基于大数据分析的窃电嫌疑用户筛选方法与流程
1.本发明涉及电力资源管理技术领域,尤其涉及一种基于大数据分析的窃电嫌疑用户筛选方法。
背景技术:
2.目前筛选窃电嫌疑用户的方法主要是将采集到的数据按单相用户是否欠压(阀值一般取20%),三相用户是否欠压、电压逆相序、电流反向、开盖告警等信息来判断的。但这种方法筛查出来的窃电用户数量非常少,并且该方法的筛查结果中遗漏了通过欠流法窃电的窃电用户;此外,由于各种干扰,筛查结果中可能还包括有误筛查结果,如此筛查出来的真实窃电用户的数量更少。同时,确定的窃电用户信息未能有效反馈,基于这种规则的筛选方法本身不能自动提高筛选精准度。
技术实现要素:
3.针对传统窃电用户筛查方法会造成欠流法窃电用户的遗漏或者无法及时反馈窃电用户信息以便自动提高筛选精准度的问题,本发明提供一种基于大数据分析的窃电嫌疑用户筛选方法,能够筛选出欠流法窃电嫌疑用户,能够根据窃电嫌疑程度对嫌疑用户精准排序,并且窃电规则能够根据现场窃电检查结果对初始的窃电嫌疑用户进行重新核实和排序,实现了窃电用户信息的及时有效反馈,能够自动不断提高筛选精准度。
4.本发明提供的基于大数据分析的窃电嫌疑用户筛选方法,包括:
5.步骤1:通过spark streaming从综合能源数据平台上获取正常用户在相同历史时间段内的关联表数据,所述关联表数据包括:水表数据、气表数据、热表数据和电表数据;
6.步骤2:对在相同历史时间段内的所述关联表数据进行数据预处理,所述数据预处理包括数据清洗和缺失值填充;
7.步骤3:采用dbscan聚类方法按照数量值分别对预处理后的所述水表数据、所述气表数据和所述热表数据进行聚类,得到所述水表数据、所述气表数据和所述热表数据分别与所述电表数据之间的相关系数;
8.步骤4:通过spark streaming从综合能源数据平台上获取待筛查用户当前月的真实关联表数据;
9.步骤5:根据所述水表数据、所述气表数据和所述热表数据分别与所述电表数据之间的相关系数,以及当前月的真实水表数据、真实气表数据和真实热表数据作为输入,采用预先训练好的lstm用电预测模型确定用户当前月的预测电表数据;
10.步骤6:比较用户当前月的真实电表数据和预测电表数据,确定窃电嫌疑用户。
11.进一步地,步骤6具体包括:若待筛查用户的真实电表数据低于预测电表数据的80%,则将该待筛查用户标定为窃电嫌疑用户。
12.进一步地,所述方法还包括:根据电表出现欠压、逆相序、反向或开盖告警的信号的次数,对窃电嫌疑用户进行排序。
13.进一步地,所述方法还包括:根据用户当前月的预测电表数据和真实电表数据的比值大小,对窃电嫌疑用户进行排序。
14.进一步地,所述方法还包括:按照窃电嫌疑用户排序结果,依次对窃电嫌疑用户进行现场排查,若标定的窃电嫌疑用户为真实窃电用户,则按照窃电比例将该真实窃电用户的电表数据还原成实际电表数据,并重新对未排查的窃电嫌疑用户进行排序。
15.进一步地,所述方法还包括:将已经查获的真实窃电用户的关联表数据和用户信息增加至案例库中进行存储。
16.本发明的有益效果:
17.(1)由于水、气、热用量通常与用电量具有相关性,本发明增加了水表数据、气表数据、热表数据作为窃电嫌疑用户筛选的依据,从而避免在筛选过程中遗漏欠流法窃电用户,使得具备四表合一的用户中的大多数窃电用户都能被发现,使得窃电嫌疑用户的筛选更加全面和精准;
18.(2)本发明根据嫌疑程度的排序使现场窃电排查更有针对性,而参数修正过程(即将真实窃电用户的电表数据按窃电比例还原成实际用电数据)则使得窃电嫌疑用户筛选过程形成一个闭环,从而可以不断提高筛选精准度。
附图说明
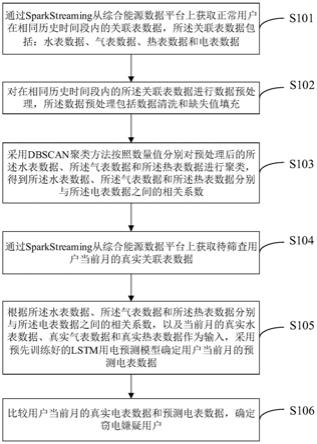
19.图1为本发明实施例提供的基于大数据分析的窃电嫌疑用户筛选方法的流程示意图之一;
20.图2为本发明实施例提供的基于大数据分析的窃电嫌疑用户筛选方法的流程示意图之二。
具体实施方式
21.为使本发明的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
22.实施例1
