一种基于ARIMA-HRNN的多维实时洪水预报方法与流程
一种基于arima-hrnn的多维实时洪水预报方法
技术领域
1.本发明涉及洪水预报技术领域(ipc分类号:g06q10/04),尤其涉及一种基于arima-hrnn的多维实时洪水预报方法。
背景技术:
2.可靠的洪水预报是做好水库防洪发电调度的前提,因此水库洪水预报是整个防洪和发电调度决策的核心组成部分。传统上基于水文模型来进行洪水预报,由于传统水文模型(例如新安江模型)结构及参数所限,难以完全反映水文规律,故预报精度往往不够理想。
3.本发明提供的一种基于arima-hrnn的实时洪水预报方法,可以用来可靠地预测给定地点的洪水趋势和洪峰时间。本发明将动态回归模块和深度学习模块的输出结合起来进行融合,并在预测结果中加入线性成分,使预测结果能够适应由于尺度转换而导致的输入期尺度的变化。基于用户自动导入的数据或从气象部门自动导入的信息进行水库长期径流预报和短期洪水径流预报。本方法基于网络的图形用户界面应用以时间序列图、表格、gis图、过程动画显示和自动生成的预测报告等格式向用户提供所生成的数据。与其他方法相比,本发明在预测流量准确性、峰值与峰现时间差值具有更好的表现。
技术实现要素:
4.本发明公开了一种基于arima-hrnn的多维实时洪水预报方法,该方法通过优化网络结构及其权重系数,使复杂的水文规律蕴含在模型中,解决了传统水文模型的缺陷,从而达到提高预报精度的目的。
5.为了解决上述问题,本发明的提供了一种基于arima-hrnn的多维实时洪水预报方法,包括以下步骤:
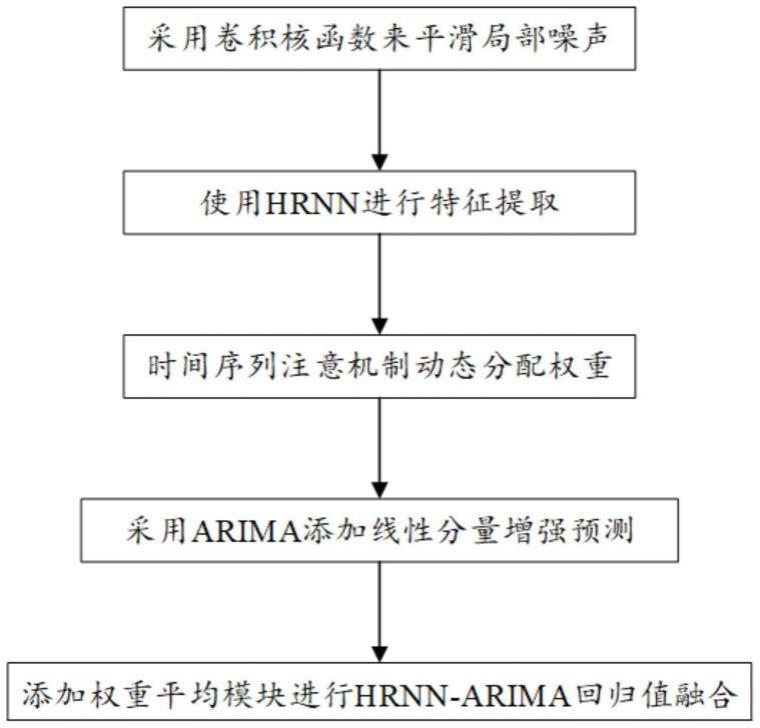
6.s1.采用卷积核函数来平滑局部噪声;
7.s2.使用混合循环神经网络(hrnn)模型进行特征提取;
8.s3.采用了时间序列注意力机制,对上游水库的流出流量、降雨等输入向量分配各种注意力权重;
9.s4.采用差分整合移动平均自回归模型(arima)添加线性分量增强预测;
10.s5.添加权重平均模块将hrnn输出结果与自回归融合滑动平均模块arima回归值加权平均融合。
11.优选的,所述s2步骤中的特征提取为提取洪水的峰值特征,在洪水过程中会有多峰过程和单峰过程的情况,对于任一洪水中入库流量对应的时间系列q={q0,q1…
,q
t
},q为洪水入库对应时间序列。不同的时间分别记为q0,q1……qt
。本发明首先提取了总数据样本的20%的样本数据即并按时间依次对洪水的入库流量顺序进行排序,查找一组洪峰位置q
peak
={qi∣0《i《t},(i代表洪水入库的某一时间序列)确定编号n,并保留洪水qi中数据样本(5/n)%的数据不会平滑,以确保洪水的形状。
12.优选的,所述s2步骤中的hrnn模型中引入了卷积神经网络(cnn),主要用于提取不
同变量之间的非线性依赖关系。与图像对应的庞大规模的维度不同,时间序列所提取的特征维度较少,因此在进行卷积后不需要进行池化层处理,对于选用的激活函数,本发明使用了relu激活函数。
13.hk=relu(wk*x+bk)
14.式中,hk为cnn输出矩阵;wk为权重参数矩阵;x为输入特征矩阵;bk为偏置。
15.优选的,所述s2步骤中的hrnn模型中引入了长短时记忆模型(lstm)和双向长短时记忆(bi-lstm),其目的是为了获得时间序列中不同时段的变量对输出的影响。
16.优选的,所述bi-lstm模型添加了注意层,以增强临界矩特征对流量预测的贡献,可以用于洪水流量预测中。
17.优选的,所述s2包括以下子步骤:
18.s21.将cnn提取的特征矩阵作为输入;
19.s22.使用bi-lstm作为循环单元,信息进入lstm;
20.s23.通过遗忘门从主信息流中丢弃一些无用的信息,按下式进行处理。
