一种基于跨模态特征融合的多任务加密网络流量分类方法
1.本发明涉及深度学习、网络流量分析和网络空间安全应用的技术领域,尤其涉及一种基于跨模态特征融合的多任务加密网络流量分类方法。
背景技术:
2.流量分类是一种根据任务和网络流量特征将流量划分到对应类别中的任务。流量分类是网络安全、服务质量(quality of service,qos)以及网络管理的前置需求,因为这些应用都需要通过流量分类来理解网络中发生的进程,在不同的任务中,同一个流量可能被划分到不同的分类中,这也被称为多任务(多标签)流量分类任务。近年来,接入网络的设备数量迅速增加、网络规模和网络吞吐量的扩大,加密协议(如tls和quic)和混淆技术的广泛使用,新型网络的出现如软件定义网络(software-defined network,sdn),工业互联网(industrial internet of things,iiot)的出现对流量分类带来了更大的挑战。
3.由于流量分类的重要意义,流量分类算法的发展非常迅速。可以将流量分类算法划分为传统流量分类算法,基于机器学习(“traditional”machine learning,ml)的流量分类算法和基于深度学习(deep learning,dl)的流量分类算法三类;总体来说,早期的传统机器学习算法尝试直接匹配端口号或者特定关键词,基于ml的算法依赖于handcraft(domain-export driven)特征,并利用类似数据挖掘的技术实现流量分类,而基于dl的算法可以自动的从结构化的高维输入中学习到复杂和高度抽象的特征。
4.基于端口号的流量分类算法和基于有效载荷的流量是两种典型的传统流量分类算法。基于端口号的流量分类算法尝试将协议字段的端口号与iana注册的端口号匹配,由于动态端口和网络地址转换技术的广泛使用,这种方法现在只能达到很低的精度;以深度报文探测(dpi)为代表的基于有效载荷的方法尝试匹配报文中的关键字或是模式,这种方式无法处理加密的流量。相比之下,基于传统机器学习的流量分类算法则可以分类经过加密的流量,因为它不一定依赖于特定的端口或是关键字,而是通过人类专家手工提取的特征。这些特征往往是和数据包序列有关联的统计信息,因此加密算法对这些特征影响有限。然而,这种方法的准确率非常依赖手工提取的特征,且在网络流量特征发生变化的时候难以及时更新。和传统机器学习不同,和传统机器学习方式不同,深度学习不需要人类专家进行特征选择,因为深度学习可以自动的从输入的训练数据中学习到复杂而结构化的特征表达,这使得深度学习是一种流量分类的非常理想的解决方案,近来很多加密流量分类的相关工作也证实了这一点。
5.最近的研究显示,从(加密)流量的多个方面提取复杂的特征,即发现不同模态输入和不同分类任务的内在联系可以使模型达到更高的分类精度,这种多模态多任务模型结构最早由aceto等人提出的distiller模型实现,典型的多模态输入由元组形式的每个包的统计信息和字节形式的有效载荷构成,异构多模态输入为模型结构的设计带来了困难,目前,有两种处理这种异构多模态输入的方式,一种是使用两个独立的模块分别处理统计信息和有效载荷,另一种是忽视每个包有效载荷长度,将每个包的统计信息和经过零填充或
是裁剪后的有效载荷编码为单个固定长度向量。
技术实现要素:
6.本部分的目的在于概述本发明的实施例的一些方面以及简要介绍一些较佳实施例。在本部分以及本技术的说明书摘要和发明名称中可能会做些简化或省略以避免使本部分、说明书摘要和发明名称的目的模糊,而这种简化或省略不能用于限制本发明的范围。
7.鉴于上述现有存在的问题,提出了本发明。
8.因此,本发明解决的技术问题是:综上所述,当前工作中对于加密流量分类的研究仍存在以下不足:随着加密技术和混淆技术的普及,网络流量迅速发生变化,基于传统方式(人类手工设计特征)的流量识别方法难以及时有效的处理这些流量,需要基于深度学习的流量分类方式自动从数据中学习新流量的识别模式;以往单任务单模态的加密流量分类方法在准确率和能力上均不如基于多模态多任务的流量识别算法(因为多模态流量识别算法可以抽取不同模态的信息,而且一次可以给出对多个任务的分类预测);现有多模态多任务流量分类模型,一种是使用两个独立的模块分别处理统计信息和有效载荷,另一种是忽视每个包有效载荷长度,将每个包的统计信息和经过零填充或是裁剪后的有效载荷编码为单个固定长度向量。其中前一种方式不同模态输入的处理是完全分离没有任何关联的,因此同一个包不同模态间的信息可能会被忽视。后一种方式忽视了每个包有效载荷的长度,对于上下传数据量不均衡的流,或是有效载荷较短的流会带来额外的计算开销。这两种方式并没有充分挖掘不同模态输入间信息的关联性,特别是每个包不同模态间信息有很强的内在联系,这种信息没有被利用。
