基于自然语言的图像修改与生成方法
1.本发明涉及一种图像修改与生成方法,特别是涉及一种基于自然语言的图像修改与生成方法。
背景技术:
2.随着计算机硬件算力和深度学习算法的发展,计算机智能辅助图像设计已经逐渐成为设计师工作中的关键工具,包括自动上色,自动填充等。这些算法在设计师已有工作的基础上给出参考建议,或补足缺失信息,提高了设计专业人士的工作效率。
3.然而对于非专业人士,专业知识的匮乏使得创意产出本身变得困难,无法利用辅助设计工具产出图像创意。
4.传统的基于一定范围内的文本信息进行图像修改与生成的算法多是通过将图像生成模型与语言模型共同训练得到的文本-图像生成能力,其生成能力仅限于训练时提供的文本范围。由于图像生成模型的复杂性,该范围通常较为局限,且生成图像的过程中无法进行精细调整。
技术实现要素:
5.针对现有技术中存在的上述不足,本发明的目的是提供一种基于自然语言的图像修改与生成方法,该方法填补了通过自然语言进行可精细化控制的图像修改或生成任务的空白,图像修改与生成效果好,能在较短时间内获取输出结果。
6.本发明是通过下述技术方案来解决上述技术问题的。
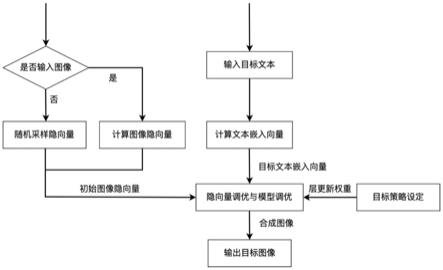
7.一种基于自然语言的图像修改与生成方法,包括如下步骤:
8.步骤s1,根据任务类型,基于输入的图像计算获取初始图像隐向量;
9.步骤s2,输入目标文本,基于所述目标文本计算目标文本嵌入向量;
10.步骤s3,设定不同目标生成策略,基于目标生成策略计算对应的图像生成预训练模型的层更新权重;
11.步骤s4,依据输入图像计算初始图像隐向量、目标文本嵌入向量与层更新权重,对图像生成预训练模型的参数与图像隐向量进行训练调优,以得到更新后的合成图像的隐向量和图像生成预训练模型;
12.步骤s5,基于更新后的合成图像的隐向量和图像生成预训练模型,得到并输出合成的目标图像。
13.优选地,所述步骤s1包括如下步骤:
14.步骤s1.1,获取用户输入,确定输入中是否存在图像;
15.步骤s1.2,若步骤s1.1中判断为是,则当前任务为修改图像,使用图像编码器计算输入的图像对应的隐向量,将计算得到的隐向量作为初始图像隐向量;
16.步骤s1.3,若步骤s1.1中判断为否,则当前任务为生成图像,在输入层的隐空间内随机采样隐向量作为初始图像隐向量;
17.其中,图像编码器为具有逆向计算对应图像生成器的输入隐向量的编码器,例如对应stylegan的restyle编码器。
18.优选地,所述步骤s2包括如下步骤:
19.步骤s2.1,获取用户输入的目标文本;
20.步骤s2.2,通过分词器将所述目标文本拆分为符号集;
21.步骤s2.3,使用预训练文本编码器计算所述符号集的目标文本嵌入向量。
22.其中,分词器为具有对自然语言文本进行单词拆分与符号转化的码本。预训练文本编码器为具有对文本符号集进行向量空间嵌入的文本模型。分词器与文本编码器通常成对使用,例如gpt2的分词器与文本编码器。
23.优选地,所述步骤s3包括如下步骤:
24.步骤s3.1,设定不同目标生成策略,所述目标生成策略包括自由度的设定,所述自由度的设定包括:形状自由度、纹理自由度和内容自由度的设定;
25.步骤s3.2,根据设定的目标生成策略计算对应图像生成预训练模型的层更新权重,其中,所述层更新权重,用于决定所述图像生成预训练模型的各层的可训练度
26.其中,自由度为控制生成图像效果的超参数,自由度越高则生成范围越广,但失真概率越大;自由度越低则生成范围越窄,但失真概率越小。图像生成预训练模型为具有层解耦能力的预训练图像生成器,例如stylegan。层更新权重决定生成模型各层的可训练度。
27.优选地,所述步骤s4包括如下步骤:
28.步骤s4.1,将初始图像隐向量输入图像生成预训练模型,获取输出的合成图像;
29.步骤s4.2,将输出的合成图像输入预训练视觉嵌入模型,获取合成图像的嵌入向量;
30.步骤s4.3,将合成图像的嵌入向量与目标文本符号集的嵌入向量输入对比语言图像预训练模型,计算语义距离作为模型训练的对比损失值;
31.步骤s4.4,将所述对比损失值反向传播到网络各节点,根据层更新权重缩放各节点损失值,再通过优化器更新合成图像的隐向量与图像生成预训练模型的参数。
32.其中,对比语言图像预训练模型为根据文本图像对进行预训练的模型,具有计算文本与图像之间的语义距离的能力,相较于图像生成预训练模型的具有更广的图像覆盖范围,且语料来源丰富,例如clip模型。
33.优选地,所述步骤s5包括如下步骤:
34.步骤s5.1,将更新后的合成图像的隐向量输入更新后的图像生成预训练模型,获取合成的目标图像;
35.步骤s5.2,将合成的目标图像输出至显示屏并展示结果。
36.与现有技术相比,本发明具有如下有益效果:
37.1、本发明利用了包括图像生成模型,图像编码器模型,文本编码器模型,和对比语言图像模型的预训练模型,将自然语言与图像的修改与生成任务解耦,使得语料库可自由扩增或替换,实现了基于自然语言的图像修改与生成。
38.2、本发明引入了图像合成的目标策略设定,通过对层更新权重的定义控制合成图像的形状、纹理、内容等特征,具有可精细化控制的特点。
39.3、本发明无需耗费长时间进行模型训练,仅需对图像嵌入向量与模型参数进行调
