软硬协同的分段扫描式蒙哥马利模幂计算系统及可读存储介质
1.本发明涉及加解密运算领域,尤其涉及一种软硬协同的分段扫描式蒙哥马利模幂计算系统及可读存储介质。
背景技术:
2.近年来,随着计算机和电子商务的发展,人类进入了信息时代,在信息爆炸的今天,隐私的安全需求日益增多,人们对于信息的快速加密,安全传输,机密保存有了更进一步的需求。信息安全不仅关系到国家的安危,战争的走向,经济的发展等大的方面,而且关系到个人的身份信息,银行账户,信息传递等等切身利益。因此密码学的发展在电子信息领域中有更加迫切的需求,在密码学中,最基本的,是信息加密、解密分为对称加密和非对称加密,这两者的区别在于是否在加密解密时是否使用了相同的密钥。
3.前者由于加密和解密使用的是同一个秘钥,计算量小、加密速度快、加密效率高,但是秘钥的管理和分发非常困难,不够安全。后者加密和解密使用不同的秘钥,安全性更高,公钥是公开的,秘钥是自己保存的,不需要将私钥给别人,但是加密和解密花费时间长、速度慢,只适合对少量数据进行加密。
4.rsa加密算法是一种非对称加密算法。在公开密钥加密和电子商业中rsa被广泛使用。目前普遍认为,rsa的安全性来源于大数分解,目前并没有合适的算法来处理大数分解。rsa算法的最核心运算是有限域的模幂运算,软件处理模幂运算由于运算量过于庞大,速度一直是rsa算法的最大限制,因此模幂运算的硬件加速有广泛的应用前景。
5.为了加速模幂的运算过程,许多模幂优化算法需要在模幂运算前,在软件层面进行预计算,再将与计算的值作为输入值传递到fpga,因此单纯的软件计算和fpga运算无法兼顾两者。单纯的软件计算大数模幂效率太低,而单纯的fpga灵活性较差,对于预计算的进行以及结果传输由较大的约束性。
技术实现要素:
6.发明目的:提出一种软硬协同的分段扫描式蒙哥马利模幂计算系统,该方案结合2k分段扫描算法和蒙哥马利算法,可以自主完成整模幂运算的数据预计算以及结果数据的传输,传输到指定的fpga地址,并启动fpga来进行具体的模幂运算,充分利用了软件的灵活性以及fpga的加速效果,灵活且高效的不同的模数n的模幂运算,更好的满足实际应用的需求,从而解决现有技术存在的上述问题。
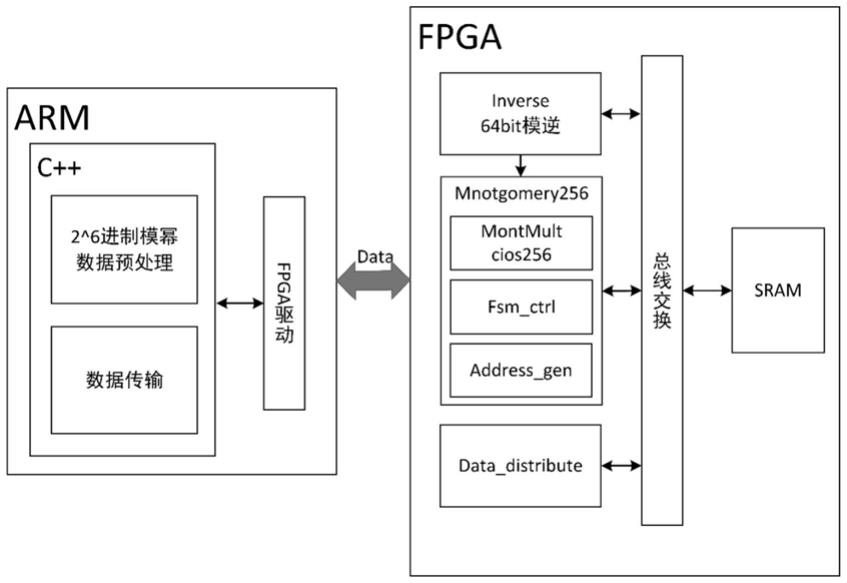
7.第一方面,提出一种软硬协同的分段扫描式蒙哥马利模幂计算系统,具体由以下技术方案实现:
8.本发明具体实施是基于soc软硬协同实现的256bit蒙哥马利模幂运算(memodn),arm端用于完成整体的任务调度,以及生成2k进制分段扫描算法需要的预计算和修正系数,fpga端完成计算密集的模幂运算。
9.arm端产生2k进制分段扫描算法所需要的预算值,以及修正系数factor。本发明采用6bit分段扫描的方式,根据2k进制分段扫描算法的具体流程,共需要(26)个预计算值以及1个修正系数。
10.除此之外arm端需要开发驱动模块,用于与数据预处理模块建立双向通信,驱动fpga,与fpga建立数据的双向通信。
11.fpga端主实现模逆模块,该模块采用了扩展欧几里得算法来计算64bit模逆的值,提供给蒙哥马利模块,作为额外的预处理值。求a关于m的模逆x,即a*x≡1(mod m),将其转化为求x和y使得ax+my=1成立,其中y为额外求出的值。模逆采用直接的扩展欧几里得算法,利用欧几里得算法的性质:ax+my=a1x1+m1y1=
…
=1,其中递归运算来得到最终的结果,递归的边界为mn=0。核心递归代码如下所示:
