一种混合抑制数据增强方法
1.本发明涉及图像处理领域,尤其涉及一种混合抑制数据增强方法。
背景技术:
2.在以水表、电表等为代表的数字式仪表读数识别领域,现阶段通常以人工手动抄录为主,少部分企业辅助以传统机器视觉进行抄录。然而,数字式仪表所处环境与工业场景不同,更为接近自然场景,具有多变性的特点,传统机器视觉对特征明显的目标检测效果不错,但是手工特征提取繁琐复杂,依赖设计者的专业知识,且缺乏泛化能力,难以满足数字式仪表读数识别的需求。
3.近年来,随着深度学习的高速发展,将深度学习用于数字式仪表的读数识别成为可能。为了充分发挥神经网络的性能,需要大量的数据训练深度神经网络。然而,在关注度相对较少的特殊领域,受客观条件和人力成本等因素的限制,很难获取优质的大规模数据集。在数字式仪表识读这一应用上则不仅要面临企业难以获取大规模数据集的问题,还存在采集到的数据集必然呈现长尾分布的特点。以字轮式水表为例,一般字轮式水表包含5个数字用于表示用水的数量,字轮式水表在出厂时都处于初始状态“00000”,想要到达“9xxxx”需要相当长的一段时间,导致高位数中数字“0”的数量要远高于其他的数字类别。因此,采集到的图像中,数字“0”占据了数据集的大部分,整个数据集呈现长尾分布。呈现长尾分布的数据集会很大程度的影响神经网络的训练效果,现阶段解决数据集的长尾分布现象,通常是三类方法:1)重采样法,对头部类别随机的删减,对尾部类别重复采样,使数据样本趋于平衡。这类方法对于小数据集极为不利,本身数据集样本较少,仍删除部分头部类别,大大降低了对数据集的利用效率,而尾部类别则容易发生过拟合。2)重权重法,通过分析数据样本分布,为每个类别的置信度设计一个惩罚权重。这类方法没有可学习参数无法学习,且小数据集中的数据样本分布不一定符合实际样本分布。3)新型损失函数法,通过设计类似focal loss等损失函数的方法指导网络学习。这类方法对超参数敏感,添加新的损失函数需要重新考虑不同损失函数之间的平衡,在迁移至检测框架的时候表现不佳。
技术实现要素:
4.针对上述问题,考虑到当前主要的几种方法在缓解数据集长尾分布的同时,可能会带来新的问题,本发明从数据增强的角度出发,发明了一种混合抑制数据增强方法,旨在缓解长尾分布数据集对神经网络带来的负面影响,在检测阶段不会产生额外的计算开销,且保证了原数据集标签空间分布极具规律性的特征,与其他数据增强方法互不影响。
5.具体内容如下:
6.s100.参数初始化,设置训练深度神经网络模型的总次数为epoch步,当前训练次数为num=0,当前训练次数中已读入图像的总数为k=0,设置混合抑制数据增强算法的初始概率为产生两个随机数分别赋给随机变量p1,p2;产生一个随机数赋给控制遮挡标签的程度的因子γ;
7.其中,β为控制因子,β∈[0,1];p1,p2∈[0,1];γ∈[0.5,1];
[0008]
的定义如下:
[0009][0010]
式中,代表标签bi所属类别的标签数,为数据集中标签的总数;
[0011]
s200.读入一幅带标签的图像ik,根据概率对图像ik中标签所在区域的信息进行擦除或是补充, k=k+1,若k《l,则执行步骤s200,否则执行步骤s300;其中,l为数据集中带标签图像的总数;
[0012]
s300.更新如果num《epoch,则num=num+1,并执行步骤s200,否则退出训练,结束。
[0013]
本发明具有如下优点:
[0014]
1.本发明随着训练深度神经网络的进行过程,动态平衡加入训练的各个标签类别的数量,能有效缓解长尾分布带来的负面影响,提升数据集各个类别的多样性,且不会在检测阶段带来额外的计算开销;
[0015]
2.本发明能大幅提高尾部类别的检测效果,大大节省人工采集和标注标签的成本与时间。
附图说明
[0016]
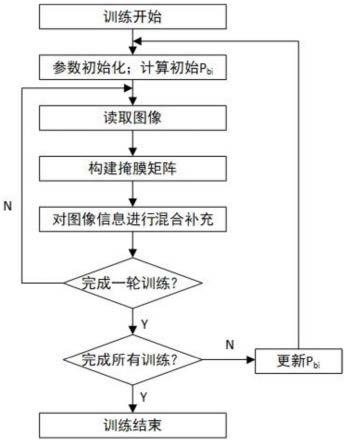
图1是本发明的流程图;
[0017]
图2是本发明处理的第k幅数字仪表图像ik以及标注方式;
[0018]
图3(a)、(b)是本发明被选中的m和m掩膜标签;
[0019]
