一种工单投诉风险预控方法与流程
1.本发明涉及风险控制,具体涉及一种工单投诉风险预控方法。
背景技术:
2.电网用于向用户供电,其承担着向用户进行安全可靠供电的重要任务。因此,及时派发电网检修工单并及时有效地进行处理,成为提高配电网检修效率及供电可靠性的重要因素。其中,电网检修工单是指电网发生故障后,国家电网客服系统根据用户所提供故障信息生成的,最终被派发至各地区相应驻点的运维人员手中,用于指导和记录故障处理的单据。
3.随着国家电网客服业务的不断发展,以及逐渐提升的人工话务强度,为了进一步加强对用户隐性特征及诉求的理解与分析,提升国家电网客服系统的服务水平,需要对客户需求及典型场景下的需求进行有效分析,从而实现对敏感用户的需求进行预测并提供更加贴心服务的目的。
技术实现要素:
4.(一)解决的技术问题
5.针对现有技术所存在的上述缺点,本发明提供了一种工单投诉风险预控方法,能够有效克服现有技术所存在的根据工单内容不能区别客户的敏感性,导致不能向客户提供具有针对性差异化服务的缺陷。
6.(二)技术方案
7.为实现以上目的,本发明通过以下技术方案予以实现:
8.一种工单投诉风险预控方法,包括以下步骤:
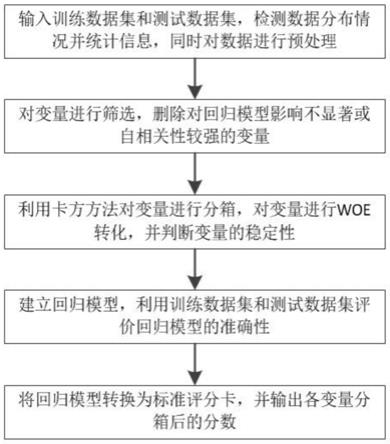
9.s1、输入训练数据集和测试数据集,检测数据分布情况并统计信息,同时对数据进行预处理;
10.s2、对变量进行筛选,删除对回归模型影响不显著或自相关性较强的变量;
11.s3、利用卡方方法对变量进行分箱,对变量进行woe转化,并判断变量的稳定性;
12.s4、建立回归模型,利用训练数据集和测试数据集评价回归模型的准确性;
13.s5、将回归模型转换为标准评分卡,并输出各变量分箱后的分数。
14.优选地,s1中检测数据分布情况并统计信息,同时对数据进行预处理,包括:
15.统计数据的缺失比例、最大值、最小值相关信息,确定各字段的长度、类型,将存在异常数据的字段处理为正常数据。
16.优选地,s2中对变量进行筛选,删除对回归模型影响不显著或自相关性较强的变量,包括:
17.计算每个变量的信息价值,根据信息价值和变量间自相关性对变量进行筛选,并结合逐步回归删除对回归模型影响不显著或自相关性较强的变量。
18.优选地,所述根据信息价值和变量间自相关性对变量进行筛选,包括:
19.保留信息价值大于0.01且变量间自相关性系数大于0.7的变量。
20.优选地,s3中利用卡方方法对变量进行分箱,包括:
21.分箱后观察分箱结果,当分箱结果不理想时进行手动调整分箱。
22.优选地,s3中对变量进行woe转化,包括:
23.采用下式对变量进行woe转化:
[0024][0025]
其中,i为某个特征的第i个分箱,badi为在第i个分箱中坏标签的数量,bad
t
为坏标签的总数,goodi为在第i个分箱中好标签的数量,good
t
为好标签的总数。
[0026]
优选地,s3中判断变量的稳定性,包括:
[0027]
计算每列特征的psi值,并基于psi值判断变量的稳定性。
[0028]
优选地,s4中建立回归模型,利用训练数据集和测试数据集评价回归模型的准确性,包括:
[0029]
利用logistic回归建立回归模型,并对训练数据集和测试数据集进行预测,分别计算两个数据集的ks值和auc值,评价回归模型的准确性。
[0030]
(三)有益效果
[0031]
与现有技术相比,本发明所提供的一种工单投诉风险预控方法,基于电力服务工单系统的数据,通过变量筛选及逻辑回归建模,建立各变量的评分卡模型,科学地评价每一个字段的不同区间属性对用户敏感性的解释程度,针对新客户及新工单都有很好的解释及预测能力,从而能够对每个用户的敏感性进行打分与识别,以便针对性地进行服务资源分配及调度、面对突发情况及时做好应对措施,有助于减少工单投诉压力,最终有效提升服务质量。
附图说明
[0032]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍。显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0033]
