一种交通车辆单目定位方法、装置、设备及存储介质与流程
1.本发明属于驾驶辅助技术领域,具体地涉及一种交通车辆单目定位方法、装置、设备及存储介质。
背景技术:
2.如今,3d重建技术是计算机视觉方向上的一个火热研究领域。从2d平面图像到3d立体空间,不仅仅是普通的尺度变换,它还涉及到深度的估计,这在目前是比较困难的,因为相机成像过程就是一个将3d空间坐标转化成图像2d坐标的过程,而如果从2d坐标反推回3d坐标的话,会出现一个问题,即从图像坐标系到相机坐标系的过程中有一个尺度因子s没办法确定,因为2d图像是不涉及深度的概念。
3.现在人们对智能化要求越来越高,为了防止交通事故的频频出现,基于3d重建技术对交通车辆进行实时定位是一项有效的驾驶辅助手段。然而在3d重建技术中,传统的深度估计方法要么是基于双目摄像头,要么是基于与雷达的结合,硬件成本比较高。此外,在3d重建技术上比较常用的是slam(simultaneous localization and mapping,同步定位与建图)方法,此方法在机器人领域发展非常好,但slam技术需要大量计算,不能满足低算力的边缘设备实现要求,因此不适合应用在车载计算机中。
技术实现要素:
4.为了解决现有交通车辆定位技术中所存在硬件成本高和算力要求高的问题,本发明目的在于提供一种交通车辆单目定位方法、装置、计算机设备及计算机可读存储介质,能够仅需与单目相机相结合即可实现深度估计,大幅度降低硬件成本,并且无需采用slam方法,可降低对算力要求,利于快速得到定位结果,特别适合应用在车载计算机中,便于实际应用和推广。
5.第一方面,本发明提供了一种交通车辆单目定位方法,包括:获取单目相机采集的监控图像;采用目标检测算法对所述监控图像进行交通车辆检测处理,得到至少一个目标车辆;针对所述至少一个目标车辆中的各个目标车辆,根据对应的且检测得到的车辆图像标记框,获取对应的且在所述监控图像中的车辆大小特征信息;针对所述各个目标车辆,将对应的车辆大小特征信息作为待测样本输入基于深度学习算法的且已完成训练的距离分类模型,得到对应的距离分类结果;针对所述各个目标车辆,根据对应的距离分类结果,确定出对应的所在位置。
6.基于上述发明内容,提供了一种基于目标检测算法和深度学习算法的单目视觉定位方案,即在获取到单目相机采集的监控图像后,可先通过目标检测算法发现所述监控图像中的目标车辆,并得到目标车辆在所述监控图像中的车辆大小特征信息,然后将该车辆大小特征信息作为待测样本输入基于深度学习算法的且已完成训练的距离分类模型,得到
距离分类结果,最后将该距离分类结果作为深度估计结果,确定出目标车辆的所在位置,从而仅需与单目相机相结合即可实现深度估计,大幅度降低硬件成本,并且无需采用slam方法,可降低对算力要求,利于快速得到定位结果,特别适合应用在车载计算机中,便于实际应用和推广。
7.在一个可能的设计中,所述目标检测算法采用基于yolov3-tiny网络的改进型网络,其中,所述改进型网络在所述yolov3-tiny网络的基础上进行了如下改动:在所述yolov3-tiny网络中将过滤器数量减少三分之一,同时从所述yolov3-tiny网络的第5卷积层中抽出形状为64*26*26的第一特征图,并经过卷积上采样将该第一特征图转变成形状为64*52*52的第二特征图,以及对于所述yolov3-tiny网络中的且形状为256*13*13的第三特征图,经过上采样和1*1的卷积核转换成形状为64*26*26的第四特征图,然后将该第四特征图与所述yolov3-tiny网络中第7卷积层的且形状为128*26*26的第五特征图融合,得到形状为192*26*26的第六特征图,并通过上采样将该第六特征图转换成形状为128*52*52的第七特征图,再然后将所述第二特征图与所述第七特征图进行特征融合,得到192*52*52的第八特征图,最后将所述第八特征图经过步长为1的卷积网络送入新增的且输出形状为52*52的第三yolo输出层。
