一种新的基于轻量级网络的显著性目标检测方法
1.本发明技术属于图像处理、人工智能领域,具体来讲,涉及一种采用全局池化聚合模块和特征聚合增强模块以及混合损失来改进的新的轻量级显著性目标检测方法。
背景技术:
2.人类的视觉系统具有一定的注意机制,能够从某些场景中优先关注其中最突出的目标。图像显著性目标检测旨在模仿人类的视觉感知特点,找到图像中更明显的目标区域,并准确分割出图像中的显著对象。近年来,在深度学习和大数据时代的快速发展下,图像显著性目标检测已经得到了迅速的发展,且作为一种有效的图像预处理技术,在计算机视觉中得到了广泛的应用场景,例如图像分割,图像理解,视觉跟踪,抠图等。目前基于深度学习的显著性目标检测研究相较于传统方法已经取得了显著的进步,但是也带来了一些新的问题:这些基于全卷积神经网络的研究往往是采用大型的网络结构以及会带来大量的计算开销。在编码部分的backbone网络,通常都是采用大参数量和计算量的resnet或vgg。这种繁重的网络不适用于实时以及资源有限的应用,如机器人应用、用户界面优化和自动驾驶等。
3.目前已经提出通过设计轻量级的卷积神经网络来解决上述问题,并将其已经在一些图像处理任务上进行实验,如图像分类。但这些轻量级网络最开始设计的初衷都不是为了一些使用深度卷积神经网络的图像任务所考虑,因此通常深度较浅,结构简单,所能提取的信息有限。而且显著性目标检测任务需要对每个像素进行预测,故若只是单纯地使用轻量级网络,与那些计算成本较大的网络相比会有一定的性能差距。如何在保持轻量级的同时提升显著性目标检测的性能是当前显著性目标检测领域的一大热点。
技术实现要素:
4.本发明的目的在于解决小型特征提取网络所存在的深度较浅、特征提取不足以及融合不同层级的干扰等问题,实现更为精准的轻量级显著性目标检测。
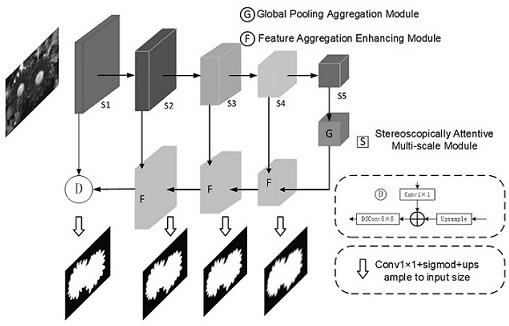
5.为了实现上述目的,本发明提供一种新的基于立体注意力的全局信息渐进聚合轻量级显著性目标检测方法,其中主要包括五个部分,第一部分是对数据集进行预处理;第二部分是引入立体注意力多尺度模块(stereoscopically attentive multi-scale module, sam)进行特征提取;第三部分是衔接全局池化聚合模块(global pooling aggregate module, gpam)来进一步提取顶层的全局语义信息;第四部分是利用特征聚合增强模块(feature aggregate enhancing module, faem)对各层特征进行更为高效的融合;第五部分是采用一种混合损失,通过融合二元交叉熵(binary cross entropy, bce)和交占比(intersection-over-union, iou)损失来对网络进行深度监督方式的训练,对网络最后一层的输出预测图进行测试。
6.第一部分包括两个步骤:步骤1,下载显著性目标检测数据集(duts,dut-omron,hku-is,sod,pascals,ecssd),然后将duts数据集中训练集的10553张图片作为模型训练样本,测试集的5019张图
片和其它5个数据集一起作为模型测试样本;步骤2,将输入图片尺寸统一调整为320
×
320维度,并对图像进行多尺度裁剪、旋转等操作进行在线数据增强,形成增强训练集样本;第二部分包括一个步骤:步骤3,将步骤2中的增强训练样本输入到以sam模块为基础的网络中,共有5个阶段,每个阶段可以获得不同分辨率的特征信息。第一个阶段使用3
×
3普通卷积和一个sam模块提取最低层特征信息,后四个阶段都使用3
×
3的深度可分离卷积和个数分别为1,3,6,3的sam模块来提取由低层到高层的特征信息;第三部分包括一个步骤:步骤4,将步骤3最顶层得到的特征信息传入gpam中,来进一步提取全局信息,以解决小型特征提取网络深度较浅、特征提取不足的问题。具体实施如下:对顶层特征执行5
×
5卷积运算,随后分成两个分支,一个下采样后进行两个3
×
3的卷积运算,另一个进行一个5
×
5的卷积运算,然后将两个分支信息进行融合,而后再次与经过5
×
5卷积的特征图进行融合;接下来再与经过1
×
1卷积的顶层特征进行相乘,最后与全局语义信息(将顶层特征经过全局池化,1
×
1卷积和上采样操作)进行像素相加;第四部分包括四个步骤:步骤5,将步骤4得到的特征图(高层特征)与步骤3的第4阶段得到的特征图(低层特征)传入feam中进行更为高效的特征融合,具体实施如下:将低层特征和高层特征都先经过3