9.为解决上述技术问题,本发明提供如下技术方案:获取待识别的原始流量;预处理所述原始流量,并获得预处理后的格式化样本;将所述格式化样本输入至训练完成后的基于特征融合技术的多模态多任务深度神经网络,得到对于每个任务对应的预测向量;基于每个任务对应预测向量,取其中最大的值对应的分类作为加密流量在该任务上最终的分类标签。
10.作为本发明所述的基于跨模态特征融合的多任务加密网络流量分类方法的一种优选方案,其中:所述待识别的原始流量包括,一组具有相同5元组的数据包,所述5元组包括源端口、ip地址、目的端口、ip地址和协议,以及掉换方向的数据包,即交换源、目的端口的ip地址和端口号。
11.作为本发明所述的基于跨模态特征融合的多任务加密网络流量分类方法的一种优选方案,其中:预处理所述原始流量包括采样、无偏化预处理、数据格式转换和标准化。
12.作为本发明所述的基于跨模态特征融合的多任务加密网络流量分类方法的一种优选方案,其中:所述采样和无偏化预处理:从所述原始流量中采样最多784字节的有效载荷和至多32个包的统计信息,采样时丢弃流量中会导致分类性能被夸大的有偏信息,即无偏化预处理。
13.作为本发明所述的基于跨模态特征融合的多任务加密网络流量分类方法的一种优选方案,其中:所述数据格式转换指采样获得的信息不适合作为深度神经网络的输入,需要将采集到的每个有效载荷的每个字节视为[0,255]之间的值,每个包对应的统计信息四元组中的数据包的到达时间加1后取对数,再将整个四元组变为四维向量。
[0014]
作为本发明所述的基于跨模态特征融合的多任务加密网络流量分类方法的一种优选方案,其中:所述标准化指将每个有效载荷的每个字节对应的[0,255]之间的值除以255,使其变为[0,1]之间的值,则所述每个有效载荷变为一个不超过128维的向量。
[0015]
作为本发明所述的基于跨模态特征融合的多任务加密网络流量分类方法的一种优选方案,其中:所述预处理后的格式化样本结构包括,每个格式化样本都包含n
p
个来自有效载荷的不超过128维的向量,定义该信息为有效载荷,和nh个来自统计信息的4维的向量,定义该信息为统计信息,所述n
p
和nh根据采样步骤获得,由于payload和header来源和数据形式不同,因此也称为多模态异构输入,基于所述原始流量第n个包的有效载荷和统计信息,分别用payloadn和headern表示。
[0016]
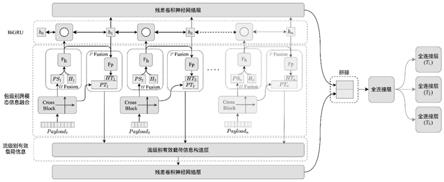
作为本发明所述的基于跨模态特征融合的多任务加密网络流量分类方法的一种优选方案,其中:所述基于特征融合技术的多模态多任务深度神经网络所包含的结构包括双路特征提取模块、包级别统计信息融合模块、bigru layer、包级别有效载荷融合模块、流级别有效载荷信息构造层、残差卷积神经网络层、分类头。
[0017]
作为本发明所述的基于跨模态特征融合的多任务加密网络流量分类方法的一种优选方案,其中:将预处理后获得的格式化样本输入至训练完成后的基于特征融合技术的多模态多任务深度神经网络,得到所述对于每个任务对应的预测向量,其中网络将输入转化为预测的过程包括,在cross block中输入的payload被添加线性位置编码并扩展到两个维度后送入卷积神经网络中,所述卷积神经网络的输出为pt,其中,pt是一个包含若干32维度向量的序列,序列长度由输入的payload决定,用以提取ps的网络块由两层全连接层构成,其输入为pt,且其输出的每个ps尺寸都为32;在h fusion中,网络块fh为单层全连接层,其输入维度为32+4,输出维度为24,并跟随着一个relu激活函数,则h fusion将phn和对应headern拼合并输出24维的向量rhn;所述h fusion输出的每个rh向量都被输入一个bigru层以获得流级别的统计信息,所述bigru输出每个64维向量hn和与之对应的rhn被合并为尺寸为88维度的向量并输入p fusion中的网络块f
p
中,所述f
p
为单层全连接层,其输入维度数为88,输出维度数为45,将f
p
的输出变为3
×
15的矩阵,并根据ptn的真实长度进行截断再与ptn拼合获得p fusion输出rpn,所述rpn具有宽度35;对于f
p