8.在一个可能的设计中,采用目标检测算法对所述监控图像进行交通车辆检测处理,得到至少一个目标车辆,包括:根据预先划定的感兴趣区域roi,对所述监控图像中的所述感兴趣区域roi,采用目标检测算法进行交通车辆检测处理,得到至少一个目标车辆。
9.在一个可能的设计中,采用目标检测算法对所述监控图像进行交通车辆检测处理,得到至少一个目标车辆,包括:根据所述监控图像的图像信息,进行采集环境判断;根据采集环境判定结果,采用传统图像处理方式和/或深度学习方式对所述监控图像进行增强处理,得到还原图像边界信息的新图像,其中,所述传统图像处理方式包括有图像形态学操作方式、直方图均衡化方式和/或图像增强方式,所述深度学习方式采用卷积神经网络cnn或对抗神经网络gan;采用目标检测算法对所述新图像进行交通车辆检测处理,得到至少一个目标车辆。
10.在一个可能的设计中,针对所述各个目标车辆,根据对应的距离分类结果,确定出对应的所在位置,包括:针对所述各个目标车辆,根据对应的距离分类结果以及对应的且在所述监控图像中的二维坐标,基于相机标定结果进行2d到3d的转换处理,得到对应的三维坐标。
11.在一个可能的设计中,所述相机标定结果为采用张正友棋盘格标定法获取的相机内外参数。
12.在一个可能的设计中,在针对所述各个目标车辆,根据对应的距离分类结果,确定出对应的所在位置之后,所述方法还包括:针对所述各个目标车辆,根据对应的所在位置,确定出对应的当前车距和/或当前危险等级,其中,当前危险等级与当前车距负相关;向车载显示屏传送驾驶辅助画面,其中,所述驾驶辅助画面包含有所述监控图像
以及所述各个目标车辆的当前车距和/或当前危险等级。
13.第二方面,本发明提供了一种交通车辆单目定位装置,包括有依次通信连接的图像获取模块、目标检测模块、特征提取模块、距离分类模块和位置确定模块;所述图像获取模块,用于获取单目相机采集的监控图像;所述目标检测模块,用于采用目标检测算法对所述监控图像进行交通车辆检测处理,得到至少一个目标车辆;所述特征提取模块,用于针对所述至少一个目标车辆中的各个目标车辆,根据对应的且检测得到的车辆图像标记框,获取对应的且在所述监控图像中的车辆大小特征信息;所述距离分类模块,用于针对所述各个目标车辆,将对应的车辆大小特征信息作为待测样本输入基于深度学习算法的且已完成训练的距离分类模型,得到对应的距离分类结果;所述位置确定模块,用于针对所述各个目标车辆,根据对应的距离分类结果,确定出对应的所在位置。
14.第三方面,本发明提供了一种计算机设备,包括有依次通信连接的存储器、处理器和收发器,其中,所述存储器用于存储计算机程序,所述收发器用于收发信息,所述处理器用于读取所述计算机程序,执行如第一方面或第一方面中任意可能设计所述的交通车辆单目定位方法。
15.第四方面,本发明提供了一种计算机可读存储介质,所述计算机可读存储介质上存储有指令,当所述指令在计算机上运行时,执行如上第一方面或第一方面中任意可能设计所述的交通车辆单目定位方法。
16.第五方面,本发明提供了一种包含指令的计算机程序产品,当所述指令在计算机上运行时,使所述计算机执行如上第一方面或第一方面中任意可能设计所述的交通车辆单目定位方法。
附图说明
17.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
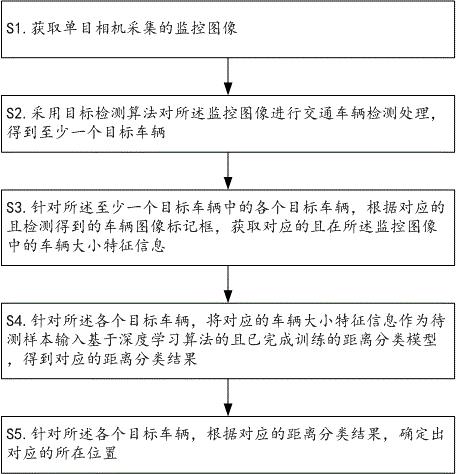
18.图1是本发明提供的交通车辆单目定位方法的流程示意图。
19.图2是本发明提供的感兴趣区域roi的划定示例图。
20.图3是本发明提供的基于yolov3-tiny网络的改进型网络示意图。
21.图4是本发明提供的对监控图像进行增强处理的流程示意图。
22.图5是本发明提供的驾驶辅助画面的示例图。
23.图6是本发明提供的交通车辆单目定位装置的结构示意图。
24.图7是本发明提供的计算机设备的结构示意图。
