级体系双向匹配出土壤调理时间序列,最终确定最佳土壤调理所需养分。
[0081]
为了更好的理解上述技术方案,下面将结合说明书附图以及具体的实施方式对上述技术方案进行详细的说明。
[0082]
实施例:
[0083]
第一方面,如图1所示,本发明实施例提供了一种基于iga-bp神经网络的土壤调理时间序列预测方法,包括:
[0084]
s1、获取并预处理与待预测土壤养分相关的土壤墒情数据;
[0085]
s2、构建bp神经网络;
[0086]
s3、采用iga算法确定所述bp神经网络的权值和阈值,并作为最优权值和阈值;
[0087]
s4、根据所述最优权值和阈值训练所述bp神经网络,获取iga-bp神经网络模型;
[0088]
s5、将所述土壤墒情数据输入所述iga-bp神经网络模型中,获取所述待预测土壤养分的预测结果;
[0089]
s6、根据各项所述待预测土壤养分的预测结果,作物生长特征以及土壤养分等级评级体系,获取最佳土壤调理时间序列。
[0090]
本发明实施例通过选定不同目标土壤成分,预测得出未来一段时间该区域的具体土壤成分演变规律,同时结合具体作物生长特征和当地土壤养分等级评级体系双向匹配出土壤调理时间序列,最终确定最佳土壤调理所需养分。
[0091]
下面将对上述方案的各个步骤展开具体介绍:
[0092]
s1、获取并预处理与待预测土壤养分相关的土壤墒情数据。
[0093]
面对海量的土壤养分数据,结合作物目前生长发育现状选定特定养分作为输出参数,借助相关性检验选定与输出参数存在强相关的土壤成分作为模型的输入参数,即所述待预测土壤养分相关的土壤墒情数据,且所述待预测土壤养分包括有机质、钙、镁或者硫元素等。
[0094]
由于数据单位存在量级差异,例如全氮、有机质的单位为g/kg,而有效磷、速效钾等单位为mg/kg,为了消除数量级差异且为了有效提高梯度下降法求解最优解的速度,将所述土壤墒情数据进行min-max规范化预处理。
[0095]
s2、构建bp神经网络,具体包括:
[0096]
首先需要明确的是,由kolmogarav定理知,在合理的结构和恰当的权值条件下,3层bp网络能够以任意精度逼近有界非线性函数。因此,本发明实施例提出的iga-bp神经网
络模型选定3层网络结构,即输入层、隐含层和输出层,均采用1层网络结果。
[0097]
将所述与待预测土壤养分相关的土壤墒情数据作为输入参数;将所述待预测土壤养分作为输出参数,确定所述bp神经网络的输入层节点数和输出层节点数。
[0098]
根据所述输入层节点数和输出层节点数,确定所述bp神经网络的隐含层节点数:
[0099][0100]
其中,hl为隐含层节点数;il为输入层节点数;ol为输出层节点数;a为0~10之间的任意常数。因此,hl由输入、输出参数的数量可确定,输入层和输出层节点数分别为il与ol。利用上述经验公式确定隐含层节点数的取值范围后,通过不断的训练、对比和选择,最终确定隐含层节点数。
[0101]
初始化所述bp神经网络的隐含层阈值、输出层阈值、隐含层到输入层和输出层的连接权值。
[0102]
s3、采用iga算法确定所述bp神经网络的权值和阈值,并作为最优权值和阈值,如图2所示,具体包括:
[0103]
s31、根据多组所述bp神经网络的隐含层阈值、输出层阈值、隐含层到输入层和输出层的连接权值,采用实数编码获取初始种群。
[0104]
采用实数编码的方式优化bp神经网络的权值和阈值,即将一个实数直接作为一个染色体的一个基因位,这样使得染色体的长度大大缩短,这不仅免去了来回编码解码的繁琐,更使得遗传操作简化。将bp神经网络参数进行混合编码就可以得到iga编码方案,如图3所示:
[0105]
首先是输出层神经元的阈值bi,然后是隐含层神经元的阈值bi以及与输入层输出层神经元的连接权值wi。其中,隐含层神经元的阈值和连接权值共有(1+si+so)*sh个。
[0106]
