一种疑似套取信息客户识别方法、系统、设备及介质与流程
1.本发明涉及电力行业的数据分析技术,特别是一种疑似套取信息客户识别方法、系统、设备及介质。
背景技术:
2.国家电网客户服务中心向用电客户通过电话和网络提供业扩报装、电力抢修,提供资费缴纳等与电力供应有关的技术开发、咨询、服务,给人们的工作、生活带来极大便利。同时,客服中心自身也承担着套取客户信息的困扰。因此,根据疑似套取客户行为特征对新客户进行识别,提高疑似套取信息客户识别准确性,对公司客服工作人员来说显得尤为重要。
3.聚类算法是特征提取常用的方法,其中均值漂移(mean shift)相比较与常见的k-means聚类算法而言,有着计算简单、快速收敛、不用人工确定k值等优点,是一种更快速,效率更高的聚类算法模型;孤立森林(isolationforest)算法针对高维海量数据在处理异常值的场景下,往往有着较好的表现。局部异常因子(lof)算法是一种基于密度模型的检验异常值算法,以局部密度的大小作为样本相对于总体数据异常程度的评估依据,是一种无监督的离群监测方法。
技术实现要素:
4.发明目的:本发明的目的是提供一种精度较高、适应性较强的疑似套取信息客户识别方法、系统、设备及介质。
5.技术方案:本发明所述的一种疑似套取信息客户识别方法,包括以下步骤:
6.(1)确定建模时间窗口,获取用户95598交互行为数据、通话语音转文本数据和客服工单数据,将数据处理为用户行为序列数据;
7.(1.1)将某一历史时间段确定为建模时间窗口,确定特征提取的训练集合;
8.(1.2)将原始数据处理为用户行为序列数据,公式为:
9.{(x1,y1),(x2,y2),...,(xn,yn)}
10.其中,x为用户;y表示行为;下角标数字表示行为顺序。
11.(2)利用meanshift算法、isolationforest算法、lof算法对用户行为进行聚类分析,根据聚类结果提取出疑似特殊套取信息客户行为特征的聚类组;
12.(2.1)均值漂移(meanshift)算法
13.mean shift相比较与常见的k-means聚类算法而言,有着计算简单、快速收敛、不用人工确定k值等优点,是一种更快速,效率更高的聚类算法模型。
14.mean shift向量定义为:给定d维空间rd中的n个样本点,对于其中一个样本x1,其mean shift向量为:
15.16.其中sr是一个半径为r的高维球状区域,i=1,2,...,n。
17.mean shift算法是从起始点开始,基准点到达样本特征点密度中心的一个过程。mean shift算法本质上是利用svm支持向量机的相关性质原理,通过对样本空间中最密集的区域样本点进行反复迭代,来得到聚类结果。
18.(2.2)孤立森林(isolationforest)算法
19.孤立森林算法是通过将各个维度数据构建成随机二叉树系列,然后通过不断的随机取值将数据无限往下划分,直到无法继续分支或二叉树达到了设定高度为止。由于异常值占比较小,即在随机二叉树中会被很快分到叶子节点中,因此通过计算根节点到各个叶子节点的距离长度,即可作为是否异常的判别量。
20.随机森林算法即在随机二叉树的基础上,通过大量生成随机二叉树构成随机森林,然后根据统计分析方法来判定异常值,达到聚类的效果。对于n个样本数据,其路径长度为h(n),其平均路径的长度c(n)为:
[0021][0022]
其中h(i)为谐波数,即等于ln(i)+欧拉常数。
[0023]
因为每个二叉树都是随机生成的,因此需要对路径长度进行统计学的归一化处理,设定s(x,n)为异常指数:
[0024][0025]
其中,e(h(x))为对给定值路径长度的期望,异常值数s即为该值对应路径的归一化。当s(x,n)趋近于1时,即这个点是异常点。当s(x,n)远小于0.5时,即这个点是正常点。
[0026]
(2.3)局部异常因子(lof)算法
[0027]
在局部异常因子算法中,异常因子lof定义为一个数据点周围的样本点所处位置的平均密度与该数据点所在位置的密度的比值。比值远大于1则代表该点所在位置的密度远小于周围点所在位置的密度,则认为该点属于异常点。其计算公式如下:
[0028][0029]
其中,点p的局部可达密度表示为:
[0030][0031]
o为点p周围一点,distk(p,o)表示为点p至点o的距离。通过计算样本点lof值的大小,与1进行比较,可以判定该样本点是否为特殊异常值。
[0032]
