面向深度神经网络的自然语言处理模型测试用例约简方法
1.本发明涉及软件测试技术中的软件测试优化技术领域,尤其涉及一种面向深度神经网络的自然语言处理模型测试用例约简方法,尤其是涉及一种面向深度神经网络的自然语言处理模型测试优化的函数。
背景技术:
2.软件测试对于软件开发至关重要,是保证软件质量和可靠性的重要手段,软件测试优化技术是软件测试的重要组成部分,通过不同的测试优化技术可以帮助测试人员快速查找缺陷,减少资源的占用,旨在极大提升测试效率,降低测试成本。
3.软件测试优化技术主要有三种方法,测试用例排序,测试用例选择和测试用例约简。测试用例选择通过筛选得到一个与原始测试集测试功能相同的小测试集来实现测试优化。测试用例排序是将使软件出错可能性大的测试用例往前排,帮助测试人员尽快发现缺陷。测试用例约简,则通过去掉冗余测试用例,把容易使算法出错的测试用例集中在一个小的测试集中,来提升测试效率并削减测试成本。
4.现有的面向深度神经网络的测试优化方法研究的大多为非文本形式的数据,但是自然语言数据的特殊性要求模型具有更强的信息提取能力,导致基于深度神经网络的自然语言处理技术与其他深度神经网络技术之间存在较大差异。因此不能直接将现有的测试优化方法直接用在这类模型上,需要结合文本数据和这类模型的特征找到一种专门适用于基于深度神经网络的自然语言处理技术模型的测试优化方法。此外,由于文本数据本身的模糊性和不规范性等特点,使文本数据具有更高的标记成本和更少的带标记样本,在对nlp领域的测试优化工作中削弱这部分成本是具有实际意义的。找到一种专门适用于nlp的深度神经网络测试优化方法和在测试优化工作中减少对文本数据的标记成本是测试优化工作现阶段面临的两个主要问题。
5.自然语言由人来编辑,使自然语言具有主观性,不准确性和不规范性等特征,而且相比于图片数据包含更丰富的信息,这就要求基于深度神经网络的自然语言处理模型具有更强大的信息提取能力。基于深度神经网络的自然语言处理模型会提取文本中包含的丰富信息,输出一个分布式的向量表征,这是一种稠密的特征向量,每个元素没有具体的含义,但是整体包含了模型提取出来的大量信息。本发明根据文本数据具有的上述特征和这类模型的输出,使用香农熵和基尼不纯度两种策略筛选测试用例中更容易使模型出错的测试用例,实现面向深度神经网络自然语言处理模型的测试用例约简的工作。
6.自然语言由人编辑,使数据本身具有主观性、模糊性和不规范性,当文本中包含过多冗余信息时,会因为信息过度混乱导致模型在提取文本的重要信息时出错。基尼不纯度是一种衡量系统混乱程度的标准,本发明使用它来衡量模型提取的文本的向量集合的混乱程度,即衡量文本包含信息的混乱程度。混乱程度越高,测试用例被分错的可能性越大。此外,如果文本包含的信息不够充分,也会因为信息不足使模型无法明确文本的重要信息,导致模型出错。香农熵衡量一条信息的信息量大小,信息量越大则信息的确定性越强,越不容
易使模型出错。基于这种思想,我们使用香农熵来衡量测试用例被错误分类的可能性大小,熵越小则文本不确定性就越小,越不容易被分错。
技术实现要素:
7.本发明的一个目的是:为了提高基于深度神经网络的自然语言处理模型的测试效率,降低测试成本,本发明提出一种面向深度神经网络的自然语言处理模型测试优化的函数,用来衡量测试用例被分错可能性大小。本发明结合模型输出特征向量和文本数据的特征,分别使用基尼不纯度和香农熵定义了衡量测试用例被错误分类可能性大小的函数,本发明首先分别依据这两个函数对测试用例排序,将被模型错误分类可能性大的测试用例往前排。
8.本发明的另一个目的是:依据香农熵去掉测试集中冗余的测试用例,实现面向深度神经网络自然语言处理模型的测试用例约简。我们将整个测试用例集作为一个大的集合,每个测试用例作为集合的单个元素,我们将每个测试用例被错误分类的评价函数做为每个元素所携带的信息,通过香农熵来衡量前k个测试用例被错误分类的确定性大小。熵值越小,测试用例集合被错误分类的确定性越强,我们通过调整香浓熵的阈值来自动划分所截取的测试集集合。
9.本发明的技术方案是:一种面向深度神经网络的自然语言处理技术测试用例约简方法,包括以下步骤:
10.步骤1)、明确待测试的模型,并使用原始数据对基于深度神经网络的自然语言处理模型进行训练;