具体实施方式
25.下面结合附图及具体实施例来对本发明作进一步阐述。在此需要说明的是,对于这些实施例方式的说明虽然是用于帮助理解本发明,但并不构成对本发明的限定。本文公开的特定结构和功能细节仅用于描述本发明示例的实施例。然而,可用很多备选的形式来体现本发明,并且不应当理解为本发明限制在本文阐述的实施例中。
26.应当理解,尽管本文可能使用术语第一和第二等等来描述各种对象,但是这些对象不应当受到这些术语的限制。这些术语仅用于区分一个对象和另一个对象。例如可以将第一对象称作第二对象,并且类似地可以将第二对象称作第一对象,同时不脱离本发明的示例实施例的范围。
27.应当理解,对于本文中可能出现的术语“和/或”,其仅仅是一种描述关联对象的关联关系,表示可以存在三种关系,例如,a和/或b,可以表示:单独存在a、单独存在b或者同时存在a和b等三种情况;对于本文中可能出现的术语“/和”,其是描述另一种关联对象关系,表示可以存在两种关系,例如,a/和b,可以表示:单独存在a或者同时存在a和b等两种情况;另外,对于本文中可能出现的字符“/”,一般表示前后关联对象是一种“或”关系。
28.如图1~3所示,本实施例第一方面提供的所述交通车辆单目定位方法,可以但不限于由具有一定计算资源的计算机设备执行,例如由车载计算机(也叫车载电脑,是一种高科技的压缩技术集成化的车用多媒体娱乐信息中心,很多汽车已经配备了类似的智能车载系统,其主要功能包括车载全能多媒体娱乐,最清晰详尽的gps卫星导航,对汽车信息和故障专业诊断,移动性的办公与行业应用等)、个人计算机(personal computer,pc,指一种大小、价格和性能适用于个人使用的多用途计算机;台式机、笔记本电脑到小型笔记本电脑和平板电脑以及超级本等都属于个人计算机)、智能手机、个人数字助理(personal digital assistant,pad)或可穿戴设备等电子设备执行,以便在获取到单目相机采集的监控图像后,可先通过目标检测算法发现所述监控图像中的目标车辆,并得到目标车辆在所述监控图像中的车辆大小特征信息,然后将该车辆大小特征信息作为待测样本输入基于深度学习算法的且已完成训练的距离分类模型,得到距离分类结果,最后将该距离分类结果作为深度估计结果,确定出目标车辆的所在位置,从而仅需与单目相机相结合即可实现深度估计,大幅度降低硬件成本,并且无需采用slam方法,可降低对算力要求,利于快速得到定位结果,特别适合应用在车载计算机中,便于实际应用和推广。如图1所示,所述交通车辆单目定位方法,可以但不限于包括有如下步骤s1~s5。
29.s1.获取单目相机采集的监控图像。
30.在所述步骤s1中,所述单目相机可以但不限于为安装在车体上的常规单目摄像头,其硬件成本远低于双目摄像头或雷达等。当所述单目相机安装在车体前部并使镜头视野涵盖车前区域时,所采集得到的实时监控图像可示例如图2所示。
31.s2.采用目标检测算法对所述监控图像进行交通车辆检测处理,得到至少一个目标车辆。
32.在所述步骤s2中,所述目标检测算法是一种用于在图片中将里面的物体检测出来且标记出物体位置的现有人工智能识别算法,具体可以但不限于采用faster r-cnn(faster regions with convolutional neural networks features,由何凯明等在2015年提出目标检测算法,该算法在2015年的ilsvrv和coco竞赛中获得多项第一)网络、ssd
(single shot multibox detector,单镜头多盒检测器,是wei liu在eccv 2016上提出的一种目标检测算法,是目前流行的主要检测框架之一)网络或yolo(you only look once,目前最新已经发展到v4版本,在业界的应用也很广泛,其基本原理是:首先对输入图像划分成7x7的网格,对每个网格预测2个边框,然后根据阈值去除可能性比较低的目标窗口,最后再使用边框合并的方式去除冗余窗口,得出检测结果)网络等。因此通过常规的样本训练方式,可以得到基于所述目标检测算法的且用于根据输入图像检测是否有交通车辆的交通车辆检测模型,以便在输入待测的所述监控图像后,可以输出对应的检测结果以及置信度预测值等信息。此外,所述交通车辆检测模型可在完成训练后,植入车载计算机等边缘设备,以便降低对计算机设备的算力需求。
