基于增量简单循环单元和双重注意力的生产瓶颈预测方法与流程
1.本发明涉及一种生产瓶颈预测方法,具体地说是一种基于增量简单循环单元和双重注意力的生产瓶颈预测方法。
背景技术:
2.面对多样的客户需求和激烈的市场竞争,制造企业对提高生产效率、加快生产节拍和强化车间管理提出了更高的要求。生产瓶颈是指制约车间正常生产最严重的生产单元,有效地识别和预测车间生产瓶颈,有助于监控车间实际生产运行情况,及时触发生产决策并为决策方案的制定提供合理的依据,进而提高车间生产效率,保证生产订单按时交付。
3.在复杂离散制造车间中,其生产过程由一系列不连续的生产工序组成,比串行生产线更为复杂,而机器利用率、机器转折点、机器活跃时间等现有的瓶颈量化方法多应用于串行生产线,不足以刻画离散制造车间中的真实瓶颈情况。在传统的瓶颈预测分析中,多数使用时序预测方法,但未考虑各个特征和状态对预测目标的不同影响,随着时间的推移,预测模型的适用性不断下降,以往的研究方法中未涉及模型时效性的研究。
4.鉴于此,本发明设计了一种可供车间生产管理人员使用的基于增量式简单循环单元和双重注意力机制的生产瓶颈预测方法,对于及时触发生产决策、提升车间生产执行能力、保证订单按时交付等具有十分重要的意义。
技术实现要素:
5.发明目的:本发明的目的是针对生产数据转化为知识的效率低、动态决策触发不及时、生产瓶颈预测精度不足等问题,提出了一种基于增量简单循环单元和双重注意力的生产瓶颈预测方法。
6.技术方案:本发明所述的一种基于增量简单循环单元和双重注意力的生产瓶颈预测方法,包括以下步骤:
7.(1)定义工位的综合能力为响应上游工位的物料供应能力和下游工位的物料需求能力之和,以综合能力的大小来量化离散制造车间各工位的生产瓶颈程度;
8.(2)以在制品状态信息、机床状态信息、生产任务组成和各工位瓶颈状态为候选特征,构建适用于生产瓶颈预测的时序关联数据集;
9.(3)采用双层注意力机制的简单循环单元网络进行特征提取,然后连接若干个全连接层挖掘历史数据中瓶颈知识,完成瓶颈预测源模型的构建;
10.(4)采用滑动时间窗和快速霍夫丁概念漂移检测方法发现数据中的概念漂移现象,及时触发源模型的增量更新;
11.(5)挑选合适时间窗的数据集,并采用样本价值遗忘机制对样本赋予不同的价值权重,充分挖掘新数据中蕴含的瓶颈知识,使模型更好的适应新的数据分布;
12.(6)以步骤(5)挑选的数据集和设定的价值权重为基础,采用基于模型的迁移学习思想,使用竞争机制从模型库中选取用于参数更新的源模型,然后对源模型参数进行增量
更新,以获得最新的目标预测模型,并采用淘汰机制判断源预测模型是否过时,以此为依据来更新预测模型库。
13.进一步地,所述步骤(1)实现过程如下:
14.为应对不同特点的制造车间和不同管理者对响应上游工位的物料供应能力和响应下游工位的物料需求能力偏重程度的不同,引入协调因子,以便全面灵活地刻画离散制造车间的生产瓶颈,具体表示如下:
[0015][0016]
其中,反映的是此工位响应上游工位的物料供应能力,反映的是此工位响应下游工位的物料需求能力,w表示入缓存区在制品等待时间,w表示在制品经本工位加工后在其他工位入缓存区中的等待时间,α为协调因子。
[0017]
进一步地,步骤(2)所述的数据集包括如下特征:
[0018]
在制品状态信息:入缓存区在制品类型及其已等待时长、出缓存区在制品类型及其已等待时长、正在加工在制品类型及其已加工时长;
[0019]
机床状态信息:机床所处状态、负载、利用率、上次故障类型、持续加工时长;
[0020]
生产任务组成:总生产任务组成、下次投产批次任务组成、下次投产时间间隔;
[0021]
历史时刻瓶颈值:各工位的响应上游工位物料供应能力和响应下游工位物料需求能力。
[0022]
进一步地,所述步骤(3)实现过程如下:
[0023]
由于输入特征和不同时刻的状态对预测目标的影响程度不同,构建一个全连接层获取各特征重要因子,将特征权重和特征相乘使各特征在瓶颈预测时发挥不同的作用:
[0024]
