编译器优化方法、系统和存储介质与流程
platform)、或反馈驱动的优化编译器框架(feedback-driven optimization compiler framework)。
11.在一些实施例中,所述一个或多个轨迹中的每个轨迹包括一个或多个指标(metric),一个或多个指标包括以下至少一个:平均指令执行周期数(cycles per instruction,cpi)、执行时间、或平均累积指令的未命中数(miss per accruing instruction)。
12.在一些实施例中,获取中间代码和可执行代码包括:基于计算机程序生成中间代码;获取中间代码的树表示(tree representation);以及通过优化树表示来生成可执行代码。
13.在一些实施例中,获取中间代码和可执行代码包括:在编译器编译计算机程序后获得中间代码和可执行代码,且该方法还包括:触发被更新的编译器重新编译计算机程序。
14.在一些实施例中,计算机程序包括多个部分,且获取中间代码和可执行代码包括:通过由编译器编译计算机程序的第一部分来获得中间代码和可执行代码,且该方法还包括:用被更新的编译器编译计算机程序的第二部分。
15.在一些实施例中,强化学习代理训练用于推荐优化动作的优化策略,该方法还包括:从被更新的编译器获取新的可执行代码;通过在运行时系统中运行新的可执行代码获取一个或多个新的轨迹和新的奖励;并根据新的奖励和一个或多个优化动作训练优化策略。
16.根据另一些实施例,系统包括一个或多个处理器以及耦合到该一个或多个处理器的一个或多个计算机可读存储器,且该一个或多个计算机可读存储器具有存储在其上的指令,所述指令可由该一个或多个处理器执行以执行上述任何实施例的方法。
17.根据另一些实施例,非瞬时性计算机可读存储介质配置有可由一个或多个处理器执行的指令,以使该一个或多个处理器执行上述任何实施例的方法。
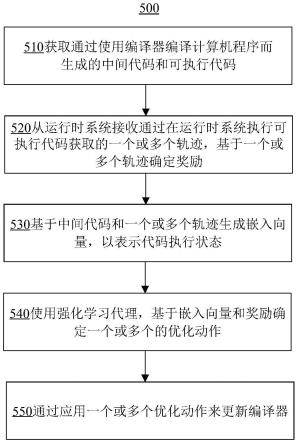
18.根据另一方面,ai辅助编译器的系统可包括一个或多个处理器以及耦合到该一个或多个处理器的一个或多个非瞬时性计算机可读存储器,该一个或多个非瞬时性计算机可读存储器存储指令,当由该一个或多个处理器执行指令时,使得系统执行以下操作:获取通过使用编译器编译计算机程序而生成的中间代码和可执行代码;基于在运行时系统中执行可执行代码而获得的一个或多个轨迹来确定奖励;基于中间代码和一个或多个轨迹生成嵌入向量,以表示代码执行状态;使用强化学习代理,基于嵌入向量和奖励确定一个或多个优化动作;以及通过应用一个或多个优化动作来更新编译器。
19.根据又一方面,非瞬时性计算机可读存储介质可以存储指令,当由一个或多个处理器执行指令时,使得该一个或多个处理器执行以下操作:获取通过使用编译器编译计算机程序而生成的中间代码和可执行代码;基于在运行时系统中执行可执行代码而获得的一个或多个轨迹来确定奖励;基于中间代码和一个或多个轨迹生成嵌入向量,以表示代码执行状态;使用强化学习代理,基于嵌入向量和奖励确定一个或多个优化动作;以及通过应用一个或多个优化动作来更新编译器。
20.本说明书中公开的实施例具有一个或多个技术效果。在一些实施例中,所述用于优化ai辅助编译器的方法和系统可以是平台无关的(例如,跨不同平台)。例如,ai辅助编译器可以在虚拟机(例如,java虚拟机(java virtual machine,jvm))、在物理机上运行的反
馈定向优化(feedback directed optimization,fdo)编译器框架、或另一适当环境中实现。在一些实施例中,基于强化学习(reinforcement learning,rl)学习对编译器的改进,该强化学习无缝地适合于编译器优化场景。例如,所述编译器优化涉及从来自运行由编译器生成的可执行代码的环境的定期反馈中学习并相应地优化编译器的迭代过程。类似地,rl框架中的rl代理可以与环境相互作用并基于环境的状态和反馈/奖励调整其动作和/或奖励策略,以及推荐优化动作。在一些实施例中,编译器公开多个接口,通过该多个接口中一个或多个接口,其与rl代理相互作用以执行推荐的优化动作。与只允许有限数量的控制编译算法的开/关标志的传统编译器相比,ai辅助编译器可以为rl代理暴露(expose)接口,以自动优化编译器。这种灵活性使ai辅助编译器更加动态,且实现更好的编译结果。在一些实施例中,在ai辅助编译器的训练过程中,来自运行可执行代码的环境的各种奖励可以被考虑在内。不同的奖励可以表明不同的优化焦点。例如,一些奖励(例如,基于平均指令执行周期数(cpi)的奖励)关注于改善执行时间,而其他奖励(例如,当可执行代码需要通过网络连接传输或部署在空间有限的边缘设备(edge device)中时)关注于生成的代码大小。因此,ai辅助编译器可以被配置为实现不同的优化目标。