[0012][0013]
式中,mod表示取模运算,/表示整除,(xn,yn)(x
n-1yn-1
)为相邻两次递归的求解,(an,mn)(a
n-1
,m
n-1
)相邻两次递归的源数据转化。
[0014]
数据分配模块,作为arm端与fpga端的数据交接模块,用于arm的存取数。受限于arm端是32位操作系统,且avalon接口为128bit,因此该模块需要对数据的位宽进行处理。此模块也完成数据读出的功能,从sram中读出256bit的结果数据,对数据进行拆分。
[0015]
sram模块,存储源数据,预算值,修正系数以及结果数据,设计为256bit位宽。
[0016]
蒙哥马利模幂模块,用于实现256bit模幂的具体运算,其主要包括:256bit蒙哥马利模乘(montmult)模块,状态机控制模块(fsm_ctrl),地址生成模块(addgent)。状态机控制模块完成整个模幂算法的控制流程,依次调用montmult模块;
[0017]
其中256bit蒙哥马利模乘模块是最核心的计算模块,其基于cios优化算法实现,原始的cios算法包括以下步骤:
[0018]
步骤1、模逆模块先启动,得到n
′0表示模乘运算所需要的模逆值,这里用作生成修正系数,表示对n的低64bit的模逆操作,r表示64bit模逆的取模值,这里r=2
64
;
[0019]
步骤2、将源数据a,b,n按照64bit为单位划分为4段
[0020]
步骤3、遍历源数据a[63:0]和b的四段64bit数据,依次进行乘法,分别存储为t[0]~t[3]
[0021]
步骤4、在有限域下,得到修正系数m
[0022]
m=t[0]
×n′0[0023]
式中,t[0]表示步骤3结果的低64bit,即修正前的结果数据。
[0024]
步骤5、将修正系数依次乘以n的四段并加上对应的t[0]~t[3],对结果进行修正,使得修正后的值可以被r整除,从而可以用移位操作代替除法操作。
[0025]
步骤6、判断是否遍历了a的四段数据,若没有,则将a右移64bit,返回步骤3。
[0026]
步骤7、由低到高拼接t[0]~t[3],记为t,若t》n,则返回t-n,否则返回t。
[0027]
根据上述算法流程,原始算法由两个内循环,可以再循环方面进行流水话的优化,步骤3的分段乘法运算和步骤5的结果修正可以流水化,无需等待步骤3的循环完全结束后
再开始步骤5的循环,可以在步骤3开始的下一个周期开始步骤5的计算,仅需要增加少量的周期就可以完成两个内循环的运算。
[0028]
模幂运算整体采用2k进制分段扫描算法,根据分段数k取值的不同,该算法可以有不同程度的优化,主要体现在模乘的调用次数。考虑到实际的执行效率以及资源消耗,本发明选用6bit分段扫描的方式,想不传统的模幂二进制算法总体可以降低12.5%的模乘次数。6bit分段算法所需要的预算值和修正系数如下所示:
[0029]
r[i]=mimodn,其中i∈{0,1,2,3
…2k-1}
[0030]
factor=2
65n
modn,其中n=256;
[0031]
式中,modn表示对n的取模操作,mi表示对源数据的幂指数操作,n表示模乘的位宽,此处为256;
[0032]
蒙哥马利模幂的2k进制分段扫描算法(k=6),具体包括以下步骤:
[0033]
步骤1、按照6bit为一组的准则,将幂指数e进行扫描分段,此处为256bit,需要在高位补3个零,之后按照6bit一组,得到43组6bit分段,记为r[0:42],初始化r=0。