21.f
t
=σ(wf·
[h
t-1
,x
t
]+bf)
[0022]
式中,f
t
为遗忘门输出;wf为遗忘权重矩阵;h
t-1
为上一时刻网络状态;x
t
为当前输入;bf为遗忘门偏置;
[0023]
在本发明中,所述遗忘门会读取当前输入x
t
和上一时刻网络状态h
t-1
,经过sigmoid函数得到一个值为0~1之间的激活向量,传递给t-1时刻的lstm单元状态c
t-1
,来决定丢弃的信息,0代表全都丢弃,1代表全都保留。
[0024]
s24.确定信息的更新情况。
[0025]
s25.通过输出门确定输出的信息。
[0026]
优选的,所述s24包括以下子步骤:
[0027]
s241.输入门sigmoid决定哪些信息被更新;
[0028]
s242.学习到的tanh神经网络层生成一个新的信息向量作为更新后的新值。
[0029]
s243.lstm单元状态更新;
[0030]
优选的,所述lstm单元状态更新为c
t
。所述c
t
的按下式进行获取:
[0031][0032]
式中:f
t
为输入门产生的激活向量;c
t-1
为上一时刻的状态;i
t
为##;为新的信息向量。
[0033]
在本发明中,上一时刻的状态c
t-1
与输入门产生的激活向量f
t
通过矢量逐元素乘法运算(*)相乘,将无用信息遗忘,然后与相加,将新的信息更新到当前信息中,此时lstm单元状态更新为c
t
。
[0034]
进一步优选的,所述i
t
按下式进行获取:
[0035]it
=σ(wi·
[h
t-1
,x
t
]+bi)
[0036]
式中:wi为不共享参数的权重矩阵;h
t-1
为上一时刻网络状态;x
t
为当前输入信息;bi为偏置。
[0037]
进一步优选的,所述按下式进行获取:
[0038][0039]
式中,wc为不共享参数的权重矩阵;h
t-1
为上一时刻网络状态;x
t
为当前输入信息;bc为偏置。
[0040]
优选的,所述s25包括以下子步骤:
[0041]
s251.输出门会读取当前输入x
t
和上一时刻网络状态h
t-1
,经过sigmoid函数得到一个值为0~1之间的激活向量来确定单元状态哪些部分可以输出;
[0042]
s252.利用tanh函数层得到-1~1范围之间的激活向量来处理lstm单元当前的状态c
t
,并与第一步的结果进行矢量逐元素相乘,得到输出h
t
。
[0043]
优选的,所述h
t
按下式进行获取:
[0044][0045]
式中:为前向lstm的隐藏状态输出;为反向lstm的隐藏状态输出。
[0046]
优选的,所述步骤s3中的时间序列注意力机制,用于学习输入矩阵每个窗口位置的隐藏表示的加权组合,并在不同时间为变量分配最佳权重,解决了在单次洪水预报中非季节性时间序列预报的问题。
[0047]
优选的,所述s3中的注意力权重按下式进行获取:
[0048]
aw
t
=tanh(h
t
)
[0049]
式中,tanh为激活函数,aw
t
为注意力权重。
[0050]
优选的,所述注意力概率向量p
t
是利用softmax函数概率计算注意力权重aw
t
,按下式进行获取:
[0051][0052]
优选的,所述s3包括以下子步骤:
[0053]
s31.通过点积形式来计算注意力权重aw
t
。
[0054]
s32.通过softmax函数概率计算注意力权重aw
t
,得到概率向量p
t
。
[0055]
s33.将bi-lstm生成的隐藏状态h与相应的注意力概率向量相乘,得到其加权值。
[0056]
优选的,所述aw
t
按下式进行获取:
[0057]
aw
t
=tanh(h
t
)
[0058]
式中,aw
t
为注意力权重;h
t
为隐藏状态矩阵;
