基于CNN-BiLSTM的电机故障预测方法及系统
基于cnn-bi lstm的电机故障预测方法及系统
技术领域
1.本发明涉及一种电机故障预测方法,尤其涉及一种基于cnn-bi lstm的电机故障预测方法。
背景技术:
2.电机是人类社会的各种生产活动和生活中用量最大、覆盖面最广的工业设备;在工业领域中,工厂中的设备基本上都是电机驱动的,对于一个发达的工业化国家而言,整个国家的40%-60%的电能都是由电机消耗的。由此可见,电机在人类生产和生活中占据着举足轻重的地位。电机一旦发生故障,带来的经济财产损失巨大,严重影响人们的生产生活。为了避免电机失效造成的经济损失和生产事故,对电机进行故障预测具有重要的意义。
3.故障预测方法可分为基于模型的故障预测方法和基于数据驱动的故障预测方法这两类。
4.基于模型的故障预测方法中模型包括了数学模型和物理模型。该方法分析被测对象的运行条件、材料特点、机械构造和失效机制等信息,动态建模从而预测未来时间的工作状态,该方法的优点是故障预测的实时性强和预测精度高,缺点是建模需要建立在对被测对象深入了解的基础上,过程较为复杂和计算量较大。基于模型的故障预测主要方法有时间序列分析、灰色模型方法、隐马尔科夫模型、卡尔曼滤波、扩展卡尔曼滤波和粒子滤波方法。
5.基于数据驱动的故障预测方法是指直接于系统的输出端测量性能数据,对性能数据进行机器学习,建立故障预测模型进行预测的方法。基于数据驱动的故障预测方法并不需要对复杂电气与电子系统的运行条件、材料特点、机械构造和失效机制等深入了解,只需要先对测量数据进行信号分析,然后应用机器学习方法进行建模和预测,因此不需要建立大计算量的复杂物理或数学模型。
6.目前基于数据驱动的故障预测方法大多数采用基于深度学习的模型,如cnn神经网络、lstm网络来进行故障预测,但是,cnn神经网络主要用来提取空间特征,对于时序特征规律往往无法有效发掘,而时序数据的处理是lstm网络的长处,但是lstm网络只能单向发掘时序特征。而且电机特征数据的变化是多因素共同作用的结果,它们具有复杂的内在联系,单一模型往往很难有效的捕捉这种关系。在建立模型过程中,模型计算时间相对较长,需要进一步优化隐藏层数与神经元个数,使模型能够更快、更精确地预测出故障的发生,满足电机生产运行的需要。
技术实现要素:
7.发明目的:本发明旨在提供一种能够实现快速、高精度故障预测的基于cnn-bi lstm的电机故障预测方法及系统。
8.技术方案:本发明所述的基于cnn-bi lstm的电机故障预测方法,包括以下步骤:
9.(1)采集信号数据;
10.(2)对采集的信号数据进行预处理;
11.(3)利用预处理后的数据建立cnn-bi lstm电机故障预测模型并进行故障预测。
12.优选地,所述步骤(1)中采集的信号数据为电机无故障和多个故障工况下的电流信号和振动信号。
13.优选地,所述步骤(2)中数据预处理过程包括首先使用时频域分析方法,提取振动信号和电流信号的特征向量,然后对所得到的电流信号和振动信号进行数据融合处理分析,最后将所得到的特征数据集进行划分。
14.优选地,所述时频域分析方法包括对信号数据进行希尔伯特变换,得到原始的包络数据,然后对包络波形进行傅里叶变换得到包络频谱,从包络频谱中提取电机故障特征频率;对电机非稳态下的信号数据噪声过大的情况,利用频谱细化技术来进行故障特征提取,将信号通过小波变换后,通过选取一个阀值,保留大于阀值的小波系数,小于阀值的则置为零,最后在进行小波重构。
15.优选地,所述特征数据集进行划分包括将特征数据集按比例划分为训练集、验证集与测试集。
16.优选地,所述建立步骤(3)中的模型的步骤为:
17.(31)卷积神经网络进行故障特征提取;
18.(32)双向长短时记忆神经网络建立故障预测模型;
19.(33)全连接层完成对时序故障特征的整合,获得故障预测结果。
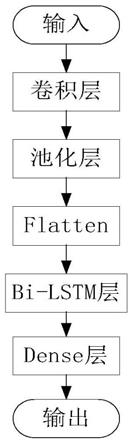
20.优选地,所述步骤(31)中故障特征提取包括首先通过卷积层对输入数据特征进行提取,然后通过池化层对提取到的特征进行提炼,最后经由flatten层压平后进行输出。
