一种基于注意力机制的情感原因提取方法与流程
1.本技术涉及情感分析技术领域,尤其涉及一种基于注意力机制的情感原因提取方法。
背景技术:
2.随着大数据时代的到来,全球正面临着史无前例信息井喷式增长的挑战,互联网信息处理技术也迎来高速发展。如何准确、及时和有效的获取互联网短文本的情感信息是社会和谐稳定有序发展前进的动力,具有重要的价值意义。但是互联网短文本具有自由、灵活且缺乏规范性等特点,且其中的情感信息受时间、地点、环境以及人物触发情绪场景的影响。这些都使得传统的文本序列标注方法对情感要素识别的难度增大。
3.相关技术中常见的文本情感原因提取的方法有三种,一种是基于规则的文本情感原因提取的方法。该方法是最早的文本情感原因提取方法,先通过构建情感词典或设计情感模板,然后对比分析计算情感词或情感模板实现文本情感分类,文本情感信息是否准确提取由情感词典或模板的完备程度决定。相关人员利用点互信息扩充基础词汇表,然后挖掘文本情感表达的褒贬词实现文本情感分类。相关人员利用情感词典分析词的情感倾向,然后计算该文本中情感词的密度、广度和情感强度等特征,综合这些特征进行文本分类。基于规则的文本情感原因提取方法虽然灵活方便,但是容易丢失文本的隐藏信息。
4.第二种是基于机器学习的文本情感原因提取方法。该方法主要通过对带标签的语料进行人工建模实现情感原因提取,然后利用机器学习算法实现文本情感分类。相关人员首先提取文本中不同属性的词作为特征,然后使用信息增益、文档频率、chi统计量和互信息等多种特征选择方法选择文本情感原因,并对比分析中心向量法、贝叶斯分类法、knn和svm四种机器学习方法的实验效果,从而得出特征选择方法和机器学习方法的最优组合。基于机器学习的文本情感原因提取方法通常基于人工设计的原因提取方法,这种方法不但费时费力,而且模型泛化能力较差。
5.第三种基于深度学习的文本情感原因提取的方法。该方法利用神经网络自主学习提取文本特征,且神经网络的多层非线性结构可以捕捉文本深层次的特征,从而实现对文本的深层次理解,克服了机器学习的缺陷。相关人员采用递归神经网络,对句子进行句法分析实现影评文本情感分类。相关人员采用长短期记忆网络模型,输入词序列,捕捉文本中词序列间的隐藏信息。相关人员提出基于卷积神经网络的分类模型,对文本的多种局部空间特征进行自动提取。深度学习在文本情感分析中的应用表现出了较佳的效果,但其发展也受限于数据集种类太少。
6.针对上述相关技术,发明人认为,相关技术中对文本情感分析大多只停留在极性分类等表层分析,对文本情感事件根本原因却未能很好的识别出来,尤其对在情感分析领域的情感原因提取效果不够显著。
技术实现要素:
7.为了增强在情感分析领域中情感原因的提取效果,本技术提供一种基于注意力机制的情感原因提取方法。
8.一种基于注意力机制的情感原因提取方法,包括:获取数据集,使用bert模型获取词嵌入矩阵;基于所述词嵌入矩阵搭建模型;使用lstm模型所获取的词向量矩阵进行多轮训练后,获取情感子句隐藏层状态和候选子句隐藏层状态;使用全连接层连接softmax对所述情感子句隐藏层状态和所述候选子句隐藏层状态进行分类后,获取情感原因提取结果并输出所述情感原因提取结果。
9.通过采用上述技术方案,使用bert从文本数据中提取特征,获得词嵌入矩阵,相较相关技术中的词嵌入模型,bert生成的单词表示由其周围的单词动态生成,因此可作为双向lstm的高质量特征输入;将提取到的情感子句特征和候选子句特征分别参与对方的注意力机制,可以更好的建模情感子句和候选子句之间的关系,使得对情感分析领域中情感原因具有更加显著的提取效果。