[0034]
步骤2、若r=0,根据r[r]的值来初始化s。
[0035]
步骤3、若r!=0,则s=montmult(r[r],s)
[0036]
步骤3、s=montmult(s,s)
[0037]
步骤4、判断是否完成6次,若未完成则返回执行步骤4,若完成则执行步骤5。
[0038]
步骤5、修正结果,s=montmult(s,factor)
[0039]
步骤6、判断是否完成扫描43组的6bit分段,若完成扫描则输出s,否则r自增1,返回步骤3。
[0040]
第二方面,提出一种可读存储介质,该可读存储介质中存储有计算机执行指令,当处理器执行所述计算机执行指令时,驱动第一方面所述的计算系统执行预定计算指令。
[0041]
有益效果:
[0042]
本发明实现了基于soc的软硬协同的分段扫描式蒙哥马利模幂算法,可以灵活的利用arm进行预计算,实现不同模数n的模幂运算,较为高效的进行模幂计算。
[0043]
本发明采用了模块化设计,主要实现了模逆模块以及蒙哥马利模乘模块,其中模乘模块采用了流水化的cios算法,高效实现模乘操作,提高效率。
[0044]
本发明采用了2k进制分段扫描算法结合蒙哥马利算法,权衡资源消耗以及效率,有效降低模乘的调用次数。
[0045]
本发明在硬件实现了扩展欧几里得算法的模逆模块,尽可能的利用fpga的计算优势,提高计算效率。
附图说明
[0046]
图1是本发明的软硬件实现方案总体架构。
[0047]
图2是本发明的蒙哥马利cios模乘流程图。
[0048]
图3是本发明的cios流水化优化示意图。
[0049]
图4是本发明设计的优化后模乘波形示意图。
[0050]
图5是本发明的6bit分段扫描模幂状态机。
[0051]
图6是本发明的6bit分段扫描模幂的总流程。
具体实施方式
[0052]
在下文的描述中,给出了大量具体的细节以便提供对本发明更为彻底的理解。然而,对于本领域技术人员而言显而易见的是,本发明可以无需一个或多个这些细节而得以实施。在其他例子中,为了避免与本发明发生混淆,对于本领域公知的一些技术特征未进行描述。
[0053]
本发明具体实施是基于soc软硬协同实现的256bit蒙哥马利模幂运算(memodn),arm端用于完成整体的任务调度,以及2k进制分段扫描算法需要的预计算和修正系数,并将预计算的结果存入指定的fpga地址,并再计算结束之后将结果数据从fpga端搬出。fpga端完成计算密集的任务,加速模幂的运算,具体结构见图1。
[0054]
arm端最主要的模块是预计算模块,用于产生2k进制分段扫描算法所需要的预算值,以及所需的修正系数factor。本发明采用6bit分段扫描的方式,根据2k进制分段扫描算法的具体流程,共需要(26)个预计算值以及1个修正系数,且该预计算值只与m和n有关,修正系数与位宽和n有关,因此相同模n的情况下,一次计算完成后可以固定为常数,也说明蒙哥马利算法更适用于模n固定的情况。具体需要的预算值和修正系数在下文算法介绍的部分列出。
[0055]
除此之外arm端需要开发驱动模块,用于与数据预处理模块建立双向通信,驱动fpga,与fpga建立数据的双向通信,具体的的驱动映射到fpga端avalon总线,通过avalon总线实现具体的数据传输。
[0056]