附图说明
21.在参照附图考虑到下文描述和权利要求书后,本文公开的系统、方法和非瞬时性计算机可读介质的以上和其他特征,以及结构的相关元件的操作方法和功能,部件的组合以及批量生产的经济性将变得更加明显。所有附图都构成本说明书的一部分,其中类似参考编号在各种附图中指定相应的部分。然而,应明确地理解,附图仅用于说明和描述的目的,并不旨在作为本公开的界限的定义。
22.图1示出根据本公开实施例的示例环境,ai辅助编译器可以应用在该环境中。
23.图2示出根据本公开实施例的示例ai辅助编译器。
24.图3示出根据本公开实施例的使用ai辅助编译器编译计算机程序的示例工作流。
25.图4示出根据本公开实施例的使用ai辅助编译器编译计算机程序的示例方法。
26.图5示出根据本公开实施例的ai辅助编译器的示例方法。
27.图6示出根据本公开实施例的ai辅助编译器的计算机设备的框图。
28.图7示出计算机系统的示例框图,本文所述的任何实施例可以在该计算机系统中实现。
具体实施例
29.本说明书旨在使本领域任何技术人员能够制造和使用实施例,并在特定应用及其要求的上下文中提供本说明书。对于本领域技术人员来说,对本公开实施例的各种修改是显而易见的,并且本文定义的通用原理可以应用于其他实施例和应用,而不脱离本说明书的精神和范围。因此,说明书不限于所示的实施例,而是被赋予与本文公开的原理和特征一致的最广泛的范围。
30.为了解决当前技术方案的这些缺点,本说明书描述了一种ai辅助编译器,其采用强化学习框架来学习计算机程序编译的底层模式,并相应地优化编译器。编译器优化在无需更改原始的高级源代码的情况下提高了生成的可执行代码的质量。例如,当应用该优化
时,由被优化的编译器生成的代码可以在目标运行时运行得更快或更高效。本文所述的实施例涉及在编译器优化中应用强化学习(rl)。rl是受行为主义心理学启发的机器学习领域,且使用奖励或惩罚的概念,以便软件代理与环境相互作用且最大化其累积奖励。rl中的训练和测试阶段可以相互交织,这也可以称为反复试验过程。rl使用马尔可夫决策过程(markov decision process,mdp)以适应环境并与环境相互作用。
31.图1示出根据本公开实施例的示例环境,ai辅助编译器可以应用在该环境中。图1所示的两个示例环境包括java虚拟机(jvm)框架100和反馈驱动的优化(fdo)编译器框架150。根据实际应用场景,ai辅助编译器可以在其他合适的环境中实现,例如另一个合适的虚拟机、物理机、或云本地编译器即服务的平台。
32.在所示的jvm框架100中,java字节码110可以作为输入被馈送到jvm120。部署在jvm120中的ai辅助编译器130可以编译java字节码110,并输出生成代码140,例如“.class”文件、“.jar”文件、或其他可由jvm120执行的适当形式的代码。在一些实施例中,生成代码140可以由jvm120执行,且执行过程可以产生一些轨迹。轨迹可以包括用于指示生成代码140的质量的性能指标。这些性能指标可以包括平均指令执行周期数(cpi)、执行时间、每特定数量的指令的未命中数(miss per a certain number of instructions,例如,每一千个指令的未命中数(miss per kilo instructions))、另一个合适的指标,或以上任何组合。在一些实施例中,这些性能指标可以由运行时系统(例如,jvm120)或由ai辅助编译器130转换为用于优化的奖励。例如,在一些实施例中,ai辅助编译器130可以包括学习用于推荐和/或实施优化动作的优化策略以提高生成代码140的质量的rl代理。在这种情况下,rl代理可以使用奖励来更新优化策略,以便有效优化动作(例如,贡献于奖励的优化动作)和类似动作有更高的概率在将来被推荐,并且无效优化动作和类似动作有较低的概率在将来被推荐。