fw
t
=n*softmax(wfx
t
+bf)
[0025]
其中,fw表示特征权重矩阵,wf表示连接权重,x
t
表示t时刻时序样本对特征进行平均池化后所得数据,bf表示偏置,n表示样本数;
[0026]
采用状态注意力机制融合简单循环单元的多个输出,充分挖掘各状态信息对预测目标的影响,提高预测的准确度:
[0027]
sw=softmax(h
ttht
,h
ttht-1
,
…
,h
ttht-e
)
[0028]
其中,sw表示状态权重矩阵,h
t
表示t时刻状态数据经简单循环单元特征提取后所获得的信息;最后将所构建的瓶颈预测源模型加入模型库,为后续的模型更新提供基础。
[0029]
进一步地,所述步骤(4)实现过程如下:
[0030]
设定固定滑动时间窗长度,计算此时间窗内源模型预测值与真实值之间的平均绝对误差,借助霍夫丁不等式计算概念漂移阈值:
[0031][0032]
其中,εd为概念漂移检测阈值,ai为当前时间窗样本块的预测误差最大值,bi为当前时间窗样本块的预测误差最小值,δ为设定的置信度,n为时间窗大小;若此时间窗样本块
的预测误差与历史时间窗样本块的最小预测误差之差大于预设的阈值,则判断该时间窗的制造数据发生了概念漂移,说明源预测模型不能拟合当前数据的分布规律,亟需触发模型参数增量更新以提高模型的适应度。
[0033]
进一步地,所述步骤(5)实现过程如下:
[0034]
选择当前时间窗以及过去tl个时间窗的制造数据来更新源预测模型,当模型训练收敛时,若当前时间窗测试样本的准确度仍未达到要求,则说明当前分布规律下的数据量较少,不需以支撑预测模型挖掘其内在规律,需等待一个时间窗的制造数据,重新训练模型直至测试精度达到预设标准;同时,不同时间窗的制造数据应用价值不同,引入样本遗忘因子dw来设定样本价值权重,即对于以往时间窗中的制造数据,每往前一个时间窗,其价值损失dw倍。
[0035]
进一步地,所述步骤(6)实现如下:
[0036]
以步骤(5)挑选的制造数据集为输入,从模型库中挑选出预测准确度最高的源模型,若预测准确度相对历史时间窗样本块的最小预测误差未发生概念漂移,则使用该源模型进行后续样本的预测,否则采用基于模型的迁移学习思想,并将步骤(5)设定的样本价值权重引入损失函数,通过adam优化器迭代更新所挑选的源模型参数,获取适应当前分布的目标模型,对充分挖掘当前时间窗数据块的分布规律,准确预测某时刻各工位的综合能力,确定车间生产过程的瓶颈单元;将该目标模型放入模型库中,同时计算挑选的源模型对此时间窗数据块的预测误差与此模型对历史时间窗数据块的最小预测误差之差,若未发生概念漂移,说明源模型已过时,则淘汰此源模型。
[0037]
有益效果:与现有技术相比,本发明的有益效果:1、本发明根据离散制造车间特点,结合供求关系,重新定义和量化了生产瓶颈,全面有效地描述了制约车间正常生产最严重的制造单元,为车间性能分析提供了可靠的依据;2、相比于现有方法,本发明在简单循环单元网络中引入特征注意力机制和状态注意力机制,有效地提高了生产瓶颈预测模型的准确度;3、预测模型的适用度会随着时间的推移而下降,本发明采用了概念检测方法来触发模型更新、选择合适的数据和设置样本价值权重来支撑模型更新、使用竞争机制挑选源模型、基于迁移学习的思想来实现模型更新、采取淘汰机制更新模型库,保证预测模型对当前数据样本仍具有较高的预测准确度和模型库的时效性;4、本发明为离散制造车间状态监控、性能分析、智能决策提供了依据,有助于提升制造车间的智能化生产水平。
附图说明
[0038]
图1为本发明的流程图;
[0039]
图2是本发明的基于迁移学习的瓶颈预测模型增量更新过程示意图。
具体实施方式
[0040]
下面结合附图对本发明做进一步详细说明。
[0041]
本发明提出一种基于增量简单循环单元和双重注意力的生产瓶颈预测方法,将制造工位类比于供应连中的中间商,应及时响应上游工位的物料供应和下游工位的物料需求,综合这两类因素,定义了工位的综合能力来描述此工位的瓶颈程度;使用双重注意力机制以区分不同特征和不同状态对预测目标的重要程度;引入滑动时间窗和快速霍夫丁概念