10.可选的,获取数据集,使用bert获取高质量的词嵌入矩阵的具体步骤包括:按照预设的格式输入数据集;通过tokenizer将原始单词拆分成子词和字符;调用tokenizer,并使用tokenizer词汇表中的索引与所述子词和字符进行匹配;获取隐藏层状态,并将所述隐藏层状态存储在encoded_layers中;从隐藏层状态中创建单词和句子向量。
11.通过采用上述技术方案,将原始单词拆分成子词和字符后与tokenizer词汇表中的索引进行匹配,能够得到更精准的特征表示,同时也解决了多义词的问题,从而有助于增强在情感分析领域中情感原因的提取效果。
12.可选的,搭建模型的具体步骤包括:获取情感子句隐藏层状态以及原因子句隐藏层状态,并将所述情感子句隐藏层状态和所述原因子句隐藏层状态进行平均池化;使用注意力机制计算注意力权重;获取基于注意力向量的情感子句表征和候选子句表征;使用cnn获取局部上下文特征,通过多次卷积并从中获取全局特征向量。
13.通过采用上述技术方案,平均池化能减小邻域大小受限造成的估计值方差增大问题,且能更多的保留图像的背景信息。
14.可选的,获取情感子句隐藏层状态以及原因子句隐藏层状态,并将所述情感子句隐藏层状态和所述原因子句隐藏层状态进行平均池化的具体操作步骤包括:使用两个双向lstm获得情感子句隐藏层状态和候选子句隐藏层状态,状态参数更新的函数公式如下:
该公式中,k为上下文中的单词索引;i、f、o为输入门、遗忘门和输出;σ为激活函数;w和b分别为权重矩阵和偏重;为元素级乘法;得到候选子句隐藏层状态[h
c1
,h
c2
,
…
,h
cn
]和情感子句隐藏层状态[h
e1
,h
e2
,
…
,h
em
];对情感子句和候选子句隐藏层状态进行平均池化后,得到情感子句隐藏层状态平均池化值c
avg
和候选子句隐藏层状态平均池化值e
avg
:其中,n为候选子句隐藏层状态个数,m为情感子句隐藏层状态个数。
[0015]
通过采用上述技术方案,能够更加精准的获得情感子句隐藏层状态和候选子句隐藏层状态,从而有助于增强在情感分析领域中情感原因的提取效果。
[0016]
可选的,使用注意力机制计算注意力权重具体步骤包括:通过注意力机制生成情感子句注意力向量αi和候选子句注意力向量和βi;该公式中,γ为得分函数,用于计算h
ic
在上下文中的重要性,wa和ba为注意力矩阵和偏重,tanh为非线性函数。
[0017]
通过采用上述技术方案,注意力机制,可以更好的关注一句话中的某些词,有助于
抓住提取重点,从而有助于增强在情感分析领域中情感原因的提取效果。
[0018]
可选的,获取基于注意力向量的情感子句表征和候选子句表征的具体步骤包括:控制情感子句隐藏层状态和候选子句隐藏层状态结合注意力权重,并得到基于注意力向量的情感子句cr和候选子句er,cr和er满足以下公式:。
[0019]
通过采用上述技术方案,结合注意力权重,能够将注意力集中在相关性更高的字词上,提高子句特征提取的效果,有助于抓住提取重点,从而有助于增强在情感分析领域中情感原因的提取效果。
[0020]
可选的,使用cnn获取局部上下文特征,通过多次卷积并从中获取全局特征向量的具体步骤包括:通过词产生特征f
tγ
,如下式:该公式中,w
γ
∈r
2kγ
(γ=2,3,4)为过滤器,b
γ
是一个偏置,tanh(
·
)是非线性双曲正切函数;将所述过滤器应用于每一个可能的候选子句词表征窗口来产生特征向量,如下所示:其中,f
γ
∈r
n-γ+1
;通过使用γ宽度的m个过滤器来生成特征映射:其中,;重复以上步骤计算得到情感子句的特征映射;对卷积层获得的进行平均池化获得子句高水平的表征,如下式所示:其中,,,是平均池化。
