推荐系统的数据处理方法、装置、电子设备和存储介质与流程
1.本发明涉及互联网技术领域,特别是涉及一种推荐系统的数据处理方法、装置、电子设备和计算机可读存储介质。
背景技术:
2.推荐系统是互联网时代的一种信息检索工具,自上世纪90年代起,人们便认识到了推荐系统的价值,经过了二十多年的积累和沉淀,推荐系统逐渐成为一门独立的学科在学术研究和业界应用中都取得了很多成果。
3.由于曝光机理、反馈闭环等原因,推荐系统中存在位置偏差、选择偏差、流行度偏差等多种混杂偏差。这些偏差相互影响,会导致推荐内容越来越窄,用户兴趣固化,影响系统生态的良性发展。
4.受用户选择和模型推荐的双重影响,推荐系统会出现选择偏差的情况。目前,为纠正推荐系统的选择偏差,主要可以采用如下两类方案:
5.方案一、利用缺失的数据进行建模等启发式方案,或者假定一个无偏的分布,从分布中采样训练数据的采样方案。方案二、采用点击率为倾向分进行反向加权,以提高转化率的预估精度。
6.但是,上述方案存在以下技术问题,假定的分布与真实的分布之间的差距较大,很难采样到合适的训练数据,导致建模困难。采用点击率为倾向分进行反向加权的方案不适用于纠正模型推荐、召回过滤等原因导致的选择偏差。
技术实现要素:
7.鉴于上述问题,提出了本发明实施例以便提供一种克服上述问题或者至少部分地解决上述问题的一种推荐系统的数据处理方法、装置、电子设备和计算机可读存储介质。
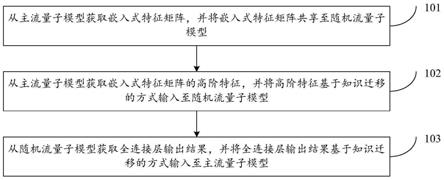
8.为了解决上述问题,根据本发明实施例的第一方面,公开了一种推荐系统的数据处理方法,所述推荐系统包含主流量子模型和随机流量子模型,所述方法包括:从所述主流量子模型获取嵌入式特征矩阵,并将所述嵌入式特征矩阵共享至所述随机流量子模型;从所述主流量子模型获取所述嵌入式特征矩阵的高阶特征,并将所述高阶特征基于知识迁移的方式输入至所述随机流量子模型;从所述随机流量子模型获取全连接层输出结果,并将所述全连接层输出结果基于知识迁移的方式输入至所述主流量子模型。
9.可选地,所述方法还包括:将所述随机流量子模型的交叉熵损失函数与所述主流量子模型的平方损失函数相加,得到所述随机流量子模型的损失函数。
10.可选地,所述平方损失函数为所述高阶特征与所述随机流量子模型的一层输出结果之差的2范数的平方。
11.可选地,所述推荐系统的损失函数为根据知识迁移量、所述随机流量子模型的交叉熵损失函数、所述主流量子模型的交叉熵损失函数、训练样本数据的标签、所述随机流量子模型的全连接层输出结果、所述主流量子模型的全连接层输出结果和蒸馏温度生成所
得。
12.可选地,所述全连接层输出结果为软标签结果。
13.可选地,所述嵌入式特征矩阵包括以下至少之一:交叉特征、广告侧特征、用户侧特征、上下文特征。
14.根据本发明实施例的第二方面,还公开了一种推荐系统的数据处理装置,所述推荐系统包含主流量子模型和随机流量子模型,所述装置包括:共享模块,用于从所述主流量子模型获取嵌入式特征矩阵,并将所述嵌入式特征矩阵共享至所述随机流量子模型;第一知识迁移模块,用于从所述主流量子模型获取所述嵌入式特征矩阵的高阶特征,并将所述高阶特征基于知识迁移的方式输入至所述随机流量子模型;第二知识迁移模块,用于从所述随机流量子模型获取全连接层输出结果,并将所述全连接层输出结果基于知识迁移的方式输入至所述主流量子模型。
15.可选地,所述装置还包括:损失函数模块,用于将所述随机流量子模型的交叉熵损失函数与所述主流量子模型的平方损失函数相加,得到所述随机流量子模型的损失函数。
16.可选地,所述平方损失函数为所述高阶特征与所述随机流量子模型的一层输出结果之差的2范数的平方。
17.可选地,所述推荐系统的损失函数为根据知识迁移量、所述随机流量子模型的交叉熵损失函数、所述主流量子模型的交叉熵损失函数、训练样本数据的标签、所述随机流量子模型的全连接层输出结果、所述主流量子模型的全连接层输出结果和蒸馏温度生成所得。
18.可选地,所述全连接层输出结果为软标签结果。
19.可选地,所述嵌入式特征矩阵包括以下至少之一:交叉特征、广告侧特征、用户侧特征、上下文特征。
