一种基于改进型蚁群算法的空气污染源反演方法
本发明公开了一种基于群智能算法的污染源反演方法,具体说是一种基于改进型蚁群算法的空气污染源反演方法。
背景技术:
1、随着化工业的发展,空气污染成为了一个不容忽视的问题。只有明确污染源位置和排放量才能够为进一步的污染治理奠定坚实的基础,才能使得整个空气监测治理链起到精准监控、实时源分析、及时管理、靶向治理等作用。
2、传统的对于空气污染源定位的方法主要是通过企业排放源清单进行排查,但在源清单的获取和数据库的创建中,由于监测区域空气污染物的开放性,使得前期排放清单的获取难度过大,数据不够完全。同时由于一些未知企业的存在,导致源清单无法收集完全。另外由于活动水平资料的不全面,排放因子难以确定。但即便是能够建立好完备的数据库,获取到监测区域内所有污染源的排放数据,由于我国工业的迅速发展,会使得整个污染源清单的数据量过于庞大,从而导致单纯通过人力排查十分困难且低效。
技术实现思路
1、为了提高空气污染源的定位准确性和排查效率,满足污染源精准定位、靶向治理的需求,本发明提供了一种基于改进型蚁群算法的空气污染源反演方法,其能够有效的对造成空气污染超标事故的污染源进行定位和参数反演,能提高现有方法的效率和准确率。
2、基于全局优化搜索的方法是采用人工智能的优化方法,根据气体扩散的特征、风速、风向等因素,选取合适的气体扩散模型,建立损失函数作为模型,采取人工智能算法对损失函数进行反复的求解,从而得到空气污染排放源的位置和排放量,可以降低人工成本和提高效率。因此,群智能算法反演空气污染源的研究具有一定的理论意义和应用价值。
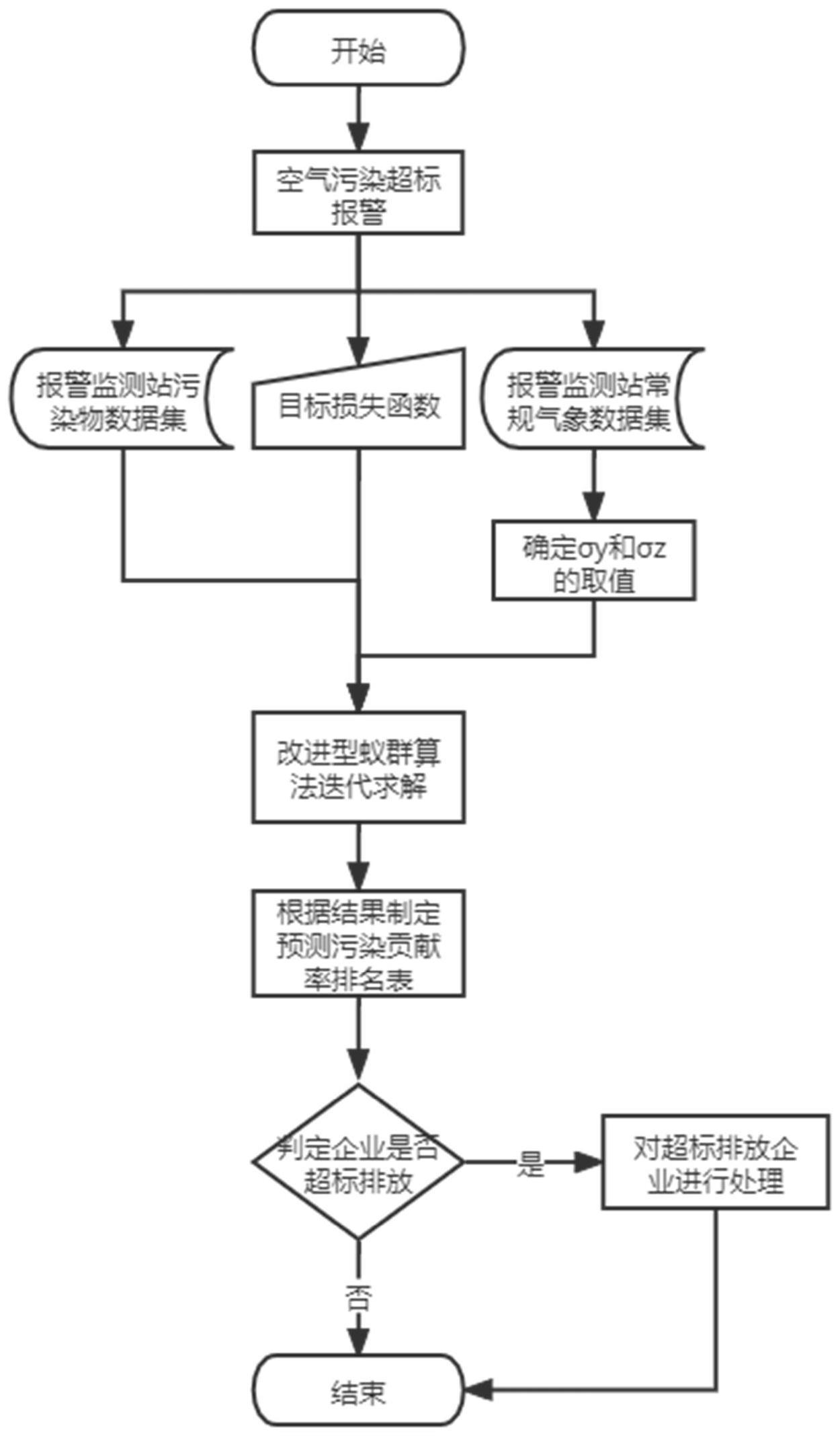
3、本发明为了实现上述目的所采用的技术方案是:一种基于改进型蚁群算法的空气污染源反演方法,包括以下步骤:
4、步骤1:采集空气污染超标的所有监测站的监测数据;
5、步骤2:构建气体扩散模型并优化,与目标优化函数共同构成空气污染源反演模型;
6、步骤3:通过蚁群算法对空气污染源反演模型进行迭代求解,得到污染源信息,以确定空气污染源。
7、步骤2具体如下:
8、构建气体扩散模型:
9、
10、其中,c(x,y,z)表示下风向处任意一点(x,y,z)的气体模拟浓度;q0表示排放源的强度;u表示平均风速;x0、y0表示排放源的水平面坐标;x、y表示监测站的水平面坐标;h0表示排放源的高度;z表示排放口下风处任意一点(x,y,z)的垂直坐标;σy和σz表示水平和竖直扩散系数,表现形式为:
11、
12、
