一种自适应接口FPGA软硬件协同仿真加速系统的制作方法
一种自适应接口fpga软硬件协同仿真加速系统
技术领域
1.本发明涉及fpga仿真测试技术领域,特别是一种自适应接口fpga软硬件协同仿真加速系统。
背景技术:
2.fpga(field-programmable gate array,可编程门阵列)仿真验证是fpga设计测试的必要步骤,是保障fpga设计质量的有效手段之一。在可编程逻辑器件设计中,对电路进行功能仿真时,现有的传统方法都是纯软件仿真,例如ies、modelsim、questasim、nc_sim、active-hdl等软件,都是在计算机或服务器上进行软件仿真。随着系统设计的复杂性不断增加,可编程逻辑门阵列(fpga)器件使用的规模和设计复杂度增长迅猛,特别是针对大规模fpga逻辑设计时,仿真运行时间长、效率低,尤其是在设计后期,需要进行回归测试时,电路规模庞大,仿真场景众多,用传统的软件仿真时会耗费数个小时、数天甚至数周的时间,从而导致测试周期大大延长,研发成本也相应剧增,最终降低了产品的市场竞争力。因此,需要发明一种针对fpga设计的仿真验证的加速手段来满足实际应用需求。
3.目前,常用的fpga软硬件协同仿真系统主要包括设置于用户pc端中的软件系统部分和对fpga进行模拟的硬件系统部分。在fpga仿真测试过程中,软件系统部分用于生成测试激励信号以及处理部分被测fpga设计,硬件系统部分用于对其他部分被测fpga设计进行测试得到测试数据。目前公开发表的fpga软硬件协同仿真系统通信接口单一,且被测设计的加载均需采用下载线手动加载,并且在对fpga进行仿真时是针对部分被测fpga设计工程的仿真加速,而不能对整体的被测fpga设计工程进行加速测试,导致仿真测试的效率较低且系统适应性不强。
技术实现要素:
4.本发明解决的技术问题是:克服现有技术的不足,提供了一种自适应接口fpga软硬件协同仿真加速系统。
5.为了解决上述技术问题,本发明实施例提供的一种自适应接口fpga软硬件协同仿真加速系统,所述系统包括:上位机和硬件板卡端,所述上位机包括:仿真软件单元和通信单元,所述硬件板卡端包括:主fpga单元和从fpga单元,其中,
6.所述仿真软件单元,被配置为产生被测设计仿真的激励数据通过dma写函数向所述主fpga单元写入激励数据,并通过dma读函数回读仿真测试数据,在运行仿真之前控制被测设计的配置流bit文件通过所述通信单元和所述主fpga单元加载至所述从fpga单元,同时控制仿真软件进行波形显示;
7.所述通信单元,被配置为仿真激励数据、仿真测试数据以及被测设计配置数据的传输通信;
8.所述主fpga单元,被配置为接收所述激励数据,经缓存后,通过通信接口发送至所述从fpga单元,并通过所述通信接口接收来自所述从fpga单元的被测fpga设计仿真结果,
经缓存后,通过通信接口发送至所述通信单元,并在仿真开始前接收来自通信模块的从fpga配置文件完成对从fpga单元的配置加载;
9.所述从fpga单元,被配置为缓存所述激励数据,根据所述激励数据对被测设计进行仿真测试,得到测试数据,并将所述测试数据发送至所述主fpga单元。
10.可选地,所述仿真软件单元包括:软件仿真环境、软件接口模块和自动加载控制模块,其中,
11.所述软件仿真环境,被配置为对仿真软件进行仿真控制,按照预设bit位序产生被测设计仿真的激励数据和回读仿真测试数据,并在所述仿真软件的软件界面上进行实时显示激励数据波形和仿真测试数据波形;
