用于恶意访问的检测分析方法及系统与流程
1.本发明涉及一种网络安全的大数据分析技术。更具体地说,本发明涉及一种用于恶意访问的检测分析方法及系统。
背景技术:
2.随着互联网技术的高速发展,各种网络服务在为我们的生活提供更加方便快捷服务的同时,也受到了越来越多,越来越复杂的恶意访问的威胁。如何有效地识别并阻断恶意访问已经成为亟待解决的网络安全问题之一。传统的防护手段虽然对已知攻击类型的恶意访问的识别准确率大幅提升,但是存在成本较大、误差比较高、不灵活以及对新型攻击不能快速识别等问题,同时对未知的恶意访问无法做到及时发现,准确识别。
技术实现要素:
3.本发明的一个目的是解决至少上述问题,并提供至少后面将说明的优点。
4.本发明还有一个目的是提供一种用于恶意访问的检测分析方法,其能够有效提高恶意访问数据检测的效率和准确性,并精准识别出对应的攻击类型,对存在恶意访问黑历史数据进行挖掘,提高恶意访问检测结果的准确性和完整性,并且对恶意访问进行快捷的响应。
5.为了实现根据本发明的这些目的和其它优点,提供了一种用于恶意访问的检测分析方法,其包括以下步骤:
6.步骤一,获取安全日志数据,清洗处理后进行待测数据的特征提取,再次进行数据清洗;
7.步骤二,将步骤一中清洗后的待测数据推送入检测模型组进行攻击识别,所述检测模型组包括恶意请求识别模型和威胁情报库识别模型;
8.步骤三,优先阻断所述检测模型组识别出的恶意数据;同时,所述检测模型组对识别出的恶意数据和非恶意数据进行呈现,供后续阻断使用。
9.优选的是,所述恶意请求识别模型采用机器学习方法来检测url,恶意访问地址的检测采用逻辑回归算法来进行检测,具体包括:
10.s201,将待测数据进行分类处理;
11.s202,进行td重要程度衡量,td值计算公式如式(ⅰ):
12.td(d,t)=tsef(d,t)*isef(t)(ⅰ)
13.式(ⅰ)中,tsef(d,t)代表url中第d个id索引为t的字符串出现的次数,
14.isef(t)的值通过式(ⅱ)计算获得,式(ⅱ)如下:
[0015][0016]
式(ⅱ)中,dsef(t)代表id为t的字符串出现在几个url中;
[0017]
s203,将td值做归一处理,计算所有的td值,输出结果。
[0018]
优选的是,所述步骤一中,所述清洗处理为对安全日志数据进行缺失值处理;所述缺失值处理采用均值填充、中位数填充以及全局常量
‘
unknow’方式填充。
[0019]
优选的是,所述特征提取采用词集模型和词袋模型分别对待测数据进行特征提取。
[0020]
优选的是,所述步骤一中,进行特征提取后,还需对待测数据再次清洗,并对待测数据中的关键字进行分词处理,对分词后的数据用作逻辑回归模型的输入数据转换为逻辑回归的二元格式。
[0021]
优选的是,所述步骤二中的恶意请求识别模型包括:xss检测模型、sql注入检测模型以及webshell检测模型。
[0022]
优选的是,所述威胁情报库识别模型具体为:基于威胁情报库计算待测数据的ip威胁信誉值,当信誉值低于预设阈值时,判定其为恶意ip。
[0023]
本发明还提供了一种基于所述用于恶意访问的检测分析方法的检测分析系统,其包括:
[0024]
日志采集模块,其用于获取网络平台的安全日志;
[0025]
数据清洗模块,其用于对安全日志数据进行缺失值处理和对特征提取后的待测数据中的“\”反斜线进行再次清洗;
[0026]
特征提取模块,其包括进行特征提取的词集模型和词袋模型;
[0027]
检测模块,其包括:恶意请求识别模型,其用于识别待测数据的攻击类别;和威胁情报库识别模块,其基于威胁情报库计算待测数据的ip威胁信誉值,并判断其是否为恶意请求;
[0028]
以及响应模块,其用于根据检测模块的输出结果,优先阻断恶意请求识别模型和威胁情报库识别模块同时命中的恶意请求。
[0029]
优选的是,所述检测分析系统还包括:数据库,其包括恶意攻击类型库和威胁情报库。
[0030]
本发明至少包括以下有益效果:本发明所述用于恶意访问的检测分析方法采用恶意请求识别模型结合威胁情报的方式可准确命中所有的攻击,包括信誉值比较低的ip,对安全防护角度来说意义重大,提高了针对恶意访问的多维度的识别精确度。本发明所述用于恶意访问的检测分析方法能够有效提高恶意访问数据检测的效率和准确性,并精准识别出对应的攻击类型,对存在恶意访问黑历史数据进行挖掘,提高恶意访问检测结果的准确性和完整性,并且对恶意访问进行快捷的响应。
[0031]
