一种虚拟化集群高可用性的实现方法和设备与流程
1.本发明属于虚拟化技术领域,具体涉及一种虚拟化集群高可用性的实现方法和设备。
背景技术:
2.虚拟化技术的应用,能够实现服务器整合,为应用系统提供独立、高效和灵活的运行环境,同时节约资源、方便管理。服务器虚拟化必须具备高可用性(high availability,ha),才能构成稳定持续的基础平台。服务器或其上运行的虚拟机发生故障时,应用系统不间断或短暂间断服务。
3.最常见的高可用解决方案是采用服务器集群技术。高可用集群通过保护用户的业务程序对外不间断提供的服务,把因软件、硬件或人为造成的故障对业务的影响降低到最小程度。如果某个节点失效,备援节点将在几秒钟的时间内接管职责。因此,对于用户而言,集群永远不会停机。高可用集群软件的主要作用就是实现故障检查和业务切换的自动化。
4.在非虚拟化系统中,要对某个计算机应用实施高可用性,需在每台节点服务器分别安装同一种应用,然后将所有节点组成一台集群服务器。应用系统种类繁多,不同应用对服务器的配置要求差异较大,如果每个应用都占用两台以上服务器,将造成服务器资源的浪费;如果仅对关键应用实施高可用性,则非关键应用将始终存在单点故障风险。
5.虚拟化软件如vmware、openstack等,通常是以虚拟机的自动实时迁移来保证虚拟机高可用,即当某一台物理服务器由于故障或维护原因导致服务中断后,其虚拟机自动切换到其他运算资源消耗较小的物理服务器上,从而保持业务的连续性。当虚拟机本身出现网络异常、虚拟机系统资源不足等故障时,虚拟机就无法实现自动迁移,高可用性不能实现。
6.当前常采用基于vsphere ha、openstack实现在虚拟化环境下的高可用,vsphere ha利用群集的多台esxi主机,为虚拟机中运行的应用程序提供快速中断恢复的高可用性。sphere ha通过在群集内的其他主机上重新启动虚拟机,防止服务器故障。持续监控虚拟机并在检测到故障时对其进行重新设置,防止应用程序故障。vsphere ha可以将虚拟机及其所驻留的主机集中在群集内,从而为虚拟机提供高可用性。群集中的主机均会受到监控,如果发生故障,故障主机上的虚拟机将在备用主机上重新启动。创建vsphere ha群集时,会自动选择一台主机作为首选主机。首选主机可与vcenter server进行通信,并监控所有受保护的虚拟机以及从属主机的状态。可能会发生不同类型的主机故障,首选主机必须检测并相应地处理故障。首选主机必须可以区分故障主机与处于网络分区中或已与网络隔离的主机。首选主机使用网络和数据存储检测信号来确定故障的类型。但是vsphere ha依赖于服务器集群,集群对主机的数量有要求,要求最少3台。集群间的通信对网络要求较高,需要高可靠的集群网络。集群的组播机制规模越大效率越低。对虚拟机的监控依赖于vmware tools,虚拟机内安装tools在有些情况下是不可接受的。且vsphere属于商业软件,闭源。存在升级改造困难的问题。
7.在openstack中,高可用方案分为主机高可用和虚拟机高可用。主机高可用指在物理计算节点发生硬件故障时(如磁盘损坏、cpu或内存故障导致宕机、物理网络故障和电源故障),自动将该节点关闭,该节点上的虚机在集群中其它健康的计算节点上重启。虚拟机高可用指在虚拟机发生故障停机时,监控软件能自动重启虚拟机。openstack高可用是基于三个步骤来实现:监控(monitoring)、隔离(fencing)和恢复(recovery)。对计算节点的跟踪监控通过探测节点上服务的故障与否来进行隔离,pacemaker提供了对集群节点的隔离功能,需要在计算节点上实现一个evacuate(疏散)的资源代理,从而允许pacemaker触发节点上的evacuate恢复操作。pacemaker和corosync是使用最多的服务高可用监控工具,但corosync对计算节点的支持数目有限,pacemaker_remote解决了这种限制。但是openstack依赖的组件较多,pacemaker,corosync等组件配置复杂,不利于维护。pacemaker问题较多,存在不稳定因素。部署复杂,集群至少需要3个节点。集群内采用组播机制,规模越大效率越低。且目前,openstack没有一套完成的监控、隔离和恢复方案,因此,用户必须自己实现服务监控和节点隔离,同时触发故障计算节点上的evacuate操作。如果使用pacemaker集群资源管理器,则需要在计算节点上实现一个evacuate的资源代理,从而允许pacemaker触发节点上的evacuate操作。