33.在所述步骤s2中,由于是在车载计算机等边缘设备上进行交通车辆检测处理,而yolov3网络又是由106层网络结构构建起来的,因此考虑边缘设备存在性能有限的问题,所述目标检测算法优先采用yolov3网络的简化版—yolov3-tiny网络,其在所述yolov3网络的基础上去掉了一些特征层,只保留了2个独立预测分支,即在所述yolov3-tiny网络中,共有两个输出层(yolo层),分别为13*13和26*26,每个网格可以预测3个边框bounding box,共有80个分类数,所以最后的两yolo层的尺寸为:13*13*255和26*26*255。所述yolov3-tiny网络共有23层,其中包含五种不同的网络层:卷积层convolutional(13个)、池化层maxpool(6个)、路由层route(2个)、上采样层upsample(1个)和输出层yolo(2个)。此外,在所述yolov3-tiny网络中,除了yolo输出层之前的那个卷积层,每个卷积层之后都有bn(batch normalization,批量归一化)层,且每个卷积层之后都有激活函数leaky(即yolo输出层之前是线性的)。
34.在所述步骤s2中,本实施例进一步考虑所述yolov3-tiny网络只有23层,由于网络层数很浅,便有一个明显的缺点,那就是对小目标检测效果不够精确,泛化能力差,若又减少了滤波器,加上最大池化层,将导致丢失的信息太多,即使增加样本数量,loss和map都没有太大的改善效果。因此优选的,如图3所示,所述目标检测算法采用基于yolov3-tiny网络的改进型网络,其中,所述改进型网络在所述yolov3-tiny网络的基础上进行了如下改动:在所述yolov3-tiny网络中将过滤器数量减少三分之一,同时从所述yolov3-tiny网络的第5卷积层中抽出形状为64*26*26的第一特征图,并经过卷积上采样将该第一特征图转变成形状为64*52*52的第二特征图,以及对于所述yolov3-tiny网络中的且形状为256*13*13的第三特征图,经过上采样和1*1的卷积核转换成形状为64*26*26的第四特征图,然后将该第四特征图与所述yolov3-tiny网络中第7卷积层的且形状为128*26*26的第五特征图融合,得到形状为192*26*26的第六特征图,并通过上采样将该第六特征图转换成形状为128*52*52的第七特征图,再然后将所述第二特征图与所述第七特征图进行特征融合,得到192*52*52的第八特征图,最后将所述第八特征图经过步长为1的卷积网络送入新增的且输出形状为52*52的第三yolo输出层(即作为所述改进型网络中的第33层)。如此在所述改进型网络中,既可通过缩减卷积通道的数目,将原来的通道数减少,从而使得所述交通车辆检测模型的大小可缩减56.2%,又能增加检测尺度,以便更好地检测小目标,达到在高精度要求情况下,使得检测速度提高40%以上。此外,还可进一步采用合适的方法对小目标进行聚类中心重筛选,以便在一定程度上提高所述交通车辆检测模型的检测精度和重叠度iou(intersection over union)值。
35.在所述步骤s2中,为了进一步降低后续计算量,滤除杂物的出现,确保数据的质量以及后续的模型准确性,可先找到合适的roi(region of interest,感兴趣区域)区域,然后在该感兴趣区域roi中采用目标检测算法进行交通车辆检测处理,即采用目标检测算法对所述监控图像进行交通车辆检测处理,得到至少一个目标车辆,包括但不限于:根据预先划定的感兴趣区域roi,对所述监控图像中的所述感兴趣区域roi,采用目标检测算法进行交通车辆检测处理,得到至少一个目标车辆。由于所述单目相机是固定安装的,所述预先划定的感兴趣区域roi在所述监控图像中的位置是固定的,如图2所示的线框区域,通过仅对所述监控图像中的所述感兴趣区域roi采用目标检测算法进行交通车辆检测处理,可以减少干扰区域的出现,例如图2所示的两侧区域。