13、式中,ω1、ω2、θ1、θ2为系数;
14、优化气体扩散模型,具体如下:令z=0,则优化后的气体扩散模型如下:
15、
16、根据优化后的气体扩散模型构建标损失函数如下:
17、
18、其中,表示监测站实际检测到的污染物浓度,表示通过上述优化后的气体扩散模型得到的污染物浓度,ltar表示损失函数值,用来评价当前结果的准确性,其越接近0表示当前结果越准确,t表示监测站的数量。
19、步骤3具体如下:
20、步骤3.1:初始化各项参数:信息素和启发函数的重要程度因子α、β以及蚁群规模m、迭代次数n、信息素挥发因子ρ,排放源各项源参数的上下限,所述排放源各项源参数包括排放源源强q0、位置(x0、y0)以及释放高度h0;
21、步骤3.2:在各项源参数构成的可行域内随机生成蚂蚁个体,并且初始化每个蚂蚁的信息素τi(i=1,2,3,…,m);
22、步骤3.3:每只蚂蚁根据状态转移规则和搜索策略选择自己的下一步位置;
23、步骤3.4:当所有蚂蚁搜索完成后,更新当前的全局最优解,然后进行选择和交换操作;
24、步骤3.5:根据第i只蚂蚁第n+1代的损失值与其第n代的损失值的大小关系对蚂蚁个体进行更新;当迭代次数达到n后,若损失函数ltar收敛,则根据当前迭代次数的蚂蚁个体作为最优蚂蚁个体,其所对应的各项源参数进行污染源排查。
25、所述步骤3.3通过以下步骤实现:
26、步骤3.3.1:状态转移概率如下:
27、
28、其中,表示启发式因子pi(n)表示第i只蚂蚁选择下一个位置的概率,当pi(n)越大时,说明当前的解越接近污染源的各项源参数;τi代表第i只蚂蚁的信息素,ηi代表第i只蚂蚁的启发函数;n为当前已迭代次数;
29、步骤3.3.2:设定一个状态转移常数p0,当pi(n)大于p0时,就采取局部搜索策略,否则采取全局搜索策略,其可如下表示:
30、
31、其中,next为当前蚂蚁的下一个位置;now为当前蚂蚁的当前位置;rand表示一个(0,1)之间的随机数;step表示局部搜索步长;λ表示步长系数,其取值为迭代次数的倒数range表示可行域范围。
32、所述步骤3.4具体如下:
33、每次迭代结束后,对整个蚁群按照损失值从小到大进行排序,将损失值最大的个体舍去,从剩下的中随机选择损失值处于中间位置的个体进行复制,填充到舍去的处,从而形成新的种群;
34、在新的种群中随机选择两个个体p1和p2进行交叉,将p1、p2的一部分进行交换,从而形成新的个体,交叉方式如下:
35、