图1为本发明的流程示意图。
具体实施方式
[0034]
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0035]
一种工单投诉风险预控方法,如图1所示,输入训练数据集和测试数据集,检测数据分布情况并统计信息,同时对数据进行预处理。
[0036]
其中,检测数据分布情况并统计信息,同时对数据进行预处理,包括:
[0037]
统计数据的缺失比例、最大值、最小值相关信息,确定各字段的长度、类型,将存在
异常数据(异常值/缺失值)的字段处理为正常数据。
[0038]
本技术技术方案中,将电力服务工单系统的数据以4:1的比例分为训练数据集、测试数据集,其中训练数据集负责训练模型,测试数据集负责测试训练后模型的拟合效果。
[0039]
对变量进行筛选,删除对回归模型影响不显著或自相关性较强的变量,具体包括:
[0040]
计算每个变量的信息价值,根据信息价值和变量间自相关性对变量进行筛选,保留信息价值大于0.01且变量间自相关性系数大于0.7的变量,并结合逐步回归(双向)删除对回归模型影响不显著或自相关性较强的变量。
[0041]
本技术技术方案中,信息价值(即iv值)用来衡量变量的预测能力,iv值越大,表示该变量的预测能力越强。
[0042]
利用卡方方法对变量进行分箱,对变量进行woe转化,并判断变量的稳定性。
[0043]
①
利用卡方方法对变量进行分箱,包括:
[0044]
分箱后观察分箱结果,当分箱结果不理想时进行手动调整分箱。
[0045]
②
对变量进行woe转化(即证据权重),包括:
[0046]
采用下式对变量进行woe转化:
[0047][0048]
其中,i为某个特征的第i个分箱,badi为在第i个分箱中坏标签的数量,bad
t
为坏标签的总数,goodi为在第i个分箱中好标签的数量,good
t
为好标签的总数。
[0049]
woe是对原始自变量的一种编码形式,需要对训练数据集和测试数据集都进行woe转化。
[0050]
③
判断变量的稳定性,包括:
[0051]
计算每列特征的psi值,并基于psi值判断变量的稳定性。
[0052]
其中,psi值越小,代表两个特征之间分布的差异越小,变量越稳定,本技术技术方案模型中变量的psi值均小于0.001。
[0053]
建立回归模型,利用训练数据集和测试数据集评价回归模型的准确性,具体包括:
[0054]
利用logistic回归建立回归模型,并对训练数据集和测试数据集进行预测,分别计算两个数据集的ks值和auc值,评价回归模型的准确性。
[0055]
其中,ks值的取值范围是[0,1],一般习惯乘以100%。通常来说,ks值越大,表明正负样本区分程度越好,ks值在41%-50%代表模型有良好的好坏样本区别能力;ks值在51%-60%代表模型有很强的好坏样本区别能力。利用训练数据集得到模型的ks值为49.92%,利用测试数据集得到模型的ks值为53.65%,反应出此模型的样本区分程度较强。
[0056]
auc值的含义为,当随机挑选一个正样本和一个负样本,根据当前分类器计算得到的分数将这个正样本排在负样本前面的概率。auc值一般在0.5~1之间,auc值越接近1,检测方法的真实性越高,模型的拟合效果越好。利用训练数据集得到模型的auc值为81.63%,利用测试数据集得到模型的auc值为81.92%,说明此模型具有较好的分类效果。
[0057]
将回归模型转换为标准评分卡,并输出各变量分箱后的分数。科学地评价每一个字段的不同区间属性对用户敏感性的解释程度,针对新客户及新工单都有很好的解释及预测能力,从而能够对每个用户的敏感性进行打分与识别,以便针对性地进行服务资源分配及调度、面对突发情况及时做好应对措施,有助于减少工单投诉压力,最终有效提升服务质
量。
[0058]
以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不会使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1