36.s3.针对所述至少一个目标车辆中的各个目标车辆,根据对应的且检测得到的车辆图像标记框,获取对应的且在所述监控图像中的车辆大小特征信息。
37.在所述步骤s3中,由于采用目标检测算法的交通车辆检测结果还会有车辆图像标记框等信息,因此可根据该车辆图像标记框得到目标车辆在所述监控图像中的车辆大小特征信息,例如将车辆图像标记框的大小作为车辆大小,等等。此外,所述车辆大小特征信息还可以包含但不限于有从所述监控图像中截取出的目标车辆图像。
38.s4.针对所述各个目标车辆,将对应的车辆大小特征信息作为待测样本输入基于深度学习算法的且已完成训练的距离分类模型,得到对应的距离分类结果。
39.在所述步骤s4中,所述深度学习算法是机器学习(其是实现人工智能的必经路径)的一种,深度学习概念源于人工神经网络的研究,含多个隐藏层的多层感知器就是一种深度学习结构,因此深度学习可通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征表示。典型的且基于深度学习算法的模型有卷积神经网络(convolutional neural network)模型、贝叶斯概率生成模型和堆栈自编码网络(stacked auto-encoder network)模型等,因此在设置距离类型(例如1米、2米、3米和4米等距离类型)与车辆大小特征信息样本的关联关系后,可通过常规的样本训练方式,得到用于根据输入数据识别出对应距离类型的所述距离分类模型,以便在输入所述车辆大小特征信息后,可以输出对应的距离分类结果以及置信度预测值等信息。此外,所述距离分类模型也可在完成训练后,植入车载计算机等边缘设备,以便降低对计算机设备的算力需求。
40.s5.针对所述各个目标车辆,根据对应的距离分类结果,确定出对应的所在位置。
41.在所述步骤s5中,由于所述距离分类结果即为在所述监控图像中对相应目标车辆的深度估计结果,因此可根据该深度估计结果和在所述监控图像中的2d坐标反推得到目标车辆在相机坐标系下的3d空间坐标,确定出所述各个目标车辆在所述相机坐标系下的所在位置,以便用于驾驶辅助方案。具体的,针对所述各个目标车辆,根据对应的距离分类结果,确定出对应的所在位置,包括但不限于:针对所述各个目标车辆,根据对应的距离分类结果以及对应的且在所述监控图像中的二维坐标,基于相机标定结果进行2d到3d的转换处理,得到对应的三维坐标。所述相机标定结果即是获取到所述单目相机的相机内外参数,所涉及到的原理如下(a)~(c)点。
42.(a)世界坐标系转换到相机坐标系:
(b)相机坐标系转化到图像坐标系:(c)图像坐标系转化到像素坐标系:简单来讲,就是从世界坐标系到图像坐标系的转化,首先从世界坐标系经过旋转矩阵和平移向量到z轴与相机光轴重合,x和y轴相互垂直的相机坐标系,也就是相机的外参[r,t];接着利用小孔成像原理从相机坐标系下映射到图像坐标系下,即z=f(焦距)所在的2d平面,f与平面焦点即为图像坐标系的原点,此变换主要是尺度变换;最后是从图像坐标系转化到像素坐标系(笛卡尔坐标系,这是一图像左上角为坐标原点的坐标系),从相机坐标系到像素坐标系的转化参数为相机的内参。优选的,所述相机标定结果为采用张正友棋盘格标定法获取的相机内外参数,其中,所述张正友棋盘格标定法是一种常用来计算相机内外参数的相机标定方法,其也可以计算出相机的镜头的畸变参数,从而进行矫正。
[0043]