优。
40.4、本发明将图像的修改与生成统一在同一框架下,具有更好的通用性。
41.5、本发明填补了通过自然语言进行可精细化控制的图像修改或生成任务的空白。
附图说明
42.通过阅读参照以下附图对非限制性实施例所作的详细描述,本发明的其它特征、目的和优点将会变得更明显:
43.图1为本发明所述基于自然语言的图像修改与生成方法的算法框架图;
44.图2为基于本发明进行图像修改的结果示意图;
45.图3为基于本发明进行图像生成的结果示意图。
具体实施方式
46.下面结合具体实施例对本发明进行详细说明。以下实施例将有助于本领域的技术人员进一步理解本发明,但不以任何形式限制本发明。应当指出的是,对本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变化和改进。这些都属于本发明的保护范围。
47.针对现有技术中存在的语料受限,可控性低,速度较慢等问题,本发明的目的是提供一种基于自然语言的图像修改与生成方法,该方法填补了通过自然语言进行可精细化控制的图像修改或生成任务的空白,图像修改与生成效果好,能在较短时间内获取输出结果。
48.如图1所示,本实施例提供了一种基于自然语言的图像修改与生成方法,包括:
49.步骤s1,根据任务类型,基于输入的图像计算获取初始图像隐向量;
50.步骤s2,输入目标文本,基于所述目标文本计算目标文本嵌入向量;
51.步骤s3,设定不同目标生成策略,基于目标生成策略计算对应的图像生成预训练模型的层更新权重;
52.步骤s4,依据输入图像计算初始图像隐向量图像、目标文本嵌入向量文本与层更新权重生成策略策略,对图像生成预训练模型的参数与图像隐向量进行训练调优,以得到更新后的合成图像的隐向量和图像生成预训练模型;
53.步骤s5,基于更新后的合成图像的隐向量和图像生成预训练模型,得到并输出合成的目标图像。
54.所述步骤s1包括如下步骤:
55.步骤s1.1,获取用户输入,确定输入中是否存在图像;
56.步骤s1.2,若步骤s1.1中判断为是,则当前任务为修改图像,使用图像编码器计算输入的图像对应的隐向量,将计算得到的隐向量作为初始图像隐向量;
57.步骤s1.3,若步骤s1.1中判断为否,则当前任务为生成图像,在输入层的隐空间内随机采样隐向量作为初始图像隐向量。
58.其中,图像编码器为具有逆向计算对应图像生成器的输入隐向量的编码器,例如对应stylegan的restyle编码器。
59.所述步骤s2包括如下步骤:
60.步骤s2.1,获取用户输入的目标文本;
61.步骤s2.2,通过分词器将所述目标文本拆分为符号集;
62.步骤s2.3,使用预训练文本编码器计算所述符号集的目标文本嵌入向量。
63.其中,分词器为具有对自然语言文本进行单词拆分与符号转化的码本。预训练文本编码器为具有对文本符号集进行向量空间嵌入的文本模型。分词器与文本编码器通常成对使用,例如gpt2的分词器与文本编码器。
64.所述步骤s3包括如下步骤:
65.步骤s3.1,设定不同目标生成策略,所述目标生成策略包括自由度的设定,所述自由度的设定包括:形状自由度、纹理自由度和内容自由度的设定;
66.步骤s3.2,根据设定的目标生成策略计算对应图像生成预训练模型的层更新权重,其中,所述层更新权重,用于决定所述图像生成预训练模型的各层的可训练度。
67.其中,自由度为控制生成图像效果的超参数,自由度越高则生成范围越广,但失真概率越大;自由度越低则生成范围越窄,但失真概率越小。图像生成预训练模型为具有层解耦能力的预训练图像生成器,例如stylegan。层更新权重决定生成模型各层的可训练度。
68.所述步骤s4包括如下步骤:
69.步骤s4.1,将初始图像隐向量输入图像生成预训练模型,获取输出的合成图像;
70.步骤s4.2,将输出的合成图像输入预训练视觉嵌入模型,获取合成图像的嵌入向量;
71.步骤s4.3,将合成图像的嵌入向量与目标文本符号集的嵌入向量输入对比语言图像预训练模型,计算语义距离作为模型训练的对比损失值;
72.步骤s4.4,将所述对比损失值反向传播到网络各节点,根据层更新权重缩放各节点损失值,再通过优化器更新合成图像的隐向量与图像生成预训练模型的参数。
73.其中,对比语言图像预训练模型为根据文本图像对进行预训练的模型,具有计算文本与图像之间的语义距离的能力,相较于图像生成预训练模型的具有更广的图像覆盖范围,且语料来源丰富,例如clip模型。
74.所述步骤s5包括如下步骤:
75.步骤s5.1,将更新后的合成图像的隐向量输入更新后的图像生成预训练模型,获取合成的目标图像;
76.步骤s5.2,将合成的目标图像输出至显示屏并展示结果。
77.本实施例填补了通过自然语言进行可精细化控制的图像修改或生成任务的空白,图像修改与生成效果好,能在较短时间内获取输出结果。
78.图2为基于本发明进行图像修改的结果示意图;图3为基于本发明进行图像生成的结果示意图。
79.以上所述的具体实施例,对本发明的解决的技术问题、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施例而已,并不用于限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1