预训练语言模型的训练方法、装置、计算机设备和介质与流程
1.本公开涉及计算机技术领域,更具体而言,涉及一种预训练语言模型的训练方法、装置、计算机设备和介质。
背景技术:
2.随着深度学习技术和全球国际化的不断发展,业务国际化趋势更加明显,能处理多国语言的人工智能(ai)技术的需求日渐增多。目前,在自然语言处理领域,预训练语言模型是一种实现ai的方法。对于覆盖不同语言的适用于特定下游任务的自然语言处理模型,预训练语言模型需要经过大规模下游任务相关的覆盖不同语言的训练样本数据的充分微调,而国际化业务(例如,跨境电商业务、跨境物流业务和国际业务智能客服等)往往覆盖不同语言,并且国际化业务相关的低资源语言(小语种)样本数据通常较为稀缺,使得下游任务相关的低资源语言的训练样本数据对预训练语言模型微调训练不足,这降低了低资源语言场景下自然语言处理模型处理下游任务的性能,也使得低资源语言样本数据稀缺的下游任务不适合于通过微调预训练语言模型而获得适用于下游任务的自然语言处理模型,这降低了不同语言场景下预训练语言模型所能适用的下游任务的种类范围。
技术实现要素:
3.有鉴于此,本公开旨在提高低资源语言场景下自然语言处理模型处理下游任务的性能和不同语言场景下预训练语言模型所能适用的下游任务的种类范围。
4.为了达到这个目的,根据本公开的一个方面,提供了一种预训练语言模型的训练方法,包括:
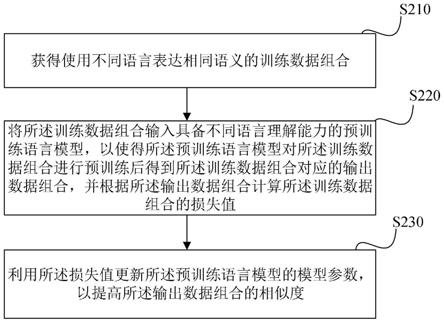
5.获得使用不同语言表达相同语义的训练数据组合;
6.将所述训练数据组合输入具备不同语言理解能力的预训练语言模型,以使得对所述训练数据组合进行预训练后得到所述训练数据组合对应的输出数据组合,并根据所述输出数据组合计算所述训练数据组合的损失值;
7.利用所述损失值更新所述预训练语言模型的模型参数,以提高所述输出数据组合的相似度。
8.可选地,所述训练数据组合至少包括使用第一语言表达第一语义的第一文本和使用第二语言表达第一语义的第二文本,所述第一文本包括多个第一分词,所述第二文本包括多个第二分词,
9.将所述训练数据组合输入具备不同语言理解能力的预训练语言模型,以使得所述预训练语言模型对所述训练数据组合进行预训练后得到所述训练数据组合对应的输出数据组合,并根据所述输出数据组合计算所述训练数据组合的损失值包括:
10.将所述多个第一分词输入所述预训练语言模型,由所述预训练语言模型得到多个第一分词向量;
11.将所述多个第二分词输入所述预训练语言模型,由所述预训练语言模型得到多个
第二分词向量;
12.基于所述多个第一分词向量和所述多个第二分词向量,计算所述第一文本的向量表示和所述第二文本的向量表示之间的相似度损失值。
13.可选地,将所述训练数据组合输入具备不同语言理解能力的预训练语言模型,以使得所述预训练语言模型对所述训练数据组合进行预训练后得到所述训练数据组合对应的输出数据组合还包括:
14.将所述第一文本输入所述预训练语言模型,由所述预训练语言模型得到第一文本预测值;
15.将所述第二文本输入所述预训练语言模型,由所述预训练语言模型得到第二文本预测值;
16.根据所述输出数据组合计算所述训练数据组合的损失值还包括:
17.基于所述第一文本预测值和所述第一文本的标签值,计算所述第一文本的预测损失值;
18.基于所述第二文本预测值和所述第二文本的标签值,计算所述第二文本的预测损失值。
19.可选地,利用所述损失值更新所述预训练语言模型的模型参数之前,所述方法还包括:
20.计算所述相似度损失值、所述第一文本的预测损失值和所述第二文本的预测损失值的线性加权和,作为所述训练数据组合的损失值。
21.可选地,所述训练数据组合包括多个双语数据对,利用所述损失值更新所述预训练语言模型的模型参数包括:
22.利用所述多个双语数据对的损失值的均值,采用深度学习优化算法更新所述预训练语言模型的模型参数。
23.可选地,所述基于所述多个第一分词向量和所述多个第二分词向量,计算所述第一文本的向量表示和所述第二文本的向量表示之间的相似度损失值包括:
24.计算所述多个第一分词向量的均值,作为所述第一文本的文本向量;
25.计算所述多个第二分词向量的均值,作为所述第二文本的文本向量;
26.计算所述第一文本的文本向量和所述第二文本的文本向量之间的向量相似度,基于所述向量相似度计算所述相似度损失值。