×
3的卷积层,然后将低层特征再进行一次3
×
3卷积,,再与上采样的高层特征相乘得到能够抑制噪声的低层特征图;同时,将高层特征再进行一次3
×
3卷积和上采样,再与低层特征相乘得到具有空间细节的高层特征图;之后将这两个特征图拼接起来,再通过两个3
×
3卷积层来减少通道,同时保留有用信息;然后通过一次3
×
3卷积获得拥有乘法和加法运算的mask w 和bias b得到最终特征图;步骤6,将步骤5得到的特征图(高层特征)与步骤3的第3阶段得到的特征图(低层特征)传入feam中进行更为高效的特征融合,得到低层、高层信息有效互补的特征图;步骤7,将步骤6得到的特征图(高层特征)与步骤3的第2阶段得到的特征图(低层特征)传入feam中进行更为高效的特征融合,得到低层、高层信息有效互补的特征图。
7.步骤8,将步骤7得到的特征图进行上采样操作,步骤3的第1阶段得到的特征图进行1
×
1卷积来改变通道数,两者通过元素求和来进行特征融合,然后通过5
×
5的深度可分离卷积来进一步激活融合后的特征图。
8.第五部分包括三个步骤:步骤9,将步骤5,6,7,8得到的每个特征图都分别依次通过dropout层、单个输出通道的3
×
3卷积、sigmod激活函数以及上采样到与输入图片一样大小,得到4个输出预测图。
9.步骤10,调试网络结构超参数,并采用一种混合损失,通过融合二元交叉熵(bce)和交占比(iou)损失来进行深度监督,即对步骤9得到4个输出预测图分别进行训练。
10.步骤11,将步骤1中6个数据集输入到步骤10中的训练好的模型中,选取网络最后一层输出特征图为最终预测图来进行网络性能的测试与评估。
11.本发明提出一种基于立体注意力的全局信息渐进聚合轻量级显著性目标检测方法。该方法首先在多尺度立体注意力模块(sam)特征提取的基础上构造了一种全局池化聚
合模块(gpam),解决了小型特征提取网络深度较浅、信息提取不足的问题;其次,构造了一种特征聚合增强模块(faem)对各层特征进行更为高效的特征融合;然后采用一种混合损失,融合二元交叉熵(bce)和交占比(iou)损失,能够更有效地定位和分割显著目标;同时,采用深度监督来提高隐藏层学习过程的透明度。
附图说明
12.图1为本发明的具体实施整体框图;图2为本发明的sam结构图;图3为本发明的gpam结构图;图4为本发明的feam结构图。
13.具体实施方式容为了更好的理解本发明,下面结合附图式对本发明的一种新的基于立体注意力的全局信息渐进聚合轻量级显著性目标检测方法进行更为详细的描述。在以下的描述中,当前已有技术的详细描述也许会淡化本发明的主题内容,这些描述在这里将被忽略。
14.图1是本发明的一种具体实施方式的总体框图,在本实施方案中,按照以下步骤进行:步骤1,下载显著性目标检测数据集(duts,dut-omron,hku-is,sod,pascals,ecssd),duts数据集由两部分组成:duts-tr和duts-te,duts-te包含5019幅具有复杂背景与结构的图像,被用于评估数据集。duts-tr总共包含10553张图像。目前,它是用于显著性目标检测的最大且最常用的训练数据集。将duts-tr的10553张图片作为模型训练样本,duts-te的5019张图片和其它5个数据集作为模型测试样本。
15.步骤2,将输入图片尺寸统一调整为320
×
320维度,之后对图像进行多次尺寸变换、随机裁剪、旋转等操作进行在线数据增强,形成增强训练集样本。其中数据图片尺寸变换的范围为输入图片的1.75倍、1.5倍、1.25倍、0.75倍。
16.步骤3,将步骤2中的增强训练样本输入到以sam模块(如图2所示)为基础的网络中,共有5个阶段,每个阶段可以获得不同分辨率的特征信息。第一个阶段使用3
×
3普通卷积和一个sam模块提取最低层特征信息,后四个阶段都使用3
×
3的深度可分离卷积和个数分别为1,3,6,3的sam模块来提取由低层到高层的特征信息。
17.步骤4,将步骤3最顶层得到的特征信息传入gpam(如图3所示)中,来进一步提取全局信息,以解决小型特征提取网络深度较浅、特征提取不足的问题。具体实施如下:对顶层特征执行5
×
5卷积运算,随后分成两个分支,一个下采样后进行两个3
×
3的卷积运算,另一个进行一个5
×
5的卷积运算,从而提取不同感受野的信息,然后将不同感受野的信息进行融合,考虑到对于小目标和背景需要大的感受野信息,故再次与经过5
