一种分布式动态可配置的爬虫平台及爬虫方法与流程
1.本发明属于互联网领域,涉及爬虫技术以及数据结构化清洗技术,具体为一种分布式动态可配置的爬虫平台及爬虫方法,用于从海量站点内定向抓取数据。
背景技术:
2.网络爬虫是一种按照一定的规则自动抓取网页内容的程序或者脚本,是搜索引擎的重要组成部分,通常包括传统爬虫和聚集爬虫。随着数据爆炸式增长,企业急需海量数据采集处理能力,面对海量站点,如何通过网络爬虫快速高效获取所需数据成为企业所关注问题。
3.目前,现有的爬虫平台存在一定的局限性,在特定的领域(例如全国政策数据、全国招投标数据、新闻数据等),用户只关注特定栏目的数据,爬虫引擎从海量数据中获得目标数据包含有大量用户不关心、不需要的数据,使得爬虫冗余度高、爬虫效率低。
技术实现要素:
4.本发明为了解决现有的爬虫平台不能快速高效的获取用户需要的数据,且数据中含有大量用户不使用的数据,同时也不能对爬虫任务执行结果进行反馈及预警的问题,设计了一种分布式动态可配置的爬虫平台及爬虫方法,其能够从海量站点内定向抓取数据,以快速高效的获取用户所需数据,也能够实时的对爬虫任务的执行过程进行反馈及预警,进一步提高爬虫结果的准确度。
5.实现发明目的的技术方案如下:
6.一方面,本发明公开了一种爬虫方法,采用分布式动态可配置爬虫平台从海量站点内定向抓取数据,爬虫方法包括:
7.用户输入爬虫需求,依据爬虫需求形成爬虫抓取规则,其中爬虫抓取规则的形成方法为:依据需求清单在分布式动态可配置爬虫平台上进行通用参数配置,通用参数至少包括规则名称、抓取页面网址、调度间隔的配置;通用参数配置完成后,打开指定页面插件,自动识别页面结构自动生成提取表达式,依据提取表达式生成相应爬虫抓取规则;若如果无法自动识别页面结构时,则经人工编写xpath及正则表达式,生成爬虫抓取规则;对爬虫抓取规则进行审核,审核通过后进入爬虫抓取规则发布流程;
8.解析爬虫抓取规则形成爬虫任务,解析爬虫调度配置形成爬虫任务调度;
9.根据爬虫任务对分布式动态可配置爬虫平台内多个爬虫子模块排序,选择排序最高的爬虫子模块作为最优爬虫运行节点;
10.启动最优爬虫运行节点并执行爬虫任务,分别抓取m个目标站点的n个指定页面,解析指定页面url并进行去重处理后加入待爬列队,直至m个目标站点中n个指定页面全部被抓取;
11.对待爬列队中指定页面的结构化数据进行相似度检测,去重处理以降低冗余度,形成并保存爬虫结果。
12.在本发明的一个实施例中,上述爬虫方法还包括:依据agent对爬虫任务的执行状态进行动态实时监测,并根据预警规则发送告警信息。
13.进一步的,上述预警规则为错误异常实时捕获分析自动过滤误报规则,其能智能识别页面改版问题并及时进行人工介入并修复规则。
14.在本发明的一个实施例中,上述步骤中,对待爬列队中指定页面的结构化数据进行相似度检测,去重处理以降低冗余度步骤,是根据抓取的结构化数据,依据simhash进行相似度检测以降低结构化数据的冗余度。
15.在本发明的一个实施例中,上述爬虫抓取规则包括待采集入口url、指定页面的请求方式、指定页面的抽取规则、爬虫结果模板。
16.第二方面,本发明还公开了一种分布式动态可配置爬虫平台,分布式动态可配置爬虫平台包括自动规则生成模块、爬虫调度模块、多个爬虫子模块、结构化数据解析模块、第一去重模块、第二去重模块、队列模块。
17.自动规则生成模块用于依据爬虫需求,无需写入代码即可自动生成爬虫抓取规则;
18.爬虫调度模块用于解析爬虫调度配置,形成爬虫任务调度,并依据爬虫任务对多个爬虫子模块排序;
19.爬虫子模块用于执行爬虫任务;