[0059]
优选的,所述p
t
按下式进行获取:
[0060][0061]
式中,awt为注意力权重;
[0062]
优选的,所述加权值按下式进行获取:
[0063]
[0064]
式中,α
t
为注意力分配系数;pi为概率向量;h
t
为上一网络层的输出向量。
[0065]
s34.通过注意力层的输出和lstm的输出之后,模型将两个模块的输出结果相加。
[0066]
在本发明中,对于bi-lstm和注意力非线性模型,是为了获得时间序列的残差预测值,而lstm模块是为了生成一个平稳的预测序列,因此加入后,可以得到带残差和趋势的预测值。
[0067]
优选的,所述步骤s4中arima模型由自回归模型、运动平均模型和平滑处理模块组成。
[0068]
优选的,所述arima模型按下式进行获取:
[0069]yt
=φ0+φy
t-1
+φ2y
t-2
+...+φ
pyt-p
+ε
t-θε
t-1-θ2ε
t-2-...-θqε
i-q
[0070]
式中,所述y
t
为实际值,ε
t
为随机误差,φ
p
和θq为系数,p是自回归滞后数,q是移动平均滞后数,p和q为整数,通常分别称为自回归和移动平均,d为差分阶数,本发明中该值为1。
[0071]
在本发明中,当数据成为平稳序列后,利用给定的函数,定义参数p,q的范围,其中p是自回归滞后数,q是移动平均滞后数,从而识别出标准值最小的akaike信息准则(aic)。在建立arima模型后,根据确定的参数p,q对arima的线性分量进行建模,在t时刻以计算结果作为期望值。
[0072]
优选的,所述s5步骤中加权平均的方式为将hrnn与arima模型的输出进行融合,从而进一步减少预测值与真实值之间的误差。
[0073]
优选的,所述s5步骤中加权平均的方式为使用动态调整加权因子的算法来对arima-hrnn模型的输出进行加权平均。
[0074]
优选的,所述arima-hrnn模型的加权平均确定方法按以下方式实现:设定w
hrnn
与w
arima
表示模型hrnn以及arima的权重,用h
1,t
={h
1,1
,h
1,2
,
…
,h
1,t
},h
2,t
={h
2,1
,h
2,2
,
…
,h
2,t
}表示模型hrnn与arima在未来t个时段的预测值,用r表示测试集中未来t个时段的真实值,定义的损失函数l(wk):当权重向量为wk时,求预测的t个时段的组合模型的预测结果w1·
hrnn+w2·
arima和真实值之间的均方根误差,l(wk)值越小,代表组合模型预测结果越接近真实值,模型准确度越高。每次进行预测,都从中挑选出l(wk)值最小的权重向量wk进行对模型集成,可以得到均方根误差最小的组合模型.为了挑选出最合适的wk。
[0075]
公式如下:
[0076][0077]
式中:l(wk)为损失函数;wk为权重向量;h
k,j
为某个时段的预测值。
[0078]
本发明提供的一种基于arima-hrnn的实时洪水预报方法,可以用来可靠地预测给定地点的洪水趋势和洪峰时间。本发明将动态回归模块和深度学习模块的输出结合起来进行融合,并在预测结果中加入线性成分,使预测结果能够适应由于尺度转换而导致的输入期尺度的变化。基于用户自动导入的数据或从气象部门自动导入的信息进行水库长期径流预报和短期洪水径流预报。本方法基于网络的图形用户界面应用以时间序列图、表格、gis图、过程动画显示和自动生成的预测报告等格式向用户提供所生成的数据。与其他方法相比,本发明在预测流量准确性、峰值与峰现时间差值具有更好的表现。
[0079]
有益效果:
[0080]
(1)hrnn模型具有较强的记忆能力,可以更精确地复现洪水变化过程的总体趋势,其预测的流量和观测到的流量具有合理的可比性变化趋势.