技术实现要素:
8.本发明所要解决的技术问题是针对上述现有技术的不足,提供一种虚拟化集群高可用性的实现方法和设备,能够保证物理机、虚拟机通过快速故障恢复保证持续服务,并通过存储共享保障数据安全。
9.为实现上述技术目的,本发明采取的技术方案为:
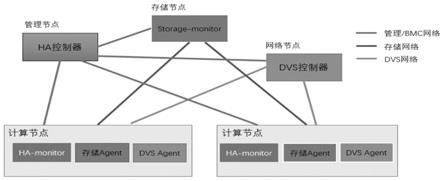
10.一种虚拟化集群高可用性的实现设备,包括:ha控制器、存储节点、dvs控制器和若干计算节点;
11.所述ha控制器,用于主机心跳的监听,并对超时主机进行决策及进一步控制;
12.所述计算节点,用于主机心跳信息的上报、存储以及虚拟机的监控;
13.所述存储节点,用于通过存储网络接收存储心跳;
14.所述dvs控制器,用于控制每个计算节点的虚拟机交换机,进行网络策略的管理配置。
15.为优化上述技术方案,采取的具体措施还包括:
16.上述的ha控制器使用udp端口监听,对于心跳报文进行计时及对错误报文进行告警处理,以保证服务及传输的效率。
17.上述的每个计算节点上部署ha-monitor、存储agent和dvs agent;
18.所述ha-monitor定时向ha控制器上报心跳信息;
19.所述ha-monitor还监控虚拟机的状态;
20.所述dvs agent通过dvs网络与dvs控制和通信。
21.上述的ha-monitor监控虚拟机的状态,监控虚拟机的各种事件,并根据ha策略对虚拟机进行重启或者告警操作,出现虚拟机进程异常退出或虚拟机内核panic事件时进行虚拟机重启。
22.上述的ha控制器通过dvs控制器的接口检查计算节点dvs agent的状态。
23.上述的存储节点提供api供ha控制器查询存储的心跳信息。
24.上述的设备中,不同的存储类型设有不同的存储监控器,且针对ocfs2集群文件系统和ceph设置存储监控器,并在每个计算节点设置storage-agent;
25.storage-agent发送存储事件的同时也定时发送心跳给storage-monitor;
26.ha控制器通过storage-monitor获取主机状态信息。
27.一种虚拟化集群高可用性的实现方法,包括:
28.步骤1:计算节点进行主机心跳信息的上报、存储以及虚拟机的监控;
29.步骤2:存储节点通过存储网络接收存储心跳;
30.步骤3:ha控制器进行主机心跳的监听,并对超时主机进行决策及进一步控制;
31.步骤4:dvs控制器控制每个计算节点的虚拟机交换机,进行网络策略的管理配置。
32.上述的步骤3中,如果连续3个周期没有收到主机心跳,ha控制器执行如下处理策略:
33.步骤3-1:主动连接libvirt进行查询虚机状态,如果连接成功并且虚机状态正确,则告警显示ha-monitor异常,否则说明主机异常,则进入步骤3-2;
34.步骤3-2:通过存储网络查询存储心跳:
35.如果存储心跳正常,说明管理网络异常,则进行告警处理,否则进入步骤3-3;
36.步骤3-3:通过bmc接口查询电源状态:
37.若电源状态正常,则关闭主机并启动虚拟机迁移流程,否则告警并关闭主机执行虚拟机迁移流程。
38.上述的步骤3-2中,对于无法存储心跳的存储类型,通过dvs控制器查询主机状态,dvs agent如果正常,则判定为管理网络的问题,进行告警处理;
39.对于不支持存储网络及dvs控制器的情况,对整个集群的管理网络进行检查,如果集群中超过一定阈值的主机管理网络都出现故障,则判定为管理网络的问题,进行告警处理。
40.本发明具有以下有益效果:
41.本发明的服务器虚拟化高可用功能主要包括虚拟机ha和主机ha。虚拟机在遇到异常关闭的时候能够通过监控软件自动重新启动。主机出现异常无响应,能通过ipmi接口隔离主机,并自动迁移运行于该主机上的虚拟机。能够有效防止集群中多个虚拟机访问同一存储的脑裂现象。主机或者虚拟机发生故障时,能够快速响应。虚拟机故障检测时间在1秒内。主机故障检测时间可以根据需要调整,默认为3个心跳周期,每个周期为5秒,即故障检测时间为15秒。
42.1.集中式的心跳检测。和集群采用的分布式心跳机制不同,此方式简单,策略单一,便于进行集中维护管理。
43.2.故障恢复检测流程,采用多种机制防误报,避免单一的策略失败,极大的防止错误的发生,并能有效防止脑裂现象。
