基于Transformer的特征聚合人体姿态估计方法
基于transformer的特征聚合人体姿态估计方法
技术领域
1.本发明涉及计算机视觉领域,具体地说是一种基于transformer的特征聚合人体姿态估计方法。
背景技术:
2.目前主流的人体姿态估计网络根据所使用的方法类型可分为基于热图的方法和基于回归的方法。前者提取输入图像的特征,生成包含关节位置信息的热图。以单人姿态估计为例,原始输入是一张包含一个人体的图片,输出是所有人体关节点的高斯热图,最后网络对每个热图进行argmax操作即可得到关节点坐标。这类方法输出的特征图较大,因此空间泛化能力较强,其预测结果往往具有更高的准确度。但这一特性导致网络训练和推理速度较为缓慢。除此之外,由于热图计算关节点坐标的过程是不可微分的,所以该方法难以构建端到端的人体姿态估计网络。
3.近些年许多基于热图的方法被提出,papandreou,george等首先使用faster rcnn预测图像中的人体边界框,再对每个人体边界框进行单人姿态估计。作者使用残差网络预测关节点的密度热图和偏移量,并引入一种新的聚合过程来获得高准确度的关节点预测值。su,kai等提出了csm模块用于不同尺度特征图间的信息通信交流。该模块对不同维度的多通道特征采取混洗操作,加强了特征图对于关节点的表征能力。li,wenbo等则是反思以往多阶段网络的不足并提出了多阶段特征聚合网络。其通过在相邻阶段之间引入特征融合,将前一阶段的先验信息融入到当前阶段中,以此来提升整个网络结构的效果。sun,ke等使整个网络的特征图始终保持高分辨率,有效减少了降采样所带来的信息损失。另外,wang,jian等利用图结构来修正原始的关节点热图结果。
4.基于回归的方法旨在通过降低损失函数来回归关节坐标。它可以从原始图片到人体关节点坐标端对端训练,并且具有较快的训练和推理速度。与热图方法相比,回归方法较弱,空间泛化能力导致预测结果精度较低。早期toshev,a.等利用深度神经网络回归人体关节点坐标。随后,carreira,joao等建立了一个迭代误差反馈的卷积结构,用于早期错误修正。sun,xiao等结合热图表征和回归方法二者的优点,用一个积分操作实现网络端到端训练。目前大多数方法是从人体上的中心点回归关节点坐标。但wei,fangyun等认为这种操作限制了特征提取。他们设置了一组更符合人体结构的点来代替原来的中心点。此外,sun,xiao等采用了用骨骼代替关节的重新参数化姿态表征,并利用关节连接结构来定义一个组合损失函数,对姿态中的长距离相互作用进行编码。
5.近期transformer在计算机视觉领域中出现的频率越来越高,许多学者尝试用它来解决姿态估计任务。其中,li,yanjie等提出了一种基于token表示的transformer方法,该网络增强了捕捉关节点之间约束关系的能力。相比于cnn聚焦于局部信息的聚合,transformer利用其全局感受野能够更好的提取图像的全局特征。li,ke等将transformer与cnn相结合,先用卷积操作获取高维特征图,再令transformer模块获取特征图像素点间的相关性并输出关节点特征图,最终回归关节点坐标。
技术实现要素:
6.本发明的目的就是提供一种基于transformer的特征聚合人体姿态估计方法,该方法预测人体终端关节点(腕、踝等)结果提升更为明显,且提升了人体部分遮挡关节点的预测准确性。
7.本发明是这样实现的:一种基于transformer的特征聚合人体姿态估计方法,该方法首先需要训练特征聚合transformer网络,然后利用训练好的特征聚合transformer网络对图像中人体姿态进行估计。训练特征聚合transformer网络的过程与后期利用训练好的特征聚合transformer网络对图像中人体姿态进行估计的过程类似。下面以训练特征聚合transformer网络为例进行说明。
8.训练特征聚合transformer网络具体包括如下步骤:
9.a1、采用卷积神经网络(convolutional neural networks,cnn)对训练样本进行特征提取得到不同层次的特征图;cnn一般输出4层特征图;
10.a2、从步骤a1中选取待融合的特征图作为候选特征图;优选的方案中,选取第2层和第4层特征图作为候选特征图;
