一种调令员和受令员语音交互作业对话分类方法与流程
1.本发明属于自然语言处理的文本分类技术,尤其涉及一种基于lstm和attention机制的调令员和受令员语音交互作业对话分类方法。
背景技术:
2.电力系统调度员是指电力系统运行的监视、指挥与控制者。调度员按照规定的调度范围行使指挥权,指挥的对象为下一级调度机构的值班调度员,发电厂值长和变电所值班长。调度员的主要职责是保证电力系统安全经济运行,向用户供应可靠的、符合质量标准的所需电力、电能和热能。调度员一般分为调令员和受令员两种,调令员发出指令由受令员来执行,调令员和受令员调度交互过程要合理,过程要标准化,防止调度员发生遗漏、误报等错误。因此,调令员和受令员语音交互作业是否规范是电网员工的重要考核内容,影响电力系统调度员的合格性评估,进而影响选拔、任用、续用等方面人事管理工作。
3.调令员和受令员语音交互作业过程就是一段多轮对话问题,交互作业过程是否规范问题就可以转化成多轮对话的分类问题,通过语音转写工具将语义交互作业过程翻译成文本,然后就变成了文本形式的多轮对话。文本形式多轮对话分类就解决了调令员和受令员交互作业过程是否标准的判断问题。多轮对话分类将对话上下文作为输入预测整轮对话的意图,理解整段对话的语义信息,对模型的分类能力要求更高,应用场景也更加丰富多样。
4.在多轮对话分类任务中,当前的研究工作往往倾向于直接将常见的文本分类模型应用到将多轮对话文本任务中。这些模型处理整个会话文本的通用方法包括简单的将多个句子被拼接成一个长序列作为模型输入以及根据多轮对话文本的层次结构(句子级别和单词级别)进行编码,提取特征并分类。
5.已有工作忽略了多轮对话文本的自身特点,不考虑多轮对话句子与句子之间的时序因素,同时,与常见的文本分类任务所使用的数据相比,调令员和受令员语音交互作业过程文本是语音翻译过来,包含更多的噪音文字,同时在内容上也会包含很多打招呼、寒暄以及身份确认等过程,此类过程和调度标准过程是无关的干扰信息。因此,如果简单地将其视为普通文本进行编码,则会在模型的学习过程中引入过多的噪声且忽略了时序的因素,影响模型最终的分类效果。
技术实现要素:
6.本发明要解决的技术问题是:提供一种调令员和受令员语音交互作业对话分类方法,解决现有模型的学习过程中引入过多的噪声且忽略了时序的因素,影响模型最终的分类效果等技术问题。
7.本发明技术方案:
8.一种调令员和受令员语音交互作业对话分类方法,其特征在于:所述方法为:利用lstm的时序学习能力分时刻编码对话文本,然后接着使用attention机制将每个时刻的向
量表示进行融合得到当前对话的向量表示,最后将向量输入分类器进行分类。
9.它包括:数据预处理:对原始数据集采取去除停用词、去除标点符号、不可见字符和去除低频词预处理操作,需要将原始数据集表示成数字形式;采用文本词语的tf-idf权重的形式将对话文本的数字化表示。
10.模型构建训练:它具体包括:
11.对调令员和受令员语音交互文本对话定义如下:分类数据集中涉及到的所有对话文本的唯一标识符组成集合u;对于u中的每一个对话ui,对话中调令员和受令员说的每一段话表示为一个时空序列ti,序列ti中的每一个元素均包含一个时间点k和调令员和受令员说的某一段话;
12.对于ti中的每个元素均使用二维向量来作为该点的表示向量,并按顺序将输入第k个lstm单元中。对于第k个lstm单元,其监督数据为
13.lstm内部迭代公式如下:
14.遗忘门部分:
[0015][0016]kk
=c
k-1
⊙fk
[0017]
输入门部分:
[0018][0019][0020]jk
=gk⊙
ik[0021]ck
=jk+kk[0022]
输出门部分:
[0023][0024][0025]
基于上述模型架构和计算迭代方法,基于训练数据迭代计算得到预训练后的lstm网络,再将需要编码的多轮对话按上述方法输入lstm网络中;然后使用attention机制对每个时刻的对话文本隐向量进行融合得到最终的多轮对话表示。
[0026]
在注意力模型中,根据每一轮对话的特征对目标任务分类的重要程度计算其注意力分数,将其作为每一轮对话特征的权重,对所有对话文本隐向量表示进行加权平均计算作为感知到的多轮对话特征。
[0027]
attention迭代公式为:
[0028][0029]
[0030][0031]
所使用的多轮对话编码即为attention层输出的隐状态向量;用一组数据训练一个分类器,将该向量通过一个输出维度为2的softmax层,监督数据为代表多轮对话文本是否标准类别的one-hot向量,输出即该多轮对话属于标准流程或异常流程的概率,得到输出结果后,取概率较大的一个类别作为此多轮对话的输出分类。
[0032]