(3)基于相似系数计算公式对聚类组的行为特征与95598用户行为特征进行相似度计算,得到用户与疑似套取信息客户的行为序列相似度;
[0033]
(4)根据相似度判别用户是否是疑似套取信息客户,利用95598工单数据的文本数据挖掘技术验证疑似套取信息客户识别准确性,将使准确率最高的相似度设为阈值,对新用户进行识别。
[0034]
一种疑似套取信息客户识别系统,包括以下模块:
[0035]
用户行为序列数据处理模块:获取用户95598交互行为数据、通话语音转文本数据和客服工单数据,将数据处理为用户行为序列数据;
[0036]
特征提取模块:用于对用户行为进行聚类分析,得到疑似特殊套取信息客户行为特征的聚类组;利用meanshift算法、isolationforest算法、lof算法对用户行为进行聚类分析,根据聚类结果提取出疑似特殊套取信息客户行为特征的聚类组;
[0037]
相似度计算模块:基于相似系数计算公式对聚类组的行为特征与新95598用户行为特征进行相似度计算,得到新用户与疑似套取信息客户的行为序列相似度;
[0038]
疑似套取信息客户识别模块,根据相似度判别用户是否是疑似套取信息客户。
[0039]
一种计算机存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现上述的一种疑似套取信息客户识别方法。
[0040]
一种计算机设备,包括储存器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述的一种疑似套取信息客户识别方法。
[0041]
有益效果:与现有技术相比,本发明具有如下优点:1、将电网客服中心的原始95598交互行为数据、通话语音转文本数据和客服工单数据处理为用户行为序列数据,在缺少标注的情况下,采用无监督进行特征提取,基于提取的特征进行疑似套取信息客户识别,得到的疑似套取信息客户识别模型的识别准确性较高、普适性较强,和局限于行为特征分析,或者局限于客户挖掘研究方法不同,准确性、完整性、普适性均有提高;2、本发明能够有效提高客服中心的工作效率,保护客户的隐私。
附图说明
[0042]
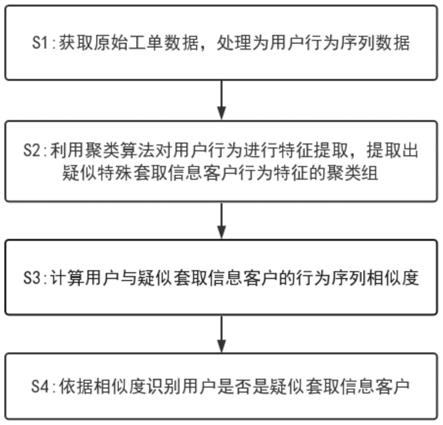
图1为一种疑似套取信息客户识别方法流程图。
具体实施方式
[0043]
下面结合附图对本发明的技术方案作进一步说明。
[0044]
如图1所示,一种疑似套取信息客户识别方法,包括以下步骤:
[0045]
(1)确定建模时间窗口,获取用户95598交互行为数据、通话语音转文本数据和客服工单数据,将数据处理为用户行为序列数据;
[0046]
本步骤首先将某一历史时间段确定为建模时间窗口,确定特征提取的训练集合。本实施方式中,选取2020年7月19日到2021年7月19日期间的原始95598交互行为数据、通话语音转文本数据和客服工单数据作为样本集。2020年7月19日到2021年3月18日为训练集,2021年3月19日到2021年7月19日为测试集。
[0047]
为了有效提取疑似套取信息客户的行为特征,将原始数据处理为用户行为序列数据,公式为:
[0048]
{(x1,y1),(x2,y2),...,(xn,yn)}
[0049]
其中,x为用户;y表示行为;下角标数字表示行为顺序。
[0050]
(2)本发明根据聚类算法对疑似套取信息客户进行特征提取,采用三种算法对用户行为序列数据进行聚类,选取聚类效果最佳的算法提取出疑似套取信息客户行为特征的聚类组。
[0051]
本实施方式中,按照一年的建模时间窗口对用户行为序列数据进行聚类分析,聚类分析有着不需要先验分布、不需要训练模型等优点,在本实施方式采用均值漂移算法、孤立森林算法和局部异常因子算法;
[0052]
(2.1)均值漂移(meanshift)算法
[0053]
mean shift相比较与常见的k-means聚类算法而言,有着计算简单、快速收敛、不用人工确定k值等优点,是一种更快速,效率更高的聚类算法模型。
[0054]
mean shift向量定义为:给定d维空间rd中的n个样本点,对于其中一个样本x1,其mean shift向量为:
[0055][0056]
其中sr是一个半径为r的高维球状区域,i=1,2,...,n。
[0057]
mean shift算法是从起始点开始,基准点到达样本特征点密度中心的一个过程。mean shift算法本质上是利用svm支持向量机的相关性质原理,通过对样本空间中最密集的区域样本点进行反复迭代,来得到聚类结果。