27.可选地,所述将所述多个第一分词输入所述预训练语言模型,由所述预训练语言模型得到多个第一分词向量包括:
28.将所述多个第一分词输入所述预训练语言模型,由所述预训练语言模型的第i层输出所述多个第一分词向量;
29.所述将所述多个第二分词输入所述预训练语言模型,由所述预训练语言模型得到多个第二分词向量包括:
30.将所述多个第二分词输入所述预训练语言模型,由所述预训练语言模型的第i层输出所述多个第二分词向量,i《n,n为所述预训练语言模型的总层数。
31.可选地,所述获得使用不同语言表达相同语义的训练数据组合包括:
32.获取训练样本的译文文本;
33.对所述训练样本的原文文本和译文文本进行分词处理,得到所述使用不同语言表达相同语义的训练数据组合。
34.根据本公开的一个方面,提供了一种预训练语言模型的训练装置,包括:
35.训练数据组合获取单元,用于获得使用不同语言表达相同语义的训练数据组合;
36.损失值计算单元,用于将所述训练数据组合输入具备不同语言理解能力的预训练语言模型,以使得所述预训练语言模型对所述训练数据组合进行预训练后得到所述训练数据组合对应的输出数据组合,并根据所述输出数据组合计算所述训练数据组合的损失值;
37.模型参数更新单元,用于利用所述损失值更新所述预训练语言模型的模型参数,以提高所述输出数据组合的相似度。
38.根据本公开的一个方面,提供了一种计算机设备,包括:
39.存储器,用于存储计算机可执行代码;
40.处理器,用于执行所述计算机可执行代码,以实现如上所述的方法。
41.根据本公开的一个方面,提供了一种计算机可读介质,包括计算机可执行代码,所述计算机可执行代码被处理器执行时实现如上所述的方法。
42.在本公开实施例中,利用了使用不同语言表达相同语义的训练数据组合是下游任务的具有相同语义但用不同语言表示的语料这一特点,在预训练语言模型的微调过程中,预训练语言模型对训练数据组合进行预训练后得到训练数据组合对应的输出数据组合,利用输出数据组合计算训练数据组合的损失值,基于损失值更新预训练语言模型的模型参数,这样,增加了输出数据组合的相似度,通过多次迭代,使得预训练语言模型能够在微调过程中将使用不同语言表达相同语义的训练数据组合表示到相似的语义空间,提升了模型的跨语言表示能力。这样,对于低资源语言就无须特定下游任务的训练样本,只需提供特定下游任务的大量高资源语言的训练样本,对预训练语言模型进行微调,即可获得支持低资源语言的适用于处理特定下游任务的自然语言处理模型,从而提高了低资源语言场景下自然语言处理模型处理下游任务的性能,也提高了不同语言场景下预训练语言模型所能适用的下游任务的种类范围。
附图说明
43.通过参考以下附图对本公开实施例的描述,本公开的上述以及其它目的、特征和优点将更为清楚,在附图中:
44.图1示出了根据本公开实施例的预训练语言模型的训练方法所应用的体系架构图。
45.图2示出了根据本公开一个实施例的预训练语言模型的训练方法的流程图。
46.图3示出了根据本公开一个实施例的预训练语言模型的训练装置的内部结构图。
47.图4示出了根据本公开一个实施例的双语数据对的数据结构。
48.图5示出了执行根据本公开一个实施例的预训练语言模型的训练方法的计算机设备的硬件图。
具体实施方式
49.以下基于实施例对本公开进行描述,但是本公开并不仅仅限于这些实施例。在下
文对本公开的细节描述中,详尽描述了一些特定的细节部分。对本领域技术人员来说没有这些细节部分的描述也可以完全理解本公开。为了避免混淆本公开的实质,公知的方法、过程、流程没有详细叙述。另外附图不一定是按比例绘制的。
50.本公开的应用场景和应用的体系架构
51.本公开实施例的应用场景可以包括形成具备不同语言理解能力的适用于特定下游任务的自然语言处理模型,以便于使用该自然语言处理模型完成国际化业务(例如,跨境电商业务、跨境物流业务和国际业务智能客服等)中的自然语言处理(natural language processing,nlp)。
52.图1示出了根据本公开实施例的预训练语言模型的训练方法所应用的体系架构图。该体系构架包括训练设备110、执行设备120、数据库130和数据存储系统140。训练设备110包括预训练语言模型111和模型微调装置112,执行设备120包括自然语言处理模型121。