12.所述软件接口模块,被配置为采用c语言编程,完成设定子函数的封装以及功能调度程序,并通过预设接口与所述软件仿真环境进行数据接口交互;
13.所述自动加载控制模块,被配置为在运行仿真之前,控制被测设计的配置流bit文件通过所述通信单元和所述主fpga单元加载至所述从fpga,以进行被测设计的自动加载。
14.可选地,所述通信单元包括:pcie通信模块和usb通信模块,其中,
15.所述pcie通信模块,被配置为将所述激励数据通过pcie发送至硬件板卡端,并从所述硬件板卡端读取仿真测试数据通过pcie传送至所述仿真软件单元;
16.所述usb通信模块,被配置为将所述激励数据通过usb发送至硬件板卡端,并从所述硬件板卡端读取仿真测试数据通过usb传送至所述仿真软件单元。
17.可选地,所述pcie通信模块包括:pcie驱动程序接口和pcie插槽接口,其中,
18.所述pcie驱动程序接口以库函数的方式通过c语言接口调用,使上位机程序能够通过pcie总线与主fpga单元进行通讯;
19.所述仿真软件单元生成的激励数据经过pcie应用程序对应的驱动程序函数接口发送至所述pcie插槽接口,并从所述pcie插槽接口获取仿真测试数据;
20.所述pcie插槽接口为pc主板自带的x16的金手指插槽,以将激励数据发送给硬件板卡端,并从所述硬件板卡端读取仿真测试数据并传送至所述仿真软件单元程序。
21.可选地,所述usb通信模块包括:usb3.0控制器fx3以及usb3.0数据线,
22.所述仿真软件单元通过所述usb3.0数据线与所述主fpga单元通信连接,通过所述usb3.0控制器fx3芯片与所述主fpga单元进行高速数据通信。
23.可选地,所述主fpga单元包括:xdma通信/gpif ii通信逻辑模块、ddr3缓存逻辑模块、ddr3读写仲裁逻辑模块、gtx通信逻辑模块和从fpga配置逻辑模块。
24.可选地,所述从fpga单元包括:被测设计dut逻辑模块、dut控制逻辑模块和gtx通信逻辑模块,其中,
25.所述被测设计dut逻辑模块,被配置为装载被测设计,将需要仿真加速的被测设计工程整体加载到从fpga单元逻辑框架中,在仿真开始前,仿真软件单元首先将从fpga单元设计的配置流文件通过通信单元送入主fpga单元中,对从fpga单元进行自动配置,随后即可进行被测设计的硬件仿真测试;
26.所述dut控制逻辑模块,被配置为控制被测设计仿真时钟树的工作状态和控制被测设计接口数据的读写;缓存激励数据,并输出激励数据至被测fpga设计;缓存被测fpga设计输出的测试数据,并将测试数据通过gtx通信模块发送给主fpga单元;
27.所述gtx通信逻辑模块,被配置为根据协议形成实现链路层功能,并以axi4_stream协议接口与发送端和接收端实现用户数据交互。
28.本发明与现有技术相比具有以下有益效果:
29.1、本发明通过软硬件联合的方式完成被测fpga设计的测试验证,将传统的在软件平台实现的仿真测试移植到软硬件结合的平台上,将被测fpga设计加载到硬件fpga芯片运行,充分利用了fpga硬件加速的优势,降低了仿真环境的运行负担,提高了fpga仿真的速度;
30.2、本发明将被测设计的配置流bit文件通过仿真软件单元发送给主fpga缓存,实现对从fpga完成自动加载配置,此种设计无需手动配置,降低了该平台使用的复杂度,提高了平台应用的灵活性,针对不同的被测设计,替换配置流bit文件即可,提高了工作效率;