因此,iga方案中个体的有效长度lenchrom=so+(1+si+so)*sh。在遗传算法优化神经网络的初始权值和阈值初始化过程中,每个个体均为一个实数串,由输出层神经元的阈值bi,隐含层神经元的阈值bi以及与输入层输出层神经元的连接权值wi三部分组成,每个权值和阈值均采用实数编码,将所有权值和阈值的编码连接起来即为一个个体的编码。将bp网络各个待优化的参数按照图3所示的编码方式填入到个体编码的相应位置中;解码时,根据对应的位置取出相应的权值和阈值等参数即可。这种实数编码方式将隐含层节点与连接权值相关联在一定程度上提高了算法的收敛速度,且相比于传统的二进制编码有效降低了计算量,减少量化误差。
[0107]
s32、确定适应度函数,计算当前种群中所有个体的适应度值。
[0108]
所述s32中适应度函数为相对适应度函数,通过第一适应度函数确定;
[0109]
所述第一适应度函数:
[0110][0111][0112]
所述相对适应度函数:
[0113]
[0114]
其中,e表示每个样本对应当前种群中每个个体,基于所述bp神经网络的学习误差;m表示包括所述待预测土壤养分及其相关的土壤墒情数据的训练样本容量;ol表示所述输出节点数;则表示第k个样本的标签值相对于第i个输出单元的输出之间的误差;fitness
l
表示第l个个体的第一适应度值,l=1,2,
…
,popnum;fitness
max
、fitness
min
分别表示当前种群中最大第一适应度值和最小第一适应度值。
[0115]
s33、判断是否满足迭代终止条件,若是,转入s37;否则,转入s34。
[0116]
具体的,计算当前群体中每个个体的学习误差及其相对适应度值,找出最优适应值的个体,若小于事先指定的最小数值,终止计算;否则再次迭代,直到满足条件为止,若达不到该条件,则以指定的遗传代数t为终止计算准则。
[0117]
s34、采用排序选择方法从当前种群中随机选择父代染色体;具体的根据每个个体的相对适应度值的大小,按照适应度比例计算个体的选择概率,适应度越大说明总体误差越小,则选择概率越大。
[0118]
s35、按照预设的交叉概率,结合多点交叉算子,将两条所述父代染色体执行交叉操作获取对应的子代染色体,所述多点交叉算子通过结合线性交叉与凸交叉构建。
[0119]
适用于实数编码遗传算法的交叉算子主要有算术交叉算子和离散交叉算子,但使用离散交叉算子产生的子代个体变化范围大,容易破坏个体的优良模式,而算术交叉算子破坏个体优良模式的几率较小,而且操作较简单,因此,选择采用算数交叉算子,但算数交叉算子的交叉结果具有一定的随机性,减缓了遗传算法的搜索速度。
[0120]
线性交叉和凸交叉是常用的算数交叉方式,线性交叉存在超出取值范围的可能,而而凸交叉产生的后代位于双亲之间而保持有效。
[0121]
为了实现优良的交叉结果,即快速而又能保证交叉结果符合约束条件,则将线性交叉与凸交叉结合在一起构建出新型多点交叉算子。本发明实施例结合线性交叉和凸交叉构造出新型多点交叉算子,不仅增大了遗传算法的搜索速度还能在很大程度上有效避免局部收敛或早熟的现象,并且还能保证子代位于解空间。
[0122]
所述s35具体包括:
[0123]
定义所述交叉概率为pc,如图4所示,构建一条与所述父代染色体有效长度相同的交叉选择个体x
rs
,所述交叉选择个体x
rs
的各基因位随机取值0或1,当取基因位x
rsc
为0时,所述父代染色体不发生交叉;
[0124]
当取基因位x
rsc
为1时,父代染色体xr、xs发生交叉,且选定的交叉位为c,对应的交叉基因为分别为x
rc
和x
sc
,且{x
rc
,x
sc
|x
rc
,x
sc
∈[nc,mc]},交叉后对应的基因分别为x
rc
′
和x
sc
′
;
[0125]
(1)若个体xr优于个体xs,即fitness
′r》fitness
′s;
[0126][0127]
x
sc
′
=x
sc
+d*(x
rc-x
sc
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)
[0128][0129]
(2)若个体xr不优于个体xs,即fintess
′r≤fitness
′s;
[0130][0131][0132]