33.在所示的fdo编译器框架150中,源代码160可以用高级编程语言(例如,java或c++)编写。服务器机器180可指物理机或机器集群,在其上可以运行由ai辅助编译器基于源代码160生成的编译代码。在线监视器190可以保持跟踪服务器机器180上的编译代码的执行状态。在一些实施例中,在线监视器190可以从编译代码的执行状态收集轨迹,并且轨迹可被转换为对ai辅助编译器170的消耗的奖励。转换可以发生在服务器机器180上或在ai辅助编译器170中。奖励和轨迹可由ai辅助编译器170用来优化使用rl框架的编译代码的质量。在一些实施例中,被优化的ai辅助编译器170可用来再次编译源代码160以生成在服务器机器180上运行的更高质量的编译代码。这里,“再次编译”可以指再次编译相同的源代码160,或者编译源代码160的不同部分。
34.为了一致性和简单性,在本说明书中使用的术语“运行时(runtime)”或“运行时系统”指的是在其上运行编译代码的库、框架、系统、或平台,例如,jvm120和服务器机器180,以及术语“计算机程序”用于指馈送到ai辅助编译器170的代码,例如,字节码110和源代码160。
35.图2示出根据本公开实施例的示例ai辅助编译器。图2中组件的布局是为了说明性的目的。根据实施方式,附图可以包括更少、更多或替代的组件,并且一些组件可以被拆分或合并。例如,ai辅助编译器220和运行时系统230可以在相同的硬件组合内实现。
36.在一些实施例中,计算机程序210可以被输入到用于编译的ai辅助编译器220。编
译结果可以包括在运行时系统230上运行的可执行代码。运行时系统230可以收集可执行代码的运行轨迹或快照。这些轨迹或快照可以包括表示可执行代码的质量或特征的各种指标,例如,可执行代码的大小、执行时间、cip、或其他合适的指标。在一些实施例中,这些指标可以由运行时系统230或由ai辅助编译器220基于奖励函数被转换成奖励。ai辅助编译器220可以根据奖励调整其行为(例如,调整优化策略的参数)。调整的目标可以包括最大化奖励,使得ai辅助编译器220可以提高其对计算机程序210的编译质量。
37.在一些实施例中,ai辅助编译器220可以包括编译器组件222,、嵌入组件223和rl代理组件224。根据实施方式,ai辅助编译器220可以包括更多、更少或替代的组件。
38.在一些实施例中,编译器组件222可以包括用于将计算机程序210翻译成可在运行时系统230上运行的可执行代码的编译器,并且编译器暴露用于接收和实现对编译器的优化动作的一个或多个接口。编译器可以是静态的(例如,低级虚拟机(low-level virtual machine,llvm)或gnu编译器集合(gnu compiler collection,gcc)或动态的(例如,即时编译(just-in-time compilation,jit)或解释器)。在一些实施例中,编译器组件222中的编译器可以将计算机程序210作为输入并生成作为输出的中间代码和可执行代码。中间代码和可执行代码可以指不同平台的不同类型的代码。例如,如果运行时系统230是物理机,则中间代码可以指汇编代码,且可执行代码可以指二进制代码。在一些实施例中,生成中间代码和可执行代码可通过以下步骤:基于计算机程序生成中间代码;获取中间代码的树表示;以及通过优化树表示生成可执行代码。
39.在一些实施例中,由在编译器组件222中的编译器暴露的接口可以被概念化为标志。每个标志可以对应于编译器的一个或多个参数。这些标志可以基于应用于编译器的优化的部分进行切换。在一些实施例中,由在编译器组件222中的编译器暴露的接口可以是应用程序编程接口(application programming interface,api)的形式,其可以接收参数且执行对编译器的各种优化配置。在一些实施例中,接口暴露给rl代理组件224以执行优化动作。
40.在一些实施例中,嵌入组件223可以被配置为将代码执行状态表示为可输入到rl代理组件224的嵌入向量。本说明书中的术语“向量”可以指矩阵或其他合适的高维数据结构。嵌入向量可以指嵌入到运行时系统230上运行的可执行代码的数据流信息和控制流信息的高维向量。数据流信息可以包括诸如存储器引用的信息,以及控制流可以包括诸如程序执行位置的信息。在一些实施例中,可以通过从编译器组件222中的用于编译计算机程序210的编译器获取中间代码和可执行代码来获取嵌入向量;从运行可执行代码的运行时系统230获取轨迹和对应于轨迹的奖励;以及基于中间代码和轨迹生成嵌入向量,以表示代码执行状态。在一些实施例中,可以根据预定频率周期性地收集轨迹。