[0081]
(2)cnn具有较好的处理洪峰问题的能力,即它可以处理洪水过程中流量的快速波动,对局部洪峰的发展更加敏感;
[0082]
(3)注入注意力机制后,提高了洪水过程预测总体趋势和预测洪峰流量的能力;
[0083]
(4)加入arima模型后,进一步减少了不同模型结合非线性和线性模型无法学习的物理机制,缩小了结果与实际值之间的差距。
附图说明
[0084]
图1为本技术文件的一种基于arima-hrnn的多维实时洪水预报方法流程图。
[0085]
图2为bi-lstm模型,新安江模型和arima-hrnn模型中的洪水预测确定性系数(dc)评估指标。
[0086]
图中,(a)bi-lstm模型;(b)新安江模型;(c)arima-hrnn模型。
具体实施方式
[0087]
实施例1
[0088]
一种基于arima-hrnn的实时洪水预报方法,包括以下步骤:
[0089]
s1、采用卷积核函数来平滑局部噪声;
[0090]
s2、使用hrnn进行特征提取;
[0091]
对于目标水库,提取洪水的峰值特征,对于任一洪水中入库流量对应的时间系列q={q0,q1…
,q
t
},本发明首先提取了总数据样本的20%的样本数据即并按时间依次对洪水的入库流量顺序进行排序,查找一组洪峰位置q
peak
={qi∣0《i《t},确定编号n,并保留洪水qi中数据样本(5/n)%的数据不会平滑,以确保洪水的形状。本实施例中,所述hrnn模型中包括cnn。所述cnn的激活函数为relu激活函数,所述relu激活函数为hk=relu(wk*x+bk)。
[0092]
式中,hk为输出矩阵;wk为权重参数矩阵;x为输入矩阵;bk为偏置。
[0093]
本实施例中,所述hrnn模型中包括lstm和bi-lstm。
[0094]
在本实施例中,所述bi-lstm添加了注意层。
[0095]
s21将cnn提取的洪水的峰值特征矩阵作为输入;
[0096]
s22.使用bi-lstm作为循环单元,信息进入lstm;
[0097]
s23.通过遗忘门从主信息流中丢弃一些无用的信息,按下式进行处理。
[0098]ft
=σ(wf·
[h
t-1
,x
t
]+bf)
[0099]
式中,f
t
为遗忘门输出;wf为遗忘权重矩阵;h
t-1
为上一时刻网络状态;x
t
为当前输入;bf为遗忘门偏置;
[0100]
在本实施例中,所述遗忘门会读取当前输入x
t
和上一时刻网络状态h
t-1
,经过sigmoid函数得到一个值为0~1之间的激活向量,传递给t-1时刻的lstm单元状态c
t-1
,来决定丢弃的信息,0代表全都丢弃,1代表全都保留。
[0101]
s24.确定信息的更新情况。
[0102]
s241.输入门sigmoid决定哪些信息被更新;
[0103]
s242.学习到的tanh神经网络层生成一个新的信息向量作为更新后的新值。
[0104]
s243.lstm单元状态更新;
[0105]
在本实施例中,所述lstm单元状态更新为c
t
。所述c
t
的按下式进行获取:
[0106][0107]
式中:f
t
为输入门产生的激活向量;c
t-1
为上一时刻的状态;i
t
为##;为新的信息向量。
[0108]
在本实施中,上一时刻的状态c
t-1
与输入门产生的激活向量f
t
通过矢量逐元素乘法运算(*)相乘,将无用信息遗忘,然后与相加,将新的信息更新到当前信息中,此时lstm单元状态更新为c
t
。
[0109]
在本实施例中,所述i
t
按下式进行获取:
[0110]it
=σ(wi·
[h
t-1
,x
t
]+bi)
[0111]
式中:wi为不共享参数的权重矩阵;h
t-1
为上一时刻网络状态;x
t
为当前输入信息;bi为偏置。
[0112]
在本实施例中,所述按下式进行获取:
[0113][0114]
式中,wc为不共享参数的权重矩阵;h
t-1
为上一时刻网络状态;x
t
为当前输入信息;bc为权重偏置。
[0115]
s25.通过输出门确定输出的信息。
[0116]
s251.输出门会读取当前输入x
t
和上一时刻网络状态h
t-1