20.结构化数据解析模块用于对抓取的结构化数据进行解析;
21.第一去重模块用于采集并对各目标站点中n个指定页面的数据进行去重处理,并输出待爬列队;
22.第二去重模块用于对待爬列队中指定页面的数据进行相似度检测,进行去重处理后向队列模块输出爬虫结果;
23.队列模块用于以列队的形式展示最优爬虫运行节点执行爬虫任务后的爬虫结果。
24.进一步的,上述分布式动态可配置爬虫平台还包括预警模块,预警模块用于对爬虫任务的执行状态进行动态实时监测,并根据预警规则进行错误异常实时捕获分析并自动过滤误报后发送告警信息。
25.优选的,上述分布式动态可配置爬虫平台还包括无头浏览器模块,无头浏览器模块用于以解决部分页面加密需要渲染数据的问题。
26.优选的,上述分布式动态可配置爬虫平台还包括验证码模块,验证码模块用于解决部分站点需要输入验证码才可以访问的问题。
27.优选的,上述分布式动态可配置爬虫平台还包括代理ip模块,代理ip模块用于解决站点对ip请求限制的问题。
28.优选的,上述分布式动态可配置爬虫平台还包括附件转换模块,附件转换模块用于自动识别图片、pdf等格式的数据,并将其转换为html格式供解析器解析。
29.优选的,上述分布式动态可配置爬虫平台还包括存储模块,存储模块用于持久化存储爬虫结果的结构化后数据,且支持mysql、oracle、postgresql、mongodb等格式数据的存储。
30.优选的,上述分布式动态可配置爬虫平台还包括日志模块,日志模块用于实时收集各爬虫子模块的运行日志,实现毫秒级展示。
31.与现有技术相比,本发明的有益效果是:
32.1.本发明的爬虫方法及爬虫平台能够支持海量站点可配置可扩展的爬虫任务,通过分布式方式运行爬虫任务,具有高并发、高性能,高可用的优点,同时可以根据用户业务需求进行动态扩缩容;爬虫抓取规则通过点选配置、自动化生成,无需写代码即可实现将开发效率提升了10倍左右。通过对爬虫任务执行状态进行实时监控,能够发现并自动告警异常任务,在提升了爬取效率的同时降低了运维成本。
33.2.通过对分布式动态可配置爬虫平台采用模块化开发,可以实现分布式动态可配置爬虫平台的高内聚、低耦合性,其通过智能识别页面结构并自动生成抓取规则,工程师只需要审核并微调即可。传统方法中一个爬虫规则从开发到上线可能需要4小时,而本发明方法只需要20分钟左右即可完成开发上线。
附图说明
34.为了更清楚地说明本发明实施例技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍。显而易见地,下面描述中的附图仅仅是本发明为了更清楚地说明本发明实施例或现有技术中的技术方案,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
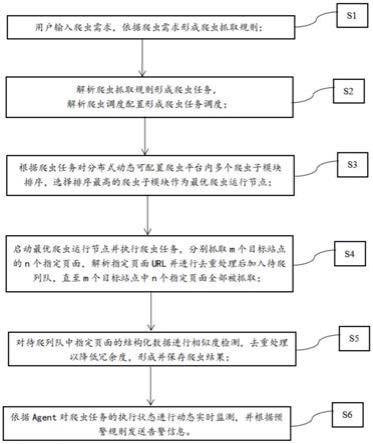
35.图1为具体实施方式中爬虫方法的流程图。
具体实施方式
36.下面结合具体实施例来进一步描述本发明,本发明的优点和特点将会随着描述而更为清楚。但这些实施例仅是范例性的,并不对本发明的范围构成任何限制。本领域技术人员应该理解的是,在不偏离本发明的精神和范围下可以对本发明技术方案的细节和形式进行修改或替换,但这些修改和替换均落入本发明的保护范围内。
37.在本实施例的描述中,需要理解的是,术语“中心”、“纵向”、“横向”、“上”、“下”、“前”、“后”、“左”、“右”、“竖直”、“水平”、“顶”、“底”、“内”、“外”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明创造和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明创造的限制。
