一种基于图神经网络的习题文本相似度检测方法和装置与流程
本技术涉及文本及语义识别,具体来说,本技术涉及一种基于图神经网络的习题文本相似度检测方法和装置。
背景技术:
1、文本相似度,即计算两个文本之间的字面或者语义上的相似性,其作为自然语言处理领域中的常用算法,在如互联网+教育场景等相关应用场景下有着重要的应用。目前常见的文本相似度的算法主要分为两大类,基于字符的字面匹配和基于词向量的语义匹配。基于字面匹配一般忽略了上下文的语序,根据输入的文本字符的相似度进行判断,其更多考虑整篇文章的整体结构;基于词向量更多应用在短文本的相似度上,首先将每个词通过训练模型得到对应词向量,然后将每个词向量依照语序聚合起来得到整个文本的语义信息,最后再计算两个文本之间的距离。
2、然而上述方法存在一定的局限性。基于字面匹配一般更多关注句子中整体的信息,却往往忽略词与词之间的相对位置,因而更多用在主题抽取中,此外由于字面匹配并没有考虑语义方面的信息,对近义词和同义词方面并没有进行特殊的处理,因而效果往往较差。而对于词向量算法,一方面它的输入会根据语序进行,因而对更多会关注于局部而非整体,其资源的消耗远超于字面的匹配,推理速度也略低于基于字面的算法,但其效果不一定更好;同时,尽管基于词向量的方法能够从语义层面上进行解析,但在长文本中,由于文章的信息量足够多,而且引入语义的信息也会引入一定的误差传递,从而导致准确率的下降。
技术实现思路
1、基于上述技术问题,本发明基于消息传递框架搭建多级图神经网络模型,所述多级图神经网络包括一级图神经网络至z级图神经网络,其中,z为大于1的自然数,且前一级图神经网络的输出作为下一级图神经网络的输入,这样消息传递所传递的是结点和邻居的边的权重,使最后得到的向量既包含习题文本的局部信息又包含全局信息。两个或多个习题文本都经过多级图神经网络处理得到的向量再求二者的余弦距离,得到两个或多个习题文本相似度。
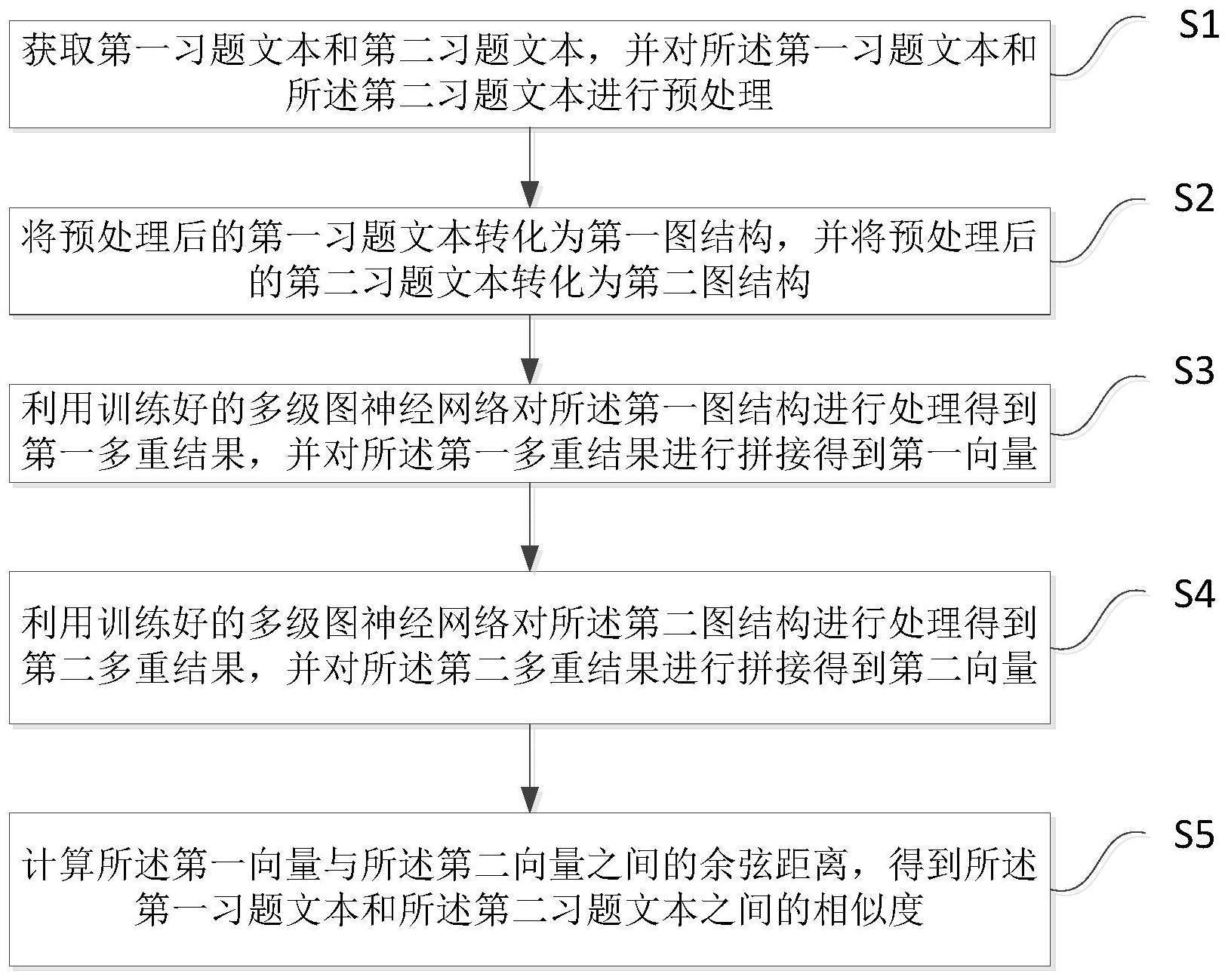
2、本发明第一方面提供了一种基于图神经网络的习题文本相似度检测方法,所述方法包括:
3、获取第一习题文本和第二习题文本,并对所述第一习题文本和所述第二习题文本进行预处理;
4、将预处理后的第一习题文本转化为第一图结构,并将预处理后的第二习题文本转化为第二图结构;
5、利用训练好的多级图神经网络对所述第一图结构进行处理得到第一多重结果,并对所述第一多重结果进行拼接得到第一向量;
6、利用训练好的多级图神经网络对所述第二图结构进行处理得到第二多重结果,并对所述第二多重结果进行拼接得到第二向量;
7、计算所述第一向量与所述第二向量之间的余弦距离,得到所述第一习题文本和所述第二习题文本之间的相似度。
8、优选地,所述获取第一习题文本和第二习题文本,并对所述第一习题文本和所述第二习题文本进行预处理,包括:
9、获取第一习题文本和第二习题文本;
10、将所述第一习题文本和所述第二习题文本中的无效文本去除;