31.3、本发明采用了pcie和usb双通信模式,用户可根据测试硬件条件选择其中任意一种通信模式,仿真软件单元即可通过用户的选择进行通信模式的自动适配,使该平台具有更强的适应性,满足用户的不同测试需求。
附图说明
32.图1为本发明实施例提供的一种自适应接口fpga软硬件协同仿真加速系统的结构示意图;
33.图2为本发明实施例提供的一种主fpga单元的逻辑架构图;
34.图3为本发明实施例提供的一种pcie xdma通信模块的逻辑架构图;
35.图4为本发明实施例提供的一种usb3.0通信模块的逻辑架构图;
36.图5为本发明实施例提供的一种ddr3缓存控制的逻辑架构图;
37.图6为本发明实施例提供的一种从fpga自动配置的逻辑框图;
38.图7为本发明实施例提供的一种从fpga自动配置流程的示意图;
39.图8为本发明实施例提供的一种从fpga单元的逻辑架构图。
具体实施方式
40.实施例一
41.参照图1,示出了本发明实施例提供的一种自适应接口fpga软硬件协同仿真加速系统的结构示意图,如图1所示,该系统可以包括:上位机和硬件板卡端,所述上位机包括:仿真软件单元101和通信单元102,所述硬件板卡端包括:主fpga单元103和从fpga单元104,其中,
42.仿真软件单元可以被配置为产生被测设计仿真的激励数据通过dma写函数向所述主fpga单元写入激励数据,并通过dma读函数回读仿真测试数据,在运行仿真之前控制被测设计的配置流bit文件通过所述通信单元和所述主fpga单元加载至所述从fpga单元,同时控制仿真软件进行波形显示;
43.通信单元可以被配置为仿真激励数据、仿真测试数据以及被测设计配置数据的传输通信;
44.主fpga单元可以被配置为接收所述激励数据,经缓存后,通过通信接口发送至所述从fpga单元,并通过所述通信接口接收来自所述从fpga单元的被测fpga设计仿真结果,
经缓存后,通过通信接口发送至所述通信单元,并在仿真开始前接收来自通信模块的从fpga配置文件完成从fpga单元的配置加载;
45.从fpga单元可以被配置为缓存所述激励数据,根据所述激励数据对被测设计进行仿真测试,得到测试数据,并将所述测试数据发送至所述主fpga单元。
46.在本发明实施例中,pc端包括仿真软件单元和通信单元,硬件板卡端包括主fpga单元和从fpga单元,平台可通过软件和硬件联合的仿真方式提高fpga设计的仿真验证效率,具有高速运算、易于维护、易于操作、适应性强等优点。
47.pc端的仿真软件单元运行于windows操作系统,按照预设的仿真时钟频率,循环产生预设时间片段内被测设计的并行激励数据,通过通信单元快速高效的传送至硬件板卡端的主fpga单元,完成待测大量激励数据的缓存功能,然后再把激励数据经过高速串行接口gtx发送至从fpga单元,完成被测设计的仿真验证,并把产生的中间仿真测试数据按照相应的位序转换为被测fpga设计仿真结果,通过高速串行接口gtx回传到主fpga单元进行数据缓存,本次时间片段仿真结束后,主fpga单元产生中断通知仿真软件单元,然后pc端的仿真软件单元再通过通信单元读取主fpga缓存的测试结果,并在仿真软件界面上进行显示,同时仿真软件单元可以启动下一个仿真时间片段的被测设计功能仿真验证。
48.在本发明的另一种具体实现方式中,所述仿真软件单元包括:软件仿真环境、软件接口模块和自动加载控制模块,其中,
49.所述软件仿真环境,被配置为对仿真软件进行仿真控制,按照预设bit位序产生被测设计仿真的激励数据和回读仿真测试数据,并在所述仿真软件的软件界面上进行实时显示激励数据波形和仿真测试数据波形;