11.步骤2)、使用步骤1)训练好的模型提取原始测试集的特征向量,并将提取的文本数据的特征向量存储在xlsx文件中;
12.其中,dnn的不同层代表不同类型的输入特征。越接近输入层的层代表更多的基本特征,即测试输入本身和从测试输入中提取的基本特征。越接近输出层的层代表更多的高阶特征,更高阶的特征可以更精确地捕捉输入和标签之间的关系。我们在这里取最后隐藏层特征,即dnn中最后隐藏层的输出,是可以直接推断输入的预测结果的高阶特征。
13.步骤3)、定义评价函数对文本数据测试用例进行排序,评价函数值越大表示测试用例被错误分类的可能性越大,我们将评价函数值大的测试用例依次向前排;所述的评价函数为基于基尼不纯度定义的评价函数或基于香农熵定义的评价函数;
14.所述的基尼不纯度定义的评价函数为:
[0015][0016]
所述的基于香农熵定义的评价函数为:
[0017][0018]
其中p
t,i
为特征向量中每个元素,n为特征向量中包含的元素数量,t为每个元素所处的行,i为每个元素所处的列。m为需要设置的参数值,ξ(t)为基于基尼不纯度定义的评价函数的函数值,h(p)为基于香农熵定义的评价函数的函数值。
[0019]
进一步的,本发明方法还包括:
[0020]
步骤4)、将所有测试用例作为一个集合,每个测试用例的评价函数值作为一条信
息,使用香农熵来衡量前k个测试用例被错误分类的确定性,依据设定的参数m和阈值,自动截取所需要测试集的大小。所述的阈值为前k个测试用例被错误分类评价值增长量的大小,设置参数m范围,其中参数m对不同模型的有效范围不同,例如对于模型bert,参数m在两种排序指标下的有效范围分别为[70,100]和[270,340],阈值范围在[0,2]即可得到优化后即简约后的测试集;
[0021]
进一步的,本发明方法还包括:
[0022]
步骤5)、在步骤4)得到的测试用例约简后的测试集,将这部分数据集重新整理成文本形式的测试集,再一次测试模型,并借助约简后的测试集的准确性下降率来评估方法的有效性。
[0023]
本发明提出的一种面向深度神经网络的自然语言处理模型的测试用例约简方法,与现有面向深度神经网络的测试用例约简技术相比较,其优点在于:已有的基于深度神经网络的测试优化工作集中在计算机视觉领域,缺少面向自然语言处理领域的深度神经网络的测试优化技术,尤其是在狭义的范畴上,还没有针对文本数据的测试优化技术研究。本发明专门针对基于深度神经网络自然语言处理技术的模型提出了一种测试用例约简方法。并且本发明从所使用文本数据独有的特征出发,定义了衡量测试用例被错误分类可能性大小的函数。随着基于深度神经网络自然语言处理技术模型的普及,可以有效提升这类模型的测试效率,削减测试成本,本发明的提出具有实际意义。
附图说明
[0024]
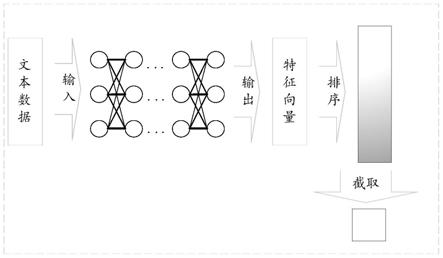
图1面向深度神经网络自然语言处理模型测试用例约简方法流程框图
具体实施方式
[0025]
下面结合附图对本发明作近一步说明。以下将结合附图1,对本发明的技术方案进行详细说明,一种面向深度神经网络的自然语言处理模型的测试用例约简方法,其具体实施步骤如下:
[0026]
1、明确目标模型和数据集,使用数据集对模型进行训练。本发明是一种测试用例集约简方法,目标模型的测试集为待测试优化的目标。为了提取目标数据集的特征向量,在确定好目标模型和使用的数据集后,使用现有的技术划分原始数据集对模型进行训练。将数据集划分出训练集、校验集和原始测试集,使用训练集和校验集对目标模型进行训练。得到训练好的待测目标模型。
[0027]
2、使用训练好的模型,得到原始数据集的特征向量表示。将原始测试用例集输入到训练好的模型中,本发明在模型结构最后隐藏层之后编辑代码,提取模型结构最后隐藏层输出的特征向量。最后隐藏层输出,提取了丰富的文本信息存储在特征向量中,这是一种稠密的特征向量,每个元素没有特定含义,但是整体却包含了文本数据中包含的大量信息。这种稠密的特征向量包含的信息越丰富,就可以和文本数据建立更密切的联系。
[0028]
其中,dnn的不同层代表不同类型的输入特征。越接近输入层的层代表更多的基本特征,即测试输入本身和从测试输入中提取的基本特征。越接近输出层的层代表更多的高阶特征,更高阶的特征可以更精确地捕捉输入和标签之间的关系。我们在这里取最后隐藏层特征,即dnn中最后隐藏层的输出,是可以直接推断输入的预测结果的高阶特征。