41.在一些实施例中,嵌入组件223可以包括图神经网络(gnn)。gnn是通过图节点之间传递的消息来捕获依赖(也称为代码依赖)的连接模型。这里,图可以指计算机程序210的图的表示。可以通过各种翻译器或现有的用于从源代码构造图的方法来生成图的表示。在一些实施例中,可通过以下操作基于依赖和从运行时系统230获取的轨迹获取嵌入向量:基于依赖和轨迹生成一个或多个序列向量;将一个或多个序列向量输入序列模型来生成嵌入向量。序列模型可以通过训练将一个或多个序列向量嵌入到一个或多个固定长度的向量的神经网络实现,由此得到的一个或多个固定长度向量的向量提供给rl代理组件224使用。
42.如上所述,在标准强化学习框架中,代理可以将环境状态和奖励作为输入,且确定动作以将环境移动到下一个状态,同时最大化累积奖励(cumulative reward)。类似地,在ai辅助编译器220的上下文中,rl代理组件224可被配置为接收作为环境状态的代码执行状态的嵌入向量(例如,向量化表示)和作为输入的与代码执行状态相对应的奖励,以及基于嵌入向量和奖励确定一个或多个优化动作。在一些实施例中,运行时系统230可以使用奖励函数且基于通过运行可执行代码收集的轨迹来计算奖励。奖励可以包括性能测量指标,例如,执行时间、cpi、其他合适的指标、或由此的任何组合。在一些实施例中,rl代理组件224可以基于输入训练用于推荐优化动作的优化策略。在一些实施例中,一个或多个优化动作可以包括以下至少一个:向量化、指令排序和启发式馈送(heuristic feed)。
43.在一些实施例中,rl代理组件224可以进一步被配置为触发由编译器组件222暴露的一个或多个接口以应用一个或多个确定优化动作来更新/优化编译器。在一些实施例中,可以通过使用被更新的编译器(全部地或部分地)重新编译计算机程序210,在运行时系统230上运行生成的可执行代码,并确定新的奖励,以便于在下一轮编译和训练中评估已应用的优化动作。rl代理组件224可以将新的奖励和环境状态(例如,新的代码执行状态)作为输入,以更新优化策略。在一些实施例中,优化策略包括多个参数,可以更新这些参数以提高有效优化动作被推荐的概率且降低无效优化动作被推荐的概率。
44.图3示出根据本公开实施例的使用ai辅助编译器编译计算机程序的示例工作流。图3所示的工作流涉及要在执行环境300中编译和运行的源程序310。示例执行环境300可以包括java虚拟机(jvm)。
45.在一些实施例中,执行环境300可以包括ai辅助编译器,根据实施方式,ai辅助编译器可以包括图3所示的一个或多个组件。例如,ai辅助编译器可以指神经程序采样(neural program sampling)组件340和深度rl代理(deep rl agent)350的组合。作为另一个示例,ai辅助编译器可以进一步包括编译器320和/或运行时系统330。
46.在一些实施例中,源程序310可以首先由编译器320编译以生成汇编代码(一种中间代码的形式)和程序二进制(一种可执行代码的形式)。程序二进制可被发送到运行时系统330以执行。根据预定流程,可以从运行时系统330收集程序二进制的执行快照(一种轨迹的形式)。运行时系统330可以生成能从中学习到用于测量程序二进制的执行性能的信息。例如,可以从运行时系统330提取一些性能指标(例如,cpi和执行时间),以量化在运行时系统330运行的代码的性能。
47.在一些实施例中,来自编译器320的汇编代码和从运行时系统330收集的快照可以被馈送到用于运行时采样的神经程序采样组件340,以获得代码执行状态的向量化表示。这个向量化表示可以包括可用作深度rl代理350的输入的高维向量。在一些实施例中,神经程序采样组件340可以包括多个神经网络,例如,图神经网络(gnn)和序列模型神经网络。例如,gnn可以学习汇编代码的图表示中的节点依赖。可以通过各种翻译器或现有的用于从源代码构建图的方法生成图表示。基于依赖和快照,表示代码执行状态的一个或多个向量可以被生成并馈入序列模型神经网络来生成最终的嵌入向量,以表示代码执行状态。
48.在一些实施例中,代码执行状态的嵌入向量作为环境状态可以被输入深度rl代理350,且来自运行时系统330的性能指标可以被翻译为对深度rl代理350的奖励。在一些实施例中,可以由运行时系统330或深度rl代理350使用奖励函数计算奖励。基于状态和奖励,深
度rl代理350可以根据优化策略生成一个或多个推荐的优化动作。优化策略定义在给定时间深度rl代理350的行为方式,并包括从感知的环境状态到要采取(例如,推荐在编译器320中执行)的优化动作的映射。在一些实施例中,奖励可以指示先前推荐的优化动作在多大程度上改善了由编译器320生成的代码的质量。基于奖励,深度rl代理350可以调整其优化策略以增加有效优化动作用于当前源程序310的概率且减少无效优化动作用于当前源程序310的概率。