38.此外,术语“第一”、“第二”、“第三”等仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”等的特征可以明示或者隐含地包括一个或者更多个该特征。在本发明创造的描述中,除非另有说明,“多个”的含义是两个或两个以上。
39.本实施例提供了一种分布式动态可配置爬虫平台,分布式动态可配置爬虫平台包括自动规则生成模块、爬虫调度模块、多个爬虫子模块、结构化数据解析模块、第一去重模块、第二去重模块、队列模块。
40.其中,自动规则生成模块用于依据爬虫需求,无需写入代码即可自动生成爬虫抓取规则;爬虫调度模块用于解析爬虫调度配置,形成爬虫任务调度,并依据爬虫任务对多个爬虫子模块排序;爬虫子模块用于执行爬虫任务;结构化数据解析模块用于对抓取的结构化数据进行解析,结构化数据解析模块内内置有包含文本前后截取、时间智能提取等30种
数据解析方法,且其可以通过自定义代码扩展;第一去重模块用于采集并对各目标站点中n个指定页面的数据进行去重处理,并输出待爬列队;第二去重模块用于对待爬列队中指定页面的数据进行相似度检测,进行去重处理后向队列模块输出爬虫结果,队列模块用于以列队的形式展示最优爬虫运行节点执行爬虫任务后的爬虫结果。
41.进一步的,上述分布式动态可配置爬虫平台还包括预警模块,预警模块用于对爬虫任务的执行状态进行动态实时监测,并根据预警规则进行错误异常实时捕获分析并自动过滤误报后发送告警信息。
42.具体的,预警规则的生成方法为:爬虫子模块实时将运行及抓取异常发送给远端队列统一收集;日志清洗程序解析并过滤无用日志;结构化日志数据供后续分析查询;拉取指定规则对最近3天所有运行日志进行智能分析并告警。
43.优选的,上述分布式动态可配置爬虫平台还包括无头浏览器模块,无头浏览器模块用于以解决部分页面加密需要渲染数据的问题。
44.优选的,上述分布式动态可配置爬虫平台还包括验证码模块,验证码模块用于解决部分站点需要输入验证码才可以访问的问题。
45.优选的,上述分布式动态可配置爬虫平台还包括代理ip模块,代理ip模块用于解决站点对ip请求限制的问题。
46.优选的,上述分布式动态可配置爬虫平台还包括附件转换模块,附件转换模块用于自动识别图片、pdf等格式的数据,并将其转换为html格式供解析器解析。
47.优选的,上述分布式动态可配置爬虫平台还包括存储模块,存储模块用于持久化存储爬虫结果的结构化后数据,且支持mysql、oracle、postgresql、mongodb等格式数据的存储。
48.优选的,上述分布式动态可配置爬虫平台还包括日志模块,日志模块用于实时收集各爬虫子模块的运行日志,实现毫秒级展示。
49.本实施例公开了一种爬虫方法,在本实施方式中,爬虫方法采用上述分布式动态可配置爬虫平台从海量站点内定向抓取数据,请参图1所示,爬虫方法包括以下步骤:
50.s1、用户输入爬虫需求,依据爬虫需求形成爬虫抓取规则;
51.具体的,用户根据企业实际需求,在分布式动态可配置爬虫平台上输入爬虫需求,平台内自动规则生成模块根据爬虫需求在无需写入代码的情况下,即可自动生成爬虫抓取规则。具体的,爬虫抓取规则的形成方法为:首先,依据需求清单在分布式动态可配置爬虫平台上进行通用参数配置,通用参数至少包括规则名称、抓取页面网址、调度间隔的配置;其次,通用参数配置完成后,打开指定页面插件,自动识别页面结构自动生成提取表达式,依据提取表达式生成相应爬虫抓取规则;若如果无法自动识别页面结构时,则经人工编写xpath及正则表达式,生成爬虫抓取规则;最后对爬虫抓取规则进行审核,审核通过后进入爬虫抓取规则发布流程。
