虚拟人脸的控制方法、装置、设备及存储介质与流程
1.本技术涉及人工智能技术,尤其涉及一种虚拟人脸的控制方法、装置、设备及存储介质。
背景技术:
2.随着人工智能的不断发展,金融、娱乐、教育等多个领域已经出现为消费者提供服务的虚拟人,虚拟人是通过计算机技术生成的一种与真实人类相对应的虚拟人物,它可以是现实人物在虚拟世界的映像,也可以是完全虚构的一个虚拟形象。在人机交互过程中,消费者不仅要求虚拟人要智能,同时还要求虚拟人在表情、动作和话语等方面要自然。脸部是虚拟人动作最丰富的一个部位,除了与表情相关外,虚拟人在说话时,唇部需要做出与发音相对应的口型,如果口型与发音不对应,很容易让消费者产生不适感。
3.在相关技术中,通常采用3d唇动算法控制虚拟人的唇部运动。3d唇动算法是先从语音提取音素,再根据音素或音素类别生成对应的唇形。然而仅仅依靠音素特征生成的唇部动作不够细腻,尤其是两个音素衔接处的唇形变化不够自然,导致3d唇动算法控制虚拟人唇部动作的准确性较低。
技术实现要素:
4.本技术提供一种虚拟人脸的控制方法、装置、设备及存储介质,可以准确控制唇部动作,使得虚拟人的唇部动作更加自然。
5.第一方面,本技术提供一种虚拟人脸的控制方法,包括:
6.获取第一音频信号,所述第一音频信号为所述虚拟人脸待发音的音频信号;
7.获取所述第一音频信号的音频特征;
8.通过动作生成网络对所述音频特征进行处理,得到人脸参数系列;
9.根据所述人脸参数序列确定虚拟人脸中多个3d顶点在多个时刻的位置,控制所述虚拟人脸中多个3d顶点移动,以及播放所述第一音频信号。
10.在一种可能的实施方式中,根据所述人脸参数序列确定虚拟人脸中多个3d顶点在多个时刻的位置,控制所述虚拟人脸中多个3d顶点移动,并播放所述第一音频信号,包括:
11.将所述人脸参数序列和所述第一音频信号进行时间对齐处理;
12.根据所述时间对齐处理后的人脸参数序列确定虚拟人脸中多个3d顶点在多个时刻的位置,控制所述虚拟人脸中的多个3d顶点移动,以及播放所述时间对齐处理后的第一音频信号。
13.在一种可能的实施方式中,获取第一音频信号,包括:
14.获取初始音频信号和预设采样率;
15.按照预设采样率对所述初始音频信号进行重采样处理,得到所述第一音频信号,所述第一音频信号的采样率为所述预设采样率。
16.在一种可能的实施方式中,获取所述第一音频信号的音频特征,包括:
17.获取所述第一音频信号的在n个维度的m个初始音频特征,所述n、m为大于1的整数;
18.对所述m个初始特征进行拼接处理,得到所述音频特征。
19.在一种可能的实施方式中,通过动作生成网络对所述音频特征进行处理,得到人脸参数序列,包括:
20.对所述音频特征进行分段处理,得到多个分段特征;
21.将所述多个分段特征输入至所述动作生成网络,得到所述人脸参数序列。
22.第二方面,本技术提供一种虚拟人脸的控制装置,包括第一获取模块、第二获取模块、处理模块和控制模块,其中,
23.所述第一获取模块用于,获取第一音频信号,所述第一音频信号为所述虚拟人脸待发音的音频信号;
24.所述第二获取模块用于,获取所述第一音频信号的音频特征;
25.所述处理模块用于,通过动作生成网络对所述音频特征进行处理,得到人脸参数序列;
26.所述控制模块用于,根据所述人脸参数序列确定虚拟人脸中多个3d顶点在多个时刻的位置,控制所述虚拟人脸中多个3d顶点移动,以及播放所述第一音频信号。
27.在一种可能的实施方式中,所述控制模块具体用于:
28.将所述人脸参数序列和所述第一音频信号进行时间对齐处理;
29.根据所述时间对齐处理后的人脸参数序列确定虚拟人脸中多个3d顶点在多个时刻的位置,控制所述虚拟人脸中的多个3d顶点移动,并播放所述时间对齐处理后的第一音频信号。
30.在一种可能的实施方式中,所述第一获取模块具体用于:
31.获取初始音频信号和预设采样率;
32.按照预设采样率对所述初始音频信号进行重采样处理,得到所述第一音频信号,所述第一音频信号的采样率为所述预设采样率。
33.在一种可能的实施方式中,所述第二获取模块具体用于:
34.获取所述第一音频信号的在n个维度的m个初始音频特征,所述n、m为大于1的整数;
35.对所述m个初始特征进行拼接处理,得到所述音频特征。
36.在一种可能的实施方式中,所述处理模块具体用于:
37.对所述音频特征进行分段处理,得到多个分段特征;
38.将所述多个分段特征输入至所述动作生成网络,得到所述人脸参数序列。
39.第三方面,本技术提供一种虚拟人脸的控制设备,包括:处理器、存储器;
40.所述存储器存储计算机执行指令;
41.所述处理器执行所述存储器存储的计算机执行指令,使得所述处理器执行第一方面任一项所述的虚拟人脸的控制方法。