的输出,需要在re-assamble层合并它们并添加一个维度的位置编码以构造流级别的有效载荷信息,此时其通道数为36;通过包级别跨模态融合携带了一部分有效载荷信息的流级别统计信息[h1,
…
,hn]和通过包级别跨模态融合携带了一部分统计信息的流级别有效载荷的输出,利用两个类似的残差卷积神经网络层抽取流级别的信息,两个不同的残差cnn网络都是由多个残差网络块堆叠而成,输出均为128维度的向量,所述两个128维向量是提取出的流级别统计特征和流级别有效载荷特征;在所述分类头中,融合流级别的统计特征和有效载荷特征,并给出多标签预测。
[0018]
本发明的有益效果:本发明能实现对流量特征的自动提取,融合,并根据融合后的结果做出多任务预测,该方法具有通用性,并不针对特定的网络环境、特定的应用场景,与基于规则的方法相比,该方法可以适应不同加密技术、混淆技术带来的流量特征变化;本发明实现了包级别和流级别统计特征和有效载荷的融合;还实现了通过双路特征提取模块(cross block)抽取了每个数据包的有效载荷低阶的时序特征和全局统计特征,并使用这种全局统计特征指导对有效载荷时序特征的进一步提取;本发明还将残差神经网络与线性位置编码相结合,改善了特征提取的效果;本发明的模型相比至2021年为止其他基于深度
神经网络具有更好的分类效果。
附图说明
[0019]
为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其它的附图。其中:
[0020]
图1为本发明一个实施例提供的一种基于跨模态特征融合的多任务加密网络流量分类方法的分类模型的整体结构示意图;
[0021]
图2为本发明一个实施例提供的一种基于跨模态特征融合的多任务加密网络流量分类方法的模型结构简化后的数据流向示意图;
[0022]
图3为本发明一个实施例提供的一种基于跨模态特征融合的多任务加密网络流量分类方法的cross block、h fusion和p fusion构成的局部模块示意图;
[0023]
图4为本发明一个实施例提供的一种基于跨模态特征融合的多任务加密网络流量分类方法的cross block简要结构示意图;
[0024]
图5为本发明一个实施例提供的一种基于跨模态特征融合的多任务加密网络流量分类方法的ht和pt对齐示意图;
[0025]
图6为本发明一个实施例提供的一种基于跨模态特征融合的多任务加密网络流量分类方法的re-assamble层结构简述示意图;
[0026]
图7为本发明一个实施例提供的一种基于跨模态特征融合的多任务加密网络流量分类方法的一个残差神经网络块示意图;
[0027]
图8为本发明一个实施例提供的一种基于跨模态特征融合的多任务加密网络流量分类方法的分类头的结构和参数示意图;
[0028]
图9为本发明一个实施例提供的一种基于跨模态特征融合的多任务加密网络流量分类方法的两种方法的召回率和精确度实验结果示意图。
具体实施方式
[0029]
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合说明书附图对本发明的具体实施方式做详细的说明,显然所描述的实施例是本发明的一部分实施例,而不是全部实施例。基于本发明中的实施例,本领域普通人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本发明的保护的范围。
[0030]
在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是本发明还可以采用其他不同于在此描述的其它方式来实施,本领域技术人员可以在不违背本发明内涵的情况下做类似推广,因此本发明不受下面公开的具体实施例的限制。
[0031]
其次,此处所称的“一个实施例”或“实施例”是指可包含于本发明至少一个实现方式中的特定特征、结构或特性。在本说明书中不同地方出现的“在一个实施例中”并非均指同一个实施例,也不是单独的或选择性的与其他实施例互相排斥的实施例。
[0032]
本发明结合示意图进行详细描述,在详述本发明实施例时,为便于说明,表示器件结构的剖面图会不依一般比例作局部放大,而且所述示意图只是示例,其在此不应限制本
发明保护的范围。此外,在实际制作中应包含长度、宽度及深度的三维空间尺寸。
[0033]
同时在本发明的描述中,需要说明的是,术语中的“上、下、内和外”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。此外,术语“第一、第二或第三”仅用于描述目的,而不能理解为指示或暗示相对重要性。
[0034]