50.所述软件接口模块,被配置为采用c语言编程,完成设定子函数的封装以及功能调度程序,并通过预设接口与所述软件仿真环境进行数据接口交互;
51.所述自动加载控制模块,被配置为在运行仿真之前,控制被测设计的配置流bit文件通过所述通信单元和所述主fpga单元加载至所述从fpga单元,以进行被测设计的自动加载。
52.在本发明的另一种具体实现方式中,所述通信单元包括:pcie通信模块和usb通信模块,其中,
53.所述pcie通信模块,被配置为将所述激励数据通过pcie发送至硬件板卡端,并从所述硬件板卡端读取仿真测试数据通过pcie传送至所述仿真软件单元;
54.所述usb通信模块,被配置为将所述激励数据通过usb发送至硬件板卡端,并从所述硬件板卡端读取仿真测试数据通过usb传送至所述仿真软件单元。
55.在本发明的另一种具体实现方式中,所述pcie通信模块包括:pcie驱动程序接口和pcie插槽接口,其中,
56.所述pcie驱动程序接口以库函数的方式通过c语言接口调用,使上位机程序能够通过pcie总线与主fpga单元进行通讯;
57.所述仿真软件单元生成的激励数据经过pcie应用程序对应的驱动程序函数接口发送至所述pcie插槽接口,并从所述pcie插槽接口获取仿真测试数据;
58.所述pcie插槽接口为pc主板自带的x16的金手指插槽,以将激励数据发送给硬件板卡端,并从所述硬件板卡端读取仿真测试数据并传送至所述仿真软件单元程序。
59.在本发明的另一种具体实现方式中,所述usb通信模块包括:usb3.0控制器fx3以及usb3.0数据线。
60.所述仿真软件单元通过所述usb3.0数据线与所述主fpga通信连接,通过所述usb3.0控制器fx3芯片与所述主fpga进行高速数据通信。
61.在本发明的另一种具体实现方式中,所述主fpga单元包括:xdma通信/gpif ii通信逻辑模块、ddr3缓存逻辑模块、ddr3读写仲裁逻辑模块、gtx通信逻辑模块和从fpga配置逻辑模块。
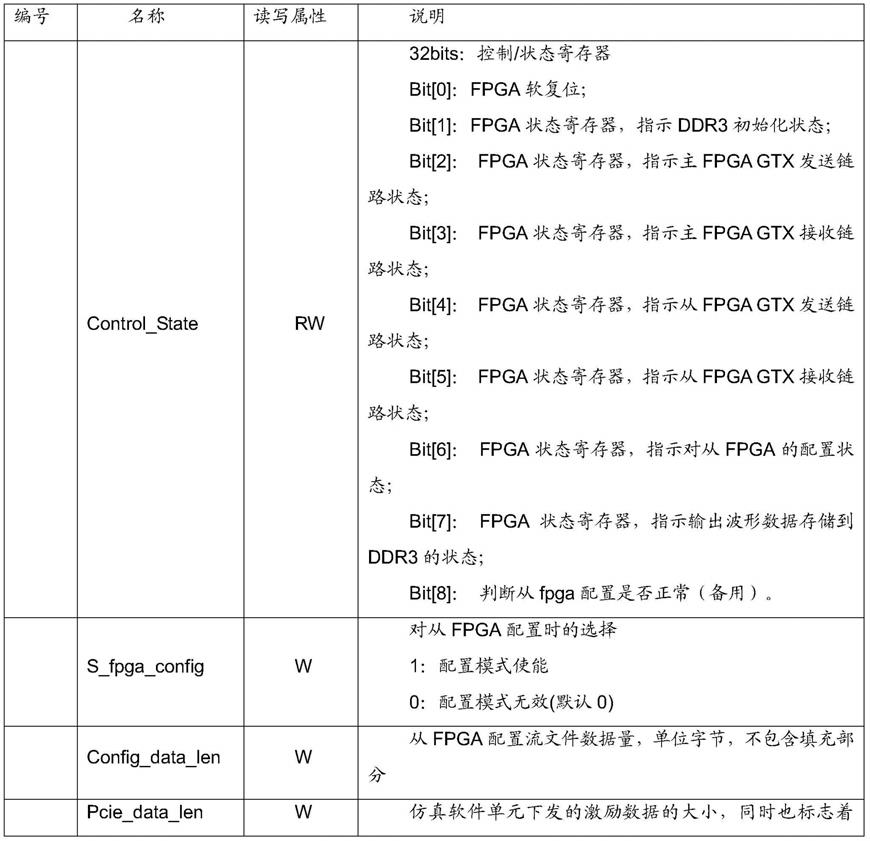
62.在本发明的另一种具体实现方式中,所述从fpga单元包括:被测设计dut逻辑模块、dut控制逻辑模块和gtx通信逻辑模块,其中,
63.所述被测设计dut逻辑模块,被配置为装载被测设计,将需要仿真加速的被测设计工程整体加载到从fpga单元逻辑框架中,在仿真开始前,仿真软件单元首先将从fpga单元设计的配置流文件通过通信单元送入主fpga单元中,对从fpga单元进行自动配置,随后即可进行被测设计的硬件仿真测试;
64.所述dut控制逻辑模块,被配置为控制被测设计仿真时钟树的工作状态和控制被测设计接口数据的读写;缓存激励数据,并输出激励数据至被测fpga设计;缓存被测fpga设计输出的测试数据,并将测试数据通过gtx通信模块发送给主fpga单元;
65.所述gtx通信逻辑模块,被配置为根据协议形成实现链路层功能,并以axi4_stream协议接口与发送端和接收端实现用户数据交互。
66.在本发明实施例中,对于仿真软件单元、通信单元、主fpga单元和从fpga单元进行如下详细描述。
67.第一、仿真软件单元