11.a3、将候选特征图进行分割,每一特征图均分为若干等大的特征块,不同特征图所划分的特征块的大小相等;且在每一特征图中将分割后的特征块进行堆叠;优选的方案中,将第2层特征图均分为若干等大的特征块,且特征块的大小与第4层特征图的大小相同;第4层特征图无需划分(或者说划分为一个特征块,仍然是其本身);
12.a4、将不同特征图的特征块进行合并;
13.a5、在合并后的特征块信息中加入位置编码,然后将其一并输出给transformer;本发明中位置编码具体是二维正弦位置编码,其在x维和y维均进行编码;
14.a6、transformer提取全局注意力并生成一组包含关节点特征的假设向量;
15.a7、利用二分匹配算法寻找最优的关节分类方案,同时,一个双通道回归头输出每个关节点的坐标,得到预测结果;
16.a8、比较预测结果与真值,计算损失函数,根据损失函数优化特征聚合transformer网络中各参数,直至得到优化后的特征聚合transformer网络。
17.损失函数的计算公式如下:
[0018][0019]
其中,yi表示第i个关节点真值,则是第i个关节点所对应假设向量的预测结果,j是关节点分类的数量,li指第i个关节点损失,公式如下:
[0020][0021]
其中,cls(i)表示第i个关节点类别,为假设向量的分类概率分布;bi和分别是关节点坐标真值和对应假设向量的坐标预测值。
[0022]
优选的,特征聚合transformer网络中各参数包括transformer中编码器数量、解码器数量、多头注意力数量、假设向量个数,以及卷积神经网络中初始学习率、权重衰减学习率等。
[0023]
本发明方法对cnn输出进行特征聚合,具体是通过对多维特征进行分割和合并的方式来实现的,通过特征聚合将低维的局部特征添加到高维的全局特征中,且此操作不会为transformer带来额外的计算成本,最后通过transformer提取全局注意力并生成一组包含关节点特征的假设向量,再经关节点分类和坐标回归两个操作预测最终结果。通过本发明方法可以提高检测结果的准确性,对于人体被遮挡部分关节点的检测结果准确率的提升尤为突出。
附图说明
[0024]
图1是本发明所提供的特征聚合transformer网络的结构示意图。
[0025]
图2是本发明对第n层特征图进行分割的过程示意图。
[0026]
图3是本发明中transformer的结构示意图。
[0027]
图4是本发明实施例中采用本发明方法与prtr实验结果的对比图。
具体实施方式
[0028]
本发明由河北省高等学校科学技术研究项目资助(zd2019131,qn2018214)、河北省自然科学基金项目(f2019201451)研究完成。以下结合附图对本发明进行详细说明,应当理解为,此处所描述的实施方式仅用于说明和解释本发明,并不用于限定本发明。
[0029]
本发明构建一种基于回归的端到端网络—特征聚合transformer网络,其整体结构如图1所示,将原始输入图像定义为i∈rh×w×3,其中h和w是图像的高和宽。随即卷积神经网络(convolutional neural networks,cnn)被用于提取原始图像多个维度(一般是4个维度)的特征图,这些特征图用表示,其中n(默认n=4)是cnn中的层数。cnn可以有效地提取图像局部特征。此外由于参数共享和池化的机制使其具有平移不变性,有效提升网络鲁棒性。随后特征聚合模块对多层特征图进行融合。该过程是解决终端关节检测和咬合问题的关键。
[0030]
特征聚合模块的目标是对cnn输出的多维特征v进行分割和合并。cnn输出的每一维特征对应一层特征图,用sn表示第n层特征图,n=1,2,
……
,n,本发明实施例中n为4,sn的高度和宽度分别用hn和wn表示。如图2所示,分割时,对每一层特征图首先进行一次1
×
1的卷积操作,以便降低特征图通道数,之后将特征图划分为若干相同大小的特征块,特征块的高度和宽度分别用h
p
和w
p
来表示。每一层特征图所划分后的特征块的大小均相同。本发明实施例中使每一层特征图所划分后的特征块的大小与第四层特征图的大小相同,即:h
p
=h
n=4
,w
p
=w
n=4
。这样,只需对前三层特征图进行特征块的划分即可,第四层特征图无需划分。
