一种包含片上调度器的FPGA异构处理架构
一种包含片上调度器的fpga异构处理架构
技术领域
1.本发明涉及异构计算领域,具体涉及一种包含片上调度器的fpga异构处理架构。
背景技术:
2.异构计算引入特定的计算单元使计算系统变为混合结构,让每一种不同类型的计算单元执行自己最擅长的工作,突破了原有的cpu发展瓶颈,能够有效提高计算系统效率。其中fpga的流水加速机制、低延迟低功耗等特点适合于雷达信号处理算法,面向雷达信号处理领域高集成、宽带多通道抗干扰、反杂波、成像实时处理的需求,cpu+fpga异构加速处理架构已成为主流的异构加速处理方案。
3.目前的cpu+fpga异构平台中,cpu作为主控机控制fpga完成运算操作,在一次运算过程内两者之间需进行多次通信,导致数据传输开销大、延迟大,fpga计算内核长期处于等待状态,难以满足雷达信号实时处理需求,需要一种更高效的数据通信与传输机制以更充分的发挥cpu+fpga架构优势。
技术实现要素:
4.发明目的:本发明主要针对目前cpu+fpga异构计算平台数据通信与传输消耗大量时间,浪费硬件效率,难以满足雷达信号实时处理需求的问题,提出一种包含片上调度器的fpga异构处理架构设计来支持多帧循环运算和kernel间启动机制,减少了主机端与设备端的交互以及数据传输次数,显著提升雷达异构计算平台的处理性能。
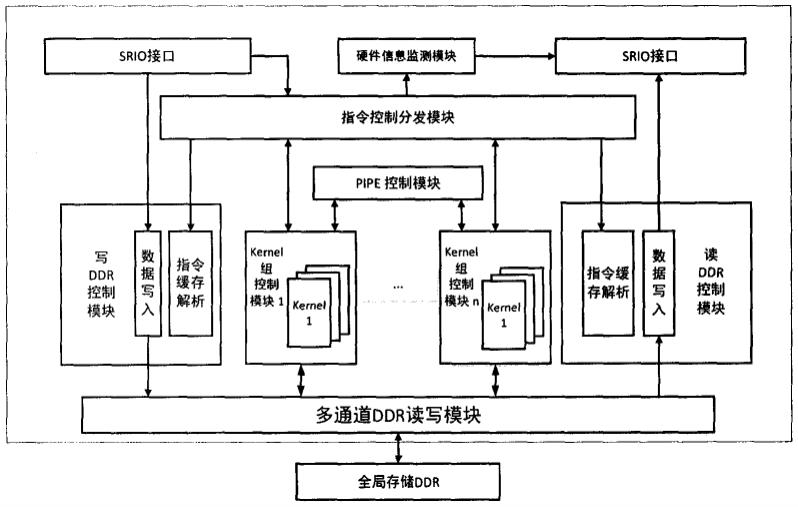
5.技术方案:本发明公开一种包含片上调度器的fpga异构处理架构设计,其特征在于:所述的fpga异构处理架构带有一个片上调度器,支持多帧循环运算控制和kernel间启动机制,辅助cpu完成异构计算任务调度。具体架构如图1所示。
6.该硬件架构所包含的主要模块包括:
7.srio接口模块:基于srio ip内核接收来自cpu端和其他fpga数据并产生响应包,以及根据指令信息、节点id、地址参数等数据,将待发送的指令和数据加上srio包头后发送。该模块对接收的指令和数据进行初步拆分和解析,发送到下一级写ddr控制模块或指令控制分发模块。
8.指令控制分发模块:实现系统指令的分发和反馈机制,根据指令类型以及内核编号等信息对指令进行仲裁发送至目标模块,调度多个子运算内核模块,同时收集模块发回的反馈信息并整理打包送入srio接口模块,发送回host端。
9.kernel的数据传输:数据流向包括ddr以及另一个kernel。ddr读写使用基于axi4总线协议的axi interconnect实现,它作为内核对ddr数据访问进行仲裁;kernel间数据通信采用pipe进行,根据指令进行通道切换。
10.运算内核:控制槽位里的内核模块,具有统一的接口,使用指令解析得到参数,对内核进行配置和调用,同时实现内核的执行模型下的并行计算、事件反馈和同步。
11.硬件信息监测模块:支持opencl标准定义的一些基本功能。例如,当cpu端使用
clgetdeviceids api获得device端的信息情况时,fpga将opencl支持信息、平台信息、内核集成状况等信息打包发送回host端。除此之外,在运行中监测整个设备的运行状态,供host随时查询以及上报异常情况。
12.fpga内各模块根据cpu端指令来执行具体任务,指令主要包含以下3类:查询fpga信息类型指令、存储控制类型指令以及kernel运算控制类型指令。其中,查询fpga信息类型指令包括查询设备id、查询设备各kernel运行状态和运行次数等;存储控制类型指令完成数据在cpu内存与fpga端ddr之间的传输;kernel运算控制类型指令包含循环控制指令、kernel启动指令、kernel参数指令、kernel数据流配置指令,控制内核完成运算任务。
13.在硬件架构中,指令控制分发模块为本发明主要创新部分,该模块执行循环控制指令以及kernel启动指令,实现了kernel间相互启动功能,来支持多帧流水及迭代运算场景。该模块架构如图2所示。其中指令分发子模块根据指令类型以及内核编号等信息对指令进行仲裁,各kernel组初步指令解析子模块以及指令缓存fifo负责完成循环指令的解码和指令的缓存,指令控制子模块负责将指令发送至目标模块,其中kernel指令控制子模块包含一个kernel完成计数器,记录各个kernel完成运算次数,供主机端以及kernel启动指令查询。
