一种基于注意力机制的锂离子电池化成预筛选方法
1.本发明涉及锂离子电池制造技术领域,特别地,涉及一种基于注意力机制的锂离子电池化成预筛选方法。
背景技术:
2.能源存储和转化技术对于人类社会的发展极为重要。电池作为一种电能的载体和中介应用广泛。其中,锂离子电池以其更高能量密度,更轻的质量,污染性和较长的使用寿命被大量用于移动端设备,新能源汽车中。
3.在锂离子电池制造过程中,化成是一个重要的环节。在化成过程中,电池在化成充电中形成固体电解质界面(sei),好的sei对提高电池循环寿命,稳定电池特性具有重要作用。
4.传统的化成筛选方法需要在form-ocv检测后才能筛选出化成充电失败或不合格的电池,进而决定电池的后续处理是丢弃还是返工,所以,化成失败的电池也要在化成充电柜上待满80分钟,且不断充电。这意味着巨大的能源和时间的浪费,且延长了电池返工的周期。一般化成场景流程包括:(1)常温老化:在常温下放置电池72-96小时;(2)化成充电:恒流充电80分钟,电流0.15c,截至电压3.7v;(3)form-ocv检测:测试恒流充电后的电池开路电压,开路电压不在合格范围的电池丢弃或返工;(4)高温老化:在45摄氏度下放置电池24小时;(5)常温老化:在常温下放置电池1-7小时,降温。
5.如果能在化成场景流程第(2)步骤化成充电过程中将有缺陷的电池提前筛选出则可以提高生产效率,减少能源消耗。因此,选择一种方法能将有缺陷的电池提前筛选出,具有很重要的价值和意义。
技术实现要素:
6.本发明目的在于提供一种基于注意力机制的锂离子电池化成预筛选方法,以解决上述现有技术中采用传统的方法在form-ocv检测后才能筛选出化成充电失败或不合格的电池,造成巨大的能源和时间的浪费且延长了电池返工周期的技术问题。
7.为实现上述目的,本发明提供了一种基于注意力机制的锂离子电池化成预筛选方法,包括:
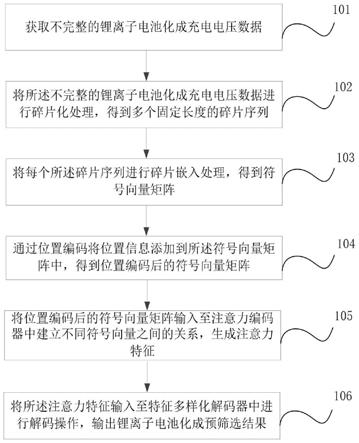
8.获取不完整的锂离子电池化成充电电压数据;
9.将所述不完整的锂离子电池化成充电电压数据进行碎片化处理,得到多个固定长度的碎片序列;
10.将每个所述碎片序列进行碎片嵌入处理,得到符号向量矩阵;
11.通过位置编码将位置信息添加到所述符号向量矩阵中,得到位置编码后的符号向量矩阵;所述位置信息为在碎片嵌入处理过程中丢失的碎片数据之间的次序信息;
12.将位置编码后的符号向量矩阵输入至注意力编码器中建立不同符号向量之间的关系,生成注意力特征;
13.将所述注意力特征输入至特征多样化解码器中进行解码操作,输出锂离子电池化成预筛选结果。
14.进一步的,将每个所述碎片序列进行碎片嵌入处理,得到符号向量矩阵,包括:
15.利用一维卷积核将每个所述碎片序列映射为一个低维嵌入向量,得到符号向量矩阵。进一步的,所述位置编码表示为:
16.τ
pe
=ατ+p
17.其中,是符号向量矩阵,是位置编码矩阵,n为固定长度碎片序列的数量,d
token
为符号向量的维度,t
pe
是位置编码后的符号向量矩阵,α是放大系数。
18.进一步的,所述注意力编码器由多个编码器层堆叠而成;所述编码器层包括多头注意力机制和前向神经网络。
19.进一步的,所述多头注意力机制具体公式如下:
[0020][0021][0022][0023][0024]ho
=concat(h1,h2,...,h
p
)
[0025]
m=multi-head attention(q,k,v)=howo[0026]
其中,为输入矩阵,其中每行为输入向量,lq为该层编码器输入向量个数,d
in
为输入向量的维度,分别为第t个头的输入矩阵关键字矩阵值矩阵对应的线性变换矩阵,dk和dv为关键字矩阵和值矩阵中行向量的维度,softmax(.)表示softmax映射,表示第t个头的输出,p为头的个数,是由h
t
连接得到,concat(.)为连接算子,是多头注意力机制的输出,经过层归一化后,通过跳层与q相加得到
[0027]
所述前向神经网络具体公式如下:
[0028][0029]
其中,m
ffn
为前向神经网络输出,w1,w2为前向神经网络权值,b1,b2为前向神经网络权值偏置,输出qo经过层归一化和通过跳层与相加得到。
[0030]
进一步的,将所述注意力特征输入至特征多样化解码器中进行解码操作,输出锂离子电池化成预筛选结果,包括:
[0031]
将所述注意力特征依次经过卷积、层归一化和gelu激活函数处理后分别得到卷积特征和池化特征;
[0032]