图4是本发明生成的新的自然样本。
[0020]
图5是头部类别数字“0”标签占整个数据集标签的比例随α的变动曲线图
具体实施方式
[0021]
实施本发明,以字轮式水表数据集为例说明具体实施过程。构建的字轮式水表数据集包含大小为512
ꢀ×
512的1253张rgb图像,即l=1253;每张字轮式水表图像包含5个数字,数字的范围为[0,9],每个数字对应一个标签,即w=512、h=512、c=3,设训练图像,标签集合b=[b0,b1…
b5]和标签信息bi=[xi,yi,wi,hi],如图2,xi、yi为标签的左上角坐标,wi、hi为标签的宽和高,算法整体流程图如图1所示。
[0022]
s100.初始化参数p1,p2←
rand(0,1),γ
←
rand(0.5,1),β=0.3,即产生两个随机数分别赋给随机变量 p1,p2,产生一个随机数赋给控制遮挡标签的程度的因子γ,设置训练深度神经网络模型的总次数为epoch 步,当前训练次数为num=0,当前训练次数中k=0,设置混合抑制数据增强算法的初始概率为
[0023]
的定义如下:
[0024][0025]
式中,代表标签bi所属类别的标签数,为数据集中标签的总数;
[0026]
s200.若k》=l(l=1253),则执行步骤s300,读入一幅带标签的图像ik,如图2,根据概率对图像ik中标签所在区域的信息进行擦除或是补充,k=k+1;
[0027]
s210.构建矩阵m∈(0,1)w×h×c,m初始值矩阵的全部元素为1,构建矩阵为标签bi所属位置的二进制掩码,表示图像ik在该位置是否进行区域信息擦除,构建m∈(0,255)w×h×c,m初始值矩阵全元素为0,构建掩码,为标签bi所属位置的初始值全0的掩码,表示图像ik中在区域信息擦除位置补充的信息,如图3(a)、(b)为被选中的和
[0028]
s220.当前标签序号为i,i的初始值为0,i∈[0,6];
[0029]
s230.若i》=n,则执行s280,若则对当前标签bi不做任何处理,i=i+1,执行s230,否则执行s240;
[0030]
s240.若p2《β,则执行步骤s241,否则执行步骤s250;
[0031]
s241.对(2)、(3)、(4)式等概率随机执行其中一个:
[0032][0033][0034][0035]
其中
“←”
表示赋值,delete表示删除操作;
[0036]
s242.对被信息擦除的区域补充随机的rgb值,即式(5)的操作,i=i+1,若i》=5,则执行s280,否则执行步骤s220;
[0037]
mi←
m(bi)=rand(0,255)
ꢀꢀꢀ
(5)
[0038]
式中,函数rand(a,b)表示在[a,b]范围内随机产生一个数;
[0039]
s250.去除标签bi,将图像ik中剩余的标签概率之和归一化形成如式(6),将图像ik中剩余的标签构建成一个候选标签集bufferp,从候选标签集bufferp中根据概率选取信号源标签bj;
[0040][0041]
s260.执行式(7),i=i+1,执行步骤s230;
[0042][0043]
s270.计算m与m,如式(8)、式(9):
[0044][0045][0046]
s280.(10)式中进行逐元素的乘法得到新的图像图4为生成后的新的图像
[0047][0048]
s300.在完成一次训练后对进行更新:
[0049][0050]
式中,n∈[0,9]代表标签的类别,gi表示在训练过程中实时统计该类别已加入训练的标签数量,∑
ngi
代表当前训练中加入训练的标签总数。α∈[0,1]为超参数,用于表示控制头部标签在训练过程中的下降速度与最终的占比;
[0051]
训练结束后,头部类别数字“0”标签占整个数据集标签的比例随α的变动如图5所示,图5中纵坐标表示数字“0”在整个数据集标签的比例,横坐标表示训练深度神经网络模型的次数。头部类别加入训练的标签比例随训练进行逐步降低,尾部各类别标签所占比例相应都有所提升。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1