49.在一些实施例中,可以通过由编译器320暴露的一个或多个接口,在编译器320中执行推荐的优化动作。暴露的接口可以被概念化为可以切换的标志或被实现为可以用参数调用的api。在一些实施例中,编译器320的优化是迭代过程。例如,在通过执行推荐的优化动作更新编译器320后,可以由被更新的编译器重新编译源程序310,被更新的编译器将与运行时系统330、神经程序采样340和深度rl代理350一起工作,以进一步调整深度rl代理350的优化策略且推荐更多改善编译器320的性能的优化动作。在一些实施例中,每个迭代可以编译源程序310的部分。例如,如果源程序310可以生成多个.o文件(目标代码),则一个迭代可以编译第一.o文件组,且下一个迭代可以使用被更新的编译器来编译第二.o文件组。在一些实施例中,每个迭代可以编译整个源程序310。在一些实施例中,当满足退出条件时,可以终止迭代优化过程。示例退出条件包括编译代码满足目标质量或rl代理决定终止(例如,当强化学习收敛时,或当已执行一定数量的迭代时)。
50.图4示出根据本公开实施例的使用ai辅助编译器编译计算机程序的示例方法。图4中的示例方法涉及将用高级编程语言编写的源代码410编译成运行在运行时系统430的可执行代码的ai辅助编译器420。在一些实施例中,源代码410可以指可批量编译的一个或多个编程项目中的一个或多个文件。在一些实施例中,可以在每次编译期间完整地编译源代码410。在任一情况下,ai辅助编译器420可以采用强化学习且迭代地改善其生成的可执行代码的质量。
51.在一些实施例中,整个源代码410或源代码410的部分可以被发送到用于编译的ai辅助编译器420。ai辅助编译器420可以通过以下步骤生成中间代码423和可执行代码422:基于接收的源代码410生成中间代码423;获取中间代码423的树表示;以及通过优化树表示来生成可执行代码422。
52.在一些实施例中,可以在运行时系统430中执行可执行代码422。示例的运行时系统430包括物理计算设备、或虚拟机器或设备。在可执行代码422的执行期间,运行时系统430可以收集(具有代码执行状态相关的信息的)轨迹,可以从轨迹中提取一些执行性能指标。示例的执行性能指标包括执行时间、cpi、平均累积指令的未命中数等。在强化学习的上下文中,这些性能指标可以是计算奖励的基础。
53.在一些实施例中,运行时系统430可以将轨迹424a反馈给ai辅助编译器420。轨迹424a可以是ai编译器420中的rl代理计算与轨迹相对应的奖励的基础。在一些实施例中,rl代理可以指深度q学习神经网络(deep q-learning neural network,dqn)代理,q学习代理、或其他合适的代理。在一些实施例中,ai辅助编译器420可以基于中间代码423和轨迹424a执行嵌入操作,以生成代码执行状态的向量化表示。向量化表示可以是可被馈送到ai辅助编译器420的rl代理中的高维向量的形式。rl代理被配置为学习用于将优化动作425推荐给ai辅助编译器420的优化策略,以最大化累积奖励。
54.如上所述,ai辅助编译器420的优化是迭代过程。在第一迭代期间,可以由rl代理基于优化策略推荐一个或多个优化动作425。ai辅助编译器420可以执行一个或多个优化动作425,以便产生较高质量的可执行代码。“质量”的定义可以根据用例而变化。例如,一些用例可能期望较快的执行时间,而其他用例可能期望大小较小的执行代码。之后,被更新的ai辅助编译器420可以在下一个迭代执行编译。如果最近生成的中间代码423和最近获取的轨迹424a显示一些执行的优化动作提高了最近生成的可执行代码的质量,则ai辅助编译器420的rl代理可调整优化策略的参数以增加该优化动作或类似动作被推荐的概率。如果最近生成的中间代码423和最近获取的轨迹424a显示一些执行的优化动作未能提高最近生成的可执行代码的质量,则ai辅助编译器420的rl代理可调整优化策略的参数以降低该优化动作或类似动作被推荐的概率。在一些实施例中,当满足退出条件时,可以终止迭代优化过程。示例的退出条件包括可执行代码422(或另一种形式的编译代码)满足目标质量或rl代理决定终止(例如,当强化学习收敛时或当达到一定数量的迭代时)。
55.图5示出根据本公开实施例的ai辅助编译器的示例方法500。方法500可以在图1所示的环境中执行。方法500可以由图1至4所示的设备、装置或系统来执行,例如系统120。根据实施方式,方法500可以包括附加的、更少、或替代的以各种顺序或并行执行的步骤。