将所述卷积特征和池化特征在不同特征空间表达后相连接,然后通过全局平均池化、线性层和softmax层后进行分类,得到锂离子电池化成预筛选结果。
[0033]
本发明具有以下有益效果:
[0034]
1、本发明提供一种基于注意力机制的锂离子电池化成预筛选方法,利用基于自注意力机制的编码器把握数据之间的联系,构建不完整电压曲线数据片段之间的关系,关注对化成影响最重要的子阶段即在化成场景流程第(2)步骤化成充电阶段,提取了有利于后续预分类的生成注意力特征。
[0035]
2、本发明提供一种基于注意力机制的锂离子电池化成预筛选方法中,设计了一种特征多样化的解码器丰富原始注意力特征,用于将编码的特征投影到不同的子空间,提高特征多样性,通过综合注意力特征在不同子空间的特征投影,得到更好的筛选效果。
[0036]
3、本发明提供一种基于注意力机制的锂离子电池化成预筛选方法,能在化成充电完成前筛选出缺陷电池,从而减少能源浪费,缩短返工周期,提高生产效率;且筛选准确率高,在准确率高达98.73%。
[0037]
除了上面所描述的目的、特征和优点之外,本发明还有其它的目的、特征和优点。下面将参照图,对本发明作进一步详细的说明。
附图说明
[0038]
构成本技术的一部分的附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
[0039]
图1是本发明中提供的一种基于注意力机制的锂离子电池化成预筛选方法的流程图;
[0040]
图2是本发明中采用的不完整的化成充电电压数据曲线图;
[0041]
图3是本发明算法整体框架的结构示意图;
[0042]
图4是本发明中碎片嵌入与位置编码的模型示意图;
[0043]
图5是本发明中注意力编码器的模型示意图;
[0044]
图6是本发明中特征多样化解码器的模型示意图。
具体实施方式
[0045]
以下结合附图对本发明的实施例进行详细说明,但是本发明可以根据权利要求限定和覆盖的多种不同方式实施。
[0046]
实际中,电池是放置在化成充电柜中进行充电,其中每个化成充电柜可以容纳上百个电池同时充电且采集充电的过程数据,如电压、电流、容量等,这些数据在一定程度上已经反映了电池的化成质量,这些数据称为原始电池数据。通过网络上传至服务器进行储存。由于网络延时和计算机采集调度等问题,原始电池数据需要进过线性插值后对齐到同一采集时间序列,即对齐操作,从而为后续工艺所使用。不完整电压数据是通过将对对齐后的电池数据进行截断得到的,相比于完整数据,其仅包含了过程的部分信息。但是,由于原始不完整电压数据缺乏明显分类特征,且不同电池之间的不完整电压数据差异很小,数据中存在较大冗余,使得传统机器学习模型难以很好的把握数据特征进行分类筛选。因此,本发明拟利用不完整的化成充电电压数据,如图2所示,结合基于注意力机制的深度学习模型,寻找数据内部之间的关系,减少数据冗余,提取数据的可分离特征,构建锂离子电池化成预筛选技术,从而缩短返工周期,减少能源消耗,提高生产效率。
[0047]
如图1和图3所示,本发明提供了一种基于注意力机制的锂离子电池化成预筛选方
法,包括以下步骤:
[0048]
步骤101、获取不完整的锂离子电池化成充电电压数据;
[0049]
步骤102、将所述不完整的锂离子电池化成充电电压数据进行碎片化处理,得到多个固定长度的碎片序列;
[0050]
步骤103、将每个所述碎片序列进行碎片嵌入处理,得到符号向量矩阵;
[0051]
步骤104、通过位置编码将位置信息添加到所述符号向量矩阵中,得到位置编码后的符号向量矩阵;所述位置信息为在碎片嵌入处理过程中丢失的碎片数据之间的次序信息;
[0052]
步骤105、将位置编码后的符号向量矩阵输入至注意力编码器中建立不同符号向量之间的关系,生成注意力特征;
[0053]
步骤106、将所述注意力特征输入至特征多样化解码器中进行解码操作,输出锂离子电池化成预筛选结果。
[0054]
本发明提供一种基于注意力机制的锂离子电池化成预筛选方法中。注意力机制是一种构建数据内部不同部分依赖关系的模型。它将同一数据通过线性映射的方式投影到值空间和关键字空间,计算输入与值空间的相似性,构建注意力矩阵对值空间向量进行加权,得到的注意力特征不但包含了输入数据的原始特征,也融合了其他数据对其影响的分量。基于注意力机制的编码器能构建不完整电压曲线数据片段之间的关系,关注对化成有重要影响的子阶段,生成注意力特征,有利于后续的分类筛选任务;由于简单的将注意力编码器所提取的数据特征进行展开,并输入到线性层进行解码的分类效果较差。受卷积将输入变换到多个特征空间进行表达从而更好的提取有效特征进行分类的启发,本发明设计了一种基于卷积和池化的特征解码器,称为特征多样化解码器。该解码器通过分支的方式,得到两类不同的特征,分别为卷积特征和池化特征。卷积特征包含了相邻数据的局部特征,而池化特征包含了数据的整体特征,最后通过全局平均池化,将每个特征通道映射为一个特征值结合线性层进行分类筛选。采用特征多样化解码器能丰富原始注意力特征,通过综合注意力特征在不同子空间的特征投影,提高分类精度,从而得到更好的筛选效果。