本发明中除非另有明确的规定和限定,术语“安装、相连、连接”应做广义理解,例如:可以是固定连接、可拆卸连接或一体式连接;同样可以是机械连接、电连接或直接连接,也可以通过中间媒介间接相连,也可以是两个元件内部的连通。对于本领域的普通技术人员而言,可以具体情况理解上述术语在本发明中的具体含义。
[0035]
实施例1
[0036]
参照图1~8,为本发明的一个实施例,提供了一种基于跨模态特征融合的多任务加密网络流量分类方法,包括:
[0037]
s1:获取待识别的原始流量。
[0038]
需要说明的是,待识别的原始流量包括:
[0039]
一组具有相同5元组的数据包,5元组包括源端口、ip地址、目的端口、ip地址和协议,且这里掉换方向(即交换源、目的端口的ip地址和端口号)的数据包也认为属于这个流。
[0040]
其中,一个流可能有多种属性,例如,这是一个“使用vpn协议加密的,爱奇艺软件发出的,视频流”,可以认为一个3任务的流:加密协议=vpn,服务类型=视频流,应用名称=爱奇艺。
[0041]
s2:预处理原始流量,并获得预处理后的格式化样本。
[0042]
需要说明的是,预处理原始流量包括采样、无偏化预处理、数据格式转换和标准化。
[0043]
其中,采样和无偏化预处理指从原始流量中采样最多784字节的有效载荷和至多32个包的统计信息,有效载荷采样指从原始流量中开头每个数据包的传输层有效载荷选取开头128字节(若不足128字节则选取全部有效载荷,不进行零填充),直到达到784字节或是到达流的最后一个包,总共从n
p
个数据包中采样;统计信息采样指从原始流量中开头每个数据包提取统计信息4元组《有效载荷大小,窗口大小(仅tcp数据包有该信息,udp数据包该项设为0),相对于第一个数据包的到达时间,方向(第一个数据包为0,后续数据包与第一个数据包同向则为0,与第一个数据包反向则为1)》,总共从nh个数据包中采样;因为该过程抛弃会导致模型分类性能被夸大的ip地址和端口等有偏信息,所以也称为无偏化预处理。
[0044]
数据格式转换指采样获得的信息不适合作为深度神经网络的输入,因此需要将采集到的每个有效载荷的每个字节视为[0,255]之间的值,每个包对应的统计信息四元组中的数据包的到达时间加1后取对数(因为这个值可能非常大),再将整个四元组变为四维向量。
[0045]
标准化指将每个有效载荷的每个字节对应的[0,255]之间的值除以255,使其变为[0,1]之间的值,因此每个有效载荷变为一个不超过128维的向量。
[0046]
进一步的,预处理后的格式化样本结构包括:
[0047]
经过预处理后,每个格式化样本都包含n
p
个来自有效载荷的不超过128维的向量,
一维卷积层-4243291relu一维卷积层-5323291relu最大池化层-6323233-[0060]
包级别统计信息融合模块(h fusion),h fusion的结构非常简单,其仅具有一个由全连接层构成的网络块fh。由于每个通过cross block提取出的有效载荷的统计信息ps和输入的header都具由固定的长度,因此对于第n个包,可以简单的将对应的psn和对应输入的headern拼接,并送入fh中,而fh的输出即为富信息统计特征rhn(rich header,rh);需要注意,并非所有的包都具有有效载荷,特别是一些上传和下载不平衡类型的应用的流量可能具有大量不带有任何有效载荷的数据包,因此还需要为这种数据包准备一个ps占位符,即一个全零向量。
[0061]
bigru layer,对于每个数据包,h fusion都输出一个相同长度的rhn,且序列[rh1,rh2,....,rhn]含有丰富的时序信息,因此理论上很适合由bigru构造和处理流级别统计信息,bigru的输入为每一个包对应的rhn,输出为[h1,h2,
…
,hn];其中,循环神经网络(recurrent neural network,rnn)在学习和处理时序特征方面扮演了一个重要的角色,相比于存在梯度爆炸和梯度弥散的rnn网络,门控循环神经网络(gate recurrent unit,gru)和长短期记忆神经网络(long-short term memory,lstm)都添加了控制门(gate)来控制信息的流动,这使得它们在分析时序信息时有更好的表现,相比lstm,gru计算更快且性能与lstm很接近,而双向门控循环神经网络(bidirectional gate recurrent unit,bigru)可以看作是两个方向不同的gru输出构成的向量,这可以用下式表示:
[0062][0063][0064][0065]
其中,x
t
为bigru的输入,h
t
为bigru的输出,和分别是前向和反向gru在t-1时刻的输出,h0为零向量,gru可以使用下式表示:
[0066]zt
=σ(wzx
t
+u
zht+1
)
[0067]rt
=σ(w
t
x
t
+u
tht-1
)
[0068][0069][0070]
其中,z
t
为更新门,更新激活状态时的逻辑门,r
t
是重置门,决定备选激活时,是否要放弃以前的激活状态h
t-1
,是备选激活,接收[x
t
,h
t-1
],h
t
是激活状态,是gru的隐层,接受wz,w
t
,uz,u
t
为参数。
[0071]
包级别有效载荷融合模块(p fusion),类似h fusion,p fusion同样使用一个全连接网络块f
p
聚合信息,但f
p
聚合的并不是来自有效载荷ptn和来自输入的headern,而是聚合局部的统计信息rhn和对应的带有全局信息的bigru输出hn,这一步的目的是实现“包级别-流级别”的信息融合,即通过流级别中的上下文信息扩充包级别中的信息。f
p
的输出为
带有时序信息的有效载荷特征(header time series feature,htn),如图5所示,进一步的,调整htn形状,使其从一维向量变为矩阵,并修剪这个宽度直到其和ptn具有相同的宽度,拼接每个htn和ptn,即可获得p fusion输出富信息有效载荷时序特征(rich payload time series feature,rpn)。
[0072]
流级别有效载荷信息构造层(re-assamble layer),其结构如图6所示,re-assamble layer将包级别的有效载荷合并为流级别的有效载荷信息。将p fusion输出的每个rpn合并,并且进一步的为之添加线性位置编码,这种线性位置编码占用一个维度,在合并后第i个位置的值可以指示每个向量在整个流中的绝对位置,以及不同两个向量的相对位置。
[0073]
残差卷积神经网络层(residual convolution neural network layer,residual cnn layer),流级别的header和payload特征提取各需要一个残差卷积神经网络层,这两个残差卷积神经网络层结构相似,都是由多个残差卷积神经网络块构成,差卷积神经网络块结构如图7所示,每个残差卷积网络块都包含一个主分支和一个“短路(shortcut)”分支,主干分支由两个核为3的一维卷积神经网络(1 dimension convolution neural network,1d-cnn)构成,而“短路”分支由一个核为1的1d-cnn构成;“短路”分支的存在将模型的映射由y=f(x)变为y=f(x)+x;因此,网络块实际要学习的映射由x
→
y变为x
→
y-x(f(x)=y-x)线性转换(projection)和非线性转换间寻求一个平衡,因此能够很好的解决退化问题;最后,一种特殊情况是,当不需要降采样且输入输出都有相同的通道数时,“短路”分支中的1d-cnn可以被移除。
[0074]
分类头(classification head),分类头需要接收residual cnn layers输出的流级别特征,融合并最终给出流量的多任务(多标签)预测,假设需要解决v=1,
…
,v个不同的流量分类问题(任务),正式的,对于每个流量的第v个任务tv,在这个任务的所有lv个类别中,它的标签为lv∈{1,
…
,lv},类似于包级别的融合,流级别的融合也是将统计信息和有效载荷信息合并输入全连接层(stream-level fusion,sf)中;对于每个分类任务,都需要一个任务特定网络块(task specific block,tsv)来给出最终的分类预测,其中,每一个ts网络块的输入都是sf的输出,由于流量分类任务可能有相关性,例如服务类型和应用类型,同时学习多个任务,有助于模型学习到在多个任务间共享的信息,即通过融合不同任务的监督信息增强模型的泛化能力。
[0075]
更进一步的,如图2所示,为模型结构简化后的数据流向,与之对应的,将预处理后获得的格式化样本输入至训练完成后的基于特征融合技术的多模态多任务深度神经网络,得到对于每个任务对应的预测向量,其中网络将输入转化为预测的过程如下:
[0076]