68.软件仿真单元包含软件仿真环境、软件接口模块和自动加载控制模块,其中软件仿真环境可以完成对仿真软件的仿真控制,采用system verilog编程,按照相应的bit位序产生被测设计仿真的激励数据和回读仿真测试数据,并在仿真软件界面上进行实时显示激励数据波形和仿真测试数据波形;软件接口模块采用c语言编程,完成pcie xdma通道或者usb gpif ii通道的dma读、dma写、寄存器读、寄存器写等子函数的封装以及功能调度等程序,可以通过system verilog的dpi接口实现与仿真软件环境进行数据接口交互;自动加载控制模块能够在运行仿真之前,控制被测设计的配置流bit文件通过通信单元和主fpga单元加载到从fpga中,从而实现被测设计的自动加载。
69.仿真软件单元通过dma写函数向主fpga单元写入激励数据,pcie通信模式最小单位为4kb,usb通信模式最小单位为1kb,执行一次仿真加速,最大处理激励数据包为256mb,仿真软件单元每次启动dma读写最大不超过1mb。如果激励数据包大于256mb,则分多次执行仿真加速处理,如果最终数据不足4kb(1kb),需要补零填充。
70.下表给出了仿真软件单元与主fpga交互时的相关寄存器配置定义,仿真软件单元以查询的方式判断相关寄存器,从而实现对从fpga的自动配置、usb或pcie通信模式的选择以及对加速板卡相应的读写控制。
71.表1、fpga与仿真软件单元交互寄存器列表
[0072][0073][0074]
usb/pcie通信模式自适应实现
[0075]
仿真软件单元的软件接口模块默认的通信模式为pcie通信,此时usb_work寄存器配置为0。当用户选用pcie通信时,仿真软件单元无需进行usb_work寄存器的配置;当用户选用usb3.0通信时,仿真软件单元首先需要将主fpga单元用户逻辑寄存器模块的usb_work寄存器配置为1,当退出usb3.0通信时,需要将usb_work寄存器配置为0,恢复成默认模式。
[0076]
从fpga自动配置加载实现
[0077]
仿真软件单元的应用函数分别实现从fpga的配置和被测设计的硬件仿真,两者相
互独立,各自执行main函数文件。
[0078]
提取被测设计文件并加载到从fpga中,综合编译得到bit文件,仿真软件单元通过dma写的方式写入主fpga,并存储于ddr3中,然后主fpga通过slave selectmap方式对从fpga进行配置。
[0079]
在仿真开始之前,仿真软件单元的自动加载控制模块首先自动读取从fpga的配置bit文件,将从fpga配置使能信号s_fpga_config置1,通知主fpga进行从fpga配置准备,并告知主fpga配置文件的数据量config_data_len,待主fpga成功完成从fpga的配置后,向自动加载控制模块发送fpga状态寄存器告知其从fpga的配置状态,1为配置成功,0为配置失败。
[0080]
第二、通信单元
[0081]
为了增加该仿真加速平台的灵活易用性,仿真软件单元与fpga通信方式有两种,一种是pcie通信,另一种是usb3.0通信,usb3.0高速数据通信的功能与pcie xdma通信功能相似,在windows系统场景下,用户可以根据实际测试需求选择使用pcie xdma或usb3.0 gpif ii的通信方式与硬件板卡主fpga进行通信。
[0082]
通信单元包括pcie通信模块和usb通信模块。
[0083]
pcie通信模块包含windows系统下的pcie驱动程序接口和pcie插槽接口。windows系统下的pcie驱动程序接口以库函数的方式通过c语言接口调用,使上位机程序能够通过pcie总线与硬件fpga板卡进行通讯。仿真软件单元生成的激励数据经过pcie应用程序对应的驱动程序函数接口发送至pcie插槽接口,同时也可以从pcie插槽接口获取仿真测试数据;pcie插槽接口是pc主板自带的x16的金手指插槽,可以将激励数据发送给硬件板卡端;同时也可以从硬件板卡端读取仿真测试数据并传送至仿真软件单元程序。