44.3.本发明不依赖第三方软件,作为虚拟化管理软件的一部分,完全自主可控。
45.4.采用集中式控制,各个节点系统开销很小,并可以任意扩展。不依赖于组播机制,对集群的规模没有限制,针对小规模集群比现有技术更有优势,大规模集群能达到商用虚拟化软件的实现效果。
46.5.集群管理部署灵活,支持集群动态管理并支持任意节点的集群。
附图说明
47.图1为本发明设备构成图;
48.图2为本发明设备中主要组件工作流程图
49.图3为本发明dvs实现原理图;
50.图4为本发明设备整体工作流程。
具体实施方式
51.以下结合附图对本发明的实施例作进一步详细描述。
52.参见图1,一种虚拟化集群高可用性的实现设备,包括:ha控制器、存储节点、dvs控制器和若干计算节点;
53.所述ha控制器,用于主机心跳的监听,并对超时主机进行决策及进一步控制;
54.所述计算节点,用于主机心跳信息的上报、存储以及虚拟机的监控;
55.所述存储节点,用于通过存储网络接收存储心跳;
56.所述dvs控制器,用于控制每个计算节点的虚拟机交换机,进行网络策略的管理配置。
57.实施例中,所述ha控制器是一个集中式的控制器,负责收集主机心跳,并对超时主机进行决策及进一步控制;其高可用性由服务端来保证,此文不做讨论。
58.所述ha控制器使用udp端口监听,对于心跳报文进行计时及对错误报文进行告警处理,以保证服务及传输的效率。
59.实施例中,每个计算节点上部署ha-monitor、存储agent和dvs agent;
60.所述ha-monitor定时向ha控制器上报心跳信息;
61.所述ha-monitor还监控虚拟机的状态;
62.所述dvs agent通过dvs网络与dvs控制和通信。
63.实施例中,所述ha-monitor监控虚拟机的状态,监控虚拟机的各种事件,并根据ha策略对虚拟机进行重启或者告警操作,出现以下两种事件时进行虚拟机重启:
64.(1)虚拟机进程异常退出,即qemu进程由于各种愿意异常退出,此时虚拟机也处于异常关闭状态。
65.(2)虚拟机内核panic。依赖于虚拟机内部的pvpanic驱动。目前大多数系统已经实现。
66.实施例中,所述ha控制器通过dvs控制器的接口检查计算节点dvs agent的状态。
67.所述存储节点提供api(application programming interface,应用程序接口)供ha控制器查询存储的心跳信息。
68.实施例中,所述设备中,不同的存储类型设有不同的存储监控器,且针对ocfs2集群文件系统和ceph设置存储监控器,并在每个计算节点设置storage-agent(对应于存储agent);
69.storage-agent发送存储事件的同时也定时发送心跳给storage-monitor(存储节点);
70.ha控制器通过storage-monitor获取主机状态信息。
71.一种虚拟化集群高可用性的实现方法,包括:
72.步骤1:计算节点进行主机心跳信息的上报、存储以及虚拟机的监控;
73.步骤2:存储节点通过存储网络接收存储心跳;
74.步骤3:ha控制器进行主机心跳的监听,并对超时主机进行决策及进一步控制;
75.步骤4:dvs控制器控制每个计算节点的虚拟机交换机,进行网络策略的管理配置。
76.实施例中,主要组件工作流程如图2所示。
77.ha-monitor:
78.ha-monitor也负责监控虚拟机的状态。可以监控虚拟机的各种事件。根据ha策略可以对虚拟机进行重启或者告警操作。以下两种事件需要进行虚拟机重启:
79.1.虚拟机进程异常退出。即qemu进程由于各种愿意异常退出,此时虚拟机也处于异常关闭状态。
80.2.虚拟机内核panic。依赖于虚拟机内部的pvpanic驱动。目前大多数系统已经实现。
81.storage-monitor:
82.不同的存储类型有不同的存储监控器,本发明中针对ocfs2集群文件系统和ceph实现了存储监控器,并在每个计算节点实现storage-agent。storage-agent发送存储事件的同时也定时发送心跳给storage-monitor。ha控制器就可以通过storage-monitor获取主机状态信息。对于存储类型不支持storage-monitor可以通过dvs等其他方式来处理。
83.dvs:
84.dvs是分布式虚拟交换机的一种实现,主要包括dvs控制器,dvs agent,ovs等组件。