首先,在cross block中输入的payload被添加线性位置编码并扩展到两个维度后送入卷积神经网络中(卷积神经网络中包含两层核和步长为3,padding为2的最大池化层),其参数和结构如表1所示,由于每个payloadn的最大长度为128,因此卷积神经网络输出的pt最大长度为15(((128+2)//3+2)//3=15,其中//表示整除,两个3来自两层核和步长均为3的最大池化层)且具有宽度32(宽度是由表1中卷积神经网络的结构和参数决定的),用以提取ps的网络块由两层全连接层构成,第一层输入是维度为480的压平后的pt(15
×
32),输出维度为32,第二层输入输出维度均为32,且带由relu激活函数;当pt长度不足15时,需要
先零填充到15再输入,因此输出的每个ps尺寸都为32。
[0077]
接着,在h fusion中,网络块fh为单层全连接层,其输入维度为32+4(即为phn和对应headern拼合后的维度和),输出维度为24,并跟随着一个relu激活函数,因此h fusion将phn和对应headern拼合并输出24维的向量rhn。
[0078]
随后,h fusion输出的每个rh向量都被输入一个bigru层以获得流级别的统计信息;bigru的输入维度为24,隐藏层维度为32,且仅包含单层。bigru层后边跟随着一个dropout层,其参数dropout
p
=0.2;接着,bigru输出每个64维向量hn和与之对应的rhn被合并为尺寸为88维度的向量并输入p fusion中的网络块f
p
中。类似fh,f
p
也为单层全连接层,其输入维度数为88(即为pt和每个输入的header向量的维度和),输出维度数为45。如图5所示,为了将f
p
的输出和对应的长度介于[0,15]之间的的ptn连接,需要先将f
p
的输出变为3
×
15的矩阵,并根据ptn的真实长度进行截断再与ptn拼合获得p fusion输出rpn,此时rpn具有宽度35(32+3,32为ptn的宽度,3为f
p
的输出变化形状后的宽度)。如图3所示,可以发现,cross block,h fusion和p fusion构成了一个信息循环,通过cross block提取出的有效载荷统计信息ps经过h fusion和p fusion后,又与由cross block提取出的有效载荷时序信息融合,这一设计是为了在后续提取过程中利用每个有效载荷的全局性的统计信息帮助其局部的时序信息提取。
[0079]
接着,对于f
p
的输出(携带一定统计特征的包级别有效载荷信息),需要在re-assamble层合并它们并添加一个维度的位置编码以构造流级别的有效载荷信息,此时其通道数为36(35+1)。
[0080]
此时,通过包级别跨模态融合(h fusion)携带了一部分有效载荷信息的流级别统计信息[h1,
…
,hn](由bigru构造)和通过包级别跨模态融合(p fusion)携带了一部分统计信息的流级别有效载荷(re-assamble layer)的输出,需要通过两个类似的残差卷积神经网络层抽取流级别的信息,两个不同的残差cnn网络都是由多个残差网络块堆叠而成,输出均为128维度的向量(由残差神经网络结构决定),这两个128维向量是提取出的流级别统计特征和流级别有效载荷特征,其中,用以进行流级别统计特征提取和有效载荷特征提取的残差网络参数分别列在表2和表3中。
[0081]
表2:残差网络参数表。
[0082][0083]
表3:残差网络参数表。
fusion机制实现的,流级别特征的融合主要是通过分类头实现的;本发明还实现了通过双路特征提取模块(cross block)抽取了每个数据包的有效载荷低阶的时序特征和全局统计特征,并使用这种全局统计特征指导对有效载荷时序特征的进一步提取;最后,本发明还将残差神经网络与线性位置编码相结合,改善了特征提取的效果;这三个设计共同使本发明的模型相比至2021年为止其他基于深度神经网络具有更好的分类效果。
[0089]
实施例2
[0090]
参照图9为本发明另一个实施例,该实施例不同于第一个实施例的是,提供了一种基于跨模态特征融合的多任务加密网络流量分类方法的验证测试,为对本方法中采用的技术效果加以验证说明,本实施例采用传统技术方案与本发明方法进行对比测试,以科学论证的手段对比试验结果,以验证本方法所具有的真实效果。
[0091]
本实施例选择的作为对比的方法时间跨度为2017到2021,包括:
[0092]
1. 1d-cnn(wang et al.):2017,end-to-end encrypted traffic classification with one-dimensional convolution neural networks;