53.本公开实施例中使用“预训练-微调”的模式来生成具有不同语言理解能力的适用于特定下游任务的自然语言处理模型。自然语言(natural language)即人类语言,自然语言处理就是对人类语言的处理。自然语言处理是以一种智能与高效的方式,对文本数据进行系统化分析、理解与信息提取的过程。示例性的,自然语言处理的下游任务可以包括自动摘要(automatic summarization)、机器翻译(machine translation,mt)、命名实体识别(named entity recognition,ner)、关系提取(relation extraction,re)、信息抽取(information extraction,ie)、情感分析、语音识别(speech recognition)、问答系统(question answering)以及主题分割等等。预训练语言模型是使用训练数据集进行预训练得到的网络模型,可根据不同需求使用下游任务相关的新的训练数据集微调预训练语言模型以获得适用于不同下游任务的自然语言处理模型。对预训练语言模型的微调是针对于具体下游任务使用新的数据集在预训练语言模型上进行微调。由于预训练语言模型需要经过大规模语料上的充分预训练,因而对预训练语言模型进行微调能够在大部分自然语言处理任务上取得优异的性能。
54.在一些实施例中,如图1所示,预训练语言模型111是具有不同语言理解力的预训练模型,预训练语言模型111的预训练方法如下:可以构造一个由覆盖不同语言的大量训练样本组成的样本集合,其中每个训练样本包括用一个语言表示的语料,以及预先为该语料打好的标签,该标签是该训练样本的真实值。将训练样本集合中的每个训练样本输入预训练语言模型,由预训练语言模型输出学习得到的预测值。将该预测值与标签进行比对,如果对于训练样本集合中,至少预定比例(例如95%以上)的训练样本的输出结果是与标签一致的,则说明该模型预训练成功,否则调整该模型中各隐含层中各隐含节点的参数,使得至少预定比例(例如95%以上)的训练样本的输出结果是与标签一致的。当预训练语言模型预训练成功后,一般要经受测试的过程才能正式投入使用。其可以采用一般机器学习模型的通用测试方法,故不赘述。目前常见的覆盖不同语言的预训练模型有xml、xml-r以及veco。数据库130中存储有用于对预训练语言模型111进行微调的训练样本集合。数据库130可以体现为任意形式的存储介质。在微调阶段,训练设备110调用数据库130中存储的训练样本集合,模型微调装置112利用训练样本集合对预训练语言模型111进行迭代训练,待模型收敛,生成具有不同语言理解力的自然语言处理模型121。模型微调装置112是本公开实施例的主要实现部件。由于模型微调装置112微调预训练语言模型111以生成自然语言处理模型121
的过程将在下文中详细说明,故不再赘述。
55.在推理阶段,执行设备120可以调用数据存储系统140中的下游任务相关的数据、代码等,也可以将数据、指令等存入数据存储系统140中。数据存储系统140可以配置于执行设备120中,也可是执行设备120外部的存储器。执行设备120调用自然语言处理模型121执行下游任务。在一些场景中,执行设备120可以是翻译设备(例如,智能终端、平板电脑等设备)。在训练设备110生成适用于下游翻译任务的自然语言处理模型121后,在推理阶段,执行设备120可调用自然语言处理模型121执行翻译任务。
56.根据本公开实施例的预训练语言模型的训练方法
57.根据本公开的一个实施例,提供了一种预训练语言模型的训练方法。该训练方法可以由模型微调装置112执行。在训练设备110为单台计算机的情况下,模型微调装置112是单台计算机的一部分,该预训练语言模型的训练方法由该单台计算机的一部分执行。在训练设备110为多台计算机构成的集合的情况下,模型微调装置112可以是其中的单台计算机,该预训练语言模型的训练方法由该单台计算机执行。在训练设备110为云的形式的情况下,模型微调装置112是云端的一系列计算机或计算机上的部分,该预训练语言模型的训练方法由云端的一系列计算机或计算机上的部分执行。