[0084]
usb通信模块主要包括usb3.0控制器fx3以及usb3.0数据线,仿真软件单元通过usb3.0控制器fx3芯片完成与主fpga的高速数据通信。本平台使用的固件代码采用cypress官方提供的sf_loopback.img,可以实现激励数据和仿真测试数据的双工通信。usb3.0和pcie采用同一套寄存器地址列表,详见表1。由于usb通信协议只是数据的串行传输,并无特定的通信协议,本发明设计了读写通信协议,具体见表2~表6。
[0085]
仿真软件单元下发写指令长度为1kb的数据,最终由主fpga提取寄存器的写配置信息,包括寄存器地址和配置数据。
[0086]
表2、寄存器写指令
[0087]
head(4byte)r/w(4byte)addr(4byte)data(4byte)填充数据(1020byte)帧头1:写指令寄存器地址寄存器配置数据0
[0088]
仿真软件单元下发的寄存器读指令长度为1kb的数据,最终由主fpga提取寄存器的配置信息,仅仅包括寄存器地址。该指令完成后,仿真软件单元需要启动dma读指令,完成1kb的数据获取。
[0089]
表3、寄存器读指令
[0090]
head(4byte)r/w(4byte)addr(4byte)data(4byte)填充数据(1020byte)帧头2:读指令寄存器地址0(忽略)0
[0091]
仿真软件单元下发寄存器读指令后,再启动dma读指令,完成1kb的数据获取。仿真软件单元最终读取的实际有效的寄存器值为1kb数据帧的前4个字节,填充数据为无效值。
[0092]
表4、dma读:(获取寄存器值)
[0093]
data(4byte)填充数据(1023byte)读取的寄存器值0
[0094]
由于单次dma写的长度为1kb,因此仿真软件单元下发的激励数据的量为1kb的倍数。
[0095]
表5、单次dma写:(激励数据)
[0096]
激励数据(1024byte)data
[0097]
仿真软件单元单次dma读的长度为1kb,最终的仿真数据量是激励数据量的两倍。
[0098]
表6、单次dma读:(仿真结果数据)
[0099]
仿真数据(1024byte)data
[0100]
本发明的硬件板卡端包含两个fpga,主fpga单元和从fpga单元,主fpga单元上电工作时需要读取外部已经固化在flash芯片中的程序,加载配置流;从fpga单元外部不连接flash,因此开始仿真之前,仿真软件单元通过pcie或者usb dma写的方式写入主fpga,然后主fpga通过slave selectmap方式对从fpga进行配置完成从fpga配置流的自动加载。具体介绍如下:
[0101]
第三、主fpga单元
[0102]
主fpga单元逻辑功能主要包括xdma通信/gpif ii通信、ddr3数据缓存、ddr3读写仲裁、高速串行gtx通信和从fpga配置逻辑,其逻辑架构如图2所示,各逻辑模块间采用fifo进行数据缓存。主fpga单元接收来自xdma通信/gpif ii通信模块的激励数据,经ddr3缓存后,通过gtx通信接口发送至从fpga单元;同时,通过gtx通信接口接收来自从fpga单元的被测fpga设计仿真结果,经ddr3缓存后,通过pcie xdma/usb3.0通信接口发送至通信单元。各逻辑模块功能详细说明如下:
[0103]