56.块510包括获取通过使用编译器编译计算机程序而生成的中间代码和可执行代码。在一些实施例中,编译器包括多个接口,且更新编译器包括:触发多个接口中的一个或多个接口以将一个或多个优化动作应用于编译器。在一些实施例中,获取中间代码和可执行代码包括:基于计算机程序生成中间代码;获取中间代码的树表示;以及通过优化树表示生成可执行代码。
57.块520包括基于通过在运行时系统执行可执行代码获取的一个或多个轨迹来确定奖励。在一些实施例中,运行时系统在以下至少一个目标中实现:具有操作系统的计算设备、虚拟机、云本地编译器即服务的平台、或反馈驱动的优化编译器框架。在一些实施例中,一个或多个轨迹中的每个轨迹包括一个或多个指标,一个或多个指标包括以下至少一个:平均指令执行周期数(cpi)、执行时间、或平均累积指令的未命中数。在一些实施例中,可以由运行时系统或云本地编译器即服务的平台执行奖励的确定。
58.块530包括基于中间代码和一个或多个轨迹生成嵌入向量,以表示代码执行状态。在一些实施例中,基于中间代码和一个或多个轨迹生成嵌入向量包括:生成中间代码的图表示;由图神经网络(gnn)基于图学习代码依赖;以及基于代码依赖和一个或多个轨迹生成嵌入向量,以表示代码执行状态。在一些实施例中,基于代码依赖和一个或多个轨迹生成嵌入向量包括:基于代码依赖和一个或多个轨迹生成一个或多个序列向量;将一个或多个序列向量输入到序列模型以生成嵌入向量。
59.块540包括使用强化学习代理,基于嵌入向量和奖励确定一个或多个优化动作。在一些实施例中,强化学习代理训练用于推荐优化动作的优化策略,且该方法还包括:从被更新的编译器获取新的可执行代码;通过在运行时系统运行新的可执行代码获取一个或多个新的轨迹和新的奖励;以及基于新的奖励和一个或多个优化动作训练优化策略。
60.块550包括通过应用一个或多个优化动作来更新编译器。
61.在一些实施例中,获取中间代码和可执行代码包括:在编译器编译计算机程序后,获取中间代码和可执行代码,且方法500还包括触发被更新的编译器重新编译计算机程序。
62.在一些实施例中,计算机程序包括多个部分,且获取中间代码和可执行代码包括通过由编译器编译计算机程序的第一部分获取中间代码和可执行代码,且方法500还包括用被更新的编译器编译计算机程序的第二部分。
63.图6示出根据本公开实施例的基于贝叶斯元强化学习(bayesian meta-reinforcement learning)用于任务控制的计算机设备600的框图。下面呈现的计算机系统600的组件旨在说明。根据实施方式,计算机系统600可以包括附加的、更少、或替代的组件。
64.计算机设备600可以是图2的ai辅助编译器220的示例实施方式。计算机设备600可以包括一个或多个处理器以及一个或多个非瞬时性计算机可读存储介质(例如,一个或多个存储器),一个或多个非瞬时性计算机可读存储介质耦合到一个或多个处理器且配置有可由一个或多个处理器执行的指令,使得系统或设备(例如,处理器)执行上述的实施例。计算机设备600可以包括与指令(例如,软件指令)相对应的各种单元/模块。
65.在一些实施例中,计算机设备600可被称为ai辅助编译器的设备。设备可以包括编译器模块620、轨迹获取模块640、嵌入模块660和rl模块680。在一些实施例中,编译器模块620可以被配置为获取通过使用编译器编译计算机程序而生成的中间代码和可执行代码。在一些实施例中,轨迹获取模块640可以被配置为收集通过在运行时系统中执行可执行代码而获取的一个或多个轨迹,且基于一个或多个轨迹确定奖励。在一些实施例中,嵌入模块660可被配置为基于中间代码和一个或多个轨迹生成嵌入向量,以表示代码执行状态。在一些实施例中,rl模块680可被配置为基于嵌入向量和奖励确定一个或多个优化动作,且通过应用一个或多个优化动作更新编译器。
66.图7示出计算设备的示例框图,在该计算设备中可以实现本文所述的任何实施例。计算设备可用于实现图1至图6所示的系统的一个或多个组件以及方法。计算设备700可以包括总线702或用于通信信息的其他通信机制、以及与总线702耦合的用于处理信息的一个或多个硬件处理器704。硬件处理器704可以例如是一个或多个通用微处理器。