20.根据本发明实施例的第三方面,还公开了一种电子设备,包括存储器、处理器及存储在所述存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现第一方面所述的推荐系统的数据处理方法。
21.根据本发明实施例的第四方面,还公开了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现第一方面所述的推荐系统的数据处理方法。
22.与现有技术相比,本发明实施例提供的技术方案具有如下优点:
23.本发明实施例提供的一种推荐系统的数据处理方案,该推荐系统可以包含主流量子模型和随机流量子模型。该主流量子模型可以基于主流量样本数据训练所得,随机流量子模型可以基于随机流量样本数据训练所得。在推荐系统的训练过程中,从主流量子模型获取嵌入式特征矩阵,并将嵌入式特征矩阵共享至随机流量子模型,实现主流量子模型与随机流量子模型之间的特征共享。从主流量子模型获取嵌入式特征矩阵的高阶特征,并将高阶特征基于知识迁移的方式输入至随机流量子模型;从随机流量子模型获取全连接层输出结果,并将全连接层输出结果基于知识迁移的方式输入至主流量子模型。
24.由于随机流量样本数据较少,为保证随机流量子模型的建模精度,一方面,本发明实施例将主流量子模型输出的嵌入式特征矩阵共享给随机流量子模型,并且,将主流量子模型的高阶特征通过知识迁移的方式出入至随机流量子模型,以丰富随机流量子模型的特征数据,提高随机流量子模型的建模精度。另一方面,随机流量子模型的全连接层输出结果
也基于知识迁移的方式输入至主流量子模型,以校正主流量子模型的推荐结果。
附图说明
25.图1是本发明实施例的一种推荐系统的数据处理方法的步骤流程图;
26.图2是本发明实施例的一种推荐系统中双向知识迁移的方案示意图;
27.图3是本发明实施例的一种推荐系统的数据处理装置的结构框图;
28.图4是本发明实施例的一种电子设备的结构示意图。
具体实施方式
29.为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
30.参照图1,示出了本发明实施例的一种推荐系统的数据处理方法的步骤流程图。该推荐系统可以包含主流量子模型和随机流量子模型。在实际的应用场景中,该推荐系统可以预估主流量数据和随机流量数据的转化率。具体地,主流量子模型可以预估主流量数据的转化率,随机流量子模型可以预估随机流量数据的转化率。其中,主流量数据为按照预设的规则推荐给用户的商店、商品、服务等流量数据。随机流量数据为按照随机的方式推荐给用户的商店、商品、服务等流量数据。该一种推荐系统的数据处理方法具体可以包括如下步骤:
31.步骤101,从主流量子模型获取嵌入式特征矩阵,并将嵌入式特征矩阵共享至随机流量子模型。
32.在本发明的实施例中,在主流量子模型的训练过程中,将主流量数据作为主流量子模型的训练样本数据,将主流量数据输入初始的主流量子模型,提取出主流量数据的嵌入式特征矩阵。
33.在实际应用中,嵌入式特征数据可以包含但不限于:交叉特征、广告侧特征、用户侧特征、上下文特征。其中,交叉特征可以为用户对商店、商品、服务等的点击率特征、转化率特征、曝光特征、点击特征、下单特征等。广告侧特征可以为商店、商品、服务等特征,如商店名称、商品图片、商品类目、商店所处商圈位置。用户侧特征可以为年龄特征、用户兴趣特征等。上下文特征可以为时间特征、日期特征、广告位特征等。
34.由于随机数据的数量级远远小于主流量数据的数量级,如果仅仅根据随机数据对随机数据子模型进行训练,训练出的随机流量子模型的精度会比较差。因此,本发明实施例将主流量模型输出的嵌入式特征矩阵共享给随机流量子模型,以丰富随机流量子模型的特征数据,进而提高随机流量子模型的建模精度。
35.步骤102,从主流量子模型获取嵌入式特征矩阵的高阶特征,并将高阶特征基于知识迁移的方式输入至随机流量子模型。
36.在本发明的实施例中,不仅将主流量子模型的嵌入式特征矩阵共享给随机流量子模型,还通过知识迁移的方式将嵌入式特征矩阵的高阶特征输入至随机流量子模型。其中,嵌入式特征矩阵的高阶特征可以为嵌入式特征矩阵经过几层深度神经网络(deep neural networks,简称dnn)后输出得到,相当于利用dnn对嵌入式特征矩阵进行特征高阶提取。