xdma通信/gpif ii通信逻辑模块:两种通信模式逻辑的选择是根据仿真软件单元发送的usb_work寄存器配置情况确定的,usb_work寄存器配置为1时选择gpif ii通信逻辑,为0时选择xdma通信逻辑,默认为xdma通信模式。
[0104]
xdma通信逻辑:xdma是xilinx封装好的pcie dma传输ip,可以很方便的把pcie总线上的数据传输事务映射到axi总线上面,实现上位机直接对axi总线进行读写,并且自动对pcie本身tlp的组包和解包。如图3所示,该模块主要实现仿真软件单元与主fpga的高速串行互联,包括仿真软件单元对主fpga逻辑的寄存器读/写控制、h2c写通道控制和c2h读通道控制,仿真软件单元通过通信单元与主fpga的xdma ip进行激励数据和测试数据的交互。仿真软件单元每次启动dma读、写操作的数据量最大不超过1mb,如果超过1mb,则分多次读写操作。
[0105]
gpif ii通信逻辑:如图4所示,gpif ii时序采用了streamin和streamout传输两种模式,单次数据流大小为1kb,该逻辑包括指令数据解析及功能控制模块、dma读写模块和寄存器读写控制模块。其中,指令数据解析及功能控制模块对仿真软件单元下发的指令进行解析,指令包括寄存器写、寄存器读、dma写和dma读,主fpga对接收到的相应的指令完成
相应的操作。仿真软件单元通过usb3.0 dma写通道下发激励数据到主fpga,单包数据流大小为1kb,先将激励数据进行缓存后传送到ddr3,完成大量数据缓存。仿真软件单元通过dma读通道读取fpga寄存器值或者读取仿真数据时,可以通过读取缓存的形式将单位为1kb的数据流进行上传,根据仿真软件单元下发的寄存器读指令或dma读指令来选择寄存器或仿真数据的读取。
[0106]
ddr3缓存逻辑模块:将来自xdma通信/gpif ii通信模块的激励数据存储在ddr3指定的空间,当存入的数据量达到指定的数据量时,通过gtx通信模块将激励数据写入被测设计及控制模块;同理,通过gtx通信模块接收来自被测设计及控制模块的测试数据,存入ddr3指定的空间,当存入的数据量达到指定的数据量时,通知仿真软件单元进行pcie或者gpif ii dma读操作,将所有存储的测试数据送入通信单元。
[0107]
本发明中ddr3存储空间为1gb,主要用于存储激励数据、测试结果数据和从fpga配置流文件数据,为了防止数据存储混乱,因此对ddr3的空间主要进行了3部分的空间划分。
[0108]
表7、ddr3空间划分
[0109][0110]
ddr3读写仲裁逻辑模块:如图5所示,对ddr3芯片进行读写操作时,读时序与写时序不能同时进行,因为读写共用一套数据总线。为了防止读写冲突,ddr3的读写优先级采用写优先模式。pcie用户工作时钟为125mhz,ddr3用户时钟为100mhz,仿真软件单元下发的激励数据包缓存在异步wfifo中,ddr3的控制逻辑实时判断该wfifo存入的数据量是否达到了4kb,如果满足要求则启动一次ddr3写操作,读取wfifo中的4kb数据量存于ddr3中,同时如果写操作不忙的时候,读取4kb的数据量存入rfifo中。
[0111]
gtx通信逻辑模块:xilinx提供的aurora协议的ip核主要是基于gtx传输器作为物理层,根据协议形成实现链路层功能,并以axi4_stream协议接口与发送端和接收端实现用户数据交互。本发明通过xilinx提供的aurora64b/66b ip来实现高速光纤通信,通道速率达到10.3125gb/s,完成全双工作模式。