14.下面将本发明对比现有技术的新增功能进行进一步阐述。
15.本发明实现的kernel间启动机制主要通过指令控制分发模块以及运算内核模块完成,其中kernel启动指令包含以下信息:kernel启动指令标志、启动kernel编号、前置kernel编号及要求计数值、后置kernel编号及要求计数值。下面对各段信息做出说明。
16.(1)kernel启动指令标志:标明此指令为kernel启动指令,当kernel指令控制子模块识别到该标志后,开始进行kernel启动指令的解码。
17.(2)启动kernel编号:标明此指令作用于哪一个kernel。
18.(3)前置kernel编号及要求计数值:前置kernel说明kernel间数据依赖关系,若kernel a的运行结果数据是另一kernel b的输入数据,则称a是b的前置kernel。为防止b读取数据时出现错误,在b的启动指令里添加字段说明前置kernel及要求计数值,之后运行过程中,只有当a执行次数达到要求时,b才会接收启动指令。
19.(4)后置kernel编号及要求计数值:后置kernel说明kernel间数据依赖关系,若kernel a的运行结果数据是另一kernel b的输入数据,则称b是a的后置kernel。为防止a运行时将b还未使用的数据覆盖,在a的启动指令里添加字段说明后置kernel及要求计数值,之后运行过程中,只有当b执行次数达到要求时,a才会接收到启动指令。
20.具体kernel间启动机制实现流程图如图3所示,具体的包括以下步骤:
21.(1)kernel启动指令传送至kernel指令控制子模块,并被kernel指令控制子模块解析。
22.(2)根据指令内容查询前置kernel以及后置kernel执行次数,判断指令执行情况。若达到指令执行条件,则kernel指令控制子模块将kernel执行指令传输至运算内核模块,若未达到执行条件则将指令存储至fifo当中,等待指令执行条件完成。
23.(3)运算内核模块接收到kernel执行指令后解析指令,发送参数,对内核进行配置和调用,控制内核完成运算任务。
24.(4)内核完成运算任务之后,向kernel指令控制子模块发送完成信号。
25.(5)kernel指令控制子模块接收完成信号,并在该内核完成计数器上加一。
26.本发明实现的多帧循环运算功能主要由指令控制分发模块执行多帧循环指令完成,其中多帧循环指令包含以下信息:多帧循环指令标志、循环指令条数、指令循环次数。下面对各段信息做出说明。
27.(1)多帧循环指令标志:标明此指令为多帧循环指令标志,当kernel的初步指令解析子模块识别到该标志后,开始进行多帧循环指令的解码。
28.(2)循环指令条数:标明循环指令包包含的指令条数。
29.(3)指令循环次数:标明循环指令包中指令需循环次数。
30.具体多帧循环运算功能实现流程图如图4所示,具体的包括以下步骤:
31.(1)指令控制分发模块接收传来的指令包,并根据指令控制字段判断指令类型,将指令分发到不同的初步指令解析子模块。
32.(2)在各个kernel的初步指令解析子模块,首先判断第一条指令,若为循环控制指令,那么其后跟随的指令为多帧控制指令,此时将该段指令存入bram块中,在之后多次读取bram中的指令,并将其解析为普通指令(其中的操作包括kernel启动指令执行条件的更改以及kernel读写指令中地址的偏移),最后将指令存入各个kernel的指令fifo中,若第一条指令为其它事务指令,则无需处理,将其直接存入相应的指令fifo。
33.(3)在指令fifo的输出端识别指令类型,如果指令类型为kernel启动指令,则判断指令执行条件,若条件达到(前置kernel和后置kernel执行次数符合执行要求),将指令fifo的读使能信号拉高,把指令输出到相应模块。
34.(4)各个kernel组控制模块根据指令执行,并在完成一次运算后发送完成信号,kernel指令控制子模块接收到信号后将该kernel的完成计数加一。