[0093]
2.hybrid(lopez-martin et al.):2017,network traffic classifier with convolutional and recurrent neural networks for internet of things;
[0094]
3. 2-cnn(huang et al.):2018,automatic multi-task learning system for abnormal network traffic detection.international;
[0095]
4.mlp(sun et al.):2019,common knowledge based and one-shot learning enabled multi-task traffic classification;
[0096]
5.mlp(zhao et al.):2019,multi-task network anomaly detection using federated learning;
[0097]
6. 1d-cnn(rezaei and liu):2020,multitask learning for network traffic classification;
[0098]
7.distiller(aceto et al.):2021,distiller:encrypted traffic classification via multimodal multitask deep learning;
[0099]
为了进行公平的比较,本实施例参照distiller(aceto et al.)的方法对所有模型进行调整,以尽量保证使用相同的模型和相同的任务设置。但是方法1~6受模型结构所限,只能接受单模态输入,因此本实施例使用(both)、(hdr)和(pay)表示模型输入,(pay)表示输入为有效载荷,hdr表示输入为统计信息,(both)表明多模态输入,即二者都有。
[0100]
所有的实验都在一台python3.8,intel i9 cpu,2080ti显卡的测试平台上使用pytorch1.8深度学习框架实现,使用scikit-learn库评估所有实验的结果,对数据集的切分和解析工作我们使用scapy库实现,对于所有方法都训练60轮,每个任务的权重总是设为相等的值,即λ1=λ2=λ3=0.33,训练时使用adam优化器,其初始学习率lr=1e-3,参数weight_decay=1e-4,每个batch尺寸都为64,最后所有的实验都进行了5折交叉验证,因此训练集和测试集分割比为5:1,对于每项测试的结果,本实施例报告5次测试的平均值和标准差。
[0101]
本实施例选择的数据集为三个公开数据集,分别为iscx vpn 2016数据集,iscx tor 2016数据集和ustc tfc 2016数据集,这三个数据集都包括多个任务,具体任务和类别列举在表4中。
[0102]
表4:数据集、任务和类别表。
[0103][0104]
在iscx vpn 2016数据集对比测试结果如表5所示:
[0105]
表5:对比测试结果表。
[0106][0107][0108]
表中tp表示模型参数量,括号内信息为标准差。由于distiller(aceto etal.)也进行了同样的实验,因此表中(ori)表示distiller(aceto et al.)中的结果,(rep)表示复现结果。可以发现,本方法在大多数指标上更优。
[0109]
进一步的,本发明还比较了最好的两种方法的召回率(recall)和精确度
(precision),如图9所示,类似的,在iscx tor 2016数据集上实验结果如表6所示:
[0110]
表6:实验结果表。
[0111][0112]
在ustc tfc 2016数据集上实验结果如表7所示:
[0113]
表7:实验结果表。
[0114][0115][0116]
从上表中可以看出,在iscx tor 2016和ustc tfc 2016数据集上,本发明提出的方法在所有任务上都超越了其他方法。
[0117]
应说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的精神和范围,其均应涵盖在本发明的权利要求范围当中。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1