11、对去除无效文本后的第一习题文本和第二习题文本进行文本归一化。
12、具体地,所述多级图神经网络包括一级图神经网络至z级图神经网络,其中,z为大于1的自然数,且前一级图神经网络的输出作为下一级图神经网络的输入。
13、再具体地,所述利用训练好的多级图神经网络对所述第一图结构进行处理得到第一多重结果,并对所述第一多重结果进行拼接得到第一向量,包括:
14、获取结点特征向量步骤,将所述第一图结构输入训练好的一级图神经网络,得到所述第一图结构中每一个结点的特征向量;
15、获取邻居结点特征向量步骤,获取每一个结点的邻居结点的特征向量;
16、汇总步骤,对所述每一个结点的邻居结点的特征向量进行汇总;
17、局部信息得到步骤,基于汇总后特征向量对第一图结构中所有结点进行更新,得到所述第一图结构的局部信息;
18、二级图神经网络步骤,将所述第一图结构的局部信息输入训练好的二级图神经网络,按照前述获取结点特征向量步骤和获取邻居结点特征向量步骤执行,直至z级神经网络输出第一多重结果;
19、拼接步骤,对所述第一多重结果进行拼接得到第一向量。
20、再具体地,对所述每一个结点的邻居结点的特征向量进行汇总,公式为:
21、
22、其中,t和t-1表示下一级神经网络和上一级神经网络,n表示当前结点,n表示n的所有邻居结点,a表示n的任一邻居结点,ean表示n与a之间边的权重,表示上一级神经网络的输出向量。
23、进一步地,所述基于汇总后特征向量对第一图结构中所有结点进行更新,公式为:
24、
25、其中,gru表示gru循环神经网络,表示对所述每一个结点的邻居结点的特征向量进行汇总的汇总结果,表示上一级神经网络的输出向量。
26、进一步优选地,在各实施方式中的所述方法还包括:在得到所述第一多重结果和所述第二多重结果之前还包括对每一级神经网络的输出结果进行注意力机制处理,将处理后的输出结果全部拼接在一起分别得到所述第一多重结果和所述第二多重结果。
27、进一步优选地,,所述进行注意力机制处理的公式为:
28、
29、
30、
31、其中,其中,tanh表示激活函数,tit和表示中间变量,i和j表示第i个和第j个结点,υt表示上下文的一个随机初始化值,表示训练参数,表示结点权重,ut表示注意力机制处理得到的加权和。
32、本发明第二方面提供了一种基于图神经网络的习题文本相似度检测装置,所述装置包括:
33、第一单元,用于获取第一习题文本和第二习题文本,并对所述第一习题文本和所述第二习题文本进行预处理;
34、第二单元,用于将预处理后的第一习题文本转化为第一图结构,并将预处理后的第二习题文本转化为第二图结构;
35、第三单元,用于利用训练好的多级图神经网络对所述第一图结构进行处理得到第一多重结果,并对所述第一多重结果进行拼接得到第一向量;
36、第四单元,用于利用训练好的多级图神经网络对所述第二图结构进行处理得到第二多重结果,并对所述第二多重结果进行拼接得到第二向量;
37、第五单元,用于计算所述第一向量与所述第二向量之间的余弦距离,得到所述第一习题文本和所述第二习题文本之间的相似度。
