一种基于值集分析的非结构化差异补丁分析方法与流程
1.本发明涉及补丁比对技术,尤其涉及一种基于值集分析的非结构化差异补丁分析方法。
背景技术:
2.1day漏洞用于指代那些已公开的漏洞,软件厂商通常不会公开1day漏洞的详细信息,而是通过安全补丁来对1day漏洞进行修复,但是当用户没有及时更新补丁时,1day漏洞的威胁将持续存在。补丁比对技术通过发现程序中的补丁能有效发现程序中的1day漏洞。结构化补丁比对技术最为当前最主流的补丁比对技术具有较好的效果,但仍然存在补丁漏报的问题。其中最主要的一类问题是无法发现非结构化差异补丁,例如在cgc测试集的124个程序中总共存在247个补丁,其中包含了24个非结构化差异补丁,占总数的9.72%。非结构化差异补丁对程序的影响是非结构化的,因此无法被结构化补丁比对技术捕获到。为了检测此类补丁,binhunt和ibinhunt在函数匹配的基础上对函数内的基本块进行符号执行以发现此类非结构化差异补丁,但该方法采用了重量级的符号执行技术,导致效率低下,例如对gzip程序进行补丁比对需要花费3个小时,对thttpd程序进行补丁比对需要6个小时。
技术实现要素:
3.本发明的目的在于针对现有技术的不足,提供了一种基于值集分析的非结构化差异补丁分析方法。
4.本发明的目的是通过以下技术方案来实现的:一种基于值集分析的非结构化差异补丁分析方法,包括如下步骤:
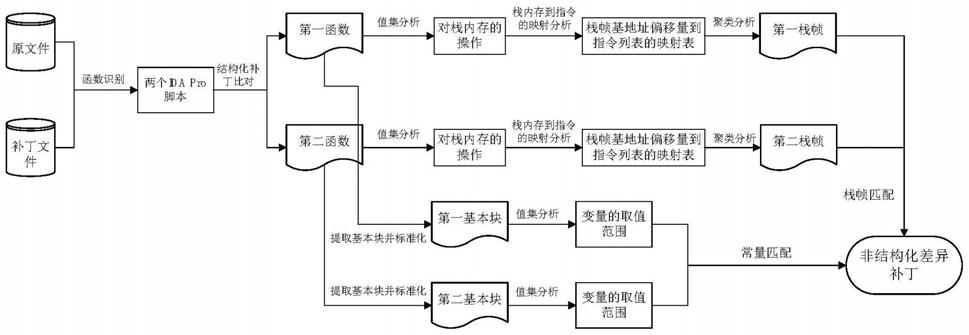
5.步骤一:对原文件以及补丁文件进行函数识别,识别函数起始地址和函数大小,生成两个ida pro脚本;
6.步骤二:对两个ida pro脚本利用结构化补丁比对技术获取匹配的函数对,所述匹配的函数对包括第一函数和第二函数,其中所述第一函数对应原文件中的函数,所述第二函数对应补丁文件中的函数;然后由所述第一函数提取第一基本块,由所述第二函数提取第二基本块;
7.步骤三:对步骤二提取的第一基本块和第二基本块进行标准化,由第一基本块得到标准化后的第一基本块对,由第二基本块得到标准化后的第二基本块对;
8.步骤四:对函数进行值集分析,提取所有对栈内存的操作,并将其表示为三元组[ins1,offset1,size1],其中ins1是对栈内存操作的指令地址,offset1为栈内存相对栈帧基地址的偏移量,offset1为负数,size1为对栈内存的读写字节数;同时利用值集分析在函数的每个标准化后的基本块处得到基本块中的所有变量的取值范围s;
[0009]
步骤五:通过对栈内存的操作进行栈内存到指令的映射分析,得到栈内存相对栈帧基地址的偏移量到指令列表的映射表:mem_ins_map:=offset
→
ins_list,其中mem_ins_map即为所述映射表,offset为栈内存相对栈帧基地址的偏移量,ins_list为所有对相
同偏移量的栈内存的操作的指令列表;然后对栈内存相对栈帧基地址的偏移量到指令列表的映射表进行聚类分析,即将具有相同指令列表的偏移量归为一个变量,由此得到一个新的映射表:stack_frame:=ins_list
→
variable,其中stack_frame为新的映射表,又记为栈帧,其中由第一函数得到第一栈帧,由第二函数得到第二栈帧,其中ins_list为所有对相同偏移量的栈内存操作的指令列表,变量为具有相同指令列表的偏移量的集合;
[0010]
步骤六:通过以下任一方法判断是否存在非结构化差异补丁:
[0011]
方法一:对步骤五得到的第一栈帧和第二栈帧利用栈帧匹配算法进行分析,并得到匹配的变量对,最后比较每对匹配变量的大小,如果存在一对变量的大小不相等,那么这两个函数的栈帧将不匹配,意味着原文件与补丁文件获取的匹配函数对中存在非结构化差异补丁;
[0012]
方法二:对第一函数和第二函数标准化后的第一基本块对和第二基本块对利用常量匹配算法进行分析,得到第一基本块对和第二基本块对中匹配的常量对,当找到匹配的常量对的值不相等时,意味着原文件与补丁文件获取的匹配函数对中存在非结构化差异补丁。
[0013]
进一步地,步骤三中所述标准化具体为:寻找基本块中的函数调用指令,如果基本块中存在函数调用指令且该指令并不是基本块中的最后一条指令,则以该函数调用指令为界限切割该基本块,得到两个新的基本块,其中一个基本块的最后一条指令即为该函数调用指令,然后对另一个基本块进行标准化,直到无法继续切割。