58.如图2所示,根据本公开一个实施例的预训练语言模型的训练方法包括:步骤s210、获得使用不同语言表达相同语义的训练数据组合;步骤s220、将所述训练数据组合输入具备不同语言理解能力的预训练语言模型,以使得所述预训练语言模型对所述训练数据组合进行预训练后得到所述训练数据组合对应的输出数据组合,并根据所述输出数据组合计算所述训练数据组合的损失值;步骤s230、利用所述损失值更新所述预训练语言模型的模型参数,以提高所述输出数据组合的相似度。
59.下面分别对以上步骤进行详细描述。
60.在步骤s210中,获得使用不同语言表达相同语义的训练数据组合。
61.下游任务是使用“预训练-微调”的模式生成的自然语言处理模型所要处理的特定任务,例如是句子关系提取任务、翻译任务、观点角色标注任务、自动生成观点任务和生成式应答任务等下游任务中的一种。为了生成支持更多语言并且在特定下游任务上取得很好的自然语言处理效果的自然语言处理模型,这里需要使用覆盖尽可能多的语言的特定下游任务的训练样本集合来对具有不同语言理解能力的预训练语言模型进行微调。训练样本集合包括覆盖不同语言的训练样本,其中每个训练样本包括用某一语言表示的特定下游任务(比如,句子关系提取任务、翻译任务、观点角色标注任务、自动生成观点任务和生成式应答任务等)的语料,以及预先为该语料打好的标签,该标签表示训练样本的真实值。可以从互联网上找到或者获取可用的训练样本集合中的语料,训练样本集合中的语料的具体表现方式并不进行限定,比如可以通过文本的方式表示,还可以通过语音的方式表示,再比如还可以通过图像的方式表示。在一个实施例中,预训练语言模型的输入只能是文本方式表示的训练语句,可以对语音方式表示的训练语句进行语音识别处理,以转换为文本方式表示的训练语句,还可以对图像方式表示的训练语句进行图像识别处理,以转换为文本方式表示的训练语句。由于打标签技术为现有技术,故不赘述。
62.在一些实施例中,训练样本包括训练数据组合,这里的使用不同语言表达相同语义的训练数据组合至少包括使用第一语言表达第一语义的第一文本和使用第二语言表达
第一语义的第二文本,第一语言和第二语言可以是任意两种语言。第一文本可以包括多个第一分词,第二文本可以包括多个第二分词。在一些实施例中,第一文本是训练样本的语料的原文文本,而第二文本可以是训练样本的语料的译文文本。在一些实施例中,第一文本和第二文本构成双语数据对。比如,第一文本是“这次旅行需要认真计划”,第二文本为“the trip needs careful planning”,则“这次旅行需要认真计划”和“the trip needs careful planning”可以看做一个双语数据对,该双语数据对是中英平行语言对。应当理解,这里的双语数据对还可以是低资源语言的平行语言对(朝鲜语泰语平行语言对,越南语德语平行语言对等等)。
63.在一个实施例中,步骤s210包括:获取的训练样本的译文文本;对所述训练样本的原文文本和译文文本进行分词处理,得到所述使用不同语言表达相同语义的训练数据组合。
64.将训练样本的语料的原文文本翻译为译文文本,可以由软件和/或硬件实现的翻译机器实现,例如图3的翻译单元311。将训练样本的语料的原文文本输入翻译单元311即可得到训练样本的语料的译文文本。应当理解,本公开不应以此为限,任何获得训练样本的语料的译文文本的方式均在本公开的保护范围内。在一个示例中,如图4所示,训练样本的语料的原文文本为“how can you prove it,can you tell me how to prove it”,原文文本的标签为“蕴含关系”。训练样本的语料的译文文本为“你怎么能证明,你能告诉我怎么证明吗”,译文文本的标签同样为“蕴含关系”。训练样本的语料的原文文本“how can you prove it,can you tell me how to prove it”和译文文本“你怎么能证明,你能告诉我怎么证明吗”构成训练数据组合,该训练数据组合是中英平行语言对。