42.第四方面,本技术提供了一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机执行指令,当所述计算机执行指令被处理器执行时用于实现第一方面任一项所述的虚拟人脸的控制方法。
43.本技术提供了一种虚拟人脸的控制方法、装置、设备及存储介质,先获取虚拟人脸待发音的第一音频信号,提取第一音频信号的音频特征,利用动作生成网络对音频特征进行处理得到人脸参数序列,再根据人脸参数序列驱动虚拟人脸运动并播放第一音频信号。上述方法不依赖音素,可以准确控制虚拟人脸的唇部动作,使得虚拟人脸的唇部动作更加自然。
44.第五方面,本技术提供一种动作生成网络的训练方法,包括:
45.获取样本视频中各帧图像的样本人脸参数和样本音频;
46.根据所述样本人脸参数和所述样本音频,生成训练数据,所述训练数据包括所述样本音频和所述样本人脸参数;
47.根据所述训练数据优化所述动作生成网络的网络参数。
48.在一种可能的实施方式中,获取样本视频中各帧图像的样本人脸参数,包括:
49.获取样本视频中各帧图像的多个人脸关键点;
50.制作三维人脸模型;
51.根据各帧图像的人脸关键点和三维人脸模型,确定三维人脸动画;
52.根据三维人脸动画,确定视频中各帧图像的样本人脸参数。
53.在一种可能的实施方式中,根据所述样本人脸参数和所述样本音频,生成训练数据,包括:
54.对所述样本人脸参数和所述样本音频进行时间对齐处理;
55.确定所述训练数据包括所述时间对齐处理后的样本人脸参数和样本音频。
56.在一种可能的实施方式中,对所述样本人脸信息和所述样本音频进行时间对齐处理,包括:
57.获取所述样本音频的音频时长;
58.根据所述样本视频的帧速率获取各帧图像的样本人脸参数所对应的时刻,以使所述样本视频中第一帧图像的样本人脸参数对应的时刻与最后一帧图像的样本人脸参数对应的时刻之间的时间差与所述音频时长相同。
59.在一种可能的实施方式中,根据所述训练数据优化所述动作生成网络的网络参数,包括:
60.按照所述预设采样率对所述样本音频进行重采样;
61.获取所述样本音频的音频特征,并对所述音频特征进行分段;
62.将分段的音频特征输入所述动作生成网络;
63.根据所述动作生成网络输出的人脸参数和预设的人脸参数计算损失函数;
64.根据所述损失函数优化所述动作生成网络的网络参数。
65.第六方面,本技术提供一种动作生成网络的训练装置,包括获取模块、生成模块和优化模块,其中,
66.所述获取模块用于,获取样本视频中各帧图像的样本人脸参数和样本音频;
67.所述生成模块用于,根据所述样本人脸参数和所述样本音频,生成训练数据,所述训练数据包括所述样本音频和所述样本人脸参数;
68.所述优化模块用于,根据所述训练数据优化所述动作生成网络的网络参数。
69.在一种可能的实施方式中,所述获取模块具体用于:
70.获取样本视频中各帧图像的多个人脸关键点;
71.制作三维人脸模型;
72.根据各帧图像的人脸关键点和三维人脸模型,确定三维人脸动画;
73.根据三维人脸动画,确定视频中各帧图像的样本人脸参数。
74.在一种可能的实施方式中,所述生成模块具体用于:
75.对所述样本人脸参数和所述样本音频进行时间对齐处理;
76.确定所述训练数据包括所述时间对齐处理后的样本人脸参数和样本音频。
77.在一种可能的实施方式中,所述生成模块具体用于:
78.获取所述样本音频的音频时长;
79.根据所述样本视频的帧速率获取各帧图像的样本人脸参数所对应的时刻,以使所述样本视频中第一帧图像的样本人脸参数对应的时刻与最后一帧图像的样本人脸参数对应的时刻之间的时间差与所述音频时长相同。
80.在一种可能的实施方式中,所述优化模块具体用于:
81.按照所述预设采样率对所述样本音频进行重采样;
82.获取所述样本音频的音频特征,并对所述音频特征进行分段;
83.将分段的音频特征输入所述动作生成网络;
84.根据所述动作生成网络输出的人脸参数和预设的人脸参数计算损失函数;
85.根据所述损失函数优化所述动作生成网络的网络参数。
86.第七方面,本技术提供一种动作生成网络的训练设备,包括:处理器、存储器;
87.所述存储器存储计算机执行指令;
88.所述处理器执行所述存储器存储的计算机执行指令,使得所述处理器执行第五方面任一项所述的动作生成网络的训练方法。
89.第八方面,本技术提供一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机执行指令,当所述计算机执行指令被处理器执行时用于实现第五方面任一项所述的动作生成网络的训练方法。