[0014]
进一步地,步骤五中所述栈内存到指令的映射分析具体为:枚举所有对栈内存的操作[ins1,offset1,size1],将ins1添加到mem_ins_map[offset1],mem_ins_map[offset1+1],
…
mem_ins_map[offset1+size
1-1]中,初始状态下mem_ins_map为空,同时在分析过程中记录栈内存相对栈帧基地址的偏移量的最小值,记为min_offset。
[0015]
进一步地,步骤五中所述聚类分析具体为:将栈内存相对栈帧基地址的偏移量从偏移量的最小值到0(不包含0)进行遍历,获取栈内存相对栈帧基地址的偏移量到指令列表的映射中对应的所有对偏移量为offset1的栈内存的操作的指令列表,改变所有对偏移量为offset1的栈内存的操作的指令列表到变量的映射中指令列表对应的变量范围使其在原来的基础上增加该offset的值;初始情况下,变量的范围为空。
[0016]
进一步地,步骤六中所述栈帧匹配算法具体为:遍历栈帧1和栈帧2中的所有元素,获取其中的指令列表和变量对,分别记为(ins_list1,variable1)和(ins_list2,variable2),其中(ins_list1,variable1)为栈帧1中的指令列表和变量对,(ins_list2,variable2)为栈帧2中的指令列表和变量对,如果ins_list1与ins_list2相等,则说明variable1与variable2是匹配的,否则就不匹配;
[0017]
进一步地,步骤六中所述常量匹配算法具体为:遍历函数中的每一个基本块,首先查看基本块的退出指令类型,当退出指令类型为函数调用指令或者是条件转移指令时,进行进一步分析,否则跳过对该基本块的分析;当退出指令类型为函数调用指令时,根据函数调用约定获取函数的所有参数,然后利用常量判断算法逐一判断参数是否是非指针类型的常量;当退出指令类型为条件转移指令时,对该基本块进行值集分析得到路径谓词,然后将路径谓词进行标准形式转化,得到路径谓词中的的常量;。
[0018]
进一步地,步骤六中所述常量判断算法具体为:根据前面的分析结果得到基本块
中的变量取值范围s,然后判断s是否等于0,如果等于0,说明该变量为常量,否则不是常量;如果为常量,则进一步判断该常量是否为指针类型,通过尝试获取内存中该地址的内容来进行判断,如果能成功获取到该常量对应的内存,则说明该常量为指针类型,否则为非指针类型的常量。
[0019]
进一步地,步骤六中所述标准形式转化具体为:为了将路径谓词转为标准形式,首先将路径谓词中的所有符号值移到左边,常量值移到右边;针对操作符,除了=和≠外,其它操作符都需要转化为≤;具体操作为,当操作符为》或者≥时,左右两边同时乘以-1,操作符将转化为《或者≤,然后针对《,将右边的常量值减去1,操作符将转为≤;最终路径谓词中右边的常量即为路径谓词中的常量。
[0020]
本发明的有益效果:利用值集分析技术来寻找非结构化差异补丁,以解决传统的结构化补丁比对技术无法发现非结构化差异补丁的问题。通过这种方法,使得改进后的补丁比对技术在cgc测试集上的漏报率从11.02%降到1.63%。同时利用这种方法,在真实的设备,netgear r6400路由器的http服务程序中成功找到了20个非结构化差异补丁,即能够找到新的1day漏洞,证明了该方法在实际应用场景下的有效性。
附图说明
[0021]
图1为一种基于值集分析的非结构差异补丁分析方法流程图。
具体实施方式
[0022]
下面根据附图和优选实施例详细描述本发明,本发明的目的和效果将变得更加明白,应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
[0023]
如图1所示,本发明的一种基于值集分析的非结构化差异补丁分析方法,包括如下步骤:
[0024]
步骤一:对原文件以及补丁文件进行函数识别,识别函数起始地址和函数大小,然后生成两个ida pro脚本,分别记为original.idb和patch.idb;
[0025]
其中原文件和补丁文件为二进制程序;
[0026]
作为其中一种实施方式,函数识别使用了nucleus提出的一种基于结构控制流图分析的函数识别技术。
[0027]