65.在一个实施例中,接着,对训练样本的语料的原文文本和译文文本进行分词处理,可以由软件和/或硬件实现的分词机器实现,例如图3的分词单元312,分词单元312可以将输入文本分割为多个最小语义单元(token)。将训练样本的语料的原文文本输入分词单元312即可得到原文文本的多个分词,将训练样本的语料的译文文本输入分词单元312即可得到译文文本的多个分词。分词处理目前有成熟技术,故不赘述。在一个示例中,如图4所示,训练样本的语料的原文文本“how can you prove it,can you tell me how to prove it”可以分词处理为多个分词:“how”、“can”、“you”、“prove”、“it”、“can”、“you”、“tell”、“me”、“how”、“to”、“prove”、“it”。训练样本的语料的译文文本可以分词处理为多个分词:“你”、“怎么”、“能”、“证明”、“你”、“能”、“告诉”、“我”、“怎么”、“证明”、“吗”。
66.在微调过程中,将训练样本集合中的每个训练样本的训练数据组合输入预训练语言模型,由预训练语言模型输出学习得到的输出数据组合。将输出数据组合分别与对应的标签进行比对,如果对于训练样本集合中,至少预定比例(例如95%以上)的训练样本的输出结果是与标签一致的,则说明该模型微调成功,否则使用本公开实施例的预训练语言模型的训练方法调整该模型中各隐含层中各隐含节点的参数,使得至少预定比例(例如95%以上)的训练样本的输出结果是与标签一致的。当预训练语言模型微调成功后,一般要经受测试的过程才能正式投入使用。其可以采用一般机器学习模型的通用测试方法,故不赘述。
67.在步骤s220中,将所述训练数据组合输入具备不同语言理解能力的预训练语言模型,以使得所述预训练语言模型对所述训练数据组合进行预训练后得到所述训练数据组合对应的输出数据组合,并根据所述输出数据组合计算所述训练数据组合的损失值。
68.这里的预训练语言模型是在覆盖不同语言的大规模语料上预训练得到的,预训练语言模型主要学习到处理语言的通用的基础知识。将上述的训练数据组合输入预训练语言模型,即可由预训练语言模型对训练数据组合进行预训练后得到训练数据组合对应的输出数据组合。在一个示例中,将训练样本的语料的原文文本“how can you prove it,can you tell me how to prove it”输入预训练语言模型可以得到该原文文本的预测值(可以是蕴含关系、矛盾关系或不相关中的一个)。将训练样本的语料的译文文本“你怎么能证明,你能告诉我怎么证明吗”输入预训练语言模型可以得到该译文文本的预测值(可以是蕴含关系、矛盾关系或不相关中的一个)。在一个示例中,将原文文本的分词“how”、“can”、“you”、“prove”、“it”、“can”、“you”、“tell”、“me”、“how”、“to”、“prove”、“it”分别输入预训练语言模型,由预训练语言模型可以分别得到对应的原文文本的分词向量。将译文文本的分词“你”、“怎么”、“能”、“证明”、“你”、“能”、“告诉”、“我”、“怎么”、“证明”、“吗”分别输入预训练语言模型,由预训练语言模型可以分别得到对应的译文文本的分词向量。
69.在深度神经网络中,损失函数通过计算模型预测值与真实值的差异来反映算法的性能优劣。因此,可以通过训练预训练语言模型寻找一组使损失函数值最小的模型参数,来获得性能最优的自然语言处理模型。在一些实施例中,损失函数值可以由以下几部分组成:训练样本的语料的原文文本的预测损失值、训练样本的语料的译文文本的预测损失值和训练数据组合的相似度损失值。训练样本的语料的原文文本的预测损失值是原文文本的真实标签值和模型预测值之间的损失值。训练样本的语料的译文文本的预测损失值是译文文本的真实标签值和模型预测值之间的损失值。训练数据组合的相似度损失值是原文文本的模型预测值和译文文本的模型预测值之间的损失值。
70.在一些实施例中,训练样本的语料的原文文本的预测损失值可以由软件和/或硬件实现的计算器实现,例如图3的第一文本预测损失值计算单元321。在一些实施例中,训练样本的语料的原文文本的预测损失值的计算方式包括:将训练样本的语料的原文文本输入预训练语言模型,由预训练语言模型得到训练样本的语料的原文文本的预测值;基于训练样本的语料的原文文本的预测值和训练样本的语料的原文文本的标签值,计算训练样本的语料的原文文本的预测损失值。在一个实施例中,可以使用比较常见的叉熵损失函数作为训练样本的语料的原文文本的预测损失值。训练样本的语料的原文文本的预测损失值的计算公式如下:
[0071][0072]
其中,是训练样本的语料的原文文本的预测损失值,y1是训练样本的语料的原文文本的标签值,是训练样本的语料的原文文本的预测值,为训练样本的语料的原文文本的第j个分词的预测值。