90.本技术提供一种动作生成网络的训练方法、装置、设备及存储介质,先获取样本视频中各帧图像的样本人脸参数和样本音频;根据样本人脸参数和样本视频中的样本音频,生成训练数据,根据训练数据优化动作生成网络的网络参数。上述方法可以降低动作生成网络的训练成本以及训练时间,将上述动作生成网络应用于虚拟人脸中,可以准确控制唇部动作,使得虚拟人脸的唇部动作更加自然。
附图说明
91.此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本技术的实施例,并与说明书一起用于解释本技术的原理。
92.图1为本技术实施例提供的一种应用场景示意图;
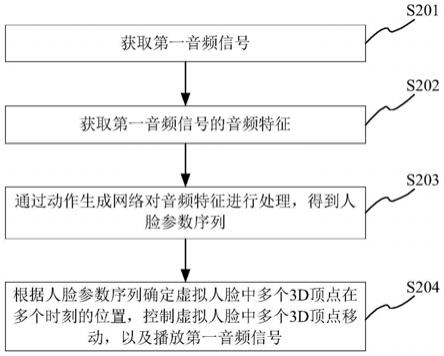
93.图2为本技术实施例提供的一种虚拟人脸的控制方法的流程示意图一;
94.图3为本技术实施例提供的一种虚拟人脸的控制方法的流程示意图二;
95.图4为本技术实施例动作生成网络的网络架构示意图;
96.图5为本技术实施例提供的一种动作生成网络的训练方法的流程示意图一;
97.图6为本技术实施例提供的一种动作生成网络的训练方法的流程示意图二;
98.图7为本技术实施例提供的利用动作生成网络的虚拟人脸的控制方法的流程示意图;
99.图8为本技术实施例提供的一种虚拟人脸的控制装置的结构示意图;
100.图9为本技术实施例提供的一种虚拟人脸的控制设备的结构示意图;
101.图10为本技术实施例提供的一种动作生成网络的训练装置的结构示意图;
102.图11为本技术实施例提供的一种动作生成网络的控制设备的结构示意图。
103.通过上述附图,已示出本技术明确的实施例,后文中将有更详细的描述。这些附图和文字描述并不是为了通过任何方式限制本技术构思的范围,而是通过参考特定实施例为本领域技术人员说明本技术的概念。
具体实施方式
104.为使本技术的目的、技术方案和优点更加清楚,下面将结合本技术的实施例,对本技术实施例中的技术方案进行清楚、完整的描述,显然,所描述的实施例是本技术一部分实施例,而不是全部的实施例。基于本技术中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本技术保护的范围。
105.虚拟人是通过计算机技术生成的一种与真实人类相对应的虚拟人物。随着人工智能的不断发展,金融、娱乐、教育等多个领域已经出现为消费者提供服务的虚拟人,例如虚拟客服、虚拟主持人、虚拟助理等。下面以虚拟客服为例对本技术的一种应用场景进行说明。
106.为了便于理解,下面结合图1,对本技术实施例所适用的应用场景进行说明。
107.图1为本技术实施例提供的一种应用场景示意图。请参见图1,包括终端设备101和服务器102。终端设备101可以通过无线网络与服务器102建立通信连接。
108.终端设备101上可以安装有各种应用,例如语音交互应用、媒体播放类应用、网页浏览器应用、通信类应用等。终端设备101可以是各种有屏幕的电子设备,包括智能手机、平板电脑、笔记本电脑、台式电脑或者智能电视等。
109.用户可以点击终端设备101中的语音交互应用,语音交互应用启动后,会根据用户的需求在终端设备101的屏幕上显示虚拟客服,用户可以与虚拟客服对话。当虚拟客服说话时,终端设备101从服务器102获取语音,终端设备101通过语音驱动虚拟人的唇部动作,使得虚拟人的唇部动作与发出的语音一致。
110.在相关技术中,通常采用3d唇动算法控制虚拟人的唇部运动,3d唇动算法是先从语音提取音素,再根据音素或音素类别生成对应的唇形。然而仅仅依靠音素特征生成的唇部动作不够细腻,尤其是两个音素衔接处的唇形变化不够自然,导致3d唇动算法控制虚拟人唇部动作的准确性较低。
111.为了解决上述技术问题,本技术提出一种虚拟人脸的控制方法,先获取虚拟人脸待发音的第一音频信号,提取第一音频信号的音频特征,利用动作生成网络对音频特征进行处理得到人脸参数序列,再根据人脸参数序列驱动虚拟人脸运动并播放第一音频信号。上述方法不依赖音素,可以准确控制虚拟人脸的唇部动作,使得虚拟人脸的唇部动作更加自然。
112.下面,通过具体实施例对本技术所示的技术方案进行详细说明。需要说明的是,下面几个实施例可以独立存在,也可以相互结合,对于相同或相似的概念或过程可能在某些实施例中不再赘述。
113.图2为本技术实施例提供的一种虚拟人脸的控制方法的流程示意图一。请参见图2,该方法可以包括:
114.s201、获取第一音频信号。
115.本技术实施例的执行主体可以为终端设备,也可以为服务器,还可以为设置在终端设备或者服务器中的虚拟人脸的控制装置,该装置可以通过软件实现,也可以通过软件和硬件结合实现。
116.第一音频信号为虚拟人脸待发音的音频信号。