其中,0《d《1为常数,d=0.5;rand1表示(0,1)之间的随机数;t表示进化代数;t表示最大进化代数;mc、nc为表示约束条件中任意个体的基因xc取值范围的上限和下限;
[0133]
将两条所述父代染色体执行上述交叉操作获取对应的子代染色体。
[0134]
s36、按照预设的变异概率,结合变异算子,将两条所述子代染色体执行变异操作,更新当前种群后转入s32,具体包括:
[0135]
定义所述变异概率为pm,x
je
表示父代中第j个个体中第e个基因,lenchrom为其有效长度,x
je
′
表示子代中第j个个体中第e个基因,1≤j≤popnum,1≤e≤lenchrom;
[0136][0137]
其中,rand2表示(0,1)之间的随机数,当rand2《pm表示实际发生变异,me、ne为表示约束条件中任意个体的基因xe取值范围的上限和下限。
[0138]
采用上述变异算子,种群中的个体依概率发生变异,变异范围可控,且个体的每一位都可能发生变异,增加了子代个体的多样性。
[0139]
s37、从当前种群中选择最优个体,将所述最优个体对应的权值和阈值作为所述最优权值和阈值。
[0140]
s4、根据所述最优权值和阈值训练所述bp神经网络,获取iga-bp神经网络模型。
[0141]
通过iga优化bp网络的权值与阈值来建立iga-bp神经网络模型,可克服bp网络收敛速度慢和易陷入局部极值等缺点,并发挥iga的全局搜索能力。
[0142]
s5、将所述土壤墒情数据输入所述iga-bp神经网络模型中,获取所述待预测土壤养分的预测结果。
[0143]
s6、根据各项所述待预测土壤养分的预测结果,作物生长特征以及土壤养分等级评级体系,获取最佳土壤调理时间序列。
[0144]
本发明实施例基于不同目标所述待预测土壤养分通过时间序列趋势预测出未来一段时间该区域的具体土壤成分演变规律,同时结合具体作物生长特征和当地土壤养分等级评级体系设计出双向匹配的土壤调理模式。
[0145]
此外,为了更清楚的解释上述技术方案,本发明实施例还提供一个具体的实施例:
[0146]
合肥长丰地区某种植大户拥有50亩草莓种植区,经过常年累积已形成长丰草莓全生长周期土壤养分历史演变数据集。今年为了拓展种植区域,实现增产增收,拟采用本发明
实施例提供的iga-bp神经网络模型对产区的另外一块草莓种植地实施改良实现土壤调理的时间序列预测。
[0147]
草莓的生长过程划分为开始生长期、开花和结果期、旺盛生长期和花芽分化期,分别获取不同时期对应的土壤墒情数据。选取对草莓果实影响较大的时期,即每年11月份左右草莓的生长期作为主要研究阶段,其他生长阶段可同理预测出草莓土壤墒情。土壤有机质作为草莓生长发育所需养分的主要来源,含有草莓生长发育所需要的各种营养元素,对于促进草莓的生长发育、改良土壤结构、提高土壤的保水保肥能力均具有重要作用,因此首先将土壤有机质(som,soil organic matter)作为预测对象。
[0148]
获取长丰草莓2000-2020年在该地区的土壤墒情数据,对其进行检验识别可知,该时序服从13阶自回归模型ar(13),由此时序模型确定的时间序列bp神经网络预测模型输入层神经元个数为13。将该区域草莓生长期土壤中全氮(g/kg)、有效磷(mg/kg)、速效钾(mg/kg)、有效铜(mg/kg)、有效锌(mg/kg)、有效铁(mg/kg)、有效锰(mg/kg)、有效硼(mg/kg)、有效钼(mg/kg)、有效硫(mg/kg)、有效硅(mg/kg)、温度(℃)、降雨量(mm)等拟作为输入层参数,将有机质(g/kg)作为输出层参数,计算各个输入变量与输出变量之间的相关关系,最终得出13个强相关因素作为最终网络的输入层各神经元。
[0149]
初始化bp神经网络拓扑结构;将预先获取到的二十组数据中的十六组用于训练网络,其余四组用于验证训练网络的误差。
[0150]
由于数据单位存在量级差异,如全氮、有机质的单位为g/kg,而有效磷、速效钾等单位为mg/kg,为了消除数量级差异且为了有效提高梯度下降法求解最优解的速度,将数据min-max规范化处理:
[0151][0152]