35.(5)当算法链完成一帧操作后,将对srio发送门铃,主机端通过接收门铃信号得知算法链的多帧执行情况,并在之后发送read_buffer请求,将结果读回主机端。
36.有益效果:在雷达信号处理的应用场景中,fpga上所部署kernel流水线前后内核间若存在数据关联性,按照opencl通用协议流程,kernel启动由主机控制完成,只有在主机接收到前置kernel执行完成信号之后才会发送启动下一kernel的指令。这两次数据交互消耗大量时间,浪费硬件效率,无法满足雷达信号实时处理需求。采用本发明实现的kernel间启动机制,可减少硬件等待时间,提高执行效率。
37.同时,为最大化利用硬件资源,在实际应用场景中经常会出现多帧数据流水处理的执行需求。本发明中,在host端,主机将算法链的执行流程、执行帧数、每个kernel的参数、前置后置kernel统一配置成固定指令格式,发送给设备。设备收到指令后,进行解码,并通过fpga端的控制逻辑,正确的执行算法链流程,并在最终将结果写回ddr。中间无需通信,仅在开始以及结束的时候进行通讯,节约了通信时间,并最大化的发挥了硬件的效率。
附图说明
38.图1为本发明提出的一种包含片上调度器的fpga异构处理架构。
39.图2为本发明提出的指令控制分发模块架构。
40.图3为本发明kernel间启动机制实现的流程示意图。
41.图4为本发明多帧循环运算功能实现的流程示意图。
具体实施方式
42.为了详细的说明本发明公开的技术方案,下面结合具体实例做进一步的阐述。
43.在本实例中,将三个不同内核部署至单片fpga中,其中输入数据需被三个内核以帧为单位依次执行20次。具体步骤如下所示:
44.步骤1:用户配置算法链的具体执行过程,并通过调用api将算法链的执行数据与指令通过srio总线以指令包的形式传入fpga端。
45.步骤2:fpga端接收到数据包后对包内数据进行分析,将计算数据传入写ddr控制模块进入ddr,指令传入指令控制分发模块。
46.步骤3:指令控制分发模块根据指令的控制字段判断指令类型,将其发送至不同的初步指令解析子模块。
47.步骤4:当初步解析子模块接收到指令后,首先判断第一条指令,如果是多帧循环指令,那么其后跟随的指令包为循环指令包,此时将该段指令包存入bram块中,在之后多次读取bram中的指令,并将其解析为普通指令(其中的操作包括kernel启动指令执行条件的更改以及kernel读写指令中地址的偏移),最后将指令存入各个kernel的指令fifo中,若第一条指令为其它事务指令,则无需处理,将其直接存入相应的指令fifo中。
48.步骤5:在指令fifo的输出端,判断指令类型,如果是kernel启动指令,则判断指令执行条件,若条件达到(前置kernel和后置kernel完成次数符合执行要求),将指令fifo的读使能信号拉高,把指令输出到相应模块。
49.步骤6:各个kernel控制模块接收到kernel运行指令后,首先配置kernel的参数。根据指令段中对应控制字判断kernel参数配置的指令,然后取出对应参数,统一完成一个工作组中多个kernel的参数配置。
50.配置完参数后,根据指令段中对应控制字判断kernel数据流配置指令,取出kernel数据流配置指令,每条指令对应着一个buffer的读或者写,先取出读指令,根据指令从ddr片外存储或pipe中读取kernel运算所用到的数据并传入kernel内部,若有多块buffer的数据,则根据指令的先后顺序依次读取相应的buffer,在传递完所有读指令后,取出kernel的写指令,根据指令控制kernel的运算数据写入对应的buffer。
51.在kernel可接收下一次配置时,再次拉高模块读使能,可以进行下一轮kernel的相关配置。
52.步骤7:当kernel执行完成一次运算,则向指令控制分发模块发送完成标志,相应kernel完成次数加一。
53.步骤8:当kernel执行次数到达20次后,向主机端发送完成门铃。并将运算数据通过读ddr控制模块传送至cpu端。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1