52.优选的,生成的爬虫抓取规则中包括待采集入口url、指定页面的请求方式、指定页面的抽取规则、爬虫结果模板等信息。
53.s2、解析爬虫抓取规则形成爬虫任务,解析爬虫调度配置形成爬虫任务调度;
54.s3、根据爬虫任务对分布式动态可配置爬虫平台内多个爬虫子模块排序,选择排序最高的爬虫子模块作为最优爬虫运行节点;
55.具体的,步骤s2和s3中,通过爬虫调度模块对爬虫调度配置解析,形成爬虫任务调度,并依据爬虫任务对多个爬虫子模块排序,从而自动选择出最优爬虫运行节点进行爬虫任务。
56.s4、启动最优爬虫运行节点并执行爬虫任务,分别抓取m个目标站点的n个指定页面,解析指定页面url并进行去重处理后加入待爬列队,直至m个目标站点中n个指定页面全部被抓取;
57.具体的,s4为在爬虫过程中,通过第一去重模块分别对各个目标站点的n个指定页面进行抓取,并对各个指定页面url解析后进行去重处理,将去重后的指定页面加入待爬列队中,此步骤相当于进行第一次降低冗余度过程。
58.同时,需要说明的是,n表示各个目标站点的指定页面的数量,不同指定页面的数量n可以相同,也可以不同。
59.s5、对待爬列队中指定页面的结构化数据进行相似度检测,去重处理以降低冗余度,形成并保存爬虫结果。
60.具体的,在本步骤中,采用结构化数据解析模块根据抓取的结构化数据,同时采用第二去重模块依据simhash进行相似度检测以降低结构化数据的冗余度,此步骤相当于进行第二次降低冗余度过程。
61.本发明通过分布式方式运行爬虫任务,具有高并发、高性能,高可用的优点,同时可以根据用户业务需求进行动态扩缩容;且爬虫抓取规则通过点选配置、自动化生成,无需写代码即可实现将开发效率提升了10倍左右;且进行了两次去重处理以降低结构化数据的冗余度。通过爬虫抓取规则及两次去重处理,从而剔除用户不关心的数据,至抓取用户关心的特定数据,实现快速高效获取用户所需数据的目的。
62.由于分布式动态可配置爬虫平台在爬虫任务执行的过程中,可能出现各种异常情况,其会导致爬虫结果偏差大,数据抽取不准确的问题,因此作为对上述爬虫方法的改进,如图1所示,上述爬虫方法还包括s6、依据agent对爬虫任务的执行状态进行动态实时监测,并根据预警规则发送告警信息。优选的,上述预警规则为错误异常实时捕获分析自动过滤误报规则,其能够对错误异常实时捕获分析并自动过滤误报后。
63.本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或计算机程序产品,一种计算机可读存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等),用于保存计算机程序,其中计算机程序被处理器执行时实现上述实施例公开的爬虫方法,关于该方法的具体步骤可以参考前述实施例中公开的相应内容,在此不再进行赘述。
64.以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
65.此外,应当理解,虽然本说明书按照实施方式加以描述,但并非每个实施方式仅包含一个独立的技术方案,说明书的这种叙述方式仅仅是为清楚起见,本领域技术人员应当将说明书作为一个整体,各实施例中的技术方案也可以经适当组合,形成本领域技术人员可以理解的其他实施方式。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1