21.优选地,所述步骤(32)中建立故障预测模型包括以bi-lstm神经网络作为故障预测模型主体,从双向发掘时序特征,将故障特征转化为时序故障特征。
22.优选地,所述故障预测模型建好后,对于学习率的优化采用adam优化算法。
23.本发明所述的基于cnn-bi lstm的电机故障预测系统,包括:
24.数据采集模块,用于采集所需的信号数据;
25.数据预处理模块,用于对采集的信号数据采用时频域分析方法提取特征向量,然后进行数据融合处理分析,并进行数据集划分;
26.特征提取模块,用于通过卷积神经网络卷积层对输入数据特征进行提取,通过池化层对提取到的特征进行提炼,然后经由flatten层压平后进行输出;
27.故障预测模块,用于通过双向长短时记忆网络从双向发掘时序特征,将故障特征转化为时序故障特征,并对时序故障特征进行整合,获得故障预测结果。
28.有益效果:与现有技术相比,本发明具有如下显著优点:充分发挥两种模型在不同领域的作用,获得更多有用信息,进一步优化隐藏层数与神经元个数,更快、更精确地预测出故障的发生。
附图说明
29.图1为本发明中电机故障预测模型的流程图;
30.图2为本发明数据预处理过程示意图;
31.图3为本发明bi lstm网络结构图。
具体实施方式
32.下面结合附图对本发明的技术方案作进一步说明。
33.一种基于cnn-bi lstm的电机故障预测方法,该方法包括:
34.(1)采集信号数据;
35.(2)对采集的信号数据进行预处理;
36.(3)利用预处理后的数据建立cnn-bi lstm电机故障预测模型并进行故障预测。
37.采集电机无故障和多个故障工况下的电流信号和振动信号作为初始数据集,并对初始数据集进行预处理。如图2所示,对采集到的信号数据进行希尔伯特变换,得到原始的包络数据,然后对包络波形进行傅里叶变换得到包络频谱,从包络频谱中提取电机故障特征频率,对电机非稳态下的信号数据噪声过大的情况,利用频谱细化技术来进行故障特征提取,将信号通过小波变换后,选取阀值,保留大于阀值的小波系数,小于阀值的则置为零,最后进行小波重构。然后把分布在不同位置的多个同类或非同类的传感器的数据加以融合处理分析,获得对被测系统或设备一致性的状态信息,并消除传感器数据中存在的冗余和矛盾,从而更准确、更可靠的了解被测系统或设备。最后将预处理后的数据按3:1:1的比例划分为训练集、验证集与测试集三部分。
38.建立cnn-bi lstm故障预测模型的步骤为:
39.(31)卷积神经网络进行故障特征提取;
40.(32)双向长短时记忆神经网络建立故障预测模型;
41.(33)全连接层完成对时序故障特征的整合,获得故障预测结果。
42.首先通过卷积层对输入数据特征进行提取,通过池化层对提取到的特征进行提炼,经由flatten层压平后进行输出。然后以bi-lstm神经网络作为故障预测模型主体,从双向发掘时序特征,将故障特征转化为时序故障特征。最后由全连接层完成对时序故障特征的整合,获得故障预测结果。
43.确定卷积神经网络和双向长短记忆神经网络模型及相关参数的步骤包括:
44.(3.1)训练环境参数确定
45.在神经网络中完成一次从训练到测试的过程称为一个epoch。
46.(3.2)激活函数配置
47.在确定cnn-bi lstm模型参数时,需要对cnn网络与bi-lstm网络的激活函数进行设置,这两种网络常用的激活函数有sigmoid、tanh与relu。
48.cnn网络结构通常由卷积层,用来降采样的池化层以及全连接层组成。cnn网络首先通过卷积层对输入数据特征进行提取,然后通过池化层对提取到的特征进行提炼,最后经由添加全连接层拼接后进行输出。
49.假设全连接网络的参数矩阵大小k1,其计算公式:
50.k1=m
×n51.式中k1为全连接网络参数矩阵大小;m全连接网络参数矩阵行数;n全连接网络参数矩阵其列数。
52.卷积公式如下:
53.示上层中输出的特征图谱的个数,表示第q个特征图谱,表示第l层中第k个积核获得的特征图谱的偏置,表示第l层中第k个卷积核获得的特征图谱的权重,f(x)表示relu激活函数。
54.对卷积结果使用激活函数,得到激活结果,为使得误差值有明显下降本文将选用relu激活函数。