117.虚拟人脸可以像真实人类一样说话,做动作;例如,虚拟人脸可以为3d虚拟人脸。
118.可以通过以下方式得到第一音频信号:获取初始音频信号和预设采样率;按照预设采样率对初始音频信号进行重采样处理,得到第一音频信号。
119.初始音频信号可以是录音设备录制的音频信号,也可以是通过语音合成(text to speech,简称tts)技术合成的音频信号。
120.初始音频信号的采样率可以高于预设采样率,例如初始信号的采样率为46khz,预设采样率为16khz。初始音频信号的采样率也可以低于预设采样率,例如初始信号的采样率为8khz,预设采样率为16khz。初始音频信号的采样率也可以与预设采样率相同,此时,初始音频信号即为第一音频信号,可以不进行重采样处理。
121.第一音频信号的采样率为预设采样率,预设采样率可以为8khz、11khz、16khz、22khz或44khz。
122.第一音频信号的时长可以与初始音频信号的时长相同。
123.s202、获取第一音频信号的音频特征。
124.音频特征可以是区分不同语音的特征,也可以是剔除与唇形无关音色的特征。
125.音频特征的特征维度可以是多维的,例如,音频特征的特征维度可以是52维的。
126.s203、通过动作生成网络对音频特征进行处理,得到人脸参数序列。
127.人脸参数序列可以为三维人脸模型参数序列或者是三维人脸顶点位移序列。
128.可以通过以下方式对音频特征进行处理:对音频特征进行分段处理,得到多个分段特征;将多个分段特征输入至动作生成网络,得到人脸参数序列。
129.例如,音频特征的时长为3min,动作生成网络对应的分段时长为5s,按照分段时长5s对3min的音频特征进行分段处理,得到36个分段特征,将36个分段特征输入至动作生成网络,得到人脸参数序列。
130.s204、根据人脸参数序列确定虚拟人脸中多个3d顶点在多个时刻的位置,控制虚拟人脸中多个3d顶点移动,以及播放第一音频信号。
131.3d顶点的位置可以是3d顶点的坐标,虚拟人脸可以根据3d顶点移动做出不同的动作,即,虚拟人脸不同的动作对应的3d顶点的位置可能不同。
132.可以通过如下方式控制虚拟人脸中多个3d顶点移动,以及播放第一音频信号:将人脸参数序列和第一音频信号进行时间对齐处理;根据时间对齐处理后的人脸参数序列,控制虚拟人脸中的多个3d顶点移动,并播放时间对齐处理后的第一音频信号。
133.在图2所示的实施例中,先获取虚拟人脸待发音的第一音频信号,再获取第一音频信号的音频特征,利用动作生成网络对音频特征进行处理得到人脸参数序列,根据人脸参数序列确定虚拟人脸中多个3d顶点在多个时刻的位置,并控制虚拟人脸中多个3d顶点移动,以及播放第一音频信号。上述方法不依赖音素,可以准确控制虚拟人脸的唇部动作,使得虚拟人脸的唇部动作更加自然。
134.在上述任意实施例的基础上,下面,结合图3所示的实施例,对上述虚拟人脸的控制方法进行详细说明。
135.图3为本技术实施例提供的一种虚拟人脸的控制方法的流程示意图二。请参见图3,该方法可以包括:
136.s301、获取初始音频信号和预设采样率。
137.需要说明的是,s301的执行过程可以参见s201的执行过程,此处不再进行赘述。
138.s302、按照预设采样率对初始音频信号进行重采样处理,得到第一音频信号。
139.需要说明的是,s302的执行过程可以参见s201的执行过程,此处不再进行赘述。
140.s303、获取第一音频信号的在n个维度的m个初始音频特征。
141.m为大于1的整数,例如,m可以为2。
142.n个维度的初始音频特征是指初始音频特征的特征维度为n,n为大于1的整数,n可以为13、26、52等数值。
143.初始音频特征可以是区分不同语音的特征,也可以是剔除与唇形无关音色的特征。
144.初始音频特征可以是梅尔频率倒谱系数(mel frequency cepstrum coefficient,mfcc)、频谱子带质心(spectral subband centroids,ssc)特征。
145.可以采用不同的特征库提取初始音频特征,例如,可以采用python_speech_features库提取初始音频特征,提取mfcc的倒谱数可以为26,提取ssc特征的过滤器个数可以为26,倒谱数以及过滤器的个数可以决定初始音频特征的特征维度。
146.假设音频信号有t秒,在计算mfcc特征的时候,设置倒谱数为26,窗口间隔为1.0/60.0,最终得到mfcc为[m1,m2,
……
,mt]
t
,其中mi=[m1,m2,
……
,m26](i=1,2,
……
,t),t=60t。其中,倒谱数决定了mfcc的特征维度,窗口间隔决定了mfcc对应的音频时段,1.0/60.0表示将每秒的音频分成60帧计算特征,每一个mi对应音频的一帧。