37.知识迁移是一种学习对另一种学习的影响,原有的知识结构对新的知识结构的学
习的影响就形成了知识的迁移。知识迁移可分为正迁移和负迁移。若原有知识结构对新知识结构的学习有促进作用,则称为正迁移;若原有知识结构对新知识结构的学习知识有阻碍作用,则成为负迁移。本发明实施例中的知识迁移均为正迁移。本步骤102将高阶特征通过知识迁移的方式输入至随机流量子模型,目的在于通过对主流量子模型的训练得到高阶特征,通过知识迁移的方式将高阶特征输入至随机流量子模型,以促进对随机流量子模型的训练,最终提高随机流量子模型的建模精度。
38.步骤103,从随机流量子模型获取全连接层输出结果,并将全连接层输出结果基于知识迁移的方式输入至主流量子模型。
39.在本发明的实施例中,上述知识迁移过程为从主流量子模型向随机流量子模型方向,本步骤103还可以从随机流量子模型向主流量子模型进行知识迁移。具体地,将随机流量子模型的全连接层输出结果(logits)通过知识迁移的方式输入至主流量子模型,目的在于对主流量子模型的输出结果进行校正。
40.本发明实施例提供的一种推荐系统的数据处理方案,该推荐系统可以包含主流量子模型和随机流量子模型。该主流量子模型可以基于主流量样本数据训练所得,随机流量子模型可以基于随机流量样本数据训练所得。在推荐系统的训练过程中,从主流量子模型获取嵌入式特征矩阵,并将嵌入式特征矩阵共享至随机流量子模型,实现主流量子模型与随机流量子模型之间的特征共享。从主流量子模型获取嵌入式特征矩阵的高阶特征,并将高阶特征基于知识迁移的方式输入至随机流量子模型;从随机流量子模型获取全连接层输出结果,并将全连接层输出结果基于知识迁移的方式输入至主流量子模型。
41.由于随机流量样本数据较少,为保证随机流量子模型的建模精度,一方面,本发明实施例将主流量子模型输出的嵌入式特征矩阵共享给随机流量子模型,并且,将主流量子模型的高阶特征通过知识迁移的方式出入至随机流量子模型,以丰富随机流量子模型的特征数据,提高随机流量子模型的建模精度。另一方面,随机流量子模型的全连接层输出结果也基于知识迁移的方式输入至主流量子模型,以校正主流量子模型的推荐结果。
42.在本发明的一种优选实施例中,为了保证随机流量子模型的建模精度,还可以在随机流量子模型的交叉熵损失函数的基础之上增加主流量子模型的平方损失函数,即将随机流量子模型的交叉熵损失函数与主流量子模型的平方损失函数相加,得到随机流量子模型的损失函数。交叉熵可在神经网络(机器学习)中作为损失函数,p表示真实标记的分布,q则为训练后的模型的预测标记分布,交叉熵损失函数可以衡量p与q的相似性。本发明实施例中的主流量子模型和随机流量子模型均存在各自的交叉熵损失函数。
43.在本发明的一种优选实施例中,主流量子模型的平方损失函数可以为主流量子模型输出的高阶特征与随机流量子模型的一层输出结果之差的2范数的平方,具体可以参照如下公式(1):
[0044][0045]
其中,λ表示平方损失函数的重要度,属于一种超参数,x表示主流量子模型的输入项或者随机流量子模型的输入项,l(x)表示主流量子模型的高阶特征,其中的x表示主流量子模型的输入项,z(x)表示随机流量子模型的一层输出结果,其中的x表示随机流量子模型的输入项。
[0046]
在本发明的一种优选实施例中,整个推荐系统的损失函数可以根据知识迁移量、随机流量子模型的交叉熵损失函数、主流量子模型的交叉熵损失函数、训练样本数据的标签、随机流量子模型的全连接层输出结果、主流量子模型的全连接层输出结果和蒸馏温度生成所得,具体可以参照如下公式(2):
[0047]
l=(1-α)ce(y,p)+αce(q,p)
·
t2ꢀꢀꢀꢀꢀꢀ
公式(2)
[0048]
其中,l表示整个推荐系统的损失函数,ce表示交叉熵损失函数,α表示知识迁移量,y表示训练样本数据的标签,p表示主流量子模型的全连接层输出结果,q表示随机流量子模型的全连接层输出结果,t表示蒸馏温度。
[0049]