[0021]
通过采用上述技术方案,通过多次卷积,以获取更精准的结果,从而有助于增强在情感分析领域中情感原因的提取效果。
[0022]
可选的,使用lstm模型所获取的词向量矩阵进行多轮训练后,获取情感子句隐藏层状态和候选子句隐藏层状态的具体步骤包括:训练所构建模型并获取训练数据集上最小化的交叉熵损失;两个双向lstm模型对情感子句和候选子句进行编码;使用cnn生成标签的概率分布并训练一定的迭代次数后,返回更新后的模型参数θ。
[0023]
通过采用上述技术方案,最小化的交叉熵损失,分类效果越好,模型拟合就越好,两个双向lstm模型有助于解决长序列训练过程中的梯度消失和梯度爆炸问题。
[0024]
可选的,使用全连接层连接softmax对所述隐藏层状态和所述候选子句隐藏层状态进行分类后,获取情感原因提取结果并输出所述情感原因提取结果的具体步骤包括:将情感子句ce和候选子句c特征表示为和,全连接层根据池化特征对所有可能的标签进行评分,得到得分向量:其中,分别是权重矩阵和偏置向量,是全连接层的输出;softmax函数对得分向量的每一个元素进行计算,获得每一个标签的概率:其中l={0,1}是一组标签(1表示是其原因,0表示否),|l|表示标签个数,是参数集合。
[0025]
通过采用上述技术方案,softmax函数对全连接层输出的每个类别的概率归一化到(0,1)区间内,从而进行分类,更有利于后续的计算,有助于清楚、方便地得出情感原因提取结果。
[0026]
综上所述,本技术包括以下至少一种有益技术效果:使用bert从文本数据中提取特征,获得词嵌入矩阵,相较相关技术中的词嵌入模型,bert生成的单词表示由其周围的单词动态生成,因此可作为双向lstm的高质量特征输入;将提取到的情感子句特征和候选子句特征分别参与对方的注意力机制,可以更好的建模情感子句和候选子句之间的关系,使得对情感分析领域中情感原因具有更加显著的提取效果。
附图说明
[0027]
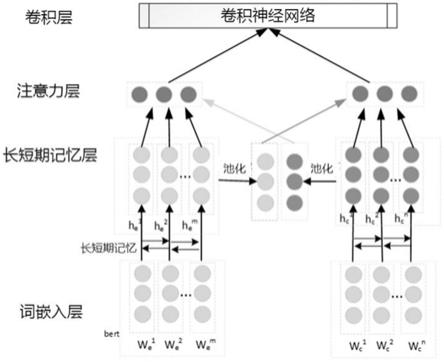
图1是本技术实施例一种基于注意力机制的情感原因提取方法的主要流程框图;图2是本技术实施例一种基于注意力机制的情感原因提取方法中的情感原因提取模型结构图;
brown fox!" 分割为 [quick, brown, fox!]。
[0037]
该 tokenizer还负责记录各个词条的顺序或位置(用于短语和词近邻查询),以及词条所代表的原始单词的起始和结束的字符偏移量。
[0038]
步骤s140:获取隐藏层状态,并将所述隐藏层状态存储在encoded_layers中;其中,encoded_layers为编辑层,其包括四个维度:层数、batch_size(每批数据量的大小)、令牌号以及隐藏单元;步骤s150:从隐藏层状态创建单词和句子向量。
[0039]
其中,从隐藏层状态创建单词和句子向量能够更好的对文本进行线性划分,从而能够得到更精准的特征表示。
[0040]
步骤s200的具体操作步骤包括s210~s240,步骤s210:获取情感子句隐藏层状态以及原因子句隐藏层状态,并将所述情感子句隐藏层状态和所述原因子句隐藏层状态进行平均池化;首先,使用两个双向lstm获得情感子句隐藏层状态和候选子句隐藏层状态,且其状态参数更新如下:该公式中,k为上下文中的单词索引;i、f、o是输入门、遗忘门和输出;σ是激活函数;w和b分别是权重矩阵和偏重;是元素级乘法;然后,得到候选子句隐藏层状态[h
c1
,h
c2
,
…
,h
cn
]和情感子句隐藏层状态[h
e1
,h
e2
,
…
,h
em