[0055]
本发明提供一种基于注意力机制的锂离子电池化成预筛选方法,能在化成充电完成前筛选出缺陷电池,从而减少能源浪费,缩短返工周期,提高生产效率;且筛选准确率高。
[0056]
在一个具体实施方式中,步骤103中的所述将每个所述碎片序列进行碎片嵌入处理,得到符号向量矩阵,包括:
[0057]
利用一维卷积核将每个所述碎片序列映射为一个低维嵌入向量,得到符号向量矩阵。
[0058]
具体的,对于不完整电压曲线数据x=(x0,x1,x2,...,xq),其中xi∈r,d
icvc
为不完整电压曲线数据长度,首先将x截成n个固定长度的碎片序列每个碎片代表了电池充电的一个子阶段,d
frag
为碎片序列的长度。碎片嵌入是利用一维卷积核将每个fj映射为一个低维嵌入向量称为符号向量,它表征了当前子阶段关于电池化成充电的语义信息,d
token
为符号向量的维度。具体公式如下:
[0059]
tj=conv1d(fj)
[0060]
其中,conv1d(.)为一维卷积操作。
[0061]
在步骤104中,由于碎片数据之间的次序信息在碎片嵌入过程中丢失,这一信息对后续分类和编码器把握数据之间关系有重要作用。因此,通过位置编码将位置信息添加到符号向量中。具体过程如图4所示,本发明采用可学习的位置编码方法。具体公式如下所示:
[0062]
所述位置编码表示为:
[0063]
τ
pe
=ατ+p
[0064]
其中,是符号向量矩阵,是位置编码矩阵其每个元素都是可学习的,n为固定长度碎片序列的数量,d
token
为符号向量的维度,t
pe
是位置编码后的符号向量矩阵,α是放大系数,作用是防止输入数据特征被位置编码掩盖。
[0065]
在一个具体实施方式中,所述注意力编码器由l个编码器层堆叠而成;所述编码器层由两部分组成,包括多头注意力机制和前向神经网络。图5为注意力编码器的模型示意图。
[0066]
所述多头注意力机制具体公式如下:
[0067][0068][0069][0070][0071]ho
=concat(h1,h2,...,h
p
)
[0072]
m=multi-head attention(q,k,v)=howo[0073]
其中,为输入矩阵,其中每行为输入向量,lq为该层编码器输入向量个数,d
in
为输入向量的维度,分别为第t个头的输入矩阵关键字矩阵值矩阵对应的线性变换矩阵,dk和dv为关键字矩阵和值矩阵中行向量的维度,softmax(.)表示softmax映射,表示第t个头的输出,p为头的个数,是由h
t
连接得到,concat(.)为连接算子,是多头注意力机制的输出,经过层归一化后,通过跳层与q相加得到
[0074]
所述前向神经网络具体公式如下:
[0075][0076]
其中,m
ffn
为前向神经网络输出,w1,w2为前向神经网络权值,b1,b2为前向神经网络权值偏置,输出qo经过层归一化和通过跳层与相加得到。
[0077]
在106步骤中在对注意力特征进行解码过程时,为了获得更好的分类效果,我们设计了一个特征多样化的解码器,具体结构如图6所示。qo经过卷积,层归一化和gelu激活函数后得到两个分支。上面的分支得到的卷积特征f
conv
,下面的分支得到的池化特征f
pool
,这两种特征是qo在不同特征空间的表达,有利于后续的分类任务。然后,两种特征连接后通过全局平均池化,线性层和softmax层得到分类结果,进而得到锂离子电池化成预筛选结果。
[0078]
以下结合具体实施例对本发明进行解释说明。
[0079]
本发明实验基于18650型锂离子电池的真实生产数据。实验采集了47959个电池的化成完整化成电压数据和对应的form-ocv结果构成原始样本集。数据预处理包括线性插值对齐和数据集混合采样,目的是将不同的电池数据对齐到同一参考时间线,平衡正负样本的数量。计算平台配置为core i9-10980xe、128gb内存、rtx 309024gb。数据集数量细节如表1所示。
[0080]
表1数据集
[0081][0082][0083]