[0029]
3、对测试用例进行排序。在抽取出特征向量的基础上,我们使用基于基尼不纯度或者基于香农熵的评价函数来衡量测试用例被错误分类的可能性大小,并依据被错误分类可能性大小对测试用例排序。上述对测试用例排序的评价函数分别为公式(1)和公式(2)。
[0030][0031][0032]
其中p
t,i
为特征向量中每个元素,m为我们需要设置的参数值,ξ(t)为基于基尼不纯度定义的评价函数的函数值,h(p)为基于香农熵定义的评价函数的函数值。
[0033]
4、基于香农熵截取测试集。在对测试用例进行排序之后,我们将容易使模型出错的测试用例往前排。之后我们以每一条测试用例出错的概率为信息,使用香农熵来截取从第1个到第k个测试用例,依据设定的参数m和阈值,自动截取所需要测试集的大小。所述的阈值为前k个测试用例被错误分类评价值增长量的大小,设置参数m范围,其中参数m对不同模型的有效范围不同,例如对于模型bert,参数m在两种排序指标下的有效范围分别为[70,100]和[270,340],香农熵足够小时,说明集合中包含的测试用例使模型出错的确定性更强,本发明将香浓熵阈值范围在[0,2]时视为足够小。针对两种排序方法,计算公式分别如式3和
[0034]
式4:
[0035][0036][0037]
其中α为熵值,ξk为第k个测试用例基于公式(1)得到的衡量值,hk(p)为第k个测试用例基于公式(2)得到的衡量值。我们依据香农熵足够小的阈值范围,根据公式(3)和公式(4)来分别截取两种排序策略下的前k个测试用例来作为约简后的测试集。
[0038]
5、将优化后得到的测试集输入模型验证方法的有效性。将步骤4得到的约简后的测试用例输入到目标模型中,使用更小的测试集检测目标模型存在的缺陷。本发明的目的是为了通过测试用例约简去除冗余的测试用例,将容易使模型出错的测试用例集中在更小的测试集中,使用准确率和准确率下降率来衡量测试用例约简的实验效果。定义如下:
[0039][0040][0041]
其中true positive(tp)为预测为正例,实际为正例;false positive(fp)为预测为正例,实际为负例;true negative(tn)为预测为负例,实际为负例;false negative(fn)为预测为负例,实际为正例。原始准确率为原始测试集得到的分类结果的准确率,准确率为测试约减策略得到的小测试集上得到的测试准确率。
[0042]
实施例:
[0043]
本发明在bert模型上进行了实验,实验结果如表1和表2。
[0044]
表1 bert基于基尼不纯度实验结果
[0045][0046][0047]
表1记录了bert模型基于基尼不纯度的实验结果,原始测试集准确率为77.34%,参数m在70到100之间取不值,间隔为10。当m取值为70时,准确率下降为33.24%,下降率最大为57.02%。当m为100时,准确率下降为61.67%,下降率最小为20.26%。所用时间也从原始的5秒减少到0秒。原始测试集大小为11968个测试用例,我们的方法在下降率最大的情况下将数据集缩减为了311个,实验结果证明本发明是有效的。
[0048]
表2 bert基于香农熵实验结果
[0049][0050]
表2记录了bert模型基于香农熵的实验结果,原始测试集准确率为77.34%,参数m在270到345之间取不值,间隔为5。当参数m为270时,准确率为77.41%,此时测试集的大小没有被缩减,而且准确率数值有微小的增长。当参数m取值为345时,准确率下降为42.60%,下降率最大为44.92%。所用时间也从原始的5秒减少到0秒。原始测试集大小为11968个测试用例,本发明在下降率最大的情况下将数据集缩减为了223个。实验结果证明基于香农熵对测试用例进行排序完成测试用例约简的方法对模型bert是有效的。
[0051]
以上内容对本发明所述面向深度神经网络的自然语言处理模型测试用例约简方法进行了详细的说明,但显然本发明的具体实现形式并不局限于此。对于本技术领域的一般技术人员来说,在不背离本发明的精神和权利要求范围的情况下对它进行的各种显而易见的改变都在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1