本发明的其它优点、目标和特征将部分通过下面的说明体现,部分还将通过对本发明的研究和实践而为本领域的技术人员所理解。
附图说明
[0032]
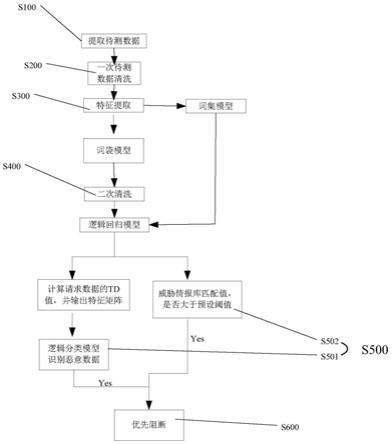
图1为本发明其中一个实施例所述用于恶意访问的检测分析方法的流程示意图。
具体实施方式
[0033]
下面结合附图对本发明做进一步的详细说明,以令本领域技术人员参照说明书文字能够据以实施。
[0034]
应当理解,本文所使用的诸如“具有”、“包含”以及“包括”术语并不排除一个或多个其它元件或其组合的存在或添加。
[0035]
如图1所示,本发明所述用于恶意访问的检测分析方法包括以下步骤:
[0036]
s100,提取待测数据,获取安全日志数据,所述安全日志数据的格式例如如下:
[0037]
{"method":"get","query":{"query":"lawn&garden buying guides"},"path":"/search","statuscode":200,"source":{"remoteaddress":"127.0.0.1","useragent":"mozilla/5.0(macintosh;intel mac os x 10_12_3)applewebkit/537.36(khtml,like gecko)
[0038]
chrome/59.0.3071.115safari/537.36"},"route":"/search","headers":{"host":"localhost:8002","connection":"keep-alive","cache-control":"no-cache","user-agent":"mozilla/5.0(macintosh;intel mac os x 10_12_3)applewebkit/537.36(khtml,like gecko)chrome/59.0.3071.115safari/537.36","accept":"*/*","accept-encoding":"gzip,deflate,
[0039]
br","accept-language":"en-us,en;q=0.8,es;q=0.6"},"requestpayload":null,"responsepayload":"search"}
[0040]
s200,第一次待测数据清洗,主要对数据集中的缺失值进行处理,缺失值处理采用了均值填充和数据分布倾斜情况使用了中位数填充的方法,且对类别属性采用了全局常量
‘
unknow’方式填充。
[0041]
s300,特征提取,因恶意访问的特征比较复杂,影响因素较多,因此采用词切分方式,对待测数据中不同的单词做为一种特征,例如:
[0042]
content={
[0043]
{
‘
city’:’shanghai’,’temp’:33.},
[0044]
{
‘
city’:’longdon’,’temp’:12.},
[0045]
{
‘
city’:’reino’,’temp’:18.},
[0046]
......
[0047]
}
[0048]
以上数据content键中有多个值,分别如:’shanghai’、’longdon’、’reino’,因此直接把获取的值作为词的特征数据,键temp是数据类型值,因此可以直接作为特征使用。根据词频的不同,分别利用词袋模型和词集模型进行待测数据的文本特征提取;词袋模型例如对数据进行词袋处理,数据如下:
[0049]
a=[
[0050]
"matched\"operator`rx'with parameter`(?:semrushbot|dotbot|coccocbot|mj12bot|ahrefsbot|winhttprequest|wappalyzer|phantomjs)'against variable`request_headers:user-agent'(value:`mozilla/5.0(compatible;semrushbot/7~bl;+http://www.semrush.com/bot.html)')",
[0051]“/login/bind/wechat_work?_target_path=%2fcourse%2f10834%2fnotes%3fselectedcou rse%3d0%26sort%3dlatest%26task%3d0&invitecode”[0052]
......