[0073]
应当理解,训练样本的语料的原文文本的预测损失值越小,预训练语言模型对原文文本的预测准确度越高。
[0074]
在一些实施例中,训练样本的语料的译文文本的预测损失值可以由软件和/或硬件实现的计算器实现,例如图3的第二文本预测损失值计算单元322。在一些实施例中,训练样本的语料的译文文本的预测损失值的计算方式包括:将训练样本的语料的译文文本输入预训练语言模型,由预训练语言模型得到训练样本的语料的译文文本的预测值;基于训练
样本的语料的译文文本的预测值和训练样本的语料的译文文本的标签值,计算训练样本的语料的译文文本的预测损失值。在一个实施例中,可以使用比较常见的叉熵损失函数作为训练样本的语料的译文文本的预测损失值。训练样本的语料的译文文本的预测损失值的计算公式如下:
[0075][0076]
其中,是训练样本的语料的译文文本的预测损失值,y2是训练样本的语料的译文文本的标签值,是训练样本的语料的译文文本的预测值,为训练样本的语料的译文文本的第j个分词的预测值。
[0077]
应当理解,训练样本的语料的译文文本的预测损失值越小,预训练语言模型对译文文本的预测准确度越高。
[0078]
在一些实施例中,训练数据组合的相似度损失值可以由软件和/或硬件实现的计算器实现,例如图3的相似度损失值计算单元323。在一些实施例中,相似度损失值的计算方式包括:将训练样本的语料的原文文本的多个分词输入预训练语言模型,由预训练语言模型得到对应于原文文本的多个分词向量;将训练样本的语料的译文文本的多个分词输入预训练语言模型,由预训练语言模型得到对应于译文文本的多个分词向量;基于对应于原文文本的多个分词向量和对应于译文文本的多个分词向量,计算训练样本的语料的原文文本的向量表示和训练样本的语料的译文文本的向量表示之间的相似度损失值。
[0079]
在一些实施例中,可以在预训练语言模型的中间层计算训练样本的语料的原文文本和译文文本的分词向量,原文文本和译文文本的分词向量计算方式包括:将训练样本的语料的原文文本的多个分词分别输入预训练语言模型,由预训练语言模型的第i层分别输出原文文本的多个分词对应的多个第一分词向量;将训练样本的语料的译文文本的多个分词分别输入预训练语言模型,由预训练语言模型的第i层分别输出译文文本的多个分词对应的多个分词向量。这里i《n,n为预训练语言模型的总层数。根据实验经验,可以选择应的多个分词向量。这里i《n,n为预训练语言模型的总层数。根据实验经验,可以选择表示向下取整数。这样,在预训练语言模型的中间层计算训练数据组合的分词向量,然后,基于训练数据组合的分词向量计算训练数据组合的向量表示之间的相似度损失值。应当理解,训练数据组合的相似度损失值越小,预训练语言模型对训练数据组合的预测相似度越高,也即是,可以在预训练语言模型的底层学习与语言无关的文本语义信息,在预训练语言模型的上层学习特定下游任务的知识。这种分层次的学习方法大大提升了预训练语言模型的泛化能力,也在一定程度上降低了预训练语言模型过拟合的风险。
[0080]
在一些实施例中,可以计算原文文本的向量表示和译文文本的向量表示之间的向量相似度,来衡量原文文本的向量表示和译文文本的向量表示之间的相似度损失值。在一个实施例中,原文文本的向量表示和译文文本的向量表示之间的相似度损失值的计算方式包括:计算原文文本的多个分词对应的多个分词向量的均值,作为原文文本的文本向量;计算译文文本的多个分词对应的多个分词向量的均值,作为译文文本的文本向量;计算原文文本的文本向量和译文文本的文本向量之间的向量相似度,基于向量相似度计算相似度损失值。向量相似度越大,相似度损失值越接近于0。在一个实施例中,原文文本的文本向量的计算公式如下:
[0081][0082]
其中,s1为训练样本的语料的原文文本的文本向量,n1为训练样本的语料的原文文本中分词的个数,为训练样本的语料的原文文本的第j个分词在预训练语言模型的第i层的输出,0≤j≤n1。
[0083]
在一个实施例中,译文文本的文本向量的计算公式如下:
[0084][0085]
其中,s2为训练样本的语料的译文文本的文本向量,n2为训练样本的语料的译文文本中分词的个数,为训练样本的语料的译文文本的第j个分词在预训练语言模型的第i层的输出,0≤j≤n2。
[0086]
在一个实施例中,相似度损失值的计算公式为:
[0087][0088]
其中,loss为训练样本的语料的原文文本和译文文本之间的相似度损失值,s1为训练样本的语料的原文文本的文本向量,s2为训练样本的语料的译文文本的文本向量,cos(s1,s2)为训练样本的语料的原文文本的文本向量和译文文本的文本向量之间的余弦相似度,sim_label为标签,sim_label=1表示训练样本的语料的原文文本和译文文本为正样本,0
°
≤原文文本的文本向量和译文文本的文本向量之间的夹角《90
°
,sim_label=0表示训练样本的语料的原文文本和译文文本为负样本,90
°
≤原文文本的文本向量和译文文本的文本向量之间的夹角≤180
°
。
[0089]
应当理解,在计算预训练语言模型的损失值时,加入了相似度损失值,使得预训练语言模型能够在微调过程中将使用不同语言表达相同语义的训练数据组合表示到相似的语义空间,提升了模型的跨语言表示能力。这样,在多语言场景下,大多数文本理解任务中更多关注的是文本的语义,文本向量表示仅和语义相关而和语言关联不大的话,那么,对于低资源语言就无须特定下游任务的训练样本,只需提供特定下游任务的大量高资源语言的训练样本,对预训练语言模型进行微调,即可获得支持低资源语言的适用于处理特定下游任务的自然语言处理模型,从而提高了低资源语言场景下自然语言处理模型处理下游任务的性能,也提高了多语言场景下预训练语言模型所能适用的下游任务的种类范围。
[0090]
在步骤s230,利用所述损失值更新所述预训练语言模型的模型参数,以提高所述输出数据组合的相似度。
[0091]
在一些实施例中,在利用损失值更新预训练语言模型的模型参数之前,计算相似度损失值、训练样本的语料的原文文本的预测损失值和训练样本的语料的译文文本的预测损失值的线性加权和,作为训练样本的训练数据组合的损失值。在一些实施例中,训练数据组合的损失值可以由软件和/或硬件实现的计算器实现,例如图3的加法器340。在一些实施例中,利用损失值更新预训练语言模型的模型参数可以由软件和/或硬件实现的参数更新器实现,例如图3的参数更新模块330。
[0092]
在一些实施例中,训练数据组合包括多个双语数据对。这里用于微调预训练语言模型的训练样本集合中包括大量的训练样本,每个训练样本均需要执行步骤s210和步骤s220的方法,得到每个训练样本的双语数据对的损失值。可以将多个训练样本数据打包成一个批次(batch),比如32个训练样本数据打包成一个整体,然后利用整个批次的多个双语数据对的损失值的均值,采用深度学习优化算法更新预训练语言模型的模型参数。由于采用深度学习优化算法更新预训练语言模型的模型参数为现有技术,故不赘述。这样,充分利用gpu的并行计算能力(一次可处理整批数据),提高了预训练语言模型的微调效率。调整模型参数后,预训练语言模型对原文文本的预测准确度、译文文本的预测准确度、以及原文文本的模型预测值和译文文本的模型预测值之间的相似度均提高。经过多次迭代微调训练后,即可生成支持更多语言并且在特定下游任务上取得很好的自然语言处理效果的自然语言处理模型。
[0093]
本公开的商业价值
[0094]
本公开实施例提高了支持多种语言的预训练语言模型的微调效率。该预训练语言模型微调成功后生成支持更多语言并且在特定下游任务上取得很好的自然语言处理效果的自然语言处理模型,提高了低资源语言场景下自然语言处理模型处理下游任务的性能和多语言场景下预训练语言模型所能适用的下游任务的种类范围,具体广阔的应用空间和市场价值。
[0095]
根据本公开实施例的预训练语言模型的训练装置
[0096]
根据本公开的一个实施例,还提供了一种预训练语言模型的训练装置。它可以是图1所示的模型微调装置112。如图3所示,该预训练语言模型的训练装置可以包括:
[0097]
训练数据组合获取单元310,用于获得使用不同语言表达相同语义的训练数据组合。
[0098]
损失值计算单元320,用于将所述训练数据组合输入具备不同语言理解能力的预训练语言模型,以使得所述预训练语言模型对所述训练数据组合进行预训练后得到所述训练数据组合对应的输出数据组合,并根据所述输出数据组合计算所述训练数据组合的损失值。
[0099]
模型参数更新单元330,用于利用所述损失值更新所述预训练语言模型的模型参数,以提高所述输出数据组合的相似度。