];最后,对情感子句和候选子句隐藏层状态进行平均池化后,得到情感子句隐藏层状态平均池化值c
avg
和候选子句隐藏层状态平均池化值e
avg
:。
[0041]
其中,n为候选子句隐藏层状态个数,m为情感子句隐藏层状态个数。
[0042]
步骤s220:使用注意力机制计算注意力权重;通过注意力机制生成情感子句注意力向量αi和候选子句注意力向量和βi;
γ是得分函数,通过计算h
ic
在上下文中的重要性,wa和ba是注意力矩阵和偏重,tanh是非线性函数。
[0043]
步骤s230:获取基于注意力向量的情感子句表征和候选子句表征;其中,情感子句表征和候选子句表征是通过情感子句隐藏层状态和候选子句隐藏层状态交互参与对方注意力机制计算得到的。
[0044]
控制情感子句隐藏层状态和候选子句隐藏层状态结合注意力权重,并得到基于注意力向量的情感子句cr和候选子句er,cr和er满足以下公式:。
[0045]
参照图1、图2和图4,步骤s240:使用cnn获取局部上下文特征,通过多次卷积并从中获取全局特征向量;其中,全局特征向量是通过多个局部特征形成的;cnn:卷积神经网络(convolutional neural networks, cnn)是一类包含卷积计算且具有深度结构的前馈神经网络,是深度学习的代表算法之一。卷积神经网络具有表征学习能力,能够按其阶层结构对输入信息进行平移不变分类,因此也被称为“平移不变人工神经网络”;通过词产生特征f
tγ
,如下式:该公式中,w
γ
∈r
2kγ
(γ=2,3,4)为过滤器,b
γ
是一个偏置,tanh(
·
)是非线性双曲正切函数;将所述过滤器应用于每一个可能的候选子句词表征窗口来产生特征向量,如下所示:
其中,f
γ
∈r
n-γ+1
;通过使用γ宽度的m个过滤器来生成特征映射:其中,;重复以上步骤计算得到情感子句的特征映射;对卷积层获得的进行平均池化获得子句高水平的表征,如下式所示:其中,,,是平均池化。
[0046]
步骤s300的具体操作步骤包括s310~s330;步骤s310:训练所构建模型并获取训练数据集上最小化的交叉熵损失;步骤s320:两个双向lstm模型对情感子句和候选子句进行编码;步骤s330:使用cnn生成标签的概率分布并训练一定的迭代次数后,返回更新后的模型参数θ;其中,模型参数θ是自动更新和自动优化的。
[0047]
步骤s400的具体操作步骤包括:将情感子句ce和候选子句c特征表示为和,全连接层根据池化特征对所有可能的标签进行评分,得到得分向量:其中,分别是权重矩阵和偏置向量,是全连接层的输出;softmax函数对得分向量的每一个元素进行计算,获得每一个标签的概率:其中l={0,1}是一组标签(1表示是其原因,0表示否),|l|表示标签个数,是参数集合。
[0048]
例如,当获取到“我很开心”时,输出情感原因提取结果为“开心”;当获取到“他很难过”时,输出情感原因提取结果为“难过”;当获取到“孩子的出生给一家人带来了无尽的喜悦和欢乐”时,输出情感原因提取结果为“喜悦和欢乐”。
[0049]
本技术实施例一种基于注意力机制的情感原因提取方法的实施原理为:获取数据
集,使用bert模型获取词嵌入矩阵,根据获得词嵌入矩阵搭建模型,使用lstm模型对词嵌入矩阵进行多轮训练后得到情感子句隐藏层状态以及候选子句隐藏层状态,全连接层连接softmax进行分类,获得情感原因提取结果并输出该结果。
[0050]
以上均为本技术的较佳实施例,并非依此限制本技术的保护范围,故:凡依本技术的结构、形状、原理所做的等效变化,均应涵盖于本技术的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1