36、其中,p1、p2表示所选蚂蚁个体,包含的排放源各项源参数组成的向量,表示交叉后形成新的蚂蚁个体,a和β表示交叉点,范围为(0,1)且a<β。6.根据权利要求3所述的一种基于改进蚁群算法的空气污染源反演方法,其特征在于,所述对蚂蚁个体进行更新,通过下式实现:
37、τi(n+1)=(1-ρ)τi(n)+δτi(n)
38、
39、
40、其中,n为当前迭代次数;ρ代表信息素挥发因子;τi代表第i只蚂蚁的信息素;δτi代表第i只蚂蚁的信息素增量;k表示常系数;li代表第i只蚂蚁个体的损失值;μ代表一个系数,对于第i只蚂蚁,若其n-1代的损失值大于第n代的损失值,那么对它的信息素增量δτi进行增加,反之则减少。
41、所述根据当前迭代次数的蚂蚁个体作为最优蚂蚁个体,其所对应的各项源参数进行污染源排查,具体为:
42、以最优蚂蚁个体的坐标(x,y)为中心,设定长度r为半径,在这个圆形区域内,对某类污染物排放的排放源按照距反演污染源的距离,得出各个排放源的预测污染贡献率排序,以确定空气污染源。
43、所述贡献率公式如下:
44、
45、其中,pi表示第i个排放源的污染概率;di表示第i个排放源到最优解对应的平面坐标(x,y)的距离;m为排查范围内的排放源数量。
46、一种基于改进型蚁群算法的空气污染源反演系统,包括:
47、数据获取模块,用于获取空气污染超标的所有监测站的监测数据;
48、模型构建模块,用于构建气体扩散模型并优化,与目标优化函数共同构成空气污染源反演模型;
49、反演模块,用于通过蚁群算法对空气污染源反演模型进行迭代求解,得到污染源信息,以确定空气污染源。
50、本发明的有益效果及优点为:
51、本发明使用了改进型蚁群算法,利用了遗传算法的交叉操作,解决了传统蚁群算法容易陷入局部最优的缺点,改进了信息素的更新机制,解决了传统一群算法收敛速度较慢,进一步加强了搜索能力,能够更快更准确地反演出引起空气污染警报的污染物的源参数信息,通过相关实验验证了方法的有效性,为空气污染治理提供了实践意义。
52、根据气体扩散规律建立气体扩散模型,并以此为基础建立空气污染源反演模型;其次对于模型的求解,采用改进的蚁群算法进行求解,从蚁群算法的容易陷入局部极值和收敛速度两个方面进行改进,结合遗传算法的交叉思想以及更新蚁群算法的信息素更新机制,从而加强蚁群算法的全局搜索能力和加快收敛速度,从而达到快速精准反演出空气污染源的相关参数信息,达到污染源的快速定位,进行靶向治理。同时本发明提出的基于改进型蚁群算法的空气污染源反演方法还可适用于水污染、土壤污染等源反演问题。
- 还没有人留言评论。精彩留言会获得点赞!