[0100]
由于上述预训练语言模型的训练装置的实现细节在上文的方法实施例的详细介绍中已经描述,为节约篇幅,故不赘述。
[0101]
根据本公开实施例的计算机设备
[0102]
根据本公开的一个实施例的预训练语言模型的训练方法可以由图5的计算机设备800实现。该计算机设备800可以是图1的模型微调装置112。图5显示的计算机设备800仅仅是一个示例,不应对本公开实施例的功能和使用范围带来任何限制。
[0103]
如图5所示,计算机设备800以通用计算设备的形式表现。计算机设备800的组件可以包括但不限于:上述至少一个处理单元810、上述至少一个存储单元820、连接不同系统组件(包括存储单元820和处理单元810)的总线830。
[0104]
其中,所述存储单元存储有程序代码,所述程序代码可以被所述处理单元810执行,使得所述处理单元810执行本说明书上述示例性方法的描述部分中描述的本公开各种
示例性实施方式的步骤。例如,所述处理单元810可以执行如图2中所示的各个步骤。
[0105]
存储单元820可以包括易失性存储单元形式的可读介质,例如随机存取存储单元(ram)8201和/或高速缓存存储单元8202,还可以进一步包括只读存储单元(rom)8203。
[0106]
存储单元820还可以包括具有一组(至少一个)程序模块8205的程序/实用工具8204,这样的程序模块8205包括但不限于:操作系统、一个或者多个应用程序、其它程序模块以及程序数据,这些示例中的每一个或某种组合中可能包括网络环境的实现。
[0107]
总线830可以为表示几类总线结构中的一种或多种,包括存储单元总线或者存储单元控制器、外围总线、图形加速端口、处理单元或者使用多种总线结构中的任意总线结构的局域总线。
[0108]
计算机设备800也可以与一个或多个外部设备700(例如键盘、指向设备、蓝牙设备等)通信,还可与一个或者多个使得用户能与该计算机设备800交互的设备通信,和/或与使得该计算机设备800能与一个或多个其它计算设备进行通信的任何设备(例如路由器、调制解调器等等)通信。这种通信可以通过输入/输出(i/o)接口850进行。并且,计算机设备800还可以通过网络适配器860与一个或者多个网络(例如局域网(lan),广域网(wan)和/或公共网络,例如因特网)通信。如图所示,网络适配器860通过总线830与计算机设备800的其它模块通信。应当明白,尽管图中未示出,可以结合计算机设备800使用其它硬件和/或软件模块,包括但不限于:微代码、设备驱动器、冗余处理单元、外部磁盘驱动阵列、raid系统、磁带驱动器以及数据备份存储系统等。
[0109]
需要领会,以上所述仅为本公开的优选实施例,并不用于限制本公开,对于本领域技术人员而言,本说明书的实施例存在许多变型。凡在本公开的精神和原理之内所作的任何修改、等同替换、改进等,均应包含在本公开的保护范围之内。
[0110]
应该理解,本说明书中的各个实施例均采用递进的方式描述,各个实施例之间相同或相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。
[0111]
应该理解,上述对本说明书特定实施例进行了描述。其它实施例在权利要求书的范围内。在一些情况下,在权利要求书中记载的动作或步骤可以按照不同于实施例中的顺序来执行并且仍然可以实现期望的结果。另外,在附图中描绘的过程不一定要求示出的特定顺序或者连续顺序才能实现期望的结果。在某些实施方式中,多任务处理和并行处理也是可以的或者可能是有利的。
[0112]
应该理解,本文用单数形式描述或者在附图中仅显示一个的元件并不代表将该元件的数量限于一个。此外,本文中被描述或示出为分开的模块或元件可被组合为单个模块或元件,且本文中被描述或示出为单个的模块或元件可被拆分为多个模块或元件。
[0113]
还应理解,本文采用的术语和表述方式只是用于描述,本说明书的一个或多个实施例并不应局限于这些术语和表述。使用这些术语和表述并不意味着排除任何示意和描述(或其中部分)的等效特征,应认识到可能存在的各种修改也应包含在权利要求范围内。其他修改、变化和替换也可能存在。相应的,权利要求应视为覆盖所有这些等效物。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1