[0031]
通过将特征图划分为若干特征块,可以将当前维度的全局信息划分为局部信息,然后在通道方向上堆叠当前维度的特征块。结合图1,特征聚合模块对多个维度的特征块进行融合,达到多维特征融合的目的。如公式(1):
[0032][0033]
其中,l为候选维度集合,conv代表卷积操作,patch指代分割操作。特征聚合模块实际上是将低维的局部特征添加到高维的全局特征中,且此融合方法不会为transformer带来额外的计算成本。
[0034]
与cnn隐式编码序列位置信息不同,transformer中的自注意力机制无法识别输入序列的顺序。因此,在将特征聚合模块的输出输入到transformer之前需要进行位置编码。本发明选择二维正弦位置编码,它在x维和y维均进行编码。由于相对位置的编码具有线性关系,这种位置编码使得模型易于学习序列元素间的相对位置关系。在添加位置信息之后,transformer捕获全局特性并输出一系列关节点假设。最后,利用二分匹配算法寻找最优的关节分类方案。同时,一个双通道回归头输出每个关节点的坐标。
[0035]
transformer的结构如图3所示,即本发明遵循传统的编码器-解码器结构。对回归方法来说这类结构比仅使用编码器更有优势。编码器包含multi-head attention层和feed forward层。解码器相比编码器而言额外添加cross multi-head attention层。attention层用于计算输入序列中元素间的相关性。
[0036]
编码器从全局接受域中提取上下文相关性。vf中的任意两个位置索引i和j构成一个无序对,自注意力层计算相应的权重来反映两个位置之间的相关性。事实上,自注意力层通过权重矩阵来推断上下文特征。随后,解码器从已有的上下文特征中推理关节点特征,并将它们存储在假设向量中。在多个(m个)串联解码器的指导下,这些假设向量所包含的信息越来越准确。最后,transformer输出这些假设向量。
[0037]
本发明通过比较预测值和真值来计算损失。结合图1,整体网络根据关节点分类和坐标回归可以得到最终的预测结果。前者可以看作是一个最优二分匹配问题,它建立了从关节点到假设向量的内射且非满射关系,这是由于部分假设向量匹配空对象。总损失函数定义为:
[0038][0039]
其中yi表示第i个关节点真值,则是第i个关节点所对应假设向量的预测结果,j是关节点分类的数量,li具体指下面公式(3)或(4)中损失函数,在不同的阶段,li不同。
[0040]
在训练阶段,损失取决于分类精度和坐标偏差。本发明采用负概率损失来评估分类,l1损失来计算坐标偏差。因此第i个关节点损失如下:
[0041][0042]
其中cls(i)表示第i个关节点类别,为假设向量的分类概率分布。bi和分别是关节点坐标真值和对应假设向量的坐标预测值。
[0043]
在推断阶段,由于无法得到真值的坐标,只能推断出分类损失,故损失函数如下:
[0044][0045]
除此之外,在关节点分类时,采用最优二分匹配算法,此过程采用匈牙利算法计算损失,如下,分类预测损失改为负对数似然函数,余下部分类似公式(3):
[0046][0047]
因为大多数假设向量匹配导致出现类不平衡,所以本发明减少了对数项的权重来解决这类问题。
[0048]
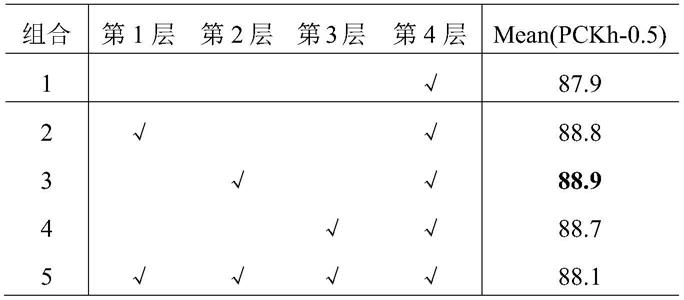
在特征聚合模块融合了多维特征图。本发明提出了一个消融实验,以验证不同cnn层的组合对预测结果的影响。首先,将cnn的输出分为四个部分,分别定义为第1~4层。在这些层中,特征图的分辨率由高到低变化,即第1层分辨率最高,第4层分辨率最低。接下来,在mpii验证集上设置了五组实验,cnn采用resnet101框架,并且输入图像大小为384
×
384。结果如表1所示,√表示候选层。与单层特征图(组合1)相比,多层特征图融合能够捕获更多的空间信息。但当维度信息过多(组合5)时会导致信息冗余,降低了网络的鲁棒性。在两层特征图的组合中,相邻层融合时特征图的分辨率相似(组合4),这种情况下不同层次特征图之间的差异不明显。另一方面,如果两层特征图的分辨率差距过大(组合2),低级特征会被分割成过多的patch,影响后续transformer对全局信息的提取。实验结果表明,第2层特征图和第4层特征图(组合3)是最优的融合选择。