67.计算设备700还可以包括主存储器707(例如随机存取存储器(ram))、高速缓存、和/或其他动态存储设备710,其耦合到总线702、用于存储要由处理器704执行的信息和指令。主存储器707还可用于在要由处理器704执行的指令的执行期间存储临时变量或其他中间信息。当这些指令存储在处理器704可访问的存储介质中时,其可以将计算设备700渲染(render)成一专用机器,该专用机器被定制以执行指令中指定的操作。主存储器707可以包括非易失性介质和/或易失性介质。非易失性介质可以包括,例如,光盘或磁盘。易失性介质可以包括动态存储器。介质的常见形式可以包括,例如,软盘、软磁盘、硬盘、固态驱动器、磁带、或任何其他磁性数据存储介质,cd-rom、任何其他光学数据存储介质、具有孔图案的任何物理介质、ram、dram、prom、和eprom、闪存-eprom、nvram、任何其他存储器芯片或盒,或同样的网络版本。
68.将可导致或编程计算设备700成为专用机器的定制硬连线逻辑、一个或多个asic或fpga、固件和/或程序逻辑与计算设备700结合,从而计算设备700可以执行本文所述的技术。根据一个实施例,这里的技术是由计算设备700响应于处理器704执行包括在主存储器707中的一个或多个指令的一个或多个序列而执行的。这些指令可以从诸如存储设备710的另一存储介质读入主存储器707。执行包括在主存储器707中的指令序列可以导致处理器704执行本文所述的处理步骤。例如,可以通过存储在主存储器707中的计算机程序指令来
执行本公开的处理/方法。当这些指令由处理器704执行时,它们可以执行如对应附图所示的和上述的步骤。在替代实施例中,硬连线电路可以代替软件指令或与软件指令结合使用。
69.计算设备700还包括耦合到总线702的通信接口717。通信接口717可以提供与连接到一个或多个网络的一个或多个网络链路耦合的双向数据通信。作为另一个示例,通信接口717可以是局域网(lan)卡,以提供与兼容lan(或与wan通信的wan组件)的数据通信连接。通信接口717也可以实现无线链路。
70.某些操作性能可以分布在处理器之间,其不仅驻留在单个机器中,而且部署在多个机器上。在一些示例的实施例中,处理器或处理器实现的引擎可以位于单个地理位置(例如,在家庭环境、办公室环境或服务器群中)。在其他示例的实施例中,处理器或处理器实现的引擎可以分布在多个地理位置。
71.在前面部分中描述的每个过程、方法和算法可以嵌入在由一个或多个计算机系统或包括计算机硬件的计算机处理器执行的代码模块中且全部地或部分地由该代码模块自动化执行。过程和算法还可以部分地或全部地在专用应用电路中执行。
72.当本公开的功能以软件功能模块的形式实现且作为独立的产品出售或使用时,它们可以是存储在处理器中可执行的非易失性计算机可读存储介质。本文公开的(整体的或部分的)特定技术方案或对当前技术有贡献的方面可以以软件产品的形式嵌入。软件产品可以存储在存储介质中,存储介质包括使计算设备(其可以是个人计算机、服务器、网络设备等)执行本公开实施例的方法的全部或一些步骤的多个指令。存储介质可以包括闪存驱动器、便携式硬盘驱动器、rom、ram、磁盘、光盘、可操作来存储程序代码的其他介质、或其任何组合。
73.特定实施例还提供了一种系统,系统包括处理器和非瞬时性计算机可读存储介质,非瞬时性计算机可读存储介质存储可由处理器执行的指令,以使系统执行上述公开的实施例的任何方法的步骤相对应的操作。特定实施例还提供了一种非瞬时性计算机可读存储介质,其中配置有可由一个或多个处理器执行的指令,以使一个或多个处理器执行上述公开的实施例的任何方法的步骤相对应的操作。
74.本文公开的实施例可以通过与客户机交互的云平台、服务器或服务器组(以下统称为“服务系统”)实现。客户机可以是终端设备、或由用户在平台上注册的客户端,其中终端设备可以是移动终端、个人计算机(pc)和可以安装平台应用程序的任何设备。
75.上面描述的各种特征和过程可以互相独立地使用或可以以各种方式组合。所有可能的组合和子组合旨在落入本公开的范围内。此外,在一些实施例中,可以省略某些方法或过程块。本文所述的方法和过程也不限于任何特定的顺序,并且与之相关的块或状态可以以其他适当的顺序执行。例如,所述的块或状态可以以具体公开的顺序以外的顺序执行,或者多个块或状态可以组合成单个的块或状态。示例块或状态可以串行、并行、或以其他方式执行。块或状态可以添加到本公开的示例实施例或从本公开的示例实施例移除。本文所述的示例系统和组件可以配置得与所描述的不同。例如,与所公开的示例性实施例相比,可以添加、移除、或重新排列元件。
76.可以通过算法至少部分地执行本文所述的示例方法的各种操作。算法可以包括在存储在存储器(例如,上述非瞬时性计算机可读存储介质)的程序代码或指令中。这种算法可以包括机器学习算法。在一些实施例中,机器学习算法不可以明确地编程计算机以执行