步骤二:对original.idb和patch.idb利用结构化补丁比对技术获取匹配的函数对,所述匹配的函数对包括第一函数和第二函数,其中所述第一函数对应原文件中的函数,所述第二函数对应补丁文件中的函数;然后由所述第一函数提取第一基本块,由所述第二函数提取第二基本块;
[0028]
作为其中一种实施方式,利用结构化补丁比对技术时使用了bindiff工具。
[0029]
步骤三:对步骤二提取的第一基本块和第二基本块进行标准化,由第一基本块得到标准化后的第一基本块对,由第二基本块得到标准化后的第二基本块对;
[0030]
所述标准化具体为:寻找基本块中的函数调用指令,如果基本块中存在函数调用指令且该指令并不是基本块中的最后一条指令,则以该函数调用指令为界限切割该基本块,得到两个新的基本块,其中一个基本块的最后一条指令即为该函数调用指令,然后对另一个基本块进行标准化,直到无法继续切割;
[0031]
标准化后的基本块除了最后一条指令不存在函数调用指令,适用于后续值集分析。
[0032]
步骤四:对函数进行值集分析,提取所有对栈内存的操作,并将其表示为三元组[ins1,offset1,size1],其中ins1是对栈内存操作的指令地址,offset1为栈内存相对栈帧基地址的偏移量,offset1为负数,size1为对栈内存的读写字节数;同时利用值集分析在函数的每个标准化后的基本块处得到基本块中的所有变量的取值范围s;
[0033]
步骤五:通过对栈内存的操作进行栈内存到指令的映射分析,得到栈内存相对栈帧基地址的偏移量到指令列表的映射表:mem_ins_map:=offset
→
ins_list,其中mem_ins_map即为所述映射表,offset为栈内存相对栈帧基地址的偏移量,ins_list为所有对相同偏移量的栈内存的操作的指令列表;然后对栈内存相对栈帧基地址的偏移量到指令列表的映射表(mem_ins_map)进行聚类分析,即将具有相同指令列表(ins_list)的偏移量(offset)归为一个变量(variable),由此得到一个新的映射表:stack_frame:=ins_list
→
variable,其中stack_frame为新的映射表,又记为栈帧,其中由第一函数得到第一栈帧,由第二函数得到第二栈帧,其中ins_list为所有对相同偏移量(offset)的栈内存操作的指令列表,变量(variable)为具有相同指令列表(ins_list)的偏移量的集合;
[0034]
所述栈内存到指令的映射分析具体为:枚举所有对栈内存的操作[ins1,offset1,size1],将ins1添加到mem_ins_map[offset1],mem_ins_map[offset1+1],
…
mem_ins_map[offset1+size
1-1]中,初始状态下mem_ins_map为空,同时在分析过程中记录栈内存相对栈帧基地址的偏移量的最小值,记为min_offset;
[0035]
所述聚类分析具体为:将栈内存相对栈帧基地址的偏移量(offset1)偏移量的最小值(min_offset)到0(不包含0)进行遍历,获取栈内存相对栈帧基地址的偏移量到指令列表的映射中对应的所有对偏移量为offset1的栈内存的操作的指令列表,改变所有对偏移量为offset1的栈内存的操作的指令列表到变量的映射中指令列表对应的变量范围使其在原来的基础上增加该offset的值;初始情况下,变量的范围为空。
[0036]
步骤六:通过以下任一方法判断是否存在非结构化差异补丁:
[0037]
方法一:对步骤五得到的第一栈帧和第二栈帧利用栈帧匹配算法进行分析,并得到匹配的变量对,最后比较每对匹配变量的大小,如果存在一对变量的大小不相等,那么这两个函数的栈帧不匹配,意味着原文件与补丁文件获取的匹配函数对中存在非结构化差异补丁;
[0038]
所述栈帧匹配算法具体为:遍历栈帧1和栈帧2中的所有元素,获取其中的指令列表和变量对,分别记为(ins_list1,variable1),(ins_list2,variable2),其中(ins_list1,variable1)为栈帧1中的指令列表和变量对,(ins_list2,variable2)为栈帧2中的指令列表和变量对,如果ins_list1与ins_list2相等,则说明variable1与variable2是匹配的,否则就不匹配;