本发明实施例中的推荐系统可以利用知识蒸馏(knowledge distillation,简称kd)方法创建,知识蒸馏是一种模型压缩方法,是一种基于“教师-学生网络思想”的训练方法,由于其简单,有效,在工业界被广泛应用。知识蒸馏就是将已经训练好的模型包含的知识(knowledge),蒸馏(distill)提取到另一个模型里面去。
[0050]
在本发明的一种优选实施例中,随机流量子模型的全连接层输出结果为软标签结果。通常,标签结果为0或者1,表示点击或者未点击。软标签结果为0至1之间的数。
[0051]
参照图2,示出了本发明实施例的一种推荐系统中双向知识迁移的方案示意图。该方案可以利用随机流量近似为无偏差推荐的特性,采用知识迁移的方式校正推荐系统中多种成因导致的选择偏差。在图2中,推荐系统可以包含主流量子模型和随机流量子模型。该方案采用主流量子模型的高阶特征向随机流量子模型进行知识迁移,以及随机流量子模型的全连接层输出结果向主流量子模型进行知识迁移的双向知识迁移。
[0052]
由于随机流量数据的数量级比较小,如果仅仅利用随机流量数据训练随机流量子模型,将会导致随机流量子模型的建模精度不高。因此,为了保证随机流量子模型的建模精度,随机流量子模型和主流量子模型共享嵌入式特征矩阵。而且,主流量子模型输出的高阶特征向随机流量子模型进行知识迁移。
[0053]
随机流量子模型输出的logits向主流量子模型进行知识迁移,以近似无偏的logits作为软标签结果对主流量子模型进行校准。
[0054]
与知识蒸馏类似,该方案中主流量子模型和随机流量子模型的训练过程大致为:
[0055]
首先,以主流量数据训练主流量子模型,获得稳定的嵌入式特征矩阵和高阶特征。
[0056]
其次,固定主流量子模型的网络参数,以随机流量数据训练随机流量子模型,将主流量子模型的高阶特征(或者称为中间层特征)知识迁移给随机流量子模型。
[0057]
然后,使用主流量数据,固定随机流量子模型的网络参数,将随机流量子模型的无偏logits知识迁移给主流量子模型。
[0058]
本发明的实施例针对推荐系统中多种成因导致的选择偏差问题,提出一种随机流量子模型与主流量子模型之间的双向知识迁移方案,随机流量子模型输出的软标签结果向主流量子模型进行知识迁移,对主流量子模型进行校正,主流量子模型的高阶特征向随机流量子模型进行知识迁移,保证随机流量子模型的建模精度,进而丰富推荐系统的推荐结果多样性,推荐结果无偏差,更加符合用户的实际需要和兴趣。
[0059]
需要说明的是,对于方法实施例,为了简单描述,故将其都表述为一系列的动作组合,但是本领域技术人员应该知悉,本发明实施例并不受所描述的动作顺序的限制,因为依据本发明实施例,某些步骤可以采用其他顺序或者同时进行。其次,本领域技术人员也应该
知悉,说明书中所描述的实施例均属于优选实施例,所涉及的动作并不一定是本发明实施例所必须的。
[0060]
参照图3,示出了本发明实施例的一种推荐系统的数据处理装置的结构框图,所述推荐系统包含主流量子模型和随机流量子模型。该一种推荐系统的数据处理装置具体可以包括如下模块:
[0061]
共享模块31,用于从所述主流量子模型获取嵌入式特征矩阵,并将所述嵌入式特征矩阵共享至所述随机流量子模型;
[0062]
第一知识迁移模块32,用于从所述主流量子模型获取所述嵌入式特征矩阵的高阶特征,并将所述高阶特征基于知识迁移的方式输入至所述随机流量子模型;
[0063]
第二知识迁移模块33,用于从所述随机流量子模型获取全连接层输出结果,并将所述全连接层输出结果基于知识迁移的方式输入至所述主流量子模型。
[0064]
在本发明的一种优选实施例中,所述装置还包括:
[0065]
损失函数模块,用于将所述随机流量子模型的交叉熵损失函数与所述主流量子模型的平方损失函数相加,得到所述随机流量子模型的损失函数。
[0066]
在本发明的一种优选实施例中,所述平方损失函数为所述高阶特征与所述随机流量子模型的一层输出结果之差的2范数的平方。
[0067]
在本发明的一种优选实施例中,所述推荐系统的损失函数为根据知识迁移量、所述随机流量子模型的交叉熵损失函数、所述主流量子模型的交叉熵损失函数、训练样本数据的标签、所述随机流量子模型的全连接层输出结果、所述主流量子模型的全连接层输出结果和蒸馏温度生成所得。