功能,但其可以从训练数据学习以建立执行该功能的预测模型。
77.本文所述的示例方法的各种操作可由临时配置(例如,通过软件)或永久配置为执行相关操作的一个或多个处理器至少部分地执行。无论是临时配置还是永久配置,这些处理器都可以构成运行以执行本文所述的一个或多个操作或功能的处理器实现的引擎。
78.类似地,本文所述的方法可以至少部分地由处理器实现,以一个或多个特定处理器作为示例硬件。例如,方法的至少一些操作可以由一个或多个处理器或处理器实现的引擎执行。此外,一个或多个处理器还可以操作以支持在“云计算”环境中或作为“软件即服务(software as a service)”(saas)的相关操作的性能。例如,至少一些操作可以由计算机组(包括处理器的示例机器)执行,这些操作可通过网络(例如,互联网)和通过一个或多个适当的接口(例如,应用程序接口(api))访问。
79.某些操作的性能可以分布在处理器之间,其不仅驻留在单个机器内,而且部署在多个机器上。在一些示例实施例中,处理器或处理器实现的引擎可以位于单个地理位置(例如,在家庭环境、办公环境、或服务器群内)。在其他示例实施例中,处理器或处理器实现的引擎可以分布在多个地理位置。
80.在本说明书中,多个示例可以实现描述为单个示例的组件、操作、或结构。尽管一个或多个方法的独立操作被示出并描述为分开的操作,但一个或多个独立操作可以同时执行,并且不需要按照图示顺序执行操作。在示例配置中,呈现为分开的组件的结构和功能可以实现为组合结构或组件。类似地,呈现为单个组件的结构和功能可以实现为分开的组件。这些和其他变化、修改、添加和改进均落入本主题的范围。
81.尽管已参考具体示例性的实施例描述了本主题的概述,但可以对这些实施例进行各种修改和改变,而不脱离本公开实施例的更广泛范围。本文仅为方便,可通过术语“公开”单独或集体地提及本主题的这些实施例,而不打算自愿将本公开的范围限制为任何单个公开或概念(如果事实上公开了超过一个公开或概念)。
82.本文所示的实施例被足够详细地描述以使那些本领域技术人员能够实践本公开的教义。可以使用和导出其他实施例,由此,使得可以进行结构和逻辑的替换和改变,而不脱离本公开的范围。因此,不以限制性意义来进行详细描述,并且各种实施例的范围仅由所附权利要求以及这些权利要求有权获得的全部等同物来定义。
83.本文所述和/或附图中描述的流程图中的任何过程描述、元件或块应理解为潜在地表示模块、段或代码部分,其包括用于实现过程中的特定逻辑功能或步骤的一个或多个可执行指令。替代实施方式包括在本文所述实施例的范围内,其中,如本领域技术人员所理解的,根据所涉及的功能,可以从所示或所讨论的实施例中删除、无序(包括基本上并发地或反向地顺序)执行元素或功能。
84.除非另有明确说明或上下文另有说明,否则正如本文中使用的“或”是包容性的,而非排他性的。因此,本文中“a、b或c”指“a、b、a和b、a和c、b和c、或a、b和c”,除非另有明确说明或上下文另有说明。此外,“和”是连带的,除非另有明确说明或上下文另有说明。因此,本文中“a和b”指“a和b,共同地或各自地”,除非另有明确说明或上下文另有说明。此外,可以为本文描述为单个事例的资源、操作或结构提供多个事例。此外,各种资源、操作、引擎和数据存储之间的边界在某种程度上是任意的,且在具体说明性配置的上下文中示出特定操作。设想了功能的其他分配,并且其可以落入本公开的各种实施例的范围。通常,在示例配
置中作为单独资源呈现的结构和功能可以实现为组合结构或资源。类似地,作为单个资源呈现的结构和功能可以实现为分开的资源。这些和其他变化、修改、添加和改进均落入由所附权利要求表示的本公开实施例的范围。因此,说明书和附图应被视为是说明性而不是限制性意义。
85.术语“包括”或“包含”用于表明存在随后声明的特征,但不排除添加其他特征。条件语言,例如,除其他外,“可能”或“可以”,除非另有明确说明,或在所使用的上下文中以其他方式理解,一般旨在传达某些实施例包括某些特征、元素和/或步骤,而其他实施例不包括。因此,这样的条件语言通常并不旨在表明一个或多个实施例以任何方式需要特征、元素和/或步骤,或者一个或多个实施例必须包括用于在有或没有用户输入或提示的情况下确定在任何特定实施例中是否包括或执行这些特征、元素和/或步骤的逻辑。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1