85.dvs agent发送网络事件的同时也定时发送心跳给dvs控制器。ha控制器就可以通过dvs控制器获取主机的状态信息。
86.dvs主要实现如图3所示。
87.实施例中,所述步骤3中,如果连续3个周期没有收到主机心跳,ha控制器(ha-controller)执行如下处理策略:
88.步骤3-1:主动连接libvirt进行查询虚机状态,如果连接成功并且虚机状态正确,则告警显示ha-monitor异常,否则说明主机异常,则进入步骤3-2;
89.步骤3-2:通过存储网络查询存储心跳:
90.如果存储心跳正常,说明管理网络异常,则进行告警处理,否则进入步骤3-3;
91.实施例中,所述步骤3-2中,对于无法存储心跳的存储类型,通过dvs控制器查询主机状态,dvs agent如果正常,则判定为管理网络的问题,进行告警处理。
92.对于不支持存储网络及dvs控制器的情况,可对整个集群的管理网络进行检查。如果集群中超过一定阈值的主机管理网都出现故障,则可判定是管理网的问题。
93.步骤3-3:通过bmc接口查询电源状态:
94.若电源状态正常,则关闭主机并启动虚拟机迁移流程,否则告警并关闭主机执行虚拟机迁移流程。
95.步骤3-1至步骤3-3形成如下防误报策略:
96.1.首先连接主机libvirt进行第一步检测,初步判断是不是管理网络的问题。
97.当ha-controller发现主机心跳超时并且不能主动连接主机,这时有两种可能:
98.一种是管理网络出现故障,主机及虚拟机工作正常;
99.一种是主机宕机。
100.以下几种机制使用一种或者结合起来进一步判断是否主机真的出现异常。
101.2.存储心跳网络检查。在采用网络存储的时候,存储网络部署心跳检查机制,判断异常主机是否有对网络存储的访问。如果此心跳网络正常,可以判断主机工作正常。
102.dvs控制器检查。对于不支持存储心跳的存储类型,通过dvs控制器来检查主机状态。dvs网络独立于其他网络,用于控制主机上的dvs agent。如果主机上的dvs agent正常,也可以确定主机工作正常。
103.3.集群网络检查。网络问题一般会影响很多主机,如果集群里的大多数主机都出现问题,则可判断是网络问题,这种情况只需要告警处理。集群中主机故障设置阈值,只有在没有超过故障阈值时,才进高可用关机迁移操作。
104.4.bmc网络检查。通过bmc网络可以进一步判断主机故障类型。是否有硬件发生故障。并通过ipmi和bmc通信进行关闭主机电源,只有在主机断电后才能进行虚拟机迁移操作。这样就防止了多个虚拟机使用相同存储的脑裂现象。
105.系统整体工作流程如图4所示。
106.缩略语和关键术语定义
107.ha高可用型(high availability),消除单点故障并将故障自动恢复(服务自动迁移到一个正常的节点),提供服务可持续的服务。
108.bmc是一个独立于服务器系统的小型操作系统,作用是方便服务器远程管理、监控、安装、重启等操作。bmc接通电源即启动运行,由于独立于业务程序不受影响,避免了因死机或者重新安装系统而进入机房。
109.ipmi是智能型平台管理接口(intelligent platform management interface)的缩写,是管理基于intel结构的企业系统中所使用的外围设备采用的一种工业标准,该标准由英特尔、惠普、nec、美国戴尔电脑和supermicro等公司制定。用户可以利用ipmi协议连接服务器bmc,监视服务器的物理健康特征,如温度、电压、风扇工作状态、电源状态等。
110.fencing,对故障节点进行排除的机制,可以控制电源关闭不可用节点。
111.libvirt,是用于管理虚拟化平台的开源的api,后台程序和管理工具。
112.qemu,是一款用来完成硬件虚拟化及虚拟机托管的开源软件。
113.dvs,distributed virtual switch分布式虚拟交换机。
114.以上仅是本发明的优选实施方式,本发明的保护范围并不仅局限于上述实施例,凡属于本发明思路下的技术方案均属于本发明的保护范围。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理前提下的若干改进和润饰,应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1