[0068]
在本发明的一种优选实施例中,所述全连接层输出结果为软标签结果。
[0069]
在本发明的一种优选实施例中,所述嵌入式特征矩阵包括以下至少之一:交叉特征、广告侧特征、用户侧特征、上下文特征。
[0070]
本发明实施例还提供了一种电子设备,参见图4,包括:处理器401、存储器402以及存储在所述存储器402上并可在所述处理器401上运行的计算机程序4021,所述处理器401执行所述程序4021时实现前述实施例的推荐系统的数据处理方法。
[0071]
本发明实施例还提供了一种可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现前述实施例的推荐系统的数据处理方法。
[0072]
对于装置实施例而言,由于其与方法实施例基本相似,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。
[0073]
本说明书中的各个实施例均采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似的部分互相参见即可。
[0074]
本领域内的技术人员应明白,本发明实施例的实施例可提供为方法、系统、或计算机程序产品。因此,本发明实施例可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明实施例可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
[0075]
本发明实施例是参照根据本发明实施例的方法、终端设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图
中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理终端设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理终端设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
[0076]
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理终端设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
[0077]
这些计算机程序指令也可装载到计算机或其他可编程数据处理终端设备上,使得在计算机或其他可编程终端设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程终端设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
[0078]
尽管已描述了本发明实施例的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例做出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本发明实施例范围的所有变更和修改。
[0079]
最后,还需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者终端设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者终端设备所固有的要素。在没有更多限制的情况下,由语句“包括一个
……”
限定的要素,并不排除在包括所述要素的过程、方法、物品或者终端设备中还存在另外的相同要素。
[0080]
以上对本发明所提供的一种推荐系统的数据处理方法和装置,进行了详细介绍,本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本发明的限制。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1