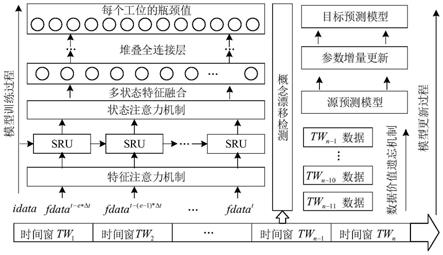
漂移技术,及时触发模型的动态更新;制造车间的生产数据应用价值不同,选取合适的新增数据并设定样本权重,以此为基础,通过竞争机制从模型库挑选最适用当前分布的源模型,然后采用基于模型的迁移学习进行模型参数的增量更新,保证预测模型能够准确地挖掘当前制造数据所蕴含的知识并使预测模型始终维持着较高的预测准确度,并通过淘汰机制更新模型库,使模型库中的预测模型始终维持着较高的适用性,如图1所示,具体包括以下步骤:
[0042]
步骤1:定义某工位的综合能力为响应上游工位的物料供应能力和下游工位的物料需求能力之和,以综合能力的大小来量化离散制造车间各工位的生产瓶颈程度。
[0043]
在制造环节多、生产过程不连续和生产工艺复杂的离散制造车间中,将每个工位视为整个生产过程的中间环节,需要及时响应上游工位的物料供应,还需满足下游工位的物料需求。
[0044]
工位的综合能力为响应上游工位的物料供应能力与下游工位的物料需求能力之和。为应对不同特点的制造车间和不同管理者对两者偏重程度不同的问题,引入协调因子,以便全面灵活地刻画离散制造车间的生产瓶颈,具体表示如下:
[0045][0046]
其中,反映的是此工位响应上游工位的物料供应能力,反映的是此工位响应下游工位的物料需求能力,w表示入缓存区在制品等待时间,w表示在制品经本工位加工后在其他工位入缓存区中的等待时间,α表示协调因子。
[0047]
步骤2:以在制品状态信息、机床状态信息、生产任务组成和各工位瓶颈状态为候选特征,构建适用于生产瓶颈预测的时序关联数据集。
[0048]
在制品状态信息ws:入缓存区在制品类型及其已等待时长、出缓存区在制品类型及其已等待时长、正在加工在制品类型及其已加工时长。
[0049]
机床状态信息ms:机床所处状态、负载、利用率、上次故障类型、持续加工时长
[0050]
生产任务组成ps:总生产任务组成、下次投产批次任务组成、下次投产时间间隔
[0051]
历史时刻瓶颈值ic:各工位的响应上游工位物料供应能力和响应下游工位物料需求能力。
[0052]
根据简单循环单元的输入特点,每条训练样本由e+1个时刻的数据构成,其中每个数据的时间间隔差为
△
t,具体表示形式如下:
[0053][0054]
其中,idata
t
表示t时刻的输入样本,i表示工位号,n表示工位数,e表示是从此刻向过去看的最大时间间隔数,
△
t表示设定的时间间隔,此样本的标签为各个工位在t+
△
t时刻的瓶颈值。
[0055]
步骤3:采用特征注意力机制对输入特征进行加权,然后输入至简单循环单元完成
时序特征提取,引入状态注意力机制对提取的状态特征进行重要性评估,综合各状态特征并将其输入若干层全连接层,获得生产瓶颈预测源模型,并将其放入模型库中,实现生产瓶颈的精准预测和形成初始模型库。
[0056]
将候选特征集输入至一个全连接层网络,经过softmax变换后放大n倍得到特征权重,权重与对应特征相乘以实现特征注意力机制,充分发挥重要特征充的作用;以加权后的特征为输入,构建简单循环单元挖掘数据中隐藏的时序信息,并借助状态注意力机制融合各状态信息,将其输入至若干层的全连接层中,借助均方误差和l2正则化计算梯度损失,实现生产瓶颈的精准预测,同时将获得的预测模型放入模型库中,形成初始模型库。
[0057]
由于输入特征和不同时刻的状态对预测目标的影响程度不同,构建一个全连接层获取各特征重要因子,将特征权重和特征相乘使各特征在瓶颈预测时发挥不同的作用,具体表示如下式:
[0058]
fw
t
=n*softmax(wfx
t
+bf)
[0059]
其中,fw表示特征权重矩阵,wf表示连接权重,bf表示偏置,x
t
表示t时刻时序样本对特征进行平均池化后所得数据,n表示样本数。同样,采用状态注意力机制融合简单循环单元的多个输出,充分挖掘各状态信息对预测目标的影响,提高预测的准确度,具体表示如下式:
[0060]
sw=softmax(h
ttht
,h
ttht-1
,
…
,h
ttht-e
)
[0061]
其中,sw表示状态权重矩阵,h
t
表示t时刻状态数据经简单循环单元特征提取后所获得的信息。最后将所训练的预测模型加入模型库,为后续的模型更新提供基础。
[0062]
步骤4:采用滑动时间窗和快速霍夫丁概念漂移检测方法发现数据中的概念漂移现象,及时触发源模型的增量更新。
[0063]
设定固定滑动时间窗长度,计算此时间窗内源模型预测值与真实值之间的平均绝对误差,借助霍夫丁不等式计算概念漂移阈值:
[0064][0065]
其中,εd为概念漂移检测阈值,ai为当前时间窗样本块的预测误差最大值,bi为当前时间窗样本块的预测误差最小值,δ为设定的置信度,n为时间窗大小;若此时间窗样本块的预测误差与历史时间窗样本块的最小预测误差之差大于预设的阈值,则判断该时间窗的制造数据发生了概念漂移,说明源预测模型不能拟合当前数据的分布规律,亟需触发模型参数增量更新以提高模型的适应度。
[0066]
步骤5:挑选合适时间窗的数据集,并采用样本价值遗忘机制对样本赋予不同的价值权重,充分挖掘新数据中蕴含的瓶颈知识,使模型更好的适应新的数据分布。
[0067]
选择当前时间窗以及过去tl个时间窗的制造数据来更新源预测模型,当模型训练收敛时,若当前时间窗测试样本的准确度仍未达到要求,则说明当前分布规律下的数据量较少,不需以支撑预测模型挖掘其内在规律,需等待一个时间窗的制造数据,重新训练模型直至测试精度达到预设标准。同时,不同时间窗的制造数据应用价值不同,引入样本遗忘因子dw来设定样本价值权重,即对于以往时间窗中的制造数据,每往前一个时间窗,其价值损失dw倍。
[0068]
预测模型需在保留历史数据中旧知识的同时学习新增数据中隐含的新知识,选取当前时间窗数据块和之前的tl个时间窗数据块来更新模型参数。制造数据越接近当前时间窗价值越高,引入遗忘因子(比如0.95),每往前一个时间窗,数据价值减少0.95倍,计算样本权重dw,具体表示形式如下:
[0069]
dwi=0.95
i i∈{0,1,2,
…
tl}
[0070]
若检测到更新后的预测模型对当前时间窗测试样本的预测误差与λ
min
之差大于阈值,说明模型适用性未能得到有效提高,换而言之,用于拟合当前数据分布规律的样本过少,需往后等待一个时间窗以获取更多此分布下的数据样本,再次更新预测模型,使预测模型对当前分布下的制造数据仍具有较高的适用性
[0071]
步骤6:以步骤(5)挑选的数据集和设定的价值权重为基础,采用基于模型的迁移学习思想,使用竞争机制从模型库中选取用于参数更新的源模型,然后对源模型参数进行增量更新,以获得最新的目标预测模型,并采用淘汰机制判断源预测模型是否过时,以此为依据来更新预测模型库。
[0072]
从源模型中挑选出最适合当前分布的源模型,若相对历史时间窗数据块最小预测误差未发生概念漂移,则以此模型为目标模型,否则以步骤(5)选取的制造数据和样本价值权重dw为基础,将挑选出来的源预测模型前若干层权重和偏置迁移至目标预测模型,借助iloss(如下式所示)和adam优化器更新网络参数,获取用于适合当前数据分布的生产瓶颈预测模型,如图2所示:
[0073][0074]
其中,tn表示样本数,表示j样本的实际值,表示j样本的预测值,γ表示l2正则化系数,w表示网络参数。
[0075]
将得到的预测模型放入模型库中,并根据源预测模型在此时间窗内的预测误差相对于源模型历史最小预测误差之差,判断是否发生概念漂移,如发生,说明此时间窗数据与训练此模型的历史数据分布不一致,应保留源模型,若未发生,说明两类数据的分布是一致的,源模型和目标模型作用相同,而此源模型的预测精度较低,应淘汰源模型。以当前时刻的候选特征集为输入,即可得到未来某时刻车间的生产瓶颈。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1