由此基于前述步骤s1~s5所描述的交通车辆单目定位方法,提供了一种基于目标检测算法和深度学习算法的单目视觉定位方案,即在获取到单目相机采集的监控图像后,可先通过目标检测算法发现所述监控图像中的目标车辆,并得到目标车辆在所述监控图像中的车辆大小特征信息,然后将该车辆大小特征信息作为待测样本输入基于深度学习算法的且已完成训练的距离分类模型,得到距离分类结果,最后将该距离分类结果作为深度估计结果,确定出目标车辆的所在位置,从而仅需与单目相机相结合即可实现深度估计,大幅度降低硬件成本,并且无需采用slam方法,可降低对算力要求,利于快速得到定位结果,特别适合应用在车载计算机中。此外,在目标检测算法中通过基于yolov3-tiny网络的改动应用,既可通过缩减卷积通道的数目,将原来的通道数减少,从而使得交通车辆检测模型的大小可缩减56.2%,又能增加检测尺度,以便更好地检测小目标,达到在高精度要求情况下,使得检测速度提高40%以上,便于实际应用和推广。
[0044]
本实施例在前述第一方面的技术方案基础上,还提供了一种在交通车辆检测处理过程中对监控图像进行预处理的可能设计一,即如图4所示,采用目标检测算法对所述监控图像进行交通车辆检测处理,得到至少一个目标车辆,包括但不限于有如下步骤s21~s23。
[0045]
s21.根据所述监控图像的图像信息,进行采集环境判断。
[0046]
在所述步骤s21中,由于所述单目相机的图像采集结果会受到很多的环境限制,比如晚上车辆远光灯直射或者阴雨天气造成曝光不足等等一系列情况,都会引起图像细节丢
失,因此可通过常规方式来根据所述监控图像的图像信息,进行采集环境判断,得到采集环境判定结果。
[0047]
s22.根据采集环境判定结果,采用传统图像处理方式和/或深度学习方式对所述监控图像进行增强处理,得到还原图像边界信息的新图像,其中,所述传统图像处理方式包括但不限于有图像形态学操作方式、直方图均衡化方式和/或图像增强方式等,所述深度学习方式采用但不限于卷积神经网络cnn或对抗神经网络gan(generative adversarial networks)等。
[0048]
在所述步骤s22中,所述增强处理的具体方式均为现有常规方式,例如进行直方图均衡化、边缘检测以及膨胀和腐蚀等开闭形态学操作,以便得到还原图像边界信息的新图像,减小环境因素对后续交通目标检测结果的影响。
[0049]
s23.采用目标检测算法对所述新图像进行交通车辆检测处理,得到至少一个目标车辆。
[0050]
由此基于前述步骤s21~s23所描述的可能设计一,可以在交通车辆检测处理过程中先对监控图像进行增强处理,得到还原图像边界信息的新图像,进而可减小环境因素对后续交通目标检测结果的影响,保障目标检测结果的准确性。
[0051]
本实施例在前述第一方面或可能设计一的技术方案基础上,还提供了一种基于定位结果辅助驾驶的可能设计二,即在针对所述各个目标车辆,根据对应的距离分类结果,确定出对应的所在位置之后,所述方法还包括但不限于有如下步骤s61~s62。
[0052]
s61.针对所述各个目标车辆,根据对应的所在位置,确定出对应的当前车距和/或当前危险等级,其中,当前危险等级与当前车距负相关。
[0053]
在所述步骤s61中,所述当前车距是指目标车辆距离所述单目相机或所述单目相机的载体(例如车体)的当前距离,由于所述单目相机或所述载体在相机坐标系中的位置是固定且可以提前获取的,因此可通过常规几何知识,计算得到所述当前车距。此外,由于所述当前车距越近,碰撞的风险越大,因此对应的当前危险等级应越高。
[0054]
s62.向车载显示屏传送驾驶辅助画面,其中,所述驾驶辅助画面包含有所述监控图像以及所述各个目标车辆的当前车距和/或当前危险等级。
[0055]
在所述步骤s62中,通过向所述车载显示屏传送展示所述驾驶辅助画面,如图5所示,即可有效提醒驾驶员注意碰撞风险,避免发生交通事故。此外,在所述当前危险等级达到警报触发条件时,还可以驱动报警装置进行声/光报警,以便更好的提醒驾驶员。
[0056]