[0039]
方法二:对第一函数和第二函数标准化后的第一基本块对和第二基本块对利用常量匹配算法进行分析,得到第一基本块对和第二基本块对中匹配的常量对,当找到匹配的常量对的值不相等时,意味着原文件与补丁文件获取的匹配函数对中存在非结构化差异补丁;
[0040]
所述常量匹配算法具体为:遍历函数中的每一个基本块,首先查看基本块的退出
指令类型,当退出指令类型为函数调用指令或者是条件转移指令时,进行进一步分析,否则跳过对该基本块的分析;当退出指令类型为函数调用指令时,根据函数调用约定获取函数的所有参数,然后利用常量判断算法逐一判断参数是否是非指针类型的常量;当退出指令类型为条件转移指令时,对该基本块进行值集分析得到路径谓词,然后将路径谓词进行标准形式转化,得到路径谓词中的的常量;
[0041]
所述常量判断算法具体为:根据前面的分析结果得到基本块中的变量取值范围s,然后判断s是否等于0,如果等于0,说明该变量为常量,否则不是常量;如果为常量,则进一步判断该常量是否为指针类型,通过尝试获取内存中该地址的内容来进行判断,如果能成功获取到该常量对应的内存,则说明该常量为指针类型,否则为非指针类型的常量;
[0042]
所述标准形式转化具体为:为了将路径谓词转为标准形式,首先将路径谓词中的所有符号值移到左边,常量值移到右边;针对操作符,除了=和≠外,其它操作符都需要转化为≤;具体操作为,当操作符为》或者≥时,左右两边同时乘以-1,操作符将转化为《或者≤,然后针对《,将右边的常量值减去1,操作符将转为≤;最终路径谓词中右边的常量即为路径谓词中的常量。
[0043]
下面将列举使用基于值集分析的非结构化差异补丁分析方法的原型工具enbindiff在cgc测试集上的效果,同时选择最先进的补丁比对工具bindiff,diaphora作为对照。最后将探究enbindiff在真实设备中发现非结构化差异补丁的能力。通过以上实验将对本发明进行进一步详细说明。
[0044]
cgc测试集中包含原程序和补丁程序,这些二进制程序在名为decree的定制操作系统中运行。该测试集中有131个服务,但其中5个服务涉及多个二进制程序之间的通信,因此仅考虑126个单二进制程序的服务。根据二进制程序名的前缀,这些二进制程序可以分为4类:cromu,kprca,nrfin和yan01。实验过程中发现在二进制文件nrfin_00026和nrfin_00032中包含大量非结构化差异补丁,例如nrfin_00026含有1004个补丁,其中1003个是bindiff发现不了的非结构化差异补丁,公平起见,这两个程序将不计入最终的测试结果中。最终的结果表明,在总共245个补丁中,bindiff能检测到218个,漏报27个,diaphora能检测到212个,漏报33个,而本发明的工具原型enbindiff能检测到241个,仅漏报4个。相比bindiff漏报率降低了9.39%,相比diaphora漏报率降低了11.84%。
[0045]
而在性能方面,针对每个程序,bindiff的平均时间开销为8.12秒,diaphora为16.46秒,而enbindiff为14.03秒,相比于bindiff而言,其增加的时间开销5.91秒在可接受范围内。
[0046]
同时,enbindiff能够在真实的设备中发现新的1day漏洞。实验中使用netgear r6400路由器的http服务程序作为测试集验证enbindiff在真实软件中发现1day漏洞的能力,具体为,将http服务程序的18个版本中每相邻的两个版本作为输入进行补丁检测,最终在17次比对中,有4次发现了非结构化差异补丁,共计20个非结构化差异补丁,通过分析确认,所有20个非结构化差异补丁都是对1day漏洞进行的修补。
[0047]
本领域普通技术人员可以理解,以上所述仅为发明的单个实例而已,并不用于限制发明,尽管参照前述实例对发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实例记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在发明的精神和原则之内,所做的修改、等同替换等均应包含在发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1