×
5卷积的特征图进行融合,这样可以更加准确地对相邻的上下文信息进行整合。接下来再与经过1
×
1卷积的顶层特征进行相乘,最后与全局语义信息(将顶层特征经过全局池化,1
×
1卷积和上采样操作)进行像素相加,能够从高级语义特征中学习更加有用的信息。gapm与一般的金字塔结构不同,这里仅下采样一次,并与经过大卷积核的特征图再次相加来融合多尺度的上下文信息,为此能够适用于低分辨率图像。不同于ppm或aspp融合不同金字塔规模的特征图,gapm将上下文信息与顶层特征相乘,再与全局语义信息相加,能够在减小计算的
同时从顶层特征中学习到精确的像素级信息。其表达式如下: 其中g1,g3,g5分别代表1
×
1卷积层,3
×
3卷积层和5
×
5卷积层,每个卷积层都包括convolution,batchnorm和relu。 为relu激活函数。f
gap
为全局平均池化。
18.步骤5,将步骤4得到的特征图(高层特征)与步骤3的第4阶段得到的特征图(低层特征)传入feam(如图4所示)中进行更为高效的特征融合,具体实施如下:先将低层特征和高层特征都先经过3
×
3的卷积层,以此来达到相同的通道数。然后将低层特征再进行一次3
×
3卷积,得到具有细节信息的特征图,再与上采样的高层特征相乘得到能够抑制噪声的低层特征图。同时,将高层特征再进行一次3
×
3卷积和上采样,得到具有语义信息的特征图,再与低层特征相乘得到具有空间细节的高层特征图。其表达式如下:其中i
l
和ih分别代表低层特征和高层特征,g表示3
×
3卷积层,包括convolution,batchnorm和relu;m表示单层3
×
3卷积。之后将这两个特征图拼接起来,再通过两个3
×
3卷积层来减少通道,同时保留有用信息。然后通过一次3
×
3卷积获得拥有乘法和加法运算的mask w 和bias b得到最终输出。其表达式如下:其中s为两层卷积层,包括convolution,batchnorm和relu; 为relu激活函数。
19.步骤6,将步骤5得到的特征图(高层特征)与步骤3的第3阶段得到的特征图(低层特征)传入feam中进行更为高效的特征融合,得到低层、高层信息有效互补的特征图。
20.步骤7,将步骤6得到的特征图(高层特征)与步骤3的第2阶段得到的特征图(低层特征)传入feam中进行更为高效的特征融合,得到低层、高层信息有效互补的特征图。步骤8,将步骤7得到的特征图进行上采样操作,步骤3的第1阶段得到的特征图进行1
×
1卷积来改变通道数,两者通过元素求和来进行特征融合,然后通过5
×
5的深度可分离卷积来进一步激活融合后的特征图。
21.步骤9,将步骤5,6,7,8得到的每个特征图都分别依次通过dropout层、单个输出通道的3
×
3卷积、sigmod激活函数以及上采样到与输入图片一样大小,得到4个输出预测图。
22.步骤10,采用一种混合损失,通过融合二元交叉熵(bce)和交占比(iou)损失,表达式如下:其中l
bce
是像素级损失,对前景和背景像素进行同等加权操作,且不考虑领域标签,有助于所有像素的收敛。l
iou
是map-level的度量,会随着前景预测置信度的增加,使前景的损失降为零。融合这两个损失,可以用bce来保持所有像素的平滑梯度,iou来让更多的重点放在前景上。从而克服轻量级特征提取网络所存在的问题,更有效地定位和分割显著目标。步骤11,调试网络结构超参数,使用adam方法进行优化,其中参数为,,weight_decay= 10-4
。batch size设为16。 设置初始学习率(init)为0.0005,并采用学习率递减模式,这样第n个epoch的学习率就变成,其中power=0.9,本发明使用50个epoch进行训练,即epochs=50。采用深度监督来判断隐藏层特征图质量的好坏,以提高各层之间的学习能力。具体来说,将步骤9得到的4个输出预测图用混合损失函数对每一层进行训练,其表达式如下:其中将设置为1。
23.步骤12,将步骤1中6个数据集输入到步骤11中的训练好的模型中,选取网络最后一层输出特征图为最终预测图来进行网络性能的测试与评估。
24.尽管上面对本发明说明性的具体实施方式进行了描述,但应当清楚,本发明不限于具体实施方式的范围,对本技术领域的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1