由此基于前述步骤s61~s62所描述的可能设计二,通过在驾驶辅助画面展示监控图像以及目标车辆的当前车距和/或当前危险等级,可有效提醒驾驶员注意碰撞风险,避免发生交通事故,实现驾驶辅助目的。
[0057]
如图6所示,本实施例第二方面提供了一种实现第一方面或第一方面中任一可能设计所述的交通车辆单目定位方法的虚拟装置,包括有依次通信连接的图像获取模块、目标检测模块、特征提取模块、距离分类模块和位置确定模块;所述图像获取模块,用于获取单目相机采集的监控图像;所述目标检测模块,用于采用目标检测算法对所述监控图像进行交通车辆检测处理,得到至少一个目标车辆;所述特征提取模块,用于针对所述至少一个目标车辆中的各个目标车辆,根据对
应的且检测得到的车辆图像标记框,获取对应的且在所述监控图像中的车辆大小特征信息;所述距离分类模块,用于针对所述各个目标车辆,将对应的车辆大小特征信息作为待测样本输入基于深度学习算法的且已完成训练的距离分类模型,得到对应的距离分类结果;所述位置确定模块,用于针对所述各个目标车辆,根据对应的距离分类结果,确定出对应的所在位置。
[0058]
本实施例第二方面提供的前述装置的工作过程、工作细节和技术效果,可以参见第一方面或第一方面中任一可能设计所述的交通车辆单目定位方法,于此不再赘述。
[0059]
如图7所示,本实施例第三方面提供了一种执行第一方面或第一方面中任一可能设计所述交通车辆单目定位方法的计算机设备,包括有依次通信连接的存储器、处理器和收发器,其中,所述存储器用于存储计算机程序,所述收发器用于收发信息,所述处理器用于读取所述计算机程序,执行如第一方面或第一方面中任一可能设计所述的交通车辆单目定位方法。具体举例的,所述存储器可以但不限于包括随机存取存储器(random-access memory,ram)、只读存储器(read-only memory,rom)、闪存(flash memory)、先进先出存储器(first input first output,fifo)和/或先进后出存储器(first input last output,filo)等等;所述处理器可以但不限于采用型号为stm32f105系列的微处理器。此外,所述计算机设备还可以但不限于包括有电源模块、显示屏和其它必要的部件。
[0060]
本实施例第三方面提供的前述计算机设备的工作过程、工作细节和技术效果,可以参见第一方面或第一方面中任一可能设计所述的交通车辆单目定位方法,于此不再赘述。
[0061]
本实施例第四方面提供了一种存储包含第一方面或第一方面中任一可能设计所述交通车辆单目定位方法的指令的计算机可读存储介质,即所述计算机可读存储介质上存储有指令,当所述指令在计算机上运行时,执行如第一方面或第一方面中任一可能设计所述的交通车辆单目定位方法。其中,所述计算机可读存储介质是指存储数据的载体,可以但不限于包括软盘、光盘、硬盘、闪存、优盘和/或记忆棒(memory stick)等计算机可读存储介质,所述计算机可以是通用计算机、专用计算机、计算机网络、或者其他可编程装置。
[0062]
本实施例第四方面提供的前述计算机可读存储介质的工作过程、工作细节和技术效果,可以参见第一方面或第一方面中任一可能设计所述的交通车辆单目定位方法,于此不再赘述。
[0063]
本实施例第五方面提供了一种包含指令的计算机程序产品,当所述指令在计算机上运行时,使所述计算机执行如第一方面或第一方面中任一可能设计所述的交通车辆单目定位方法。其中,所述计算机可以是通用计算机、专用计算机、计算机网络、或者其他可编程装置。
[0064]
最后应说明的是,本发明不局限于上述可选的实施方式,任何人在本发明的启示下都可得出其他各种形式的产品。上述具体实施方式不应理解成对本发明的保护范围的限制,本发明的保护范围应当以权利要求书中界定的为准,并且说明书可以用于解释权利要求书。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1