55.relu公式如下:
56.relu(x)=max(0,x)
57.bi lstm网络结构,从结构上讲,相较于单向的lstm网络,bi lstm网络是正向和反向传播的双向循环结构,从时间流向来看,bi lstm在lstm数据从过去到未来单向流动的基础上增加了从未来到过去的数据流向,且用于过去的隐藏层和用于未来的隐藏层之间相互独立,所以bi lstm可以更好的发掘数据的时序特征。图3为bi-lstm网络在t-1、t、t+1时刻,模型沿时间轴展开的结果,其中x为模型输入,h为隐藏层状态,y为输出。bi-lstm可以同时处理正反两个时间流向的模型,因此其具有两个方向的隐藏层。如图中所示正向传播的隐藏层与反向传播的隐藏层之间并没有发生交互,可以拆分开,当成两个独立且数据流向相反的网络。
58.假设为t时刻正向lstm网络的隐藏层状态,其计算公式如下式所示。可以看作是单层的lstm网络,由t-1时刻状态计算t时刻状态的过程,x
t
为t时刻的输入。
[0059][0060]
式中为t时刻正向lstm网络的隐藏层状态;lstm为lstm单元;x
t
为t时刻的输入;为t-1时刻状态正向lstm网络的隐藏层状态。
[0061]
类似的为t时刻反向lstm网络的隐藏层状态,其计算公式如下式所示。
[0062][0063]
式中:为t时刻正向lstm网络的隐藏层状态;lstm为lstm单元;x
t
为t时刻的输入;为t时刻状态正向lstm网络的隐藏层状态。
[0064]
bi-lstm网络输出就是两部分隐藏层状态与组合在一起,从而构成网络整体隐藏状态h
t
。
[0065]
(3.3)优化器的选择
[0066]
深度学习网络训练的目的,就是通过不断的优化参数值,使训练误差尽可能的减小,这一过程称为模型优化。所使用的算法就是各种优化器,常用的优化器有sgd、rmsprop与adam等。其中,adam算法是一种可以用于更新网络权重的一种优化算法,它能基于训练数据对神经网络的学习率进行优化,进而对网络权重进行更新。adam算法具有多种优化算法的优点,既可以基于一阶矩均值计算适合于各个参数的学习率,还可以充分的利用梯度的二阶矩均值来更新学习率。因此,建立cnn-bi lstm故障预测模型后,对于学习率的优化采用了adam优化算法。
[0067]
(3.4)损失函数的选择
[0068]
计算故障预测模型损失,选择均方根误差作为损失函数,配合adam优化器来调节模型参数。定义真实值y与模型的预测值y
p
的均方差为损失函数,公式如下。
[0069][0070]
其中y
ip
为预测值,yi为实际值,n为训练或验证样本数量。
[0071]
在训练模型时,根据损失函数是否随着训练次数的增加而减小来判断损失函数的收敛性。若其不收敛,则需重新调整模型参数,继续训练,直至收敛。模型训练过程中通过比较验证数据预测值和真实值之间的均方根误差判断模型的实际效果。
[0072]
若rmse值较大,则模型可能存在过拟合等情况,模型需要进行重新训练;若rmse值较小,则模型精度较高,并且值越小,模型精度越高。
[0073]
(3.5)网络超参数调优
[0074]
使用训练集对模型进行训练,验证集用来评估训练效果,根据评估的结果调整模型参数,重复这个流程,直到误差连续多次迭代不再减少,触发earlystopping早停机制或者达到设定的最大训练次数,选择效果最好的模型参数。经过训练和验证,所确定的cnn-bi lstm故障预测模型参数为cnn网络层数为2,卷积核尺寸为2,卷滤波器大小分别为32、64,bi-lstm层数为1,bi-lstm神经元数为20。
[0075]
当测试集数据输入cnn-bi lstm故障预测模型后,首先由两层不断加深的一维卷积层进行特征提取,池化层进行过滤,flatten层进行扁平,然后cnn神经网络提取出的特征数据输入神经元数量为20的单层bi lstm网络中,挖掘数据中的时序关系,最后经由dense层对数据特征进行增强后,输出预测结果。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1