23.如图1所示,本发明实施例提供的基于大数据分析的窃电嫌疑用户筛选方法,包括以下步骤:
24.s101:通过spark streaming从综合能源数据平台上获取正常用户在相同历史时间段内的关联表数据,所述关联表数据包括:水表数据、气表数据、热表数据和电表数据;
25.s102:对在相同历史时间段内的所述关联表数据进行数据预处理,所述数据预处理包括数据清洗和缺失值填充;
26.s103:采用dbscan聚类方法按照数量值分别对预处理后的所述水表数据、所述气表数据和所述热表数据进行聚类,得到所述水表数据、所述气表数据和所述热表数据分别与所述电表数据之间的相关系数;
27.s104:通过spark streaming从综合能源数据平台上获取待筛查用户当前月的真实关联表数据;
28.s105:根据所述水表数据、所述气表数据和所述热表数据分别与所述电表数据之间的相关系数,以及当前月的真实水表数据、真实气表数据和真实热表数据作为输入,采用预先训练好的lstm用电预测模型确定用户当前月的预测电表数据;
29.s106:比较用户当前月的真实电表数据和预测电表数据,确定窃电嫌疑用户。
30.具体地,若待筛查用户的真实电表数据低于预测电表数据的80%,则将该待筛查用户标定为窃电嫌疑用户。
31.由于水、气、热用量通常与用电量具有相关性,本发明实施例中,增加了水表数据、气表数据、热表数据作为窃电嫌疑用户筛选的依据,从而避免在筛选过程中遗漏欠流法窃电用户(例如,某欠流法窃电用户,按通过判断是否欠压、逆相序、反向、开盖告警这些传统手段不能发现窃电,但通过该用户的电量数据与水、气、热表数据进行比对,如果按历史数据月度水、气、热表数据正常,而电表月度数据异常减少,如果少于某一阈值(例如20%),即可判断为窃电嫌疑用户),使得具备四表合一的用户中的大多数窃电用户都能被发现,使得窃电嫌疑用户的筛选更加全面和精准。
32.实施例2
33.由于水、气、热三表的数据与用电量往往存在关联,基于历史数据和实际结果,精细化模型,探究多源数据与用电异常的耦合关系,对用电异常进行量化分析,完成窃电嫌疑排序。
34.如图2所示,在上述实施例的基础上,本发明实施例与上述实施例的不同之处在于本发明实施例还包括以下步骤:
35.s107:根据电表出现欠压、逆相序、反向或开盖告警的信号的次数,对窃电嫌疑用户进行排序;或者,根据用户当前月的预测电表数据和真实电表数据的比值大小,对窃电嫌疑用户进行排序;
36.具体地,电表出现欠压、逆相序、反向或开盖告警的信号的次数越多,表明该窃电嫌疑用户为真实窃电用户的可能性越大,则该窃电嫌疑用户排序越靠前。
37.预测电表数据与真实电表数据的比值越大,表明该窃电嫌疑用户为真实窃电用户的可能性越大,则该窃电嫌疑用户排序越靠前。
38.s108:按照窃电嫌疑用户排序结果,依次对窃电嫌疑用户进行现场排查,若标定的窃电嫌疑用户为真实窃电用户,则按照窃电比例将该真实窃电用户的电表数据还原成实际电表数据,并重新对未排查的窃电嫌疑用户进行筛查和排序;迭代执行本步骤,直至排查完所有的窃电嫌疑用户;
39.具体地,将真实窃电用户的电表数据按窃电比例还原成实际用电数据之后,可以恢复正常的电量与水、气、热量的相关性,从而基于正常的相关性重新对未排查的窃电嫌疑用户进行筛查和排序,可以使判断结果更加精准。
40.s109:将已经查获的真实窃电用户的关联表数据和用户信息增加至案例库中进行存储。
41.具体地,对已查获的真实窃电用户,通过将其信息和关联数据加入中,可以方便以后作为特征对比分析。例如,从该案例库中输出实际窃电的数据,作为训练数据,不断优化窃电识别的学习模型,可以提高其窃电检查准确率。
42.本发明实施例中,增加了水、气、热表数据作为窃电嫌疑用户筛选的依据后,使得
窃电嫌疑用户筛选更加全面和精准;并且根据嫌疑程度的排序使现场窃电排查更有针对性,而参数修正过程(即将真实窃电用户的电表数据按窃电比例还原成实际用电数据)则使得窃电嫌疑用户筛选过程形成一个闭环,从而可以不断提高筛选精准度。
43.最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1