[0147]
假设音频信号有t秒,在计算ssc特征的时候,设置过滤器个数为26,窗口间隔为1.0/60.0,最终得到ssc为[s1,s2,
……
,st]
t
,其中si=[s1,s2,
……
,s26](i=1,2,
……
,t),t=60t。其中,过滤器个数决定ssc特征的维度。
[0148]
s304、对m个初始特征进行拼接处理,得到音频特征。
[0149]
拼接处理是指在维度上进行拼接。例如,初始特征为26维的mfcc和26维的ssc,将mfcc和ssc拼接后得到52维的音频特征。
[0150]
可以用以下方式表示具体的拼接过程:
[0151]
26维的mfcc表示为:[m1,m2,
……
,mt]
t
;
[0152]
26维的ssc表示为:[s1,s2,
……
,st]
t
;
[0153]
拼接后的52维的音频特征为:[(m1,s1),(m2,s2),
……
,(mt,st)]
t
。
[0154]
音频特征的时长与初始音频信号的时长是一致的。
[0155]
s305、对音频特征进行分段处理,得到多个分段特征。
[0156]
可以采用以下至少一种方式对音频特征进行分段处理:
[0157]
方式一、利用滑动窗口对音频特征进行分段处理。
[0158]
假设音频特征为音频特征[f1,f2,
……
,ft]
t
,进行分段的滑动窗口的窗口宽度为16,滑动步长为1。首先在音频特征的头尾添加pad,pad长度为1/2的窗口宽度。添加pad后的音频特征为[0,0,0,0,0,0,0,0,f1,f2,
……
,ft,0,0,0,0,0,0,0,0],其中0并不是标量而是零向量,向量维度与fi维度相同。经过滑动窗口分段后,得到一组分段特征,分别为{[0,0,0,0,0,0,0,0,f1,f2,
……
,f8]
t
、[0,0,0,0,0,0,0,f1,f2,
……
,f9]
t
、
……
、[ft-7,ft-6,
……
,ft,0,0,0,0,0,0,0,0]
t
},其中,t为音频信号的时长。
[0159]
s306、将多个分段特征输入至动作生成网络,得到人脸参数序列。
[0160]
动作生成网络可以是唇部动作生成神经网络。
[0161]
动作生成网络可以通过对输入的分段特征进行卷积处理和全连接层处理,得到人脸参数序列。
[0162]
为了便于理解,下面,结合图4,对动作生成网络的网络架构进行说明。
[0163]
图4为本技术实施例动作生成网络的网络架构示意图。请参见图4,包括4个卷积层和3个全连接层。分段特征先进入卷积层,每个卷积层由3*1的卷积核对分段特征进行卷积处理。经过4个卷积层的处理和2个全连接层的处理得到嵌入空间的特征向量,特征向量再由1个全连接层处理得到人脸参数序列。
[0164]
s307、将人脸参数序列和第一音频信号进行时间对齐处理。
[0165]
可以通过以下方式将人脸参数序列和第一音频信号进行时间对齐处理:根据音频特征的提取参数及分段参数,确定输入网络的分段音频特征之间的时间间隔。此间隔也是人脸参数序列中相邻人脸参数序列之间的时间间隔。在播放音频的同时,按照所述时间间隔更新人脸参数序列,即可对齐人脸参数序列与第一音频信号。
[0166]
例如,计算音频特征的窗口间隔是1.0/60.0秒,音频特征分段的滑动窗口滑动步长是1,则输入网络的分段音频特征间的时间间隔为1.0/60.0*1=1/60秒,即动作生成网络输出的人脸参数间的时间间隔也是1/60秒。在播放音频的同时,按照每隔1/60秒更新人脸参数,即可实现音频与人脸画面的同步。
[0167]
s308、根据时间对齐处理后的人脸参数序列确定虚拟人脸中多个3d顶点在多个时刻的位置,控制虚拟人脸中的多个3d顶点移动,以及播放时间对齐处理后的第一音频信号。
[0168]
在图3所示的实施例中,先获取初始音频信号和预设采样率,对初始音频信号进行重采样处理,得到采样率为预设采样率的第一音频信号。提取第一音频信号的n个维度的m个初始音频特征,将m个初始特征进行维度上的拼接,得到音频特征。对音频特征进行分段处理,得到多个分段特征。将多个分段特征输入至动作生成网络,得到人脸参数序列;将人脸参数序列和第一音频信号进行时间对齐处理。根据时间对齐处理后的人脸参数序列确定虚拟人脸中多个3d顶点在多个时刻的位置,控制虚拟人脸中的多个3d顶点移动,以及播放时间对齐处理后的第一音频信号。上述方法不依赖音素,可以准确控制虚拟人脸的唇部动作,使得虚拟人脸的唇部动作更加自然。同时,上述方法整个过程耗时短,可以达到实时的播放第一音频信号和显示虚拟人脸的唇部动作。
[0169]
图2-图3所示的实施例说明了虚拟人脸的控制方法。虚拟人脸的控制方法中使用