[0053]
]
[0054]
获取a中对应的特征名称:[
‘
matched’,’rx’,’operator’,’with’,’parameter’......],对词袋中的数据进行了词袋化处理。以便于进行步骤s400。
[0055]
s400,再次进行数据清洗;针对数据中的“\”反斜线进行清洗,并以及对数据中的“.”点、“com”等关键字进行分词处理,对分词后的数据用作逻辑回归模型的输入数据转换为逻辑回归的二元格式;
[0056]
s500,再次清洗后的待测数据推送入检测模型组进行攻击识别,所述检测模型组包括恶意请求识别模型和威胁情报库识别模型;根据采集到的数据进行攻击检测模型识别;对已知特征的攻击数据采用机器学习模型智能识别的方式进行识别攻击ip,对未知类型的攻击ip采用威胁情报的方式进行命中,因威胁情报强大的命中率和准确性及ip的恶意历史因素,可高效准确地识别恶意ip数据。攻击识别具体包括:
[0057]
s501,恶意请求url识别
[0058]
其中恶意请求url识别采用机器学习方法来检测url通常在浏览器中试用,且符合标准格式要求,如://xxx/xxx/[?query]格式,url是由域名、主机名、路径和网址以及端口组成的;
[0059]
恶意访问地址的检测采用了逻辑回归算法来进行检测,通过对待测数据进行分类处理,且包括评估逻辑模型的独立二元变量。
[0060]
然后对数据url进行转换成数据帧值,数据帧转换方式如下:
[0061]
#生成键值整数索引
[0062]
f=pd.datafram(das)
[0063]
#数据转换成ndarray类型,并进行随机处理
[0064]
f_url=np.array(f);random.shuffle(f_url)
[0065]
下一步对所有数据做进行td重要程度衡量,td值计算公式如式(ⅰ):
[0066]
td(d,t)=tsef(d,t)*isef(t)
ꢀꢀꢀ
(ⅰ)
[0067]
式(ⅰ)中,tsef(d,t)代表url中第d个id索引为t的字符串出现的次数,
[0068]
isef(t)的值通过式(ⅱ)计算获得,式(ⅱ)如下:
[0069][0070]
式(ⅱ)中,dsef(t)代表id为t的字符串出现在几个url中;再对url中每个字符中的td值进行计算,将td值做归一处理,计算所有的td值,输出结果如下:
[0071]
[
[0072]
0.521215,(0,21518)
[0073]
0.325655,(0,16515)
[0074]
0.452154,(1,16545)
[0075]
...
[0076]
...
[0077]
]
[0078]
输出矩阵中每一行的输出向量,表示所有的url数量,而没有表示的项目值都是0,
[0079]
将数据结果进行输出,判断是否为恶意访问,是则进行步骤s600,否则进行步骤s502。
[0080]
s502,同时对数据ip进行威胁情报库识别,威胁情报库中记录了所有网络攻击的恶意ip信息,采用情报库匹配的方式对待检测ip进行匹配命中,若命中的数据,则取出情报库中的恶意信誉值作为当前是否恶意ip的判断参考;超出阈值则进行步骤s600。
[0081]
s600,所述恶意请求识别模型识别当前访问为恶意行为,且威胁情报库中对此ip也进行了命中,则对当前访问进行优先推送处理。对其中的恶意数据做及时阻断处理,如防火墙阻断或加入黑名单和威胁情报库。
[0082]
本发明还提供了一种基于所述用于恶意访问的检测分析方法的检测分析系统,其包括:
[0083]
日志采集模块,其用于获取网络平台的安全日志;
[0084]
数据清洗模块,其用于对安全日志数据进行缺失值处理和对特征提取后的待测数据中的“\”反斜线进行再次清洗;
[0085]
特征提取模块,其包括进行特征提取的词集模型和词袋模型;
[0086]
检测模块,其包括:恶意请求识别模型,其用于识别待测数据的攻击类别;和威胁情报库识别模块,其基于威胁情报库计算待测数据的ip威胁信誉值,并判断其是否为恶意请求;
[0087]
以及响应模块,其用于根据检测模块的输出结果,优先阻断恶意请求识别模型和威胁情报库识别模块同时命中的恶意请求。
[0088]
在其中一个实施例中,所述检测分析系统还包括:数据库,其包括恶意攻击类型库和威胁情报库。本发明所述检测分析系统结构简单,运行稳定且速度快。
[0089]
尽管本发明的实施方案已公开如上,但其并不仅仅限于说明书和实施方式中所列运用,它完全可以被适用于各种适合本发明的领域,对于熟悉本领域的人员而言,可容易地实现另外的修改,因此在不背离权利要求及等同范围所限定的一般概念下,本发明并不限于特定的细节和这里示出与描述的图例。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1