[0058]
(2.2)孤立森林(isolationforest)算法
[0059]
孤立森林算法是通过将各个维度数据构建成随机二叉树系列,然后通过不断的随机取值将数据无限往下划分,直到无法继续分支或二叉树达到了设定高度为止。由于异常值占比较小,即在随机二叉树中会被很快分到叶子节点中,因此通过计算根节点到各个叶子节点的距离长度,即可作为是否异常的判别量。
[0060]
随机森林算法即在随机二叉树的基础上,通过大量生成随机二叉树构成随机森林,然后根据统计分析方法来判定异常值,达到聚类的效果。对于n个样本数据,其路径长度为h(n),其平均路径的长度c(n)为:
[0061][0062]
其中h(i)为谐波数,即等于ln(i)+欧拉常数。
[0063]
因为每个二叉树都是随机生成的,因此需要对路径长度进行统计学的归一化处理,设定s(x,n)为异常指数:
[0064][0065]
其中,e(h(x))为对给定值路径长度的期望,异常值数s即为该值对应路径的归一化。当s(x,n)趋近于1时,即这个点是异常点。当s(x,n)远小于0.5时,即这个点是正常点。
[0066]
(2.3)局部异常因子(lof)算法
[0067]
在局部异常因子算法中,异常因子lof定义为一个数据点周围的样本点所处位置的平均密度与该数据点所在位置的密度的比值。比值远大于1则代表该点所在位置的密度远小于周围点所在位置的密度,则认为该点属于异常点。其计算公式如下:
[0068][0069]
其中,点p的局部可达密度表示为:
[0070][0071]
o为点p周围一点,distk(p,o)表示为点p至点o的距离。通过计算样本点lof值的大小,与1进行比较,可以判定该样本点是否为特殊异常值。
[0072]
(3)基于相似系数计算公式对聚类组的行为特征与95598用户行为特征进行相似度计算,得到用户与疑似套取信息客户的行为序列相似度;
[0073]
本实施方式中,通过计算相似系数cos(θ),来判定异常特征与新用户特征的相似度。其中ai为异常特征,bi为对应的新用户特征。计算相似系数的公式如下:
[0074][0075]
本发明采用无监督进行特征提取,基于提取的特征组计算相似度,以此进行疑似套取信息客户识别,得到的疑似套取信息客户识别模型的识别准确性较高、普适性较强。
[0076]
(4)根据相似度判别用户是否是疑似套取信息客户,利用95598工单数据的文本数据挖掘技术验证疑似套取信息客户识别准确性,将使准确率最高的相似度设为阈值,对新用户进行识别。
[0077]
本实施方式中,将工单文本挖掘结果作为验证模型识别准确性依据,通过对新用户是否为特殊异常客户的识别,与客服工单记录进行匹配,模型的识别效果如下:
[0078]
2021年3月19日到2021年7月19日模型共识别5386位疑似套取信息客户,客服工单记录本文挖掘结果显示共有4653位疑似套取信息客户,识别命中率约为86.4%,表示模型对95598疑似套取信息客户的识别效果较好。
[0079]
一种疑似套取信息客户识别系统,包括以下模块:
[0080]
用户行为序列数据处理模块:获取用户95598交互行为数据、通话语音转文本数据和客服工单数据,将数据处理为用户行为序列数据;
[0081]
特征提取模块:用于对用户行为进行聚类分析,得到疑似特殊套取信息客户行为特征的聚类组;利用meanshift算法、isolationforest算法、lof算法对用户行为进行聚类分析,根据聚类结果提取出疑似特殊套取信息客户行为特征的聚类组;
[0082]
相似度计算模块:基于相似系数计算公式对聚类组的行为特征与新95598用户行为特征进行相似度计算,得到新用户与疑似套取信息客户的行为序列相似度;
[0083]
疑似套取信息客户识别模块,根据相似度判别用户是否是疑似套取信息客户。
[0084]
一种计算机存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现上述的一种疑似套取信息客户识别方法。
[0085]
一种计算机设备,包括储存器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述的一种疑似套取信息客户识别方法。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1