了动作生成网络,下面结合图5-图6所示的实施例说明动作生成网络的训练方法。
[0170]
图5为本技术实施例提供的一种动作生成网络的训练方法的流程示意图一。请参见图4,该方法可以包括:
[0171]
s501、获取样本视频中各帧图像的样本人脸参数和样本音频。
[0172]
样本视频中包括人脸图像;样本视频可以通过摄像装置获取,摄像装置中摄像头的画面分辨率为1280*720,帧速率大于等于60fps。
[0173]
样本人脸参数可以推导出3d人脸顶点的位置。
[0174]
可以通过以下方式获取样本人脸参数:获取样本视频中各帧图像的多个人脸关键点;制作三维人脸模型;根据各帧图像的人脸关键点和三维人脸模型,确定三维人脸动画;根据三维人脸动画,确定视频中各帧图像的样本人脸参数。
[0175]
关键点可以是虚拟人脸的嘴角,唇峰、眼角,眉头,眉尾,下巴等。
[0176]
上述获取样本人脸参数的方式可以通过面部生成软件实现,面部生成软件可以为faceware。
[0177]
三维人脸模型可以包括三维人脸无表情模型和若干基础动作模型(如张嘴、撇嘴、闭眼等)。
[0178]
样本视频中包括样本音频;样本音频可以采用视频编辑软件从样本视频中分离出来。视频编辑软件可以为格式工厂。
[0179]
s502、根据样本人脸参数和样本音频,生成训练数据。
[0180]
可以通过如下方式根据样本人脸参数和样本音频,生成训练数据:对样本人脸信息参数和样本音频进行时间对齐处理;确定训练数据包括时间对齐处理后的样本人脸参数和样本音频。
[0181]
s503、根据训练数据优化动作生成网络的网络参数。
[0182]
可以通过如下方式根据训练数据优化动作生成网络的网络参数:按照预设采样率对样本音频进行重采样;获取样本音频的音频特征,并对音频特征进行分段;将分段的音频特征输入动作生成网络;根据动作生成网络输出的人脸参数和预设的人脸参数计算损失函数;根据损失函数优化动作生成网络的网络参数。
[0183]
损失函数可以为:
[0184]
loss=λ
p
l
p
+λvlv[0185]
其中l
p
为三维人脸各顶点的位置差异,lv为三维人脸各顶点运动时的速度差异,λ
p
和λv为权重系数。
[0186]
在动作生成网路的训练过程中,需要利用损失函数对网络参数进行优化,如果损失函数没有收敛,则需要反复利用训练数据更新动作生成网络的网络参数,直至损失函数收敛,训练停止,得到训练好的动作生成网络。
[0187]
在图5所示的实施例中,先获取样本视频,再获取样本视频中各帧图像的样本人脸参数和样本音频,根据样本视频的样本音频与样本人脸参数生成训练数据,利用训练数据反复优化动作生成网络的网络参数,直至动作生成网络满足条件后,停止训练。上述动作生成网络的训练方法可以降低动作生成网络的训练成本以及训练时间,将上述动作生成网络应用于虚拟人脸中,可以准确控制唇部动作,使得虚拟人脸的唇部动作更加自然。
[0188]
在图5所示实施例的基础上,下面,结合图6所示的实施例,对上述动作生成网络的
训练方法进行详细说明。
[0189]
图6为本技术实施例提供的一种动作生成网络的训练方法的流程示意图二。请参见图6,该方法可以包括:
[0190]
s601、获取样本视频中各帧图像的样本人脸参数和样本音频。
[0191]
需要说明的是,s601的执行过程可以参见s501的执行过程,此处不再进行赘述。
[0192]
s602、对样本人脸参数和样本音频进行时间对齐处理。
[0193]
可以通过以下方式对样本人脸参数和样本音频进行时间对齐处理:获取样本音频的音频时长,样本音频与样本视频中的帧画面相互对应,即样本音频的时长与样本视频中画面的播放时长相同;根据样本视频的帧速率获取各帧图像的样本人脸参数所对应的时刻,以使样本视频中第一帧图像的样本人脸参数对应的时刻与最后一帧图像的样本人脸参数对应的时刻之间的时间差与音频时长相同。
[0194]
s603、确定训练数据包括时间对齐处理后的样本人脸参数和样本音频。
[0195]
训练数据应该包含尽可能多的不同发音的词语和样本人脸参数。
[0196]
例如,可以采用thchs-30中文语音识别数据集作为说话人素材,每句话录制成一段单独的视频,采用faceware软件对视频进行批量处理,可快速生成所有训练数据。
[0197]
s604、根据训练数据优化动作生成网络的网络参数。
[0198]
需要说明的是,s604的执行过程可以参见s503的执行过程,此处不再进行赘述。
[0199]