通过采用三个深度学习基准模型,即多层感知机(mlp)、全卷积网络(fcn)、残差网络(resnet),与采用本发明方法(te-fdd)进行了基于真实生产数据的对比实验,对比不同模型之间的性能差异对比。其中,mlp结构为隐含层3层,隐含层神经元个数为500,激活函数为relu。fcn结构为3层,每层为卷积、批归一化、relu,其中每层的卷积核大小分别为7,5,3。resnet结构为3层,其中每层卷积核分别为7,5,3,层内卷积核大小不变,每层包括3个卷积层和1个跳层连接,卷积层结构为卷积、批归一化、relu。本发明方法的默认参数设置为p=8,l=6,d
frag
=d
token
=16,d
icvc
=80。
[0084]
本发明训练使用adam优化器和steplr学习率调整器结合bp算法对模型参数进行跟新。adam的参数设置为β1=0.9,β2=0.98,ε=10-9
。steplr公式如下:
[0085][0086]
其中lr
init
为初始学习率,γ∈[0,1]为衰减系数,v为步长。epoch为当前训练阶段,lr
epoch
为当前训练阶段学习率,[.]为向上取整函数。本发明模型一共训练了512个阶段,其中lr
init
=0.0001,γ=0.95,v=10。损失函数为交叉熵函数。
[0087]
我们选用的评价指标如下:
[0088]
准确率:模型分类正确的数据比率,越大越好。
[0089]
失误率:缺陷电池中没有被正确分类的比率,越小越好。
[0090][0091]
其中n
tn
为正确分类的负样本数量,n
neg
为所有负样本的数量。
[0092]
f1-value:综合反映模型的分类性能,越大越好。
[0093]
g-means:反映模型在应对不平衡数据集时的表现,越大越好。
[0094]
具体实验结果如表2所示。
[0095]
表2不同方法对比实验结果
[0096][0097]
除此之外,本发明还进行了不同数据长度和不同解码器对模型性能的影响实验测试。其中,表4中对比解码器结构如下:线性解码器为线性层;多层感知机解码器:隐含层2层,神经元数量分别为256,2。具体实验结果如表3和表4所示。
[0098]
表3基于不同数据长度的模型实验结果
[0099][0100]
表4基于不同解码器的模型实验结果
[0101][0102]
由表2的实验结果可以看出:在不同方法对比实验中,本发明方法在准确率和失误率上的结果最优,分别为98.73%和1.92%,准确率比mlp高出4.46%,比resnet高出2.49%。失误率比mlp低13.74%。f1-value和g-means衡量模型在不平衡数据集上的效果,本发明方法这两项指标结果也是最优,表明本文方法在预筛选任务中表现较好。在运行速度方面,本文方法结果并非最优,但在实际生产中,电池与筛选是并行的,因此本文方法能满足实际生产需要。
[0103]
由表3的实验结果可以看出:用更短输入数据长度训练的预筛选模型,能更早的筛选出失效电池,但是准确率也会随之降低。因此,如何权衡输入数据长度和准确率之间的关系和对模型的影响是该实验要验证的。从实验结果看,本文方法在输入数据长度d
icvc
=40(即包含前20分钟的充电电压数据)的基础上,准确率为96.13%,提前筛选时间为60分钟;在输入数据长度d
icvc
=80(即包含前40分钟的充电电压数据)的基础上,准确率为98.73%,提前筛选时间为40分钟;在输入数据长度d
icvc
=161(即完整的充电电压数据)的基础上,准确率为99.07%,提前筛选时间为0分钟,作为对照。
[0104]
由表4的实验结果可以看出:本发明的注意力编码器可以和不同的解码器进行组合用于预筛选任务,但不同解码器的性能各不相同。该实验为不同解码器对预筛选性能的影响,其中采用本发明的特征多样化解码器效果最佳,优于其他解码器。
[0105]
综上所述,本发明提供一种基于注意力机制的锂离子电池化成预筛选方法,利用基于自注意力机制的编码器把握数据之间的联系能构建不完整电压曲线数据片段之间的关系,关注于对化成有重要影响的子阶段,提取了有利于后续预分类的生成注意力特征;同时设计了一种特征多样化的解码器丰富原始注意力特征,用于将编码的特征投影到不同的子空间,提高特征多样性,通过综合注意力特征在不同子空间的特征,在化成充电完成前筛选出缺陷电池,从而减少能源浪费,缩短返工周期,提高生产效率;且筛选准确率高。
[0106]
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1