基于调令员和受令员说的每一段话的时序特性,采用lstm序列对此多轮对话进行编码;首先,将每个多轮对话建模成一个时序序列,再将每个时刻的tf-idf权重信息输入到lstm单元中。
[0033]
针对多轮对话i,对于话术时间序列ti中时间为k的一段话,使用tf-idf权重信息进行向量化表示;设置固定长度的lstm序列,lstm序列的长度大于所有训练数据多轮对话的轮数,将多轮对话每一轮的对话文本向量化信息按顺序依次输入,其中每个lstm单元的输出监督数据为下一轮对话文本的向量;序列代表一个长为n的多轮对话文本序列,其中代表第i个多轮对话在第k轮的对话。
[0034]
使用lstm和attention机制融合模型,在数据集上对调令员和受令员语音交互作业对话进行分类。
[0035]
本发明的有益效果:
[0036]
本发明采用长短期记忆(long short-term memory,lstm)能够很好的编码时序特征,注意力机制(attention)机制能够从大量信息中快速筛选出高价值信息,采用基于lstm和attention机制的调令员和受令员语音交互作业对话分类方法。
[0037]
本发明利用lstm强大的时序学习能力分时刻编码对话文本,然后接着使用attention机制将每个时刻的向量表示进行融合得到当前对话的向量表示,最后将向量输入分类器进行分类
[0038]
本发明将多轮对话文本利用lstm分时刻深度编码,表示为多维向量,解决已有方法不考虑时序特征的问题,接着使用attention机制将多个时刻的向量表示融合获得对话的表示向量,提取有价值的特征,去掉冗余无关的信息,解决现有模型去噪声能力差的问题,提高多轮对话分类的效果。
[0039]
解决了现有模型的学习过程中引入过多的噪声且忽略了时序的因素,影响模型最终的分类效果等技术问题。
具体实施方式
[0040]
基于lstm和attention机制的调令员和受令员语音交互作业对话分类方法主要包括五个关键过程:数据预处理、模型构建训练和使用已构建模型预测调令员和受令员语音交互作业对话类别。
[0041]
过程一:数据预处理
[0042]
在真实数据中,往往存在大量的冗余信息,缺省值以及噪音,也可能因为人工错误导致异常点的存在。此外,就本技术提案所采用的数据集而言,因为其是多轮对话文本,口语化省略严重,还存在非结构化,词语之间不存在分隔符等诸多不利于提取特征的因素。因此,数据预处理是自然语言处理算法中必不可少的步骤。
[0043]
常见的数据预处理操作包括数值归一化,数据结构化,数据去冗余等。就本技术提案而言,将对原始数据集采取去除停用词、去除标点符号和不可见字符、去除低频词等数据预处理操作,需要将原始数据集(文本信息)表示成数字形式。而时下将文本信息表示成数字有多种方式,如统计词频,tf-idf,词向量等。本模型需要的输入是交互语句的数字化表示。针对对话文本的数字化表示,将采用文本词语的tf-idf权重的形式。tf-idf是一种自然语言处理中最常用且基础的统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。
[0044]
过程二:模型构建训练
[0045]
本方案对调令员和受令员语音交互文本对话定义如下:分类数据集中涉及到的所有对话文本的唯一标识符可组成集合u。对于u中的每一个对话ui,对话中调令员和受令员说的每一段话可表示为一个时空序列ti,序列ti中的每一个元素均包含一个时间点k和调令员和受令员说的某一段话。
[0046]
基于调令员和受令员说的每一段话的时序特性,采用lstm序列对此多轮对话进行编码。首先,将每个多轮对话建模成一个时序序列,再将每个时刻的tf-idf权重信息输入到lstm单元中。
[0047]
针对多轮对话i,对于话术时间序列ti中时间为k的一段话,使用tf-idf权重信息进行向量化表示。设置固定长度的lstm序列,lstm序列的长度大于所有训练数据多轮对话的轮数,如果后续分类解码过程中,多轮对话轮数大于lstm序列的长度,就从多轮对话的第一轮取到和lstm序列的长度的轮数,多出的轮数不再考虑。将多轮对话每一轮的对话文本向量化信息按顺序依次输入,其中每个lstm单元的输出监督数据为下一轮对话文本的向量。如序列代表一个长为n的多轮对话文本序列,其中代表第i个多轮对话在第k轮的对话。
[0048]
对于ti中的每个元素均使用二维向量来作为该点的表示向量,并按顺序将输入第k个lstm单元中。对于第k个lstm单元,其监督数据为
[0049]
lstm内部迭代公式如下:
[0050]
遗忘门部分,fk是遗忘因子,u和w是权重矩阵和偏置项,c表示单元状态,kk是遗忘值:
[0051][0052]kk
=c
k-1
⊙fk
[0053]
输入门部分,u和w是权重矩阵和偏置项,i和g是输入门因子,j是综合因子,c是更新后的单元状态:
[0054][0055][0056]jk
=gk⊙
ik[0057]ck
=jk+kk[0058]
输出门部分,u和w是权重矩阵和偏置项,o是输出门因子,v是输出的当前的向量表
示:
[0059][0060][0061]
基于上述模型架构和计算迭代方法,基于训练数据迭代计算得到预训练后的lstm网络,再将需要编码的多轮对话按上述方法输入lstm网络中。然后使用attention机制对每个时刻的对话文本隐向量进行融合得到最终的多轮对话表示,在注意力模型中,根据每一轮对话的特征对目标任务分类的重要程度计算其注意力分数,将其作为每一轮对话特征的权重,对所有对话文本隐向量表示进行加权平均计算作为感知到的多轮对话特征。
[0062]
attention迭代公式如下,w和b是权重矩阵和偏置项,α是计算权重,g是最终的加权向量:
[0063][0064][0065][0066]
本发明所使用的多轮对话编码即为attention层输出的隐状态向量。
[0067]
用一组数据训练一个分类器,将该向量通过一个输出维度为2的softmax层,监督数据为代表多轮对话文本是否标准类别的one-hot向量,输出即该多轮对话属于标准流程或异常流程的概率。得到输出结果后,取概率较大的一个类别作为此多轮对话的输出分类。
[0068]
过程三预测
[0069]
最终,在模型训练完毕之后,本技术提案将使用lstm和attention机制融合模型,在数据集上对调令员和受令员语音交互作业对话进行分类。
[0070]
基于上述方案设计,在此说明本发明所提出方法产生的积极效果。本方案在基于调令员和受令员语音交互作业对话文本数据集,该数据集是从线上业务已有的语音数据翻译成文本并人工标注的,每个对话都会被标注为异常或标准,其中训练集包含20000个现实场景对话,验证集包含1000个对话场景,测试集包含1000个对话场景。当然,为了防止泄露用户隐私,对话内容中涉及到用户的个人数据都在后期被注释过滤。
[0071]
为了验证本方案提出的模型的有效性和正确性,本发明选择了四种经典的多轮对话文本分类方法作为基线方法进行对比:
[0072]
(1)朴素贝叶斯分类器nbc
[0073]
朴素贝叶斯分类器nbc(naivebayesclassifier)是一种假设特征之间强独立下运用贝叶斯定理为基础的简单概率分类器。本发明假设特征的先验概率为多项式分布,即:
[0074][0075]
其中,p(xj=x
jl
|y=ck)是第k个类别的第j维特征第l个取值条件的概率,mk是训练集输出为第k类的样本个数,λ是拉普拉斯平滑项。本发明添加拉普拉斯平滑,即λ=1。
[0076]
(2)支持向量机svm
[0077]
支持向量机svm(supportvectormachine)是一种二分类模型,其基本模型是定义在特征空间上的间隔最大的线性分类器。本发明设置惩罚参数c=1.0,核函数为多项式函数且多项式的维度为3,停止训练的误差值大小为1
×
10-3
。
[0078]
(3)textcnn
[0079]
kim于2014年提出textcnn,将cnn应用到文本分类任务,从而使cnn能够更好地捕捉文本局部语义特征。本发明设置词向量维度为128、滤波器数量为128、模型迭代次数为200、每批次训练数据量为64、学习率为1
×
10-3
。
[0080]
(4)bert
[0081]
bert是谷歌ai团队于2018年发布的模型,在包括文本分类任务的多项自然语言处理任务中创造了当时最佳成绩,bert具有强大的学习能力,在已经预训练的参数去在领域内微调可以有效的学些语义信息。本发明设置bert预训练模型的堆叠层数l=12,词向量维度为768,multi-head self-attention机制的头数h=12,经多次实验后确定对于该任务,bert模型的最佳训练参数为:dropout随机失活率=0.1,模型迭代次数=4,每批次训练数据量=12,学习率=5
×
10-5
。
[0082]
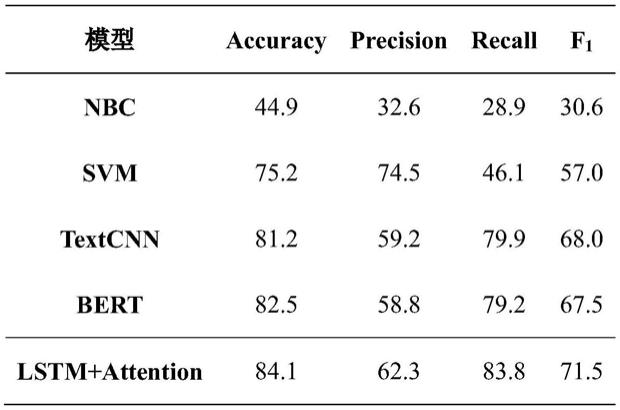
根据本技术提案的数据集特点及lstm模型和attention机制的常规设置方案,input_size为8000维度常用词,num_layers设置为1,hidden_size设置为10,其他设置都选择默认值,实验结果如表1所示
[0083]
表1调令员和受令员语音交互作业对话分类实验结果
[0084][0085]
实验结果说明,与现有的其他模型对比,本发明中提出的模型效果总体上更优,f1值达到最高的71.5%,取得所有模型中最好的结果。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1