fpga端主实现模逆模块,该模块采用了扩展欧几里得算法来计算64bit模逆的值,提供给蒙哥马利模块,作为额外的预处理值,由于模逆模块的结果是作为模幂算法的输入值使用的,具体的求a关于m的模逆x,即a*x≡1(mod m),将其转化为求x和y使得ax+my=1成立,其中y为额外求出的值。该模块并不会被大量调用,仅在模幂算法的开始调用一次,采用直接的扩展欧几里得算法,利用欧几里得算法的性质:
[0057]
ax+my=a1x1+m1y1=
…
=1,其中递归运算来得到最终的结果,递归的边界为mn=0。核心递归代码如下所示:
[0058][0059]
式中,mod表示取模运算,/表示整除,(xn,yn)(x
n-1yn-1
)为相邻两次递归的求解,(an,mn)(a
n-1
,m
n-1
)相邻两次递归的源数据转化。
[0060]
数据分配模块,作为arm端与fpga端的数据交接模块,用于arm的存取数。受限于arm端是32位操作系统,且avalon接口为128bit,因此实际上arm与avalon的交互是32bit的,而本发明是256bit的模幂运算,因此在此模块需要进行两段的数据拼接。首先要将128bit的avalon数据接口中提取出有效的32bit,分为4拍,后将有效的数据再拼接成256bit传入sram。此模块也完成数据读出的功能,从sram中读出256bit的结果数据,对数据进行拆分。
[0061]
sram模块,存储源数据,预算值,修正系数以及结果数据,设计为256bit位宽。
[0062]
蒙哥马利模幂模块,用于实现256bit模幂的具体运算,其主要包括:256bit蒙哥马利模乘(montmult)模块,状态机控制模块(fsm_ctrl),地址生成模块(addgent)。状态机控制模块完成整个模幂算法的流程,依次调用montmult模块;地址生成模块用于生成源数据
以及预算值的地址,从sram中取出对应的数,同时再计算完成的时候,生成结果数据的地址。
[0063]
其中256bit蒙哥马利模乘模块是最核心的计算模块,其基于cios优化算法实现,具体的流程图见图2,原始的cios算法包括以下步骤:
[0064]
步骤1、模逆模块先启动,得到n
′0表示模乘运算所需要的模逆值,这里用作生成修正系数,表示对n的低64bit的模逆操作,r表示64bit模逆的取模值,这里r=2
64
;
[0065]
步骤2、将源数据a,b,n按照64bit为单位划分为4段
[0066]
步骤3、遍历源数据a[63:0]和b的四段64bit数据,依次进行乘法,分别存储为t[0]~t[3]
[0067]
步骤4、在有限域下,得到修正系数m
[0068]
m=t[0]
×n′0[0069]
式中,t[0]表示步骤3结果的低64bit,即修正前的结果数据。
[0070]
步骤5、将修正系数依次乘以n的四段并加上对应的t[0]~t[3],对结果进行修正,使得修正后的值可以被r整除,从而可以用移位操作代替除法操作。
[0071]
步骤6、判断是否遍历了a的四段数据,若没有,则将a右移64bit,返回步骤3。
[0072]
步骤7、由低到高拼接t[0]~t[3],记为t,若t》n,则返回t-n,否则返回t。
[0073]
根据上述算法流程,原始算法由两个内循环,可以再循环方面进行流水话的优化,步骤3的分段乘法运算和步骤5的结果修正可以流水化,无需等待步骤3的循环完全结束后再开始步骤5的循环,由于是分段的乘法以及修正,因此可以在步骤3完成第一段乘法之后可以直接开始该段结果的修正。仅需要增加少量的周期就可以完成两个内循环的运算,示意图见图3,将原来的两个顺序执行内循环inner loop1和inner loop2,优化成流水计算的两个内循环,理论增加一个周期就可以完成两个内循环。