在图6所示的实施例中,先获取样本视频,再获取样本视频中各帧图像的样本人脸参数,提取样本视频中的样本音频,将样本音频与样本人脸参数进行时间对齐处理,根据对齐后的样本音频与样本人脸参数生成训练数据,利用训练数据反复优化动作生成网络的网络参数,直至动作生成网络满足条件后,停止训练。上述动作生成网络的训练方法可以降低动作生成网络的训练成本以及训练时间,将上述动作生成网络应用于虚拟人脸中,可以准确控制唇部动作,使得虚拟人脸的唇部动作更加自然。
[0200]
图2-图3所示的实施例说明了虚拟人脸的控制方法。图5-图6所示的实施例说明了动作生成网络的训练方法。下面,结合图7,对动作生成网络的训练方法以及利用动作生成网络对虚拟人脸的控制方法进行具体说明。
[0201]
图7为本技术实施例提供的利用动作生成网络的虚拟人脸的控制方法的流程示意图。请参见图7,该方法具体如下:
[0202]
以thchs-30中文语音识别数据集作为说话人素材,将每句话录制成单独的样本视频(s701),录制视频的网络摄像头的画面分辨率为1280
×
720,帧速率为60fps。为了避免漏拍唇部动作,摄像头帧速率应该不低于60fps。利用faceware面部生成软件对样本视频进行批量处理,具体过程为:将拍摄的视频输入faceware analyzer,此模块可以跟踪视频中的人脸并检测人脸关键点(s702),然后faceware retargeter可以根据人脸关键点信息生成三维人脸动画,不过还需要一个三维人脸无表情模型和若干基础动作模型(如张嘴、撇嘴、闭眼等)(s703);retargeter会根据analyzer对视频的分析结果,结合三维人脸模型及其基础动作模型,生成一段三维人脸动画(s704)。根据三维人脸动画,确定样本视频中各帧图像的样本人脸参数,将样本人脸参数和样本视频中的音频信号进行时间对齐处理,根据对齐后的样本人脸参数和样本视频中的音频信号组成训练数据(s705)。
[0203]
利用训练数据训练动作生成网络,采用的音频特征窗口大小为16,滑动窗口移动
步长为1,损失函数中λ
p
=1.0,λv=10.0,一次训练的音频数为64,采用adam优化,学习率为0.0001,网络输出为虚拟人脸的顶点位移。将顶点位移与三维人脸模型无表情状态下的顶点位置相加,得到与音频对应的三维人脸顶点位置(s706)。随着网络参数不断优化,损失函数值逐渐降低,直到满足一定条件,训练停止,得到训练好的唇部动作生成网络(s707)。
[0204]
将虚拟人脸待发音音频信号经过重采样、特征提取和分段后,输入动作生成网络,网络输出与音频对应的三维人脸顶点位移序列(s708)。将此位移序列输入虚拟人脸渲染系统,驱动虚拟人脸做出与发音音频相对应的唇形(s709)。
[0205]
上述动作生成网络的训练方法可以降低动作生成网络的训练成本以及训练时间,将上述动作生成网络应用于虚拟人脸中,可以准确控制唇部动作,使得虚拟人脸的唇部动作更加自然。经过测试,本技术虚拟人脸的控制方法无论在pc端还是移动端,都可以达到毫秒级的单帧运行时间,完全可以满足实时要求。
[0206]
图8为本技术实施例提供的一种虚拟人脸的控制装置的结构示意图。请参见图8,该虚拟人脸模型的控制装置10可以包括第一获取模块11、第二获取模块12、处理模块13和控制模块14,其中,
[0207]
第一获取模块11用于,获取第一音频信号,第一音频信号为所述虚拟人脸模型待发音的音频信号;
[0208]
第二获取模块12用于,获取第一音频信号的音频特征;
[0209]
处理模块13用于,通过动作生成网络对音频特征进行处理,得到人脸参数序列;
[0210]
控制模块14用于,根据人脸参数序列确定虚拟人脸中多个3d顶点在多个时刻的位置,控制虚拟人脸模型中多个3d顶点移动,以及播放第一音频信号。
[0211]
在一种可能的实施方式中,控制模块14具体用于:
[0212]
将人脸参数和第一音频信号进行时间对齐处理;
[0213]
根据时间对齐处理后的人脸参数序列确定虚拟人脸中多个3d顶点在多个时刻的位置,控制虚拟人脸模型中的多个3d顶点移动,以及播放时间对齐处理后的第一音频信号。
[0214]
在一种可能的实施方式中,第一获取模块11具体用于:
[0215]
获取初始音频信号和预设采样率;
[0216]
按照预设采样率对初始音频信号进行重采样处理,得到第一音频信号,第一音频信号的采样率为预设采样率。
[0217]
在一种可能的实施方式中,第二获取模块12具体用于:
[0218]
获取第一音频信号的在n个维度的m个初始音频特征,n、m为大于1的整数;
[0219]
对m个初始特征进行拼接处理,得到音频特征。
[0220]
在一种可能的实施方式中,处理模块13具体用于:
[0221]
对音频特征进行分段处理,得到多个分段特征;
[0222]
将多个分段特征输入至动作生成网络,得到人脸参数序列。
[0223]