,经过sigmoid函数得到一个值为0~1之间的激活向量来确定单元状态哪些部分可以输出;
[0117]
s252.利用tanh函数层得到-1~1范围之间的激活向量来处理lstm单元当前的状态c
t
,并与第一步的结果进行矢量逐元素相乘,得到输出h
t
。
[0118]
在本实施例中,所述h
t
按下式进行获取:
[0119][0120]
式中:为前向lstm的隐藏状态输出;为反向lstm的隐藏状态输出。
[0121]
s3、时间序列注意机制动态分配权重;
[0122]
s31.通过点积形式来计算注意力权重aw
t
。
[0123]
s32.通过softmax函数概率计算注意力权重aw
t
,得到概率向量p
t
。
[0124]
s33.将bi-lstm生成的隐藏状态h与相应的注意力概率向量相乘,得到其加权值。
[0125]
在本实施例中,所述aw
t
按下式进行获取:
[0126]
aw
t
=tanh(h
t
)
[0127]
式中,aw
t
为注意力权重;h
t
为上一层输出向量;
[0128]
在本实施例中,所述p
t
按下式进行获取:
[0129][0130]
式中,awt为注意力权重;
[0131]
在本实施例中,所述加权值按下式进行获取:
[0132][0133]
式中,α
t
为注意力分配系数;pi为概率向量,h
t
为上一层输出向量。
[0134]
s34.通过注意力层的输出和lstm的输出之后,模型将两个模块的输出结果相加。
[0135]
4、采用arima添加线性分量增强预测;
[0136]
在本实施例中,所述arima由自回归模型、运动平均模型和平滑处理模块组成。
[0137]
在本实施例中,所述arima模型按下式进行获取:
[0138]yt
=φ0+φy
t-1
+φ2y
t-2
+...+φ
pyt-p
+ε
t-θε
t-1-θ2ε
t-2-...-θqε
i-q
[0139]
式中,所述y
t
为实际值,ε
t
为随机误差,φ
p
和θq为系数,p是自回归滞后数,q是移动平均滞后数,p和q为整数,通常分别称为自回归和移动平均,d为差分阶数,本发明中该值为1。
[0140]
在本实施中,当数据成为平稳序列后,利用给定的函数,定义参数p,q的范围,其中p是自回归滞后数,q是移动平均滞后数,从而识别出标准值最小的akaike信息准则(aic)。在建立arima模型后,根据确定的参数p,q对arima的线性分量进行建模,在t时刻以计算结果作为期望值。
[0141]
5、添加权重平均模块将hrnn输出结果与arima回归值加权融合;
[0142]
在本实例中,所述s5步骤中加权平均的方式为使用动态调整加权因子的算法来对arima-hrnn模型的输出进行加权平均。
[0143]
在本实例中,所述hrnn输出结果与arima回归值加权融合按以下方式实现:设定w
hrnn
与w
arima
表示模型hrnn以及arima的权重,用h
1,t
={h
1,1
,h
1,2
,
…
,h
1,t
},h
2,t
={h
2,1
,h
2,2
,
…
,h
2,t
}表示模型hrnn与arima在未来t个时段的预测值,用r表示测试集中未来t个时段的真实值,定义的损失函数l(wk):当权重向量为wk时,求预测的t个时段的组合模型的预测结果w1·
hrnn+w2·
arima和真实值之间的均方根误差,l(wk)值越小,代表组合模型预测结果越接近真实值,模型准确度越高。每次进行预测,都从中挑选出l(wk)值最小的权重向量wk进行对模型集成,可以得到均方根误差最小的组合模型.为了挑选出最合适的wk。公式如下:
[0144][0145]
式中:l(wk)为损失函数;wk为权重向量;h
k,j
为某个时段的预测值。
[0146]
本实例利用交叉验证来估计25场洪水过程预测的结果如图2。
[0147]
由图2可知,arima-hrnn模型相比于bi-lstm模型,新安江模型,可以有效地描述水库洪水预报过程中的完整洪水过程。arima-hrnn模型除个别峰值的预报效果较差外,其预测值和观测值的趋势较为一致。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1