38、本发明第三方面提供了一种计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现以下步骤:
39、获取第一习题文本和第二习题文本,并对所述第一习题文本和所述第二习题文本进行预处理;
40、将预处理后的第一习题文本转化为第一图结构,并将预处理后的第二习题文本转化为第二图结构;
41、利用训练好的多级图神经网络对所述第一图结构进行处理得到第一多重结果,并对所述第一多重结果进行拼接得到第一向量;
42、利用训练好的多级图神经网络对所述第二图结构进行处理得到第二多重结果,并对所述第二多重结果进行拼接得到第二向量;
43、计算所述第一向量与所述第二向量之间的余弦距离,得到所述第一习题文本和所述第二习题文本之间的相似度。
44、本发明第四方面提供了一种计算机程序产品,包括计算机程序,该计算机程序被处理器执行时实现以下步骤:
45、获取第一习题文本和第二习题文本,并对所述第一习题文本和所述第二习题文本进行预处理;
46、将预处理后的第一习题文本转化为第一图结构,并将预处理后的第二习题文本转化为第二图结构;
47、利用训练好的多级图神经网络对所述第一图结构进行处理得到第一多重结果,并对所述第一多重结果进行拼接得到第一向量;
48、利用训练好的多级图神经网络对所述第二图结构进行处理得到第二多重结果,并对所述第二多重结果进行拼接得到第二向量;
49、计算所述第一向量与所述第二向量之间的余弦距离,得到所述第一习题文本和所述第二习题文本之间的相似度。
50、本发明第五方面提供了一种计算机设备,包括存储器和处理器,所述存储器中存储有计算机可读指令,所述计算机可读指令被所述处理器执行时,使得所述处理器执行以下步骤:
51、获取第一习题文本和第二习题文本,并对所述第一习题文本和所述第二习题文本进行预处理;
52、将预处理后的第一习题文本转化为第一图结构,并将预处理后的第二习题文本转化为第二图结构;
53、利用训练好的多级图神经网络对所述第一图结构进行处理得到第一多重结果,并对所述第一多重结果进行拼接得到第一向量;
54、利用训练好的多级图神经网络对所述第二图结构进行处理得到第二多重结果,并对所述第二多重结果进行拼接得到第二向量;
55、计算所述第一向量与所述第二向量之间的余弦距离,得到所述第一习题文本和所述第二习题文本之间的相似度。
56、本技术的有益效果为:本技术所述方法基于消息传递框架搭建多级图神经网络模型,所述多级图神经网络包括一级图神经网络至z级图神经网络,其中,z为大于1的自然数,且前一级图神经网络的输出作为下一级图神经网络的输入,这样消息传递所传递的是结点和邻居的边的权重,使最后得到的向量既包含习题文本的局部信息又包含全局信息。两个或多个习题文本都经过多级图神经网络处理得到的向量再求二者的余弦距离,得到相似度,得到的相似度更为精准,进而提升了习题文本之间比较的效率和精度。
- 还没有人留言评论。精彩留言会获得点赞!