提取bp神经网络基本信息。借助前文所述经验公式采用试凑法不断调整隐含层hiddennum的个数,最终发现当hiddennum=9时,网络较好。由此得出bp神经网络的输入层(inputnum)、隐藏层、输出层(outputnum)节点数分别为13、9、1。隐藏层激活函数为logsig,输出层激活函数为tansig,训练函数为trainlm,期望误差为均方误差函数mse。
[0153]
则改进后遗传算法(iga)的染色体编码长度lenchrom为
[0154]
lenchrom=13
×
9+9+9
×
1+1=136
ꢀꢀꢀꢀꢀ
(12)
[0155]
根据改进后遗传算法(iga)进行的最优权值和阈值的训练。在matlab环境下进行程序设计,采用的实数编码码串长度为136,将种群的初始化数目popnum设定为50,进化次数t设定为200次,精度为0.01。选择操作使用排序选择方法;交叉运算使用上述将线性交叉与凸交叉结合在一起构建出的新型多点交叉算子;变异运算使用上述变异算子。交叉概率pc=0.1,变异概率pm=0.08,输入训练样本数据,对网络进行训练,算法经过142代后最好的适应度与平均适应度相同,达到精度,如图5所示。
[0156]
此时,得到各权值及阈值,如表1所示,输入层与隐含层的连接权值矩阵w
13
×9为:
[0157]
表1
[0158][0159][0160]
隐含层与输出层之间的连接权值矩阵w9×1′
为:
[0161]
[-0.7217 0.3002 0.7006
ꢀ‑
0.6084
ꢀ‑
0.9595 1.4529
ꢀ‑
0.1636
ꢀ‑
1.5121 0.6445]
[0162]
隐含层神经元的阈值矩阵b9×1′
为:
[0163]
[-0.9939
ꢀ‑
1.1896 1.1738
ꢀ‑
0.8124 1.9539
ꢀ‑
0.3322 0.8916 1.8106 0.1242]
[0164]
输出神经元的阈值为b1×1′
=[-0.9601]。
[0165]
iga-bp神经网络模型训练,将优化过的初始权值及阈值代入bp神经网络,设定循环次数为500次,训练速度为0.01,网络目标误差为0.00001。经过11次训练后,网络误差达到设定的精度,如图6所示。
[0166]
网络误差判断。将2017-2020年的氮磷钾等数据作为网络的输入值,对2017-2020年该区域的土壤墒情数据进行归一化处理,将处理的结果导入训练完成的iga-bp神经网络模型中。
[0167]
其次,采用一般的bp神经网络对同一地区的土壤有机质进行预测,iga-bp神经网络与一般bp神经网络结果,如图7和表2所示。
[0168]
表2
[0169]
指标iga-bp神经网络一般bp神经网络平均绝对误差mea2.26963.3629均方误差mse7.828416.379均方根误差rmse2.79794.0471
[0170]
从上表可看出经过优化后的神经网络精度更高,并由此预测出该区域2021年有机
质含量约为22.54g/kg。
[0171]
在土壤调理中,钙(cao)、镁(mgo)和硫(s)同样发挥着巨大的作用,钙是细胞壁果胶质和染色体的结构成分,不仅与磷脂分子形成钙盐,维持膜的结构和功能,还起到调节介质的生理平衡的作用;而硫不仅参与氧化还原反应还是蛋白质和酶的组成成分。
[0172]
因此,本发明实施例还借助上述iga-bp神经网络预测模型分别对钙、镁、硫多个目标待预测养分进行时间序列预测,得出2021年该区域钙、镁、硫的含量约为387.69mg/kg、203.58mg/kg、31.64mg/kg。
[0173]
根据各项所述待预测土壤养分的预测结果,作物生长特征以及土壤养分等级评级体系,获取最佳土壤调理时间序列。
[0174]
具体的,根据有机质、钙、镁或者硫的预测结果,以及安徽省耕地土壤养分等级划分标准可以发现该土壤中有机质、钙、镁和硫养分等级分别呈现为中等、稀缺、中等、丰富。
[0175]