[0049]
表1不同层特征图融合对预测结果的影响
[0050][0051]
本发明实施例中选用coco和mpii数据集。coco是微软团队提供的一个大型数据集,用于人体姿态估计等计算机视觉任务。coco2017分为训练集、验证集和测试集。它拥有20万张图片和2.5万人体标签,每个人体标签包含17个关节点。在解决姿态估计问题时,coco首先对目标进行检测并定位关节点。其次,姿态估计的评价标准参考了该数据集中的目标检测标准。它使用oks(object keypoint similarity)来评价关节点真值和预测值之间的相似性。本发明中整体网络根据oks结果计算ap(average precision)和ar(average recall)。mpii是评估人体姿态估计结果的另一个数据集。它包含28000多个训练样本。评价采用pck度量标准。
[0052]
在数据准备阶段,本发明使用detr来检测人体边界框。coco的原始图像为384
×
288,按照人体边界框切成块,再扩展成相同大小的单人图像。数据增强包括如下方式:随机旋转([-40
°
,40
°
]),随机比例([0.7,1.3])和翻转。除了将图像分辨率设置为384
×
384之外,mpii数据预处理过程与coco一致。transformer超参数配置如下:编码器、解码器和注意力head的数量分别为6、6、8,假设向量的数量设置为100。cnn使用为resnet101或resnet152,优化器为adamw。此外,本发明将cnn的初始学习率设置为1
×
10-5
,权重衰减的学习率则是1
×
10-4
。在200个训练周期中采用了多阶段学习率。将coco在第120和140轮中学习率减半。同样,在mpii的第130个轮次时也降低学习率。在测试阶段,本发明对coco和mpii使用调谐的人体检测器(在coco val2017上使用ap 50.2)的人体检测结果。
[0053]
本发明实验环境使用ubuntu20,编程语言为python,模型框架应用pytorch。整个实验在英伟达rtx 2080上完成。实验结果如图4以及表2-4所示。图4中第一列为gt为关节点真值,第二列是prtr实验结果,第三列是本发明方法的检测结果。由图4可以看出,采用本发
明方法得出的关节点与真值更接近,而且对于遮挡部分关节点也能比较准确地检测出。
[0054]
表2在coco验证集上本发明与其他方法预测结果对比
[0055][0056]
表2显示了在coco验证集上本发明与其他方法的预测结果对比。resnet-101框架在基于回归的方法中具有良好的性能。采用本发明方法ap达到了71.5%,比使用resnet-101的prtr高1.4%。类似地,与pointsetnet
+
相比,实验结果有了显著的改进。
[0057]
表3在coco测试集上本发明与其他方法预测结果对比
[0058][0059]
表3给出了在coco测试集上本发明与其他方法的预测结果对比。可见,采用本发明方法在coco测试集上的ap为70.2%,与相同主干网络的prtr比仍然高1.4%。directpose和integral的ap分别仅为63.3%和67.8%。另外本发明方法的ar是77.6%,比prtr高1%。
[0060]
表4在mpii验证集上本发明与其他方法预测结果对比
[0061][0062]
mpii验证集的结果如表4所示。使用resnet-101作为主干网络时,prtr的腕关节(英文缩写为wri)pckh-0.5评分为82.4%,踝关节(英文缩写为ank)为77.4%。本发明方法在相同条件下的得分分别是83.5%(1.1%
↑
)和79.1%(1.7%
↑
)。当采用resnet-152置换主干网络时,prtr的腕部和踝关节prtr的pckh-0.5评分分别为82.6%和78.4%。本发明方法在相同条件下的得分分别是84.2%(1.6%
↑
)和79.9%(1.5%
↑
)。与躯干关节相比,该方法对终端关节的预测结果有更大的改进。具体实验数据如图4所示。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1