[0112]
从fpga配置逻辑模块:该模块通过pcie完成仿真软件单元对从fpga的逻辑配置,仿真软件单元把配置流文件通过pcie存储在主fpga的ddr3中,然后由主fpga完成对从fpga的配置,配置时钟为5mhz。如图6所示,该模块主要包括配置状态检测和数据缓存功能。通过配置接口与从fpga连接,当主fpga接收到仿真软件单元发送的从fpga配置指令时,通过与从fpga配置信号的接口发送program_b信号,等待从fpga初始化完成,将缓存的从fpga配置bit流发送给从fpga完成对从fpga的配置;通过状态接口与从fpga连接,负责从fpga配置整个过程的控制,完成从fpga配置程序的写入;将存储在ddr3的配置文件读出进行缓存,由于ddr3读写的数据位宽为256bits,而对从fpga配置的slave selectmap16模式数据位宽为16bits,因此为了两者数据位宽的匹配,需要把256bits的数据转换为16bits的数据。
[0113]
图7为从fpga的配置流程,具体为:
[0114]
1、等待仿真软件单元配置使能信号,若配置使能信号为高,则向从fpga发送program_b置低信号,并继续执行a);
[0115]
2、等待从fpga初始化完成,若返回init_b置低信号,则继续执行c),若init_b信号不拉低,输出错误状态给仿真软件单元;
[0116]
3、启动读取ddr3内缓存的从fpga配置数据,经缓存后通过配置数据线依次发送给从fpga;
[0117]
4、配置数据发送完成后,检测从fpga返回的done信号是否变高,变高,代表配置操作成功,新数据生效;若为低电平,代表配置操作失败,输出错误状态给仿真软件单元。
[0118]
5、用户逻辑寄存器模块:该模块主要实现仿真软件单元与主fpga交互时的相关寄存器配置,仿真软件单元以查询的方式判断相关寄存器,从而实现对加速板卡相应的读写控制。
[0119]
第四、从fpga单元
[0120]
从fpga单元逻辑功能主要包括被测设计dut、dut控制逻辑、高速串行gtx通信,其逻辑架构如图8所示。各逻辑模块功能详细说明如下:
[0121]
被测设计dut逻辑模块:用于装载被测设计,将需要仿真加速的被测设计工程整体加载到从fpga单元逻辑框架中,进行综合布局布线生成bit文件后,在仿真开始前,仿真软件单元首先将从fpga设计的配置流文件通过通信单元送入主fpga中,对从fpga进行自动配置,随后即可进行被测设计的硬件仿真测试。
[0122]
dut控制逻辑模块:该模块完成从fpga的工作调度,主要控制被测设计仿真时钟树的工作状态和控制被测设计接口数据的读写等。缓存激励数据,并输出激励数据至被测fpga设计;缓存被测fpga设计输出的测试数据,并将测试数据通过gtx通信模块发送给主fpga单元,进而传递到仿真软件单元进行波形显示。
[0123]
gtx通信逻辑模块:与主fpga单元gtx通信模块功能一致。
[0124]
本技术所述具体实施方式可以使本领域的技术人员更全面地理解本技术,但不以任何方式限制本技术。因此,本领域技术人员应当理解,仍然对本技术进行修改或者等同替换;而一切不脱离本技术的精神和技术实质的技术方案及其改进,均应涵盖在本技术专利的保护范围中。
[0125]
本发明说明书中未作详细描述的内容属本领域技术人员的公知技术。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1