考虑到长丰草莓生长在弱酸性土壤中最适宜,因此在进行土壤调理过程中调整ph(范围约为5.5-6.5),使得该区域草莓生长环境在弱酸性范围内,并添加适量的有机质(7.64g/kg)和镁(96.42mg/kg)以及多量的钙(812.31mg/kg)实现土壤改良,促进作物的生长发育。
[0176]
第二方面,如图8所示,本发明实施例提供了一种基于iga-bp神经网络的土壤调理时间序列预测系统,包括:
[0177]
预处理模块,用于获取并预处理与待预测土壤养分相关的土壤墒情数据;
[0178]
构建模块,用于构建bp神经网络;
[0179]
优化模块,用于采用iga算法确定所述bp神经网络的权值和阈值,并作为最优权值和阈值;
[0180]
第一获取模块,用于根据所述最优权值和阈值训练所述bp神经网络,获取iga-bp神经网络模型;
[0181]
预测模块,用于将所述土壤墒情数据输入所述iga-bp神经网络模型中,获取所述待预测土壤养分的预测结果;
[0182]
第二获取模块,用于根据各项所述待预测土壤养分的预测结果,作物生长特征以及土壤养分等级评级体系,获取最佳土壤调理时间序列。
[0183]
第三方面,本发明实施例提供了一种存储介质,其存储有基于iga-bp神经网络的土壤调理时间序列预测的计算机程序,其中,所述计算机程序使得计算机执行如上所述的土壤调理时间序列预测方法。
[0184]
第四方面,本发明实施例提供了一种电子设备,包括:
[0185]
一个或多个处理器;
[0186]
存储器;以及
[0187]
一个或多个程序,其中所述一个或多个程序被存储在所述存储器中,并且被配置成由所述一个或多个处理器执行,所述程序包括用于执行如上所述的土壤调理时间序列预测方法。
[0188]
可理解的是,本发明实施例提供的基于iga-bp神经网络的土壤调理时间序列预测系统、存储介质和电子设备与本发明实施例提供的基于iga-bp神经网络的土壤调理时间序列预测方法相对应,其有关内容的解释、举例和有益效果等部分可以参考基于iga-bp神经
网络的土壤调理时间序列预测方法中的相应部分,此处不再赘述。
[0189]
综上所述,与现有技术相比,具备以下有益效果:
[0190]
1、本发明实施例采用iga算法确定bp神经网络的权值和阈值,并作为最优权值和阈值;根据最优权值和阈值训练bp神经网络,获取iga-bp神经网络模型;将土壤墒情数据输入iga-bp神经网络模型中,获取待预测土壤养分的预测结果;通过选定不同目标土壤成分,预测得出未来一段时间该区域的具体土壤成分演变规律,同时结合具体作物生长特征和当地土壤养分等级评级体系双向匹配出土壤调理时间序列,最终确定最佳土壤调理所需养分。
[0191]
2、本发明设计的遗传算法编码方式由输出层神经元的阈值,隐含层神经元的阈值以及与输入层输出层神经元的连接权值三部分组成,每个权值和阈值均采用实数编码,这种实数编码方式将隐含层节点与连接权值相关联在一定程度上提高了算法的收敛速度,且相比于传统的二进制编码有效降低了计算量,减少量化误差。
[0192]
3、本发明实施例为了实现优良的交叉结果,即快速而又能保证交叉结果符合约束条件,则将线性交叉与凸交叉结合在一起构建出新型多点交叉算子。本发明实施例结合线性交叉和凸交叉构造出新型多点交叉算子,不仅增大了遗传算法的搜索速度还能在很大程度上有效避免局部收敛或早熟的现象,并且还能保证子代位于解空间。
[0193]
4、本发明实施例采用上述变异算子,种群中的个体依概率发生变异,变异范围可控,且个体的每一位都可能发生变异,增加了子代个体的多样性。
[0194]
5、本发明实施例基于不同目标所述待预测土壤养分通过时间序列趋势预测出未来一段时间该区域的具体土壤成分演变规律,同时结合具体作物生长特征和当地土壤养分等级评级体系设计出双向匹配的土壤调理模式。
[0195]
需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个
……”
限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
[0196]
以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1