[0074]
根据流水化之后的逻辑以及流程图,设计波形,见图4,由图可见信号temp_cs和temp_after仅仅相差一拍,流水的进行计算,无需等待,最后在第23个周期的时候输出最终的模乘结果。
[0075]
模幂运算整体采用2k进制分段扫描算法,根据分段数k取值的不同,该算法可以有不同程度的优化,主要体现在模乘的调用次数。不同分段数所需的模乘次数,以及与传统的二进制模幂算法相比较模乘次数的降低比例如下表所示:
[0076]
表1:不同分段数所需的模乘次数以及与传统的二进制模幂算法相比较模乘次数的降低比例对照表
[0077]
分段数/模乘次数2k进制分段扫描(次)降低比例(%)预计算值4bit3781.56175bit3577.03336bit33612.50657bit32415.621298bit32016.67257
[0078]
考虑到实际的执行效率以及资源消耗,本发明选用6bit分段扫描的方式。
[0079]
因此6bit分段算法所需要的预算值和修正系数如下所示:
[0080]
r[i]=mimodn,其中i∈{0,1,2,3
…2k-1}
[0081]
factor=2
65n
modn,其中n=256;
[0082]
式中,modn表示对n的取模操作,mi表示对源数据的幂指数操作,n表示模乘的位宽,此处为256;
[0083]
i的二进制i的十进制r[i]0_00000001
………………
0_11111163m
63
modn1_000000642
65
×
256
modn
[0084]
蒙哥马利模幂的2
κ
进制分段扫描算法(k=6)的具体实现采用状态机的方式,见图5,状态机共有6个状态,分别是(idle,fetch,initial,next,loop,modify,done),其中。fetch为取数状态;initial是初始化状态,在整个流程中只执行一次;而loop为主体的循环体,在k=6的情况下,每一次大循环中,该循环需要循环6次;modify为结果修正的状态。详细的流程图见图6,具体步骤如下:
[0085]
步骤1、按照6bit为一组的准则,将幂指数e进行扫描分段,此处为256bit,需要在高位补3个零,之后按照6bit一组,得到43组6bit分段,记为r[0:42],初始化r=0。
[0086]
步骤2、若r=0,根据r[r]的值来初始化s。
[0087]
步骤3、若r!=0,则s=montmult(r[r],s)
[0088]
步骤3、s=montmult(s,s)
[0089]
步骤4、判断是否完成6次,若未完成则返回执行步骤4,若完成则执行步骤5。
[0090]
步骤5、修正结果,s=montmult(s,factor)
[0091]
步骤6、判断是否完成扫描43组的6bit分段,若完成扫描则输出s,否则r自增1,返回步骤3。
[0092]
至此已经完成模幂的运算,最后的s就是最终的模幂结果,对设计进行真实的仿真,得到一次完成模幂的波形图,working拉高在计算模逆,模逆运算的周期在整个模幂仅仅占用很小一部分。rdy_all拉高得到了最终结果。
[0093]
如上所述,尽管参照特定的优选实施例已经表示和表述了本实施例,但其不得解释为对本实施例自身的限制。在不脱离所附权利要求定义的本实施例的精神和范围前提下,可对其在形式上和细节上做出各种变化。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1