本技术实施例提供的虚拟人脸的控制装置10可以执行上述虚拟人脸的控制方法实施例所示的技术方案,其实现原理以及有益效果类似,此次不再进行赘述。
[0224]
图9为本技术实施例提供的一种虚拟人脸的控制设备的结构示意图。请参见图9,虚拟人脸的控制设备20可以包括:存储器21、处理器22。示例性地,存储器21、处理器22,各部分之间通过总线23相互连接。
[0225]
存储器21存储计算机执行指令;
[0226]
处理器22执行存储器21存储的计算机执行指令,使得处理器22执行上述任一项的虚拟人脸的控制方法。
[0227]
图9实施例所示的虚拟人脸的控制设备可以执行上述虚拟人脸的控制方法实施例所示的技术方案,其实现原理以及有益效果类似,此处不再进行赘述。
[0228]
本技术提供了一种计算机可读存储介质,计算机可读存储介质中存储有计算机执行指令,当计算机执行指令被处理器执行时用于实现上述任一项的虚拟人脸的控制方法。
[0229]
本技术实施例还提供一种计算机程序产品,包括计算机程序,该计算机程序被处理器执行时,可实现上述虚拟人脸的控制方法。
[0230]
图10为本技术实施例提供的一种动作生成网络的训练装置的结构示意图。请参见图10,该动作生成网络的训练装置30可以包括获取模块31、生成模块32和优化模块33,其中,
[0231]
获取模块31用于,获取样本视频中各帧图像的样本人脸参数和样本音频;
[0232]
生成模块32用于,根据样本人脸参数和样本音频,生成训练数据,训练数据包括样本音频和样本人脸参数;
[0233]
优化模块33用于,根据训练数据优化动作生成网络的网络参数。
[0234]
在一种可能的实施方式中,获取模块31具体用于:
[0235]
获取样本视频中各帧图像的多个人脸关键点;
[0236]
制作三维人脸模型;
[0237]
根据各帧图像的人脸关键点和三维人脸模型,确定三维人脸动画;
[0238]
根据三维人脸动画,确定视频中各帧图像的样本人脸参数。
[0239]
在一种可能的实施方式中,生成模块32具体用于:
[0240]
对样本人脸参数和样本音频进行时间对齐处理;
[0241]
确定训练数据包括时间对齐处理后的样本人脸参数和样本音频。
[0242]
在一种可能的实施方式中,生成模块32具体用于:
[0243]
获取样本音频的音频时长;
[0244]
根据样本视频的帧速率获取各帧图像的样本人脸参数所对应的时刻,以使所述样本视频中第一帧图像的样本人脸参数对应的时刻与最后一帧图像的样本人脸参数对应的时刻之间的时间差与所述音频时长相同。
[0245]
在一种可能的实施方式中,优化模块33具体用于:
[0246]
按照所述预设采样率对所述样本音频进行重采样;
[0247]
获取所述样本音频的音频特征,并对所述音频特征进行分段;
[0248]
将分段的音频特征输入所述动作生成网络;
[0249]
根据所述动作生成网络输出的人脸参数和预设的人脸参数计算损失函数;
[0250]
根据所述损失函数优化所述动作生成网络的网络参数。
[0251]
图11为本技术实施例提供的一种动作生成网络的控制设备的结构示意图。请参见图10,动作生成网络的控制设备40可以包括:存储器41、处理器42。示例性地,存储器41、处理器42,各部分之间通过总线43相互连接。
[0252]
存储器41存储计算机执行指令;
[0253]
处理器42执行存储器41存储的计算机执行指令,使得处理器42执行上述任一项的动作生成网络的训练方法。
[0254]
图11实施例所示的动作生成网络的控制设备可以执行上述动作生成网络的控制方法实施例所示的技术方案,其实现原理以及有益效果类似,此处不再进行赘述。
[0255]
本技术实施例还提供一种计算机可读存储介质,计算机可读存储介质中存储有计算机执行指令,当计算机执行指令被处理器执行时用于实现前述任一项所述的动作生成网络的训练方法。
[0256]
本技术实施例还提供一种计算机程序产品,包括计算机程序,该计算机程序被处理器执行时,可实现上述动作生成网络的训练方法。
[0257]
本领域技术人员在考虑说明书及实践这里公开的发明后,将容易想到本技术的其它实施方案。本技术旨在涵盖本技术的任何变型、用途或者适应性变化,这些变型、用途或者适应性变化遵循本技术的一般性原理并包括本技术未公开的本技术领域中的公知常识或惯用技术手段。说明书和实施例仅被视为示例性的,本技术的真正范围和精神由下面的权利要求书指出。
[0258]
应当理解的是,本技术并不局限于上面已经描述并在附图中示出的精确结构,并且可以在不脱离其范围进行各种修改和改变。本技术的范围仅由所附的权利要求书来限制。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1