一种融合信息高级特征的命名实体识别方法
1.本发明涉及自然语言处理技术领域,更具体的,涉及一种融合信息高级特征的命名实体识别方法。
背景技术:
2.命名实体识别是一项识别非结构化文本中的实体的任务,比如人物、地点和组织等,在非结构化文本的实体识别中起着举足轻重的作用。根据以前的研究者的研究,命名实体识别已在关系抽取、问答、事件抽取、信息检索和知识图构建等多个场景上得到了广泛的应用。
3.对于词语是自然分离的语言中,比如英语,命名实体识别通常被作为序列标记问题,并在基于深度学习的方法中取得了最先进的结果。与英语相比,中文没有空lattice作为单词的分隔符,因此中文的词语一般通过分词工具和引入外部词典来获得。而在海洋产业等非通用领域中,有很多专业性的词语不能有效地通过分词工具或与外部词典匹配等手段获得,比如“鲸鱼”、“海事景点”、“水下餐厅”,从而造成实体边界模糊,给中文命名实体识别带来了许多困难。
4.为了应对现有技术中存在问题,现有专利公开了一种命名实体的识别方法及装置;其中,该方法包括:利用卷积神经网络模型cnn对文字图像进行信息抽取,得到文字图像中文字对应的字体向量;将字体向量与文字对应的文字向量进行拼接,并根据拼接得到的拼接向量获取特征向量;根据特征向量得到命名实体集,其中,命名实体集中包括多个命名实体;构建与文字图像对应的设问题目,并基于设问题目定位得到需要获取的命名实体。然而现有的专利方法的精度较低,不能够可靠高效地提取命名实体;因此,如何能够发明一种命名实体的识别方法,能够可靠高效地提取命名实体,是本技术领域亟需解决的问题。
技术实现要素:
5.本发明为了解决现有技术不能够可靠高效地提取命名实体的问题,提供了一种融合信息高级特征的命名实体识别方法,其具有计算方便,实用高效的特点。
6.为实现上述本发明目的,采用的技术方案如下:
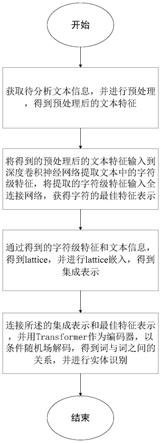
7.一种融合信息高级特征的命名实体识别方法,包括以下具体步骤:
8.s1.得到待分析文本信息,并进行预处理,得到预处理后的文本特征;
9.s2.将得到的预处理后的文本特征输入到深度卷积神经网络提取文本中的字符级特征,将提取的字符级特征输入全连接网络,获得字符的最佳特征表示;
10.s3.通过得到的字符级特征和文本信息,得到lattice,并进行lattice嵌入,得到集成表示;
11.s4.连接所述的集成表示和最佳特征表示,并用transformer作为编码器,
12.以条件随机场进行解码,得到词与词之间的关系,并进行实体识别。
13.优选的,步骤s1,具体为:将得到的文本信息的序列表示为s={c1,c2,
…
,cn},其中
n表示句子长度,ci为句子s中的字符;将输入的句子中的每个字符ci映射为字符向量,公式如下:
14.xi=ec(ci),
15.其中xi为字符向量,ec是一个包含了字符和词语的预训练词向量;由此,得到预处理后的文本特征:
16.x=[x1,x2,
…
,xn]。
[0017]
进一步的,步骤s2,具体步骤为:
[0018]
s201.对得到预处理后的文本特征两端进行填充;
[0019]
s202.使用三个尺寸不同的过滤器扫描填充后的文本特征,并提取第一特征、第二特征、第三特征;
[0020]
s203.分别对所述的第一特征、第二特征、第三特征进行最大池化操作,并将操作后的第一特征、第二特征、第三特征拼接起来得到文本中的字符信息;
[0021]
s204.将得到的文本中的字符信息输入到全连接网络中,并得到字符信息的最佳特征表示xc。
[0022]
更进一步的,步骤s202中三个尺寸不同的过滤器分别为面积为2*50,3*50和4*50的三个过滤器。
[0023]
更进一步的,步骤s3,具体步骤为:
[0024]
s301.将所述的文本序列s的所有子序列分别与现有词典d,用来表示从字符序号b开始到字符序号e结束的子序列,b和e是常数,并得到文本序列s中所有与现有词典d匹配的序列
[0025]
s302.将cw映射为向量:xw=ec(cw),其中ec是一个包含了字符和词语的预训练词向量;
[0026]
s303.将预处理后的文本特征x和向量xw拼接起来,得到latticex
l
,即x
l
=[x,xw];
[0027]
s304.将x
l
输入一个全连接层来获得本特征x和向量xw的集成表示x
l
:
[0028]
x
l
=w
l
x
l
+b
[0029]
其中w
l
是可训练的参数。
[0030]
更进一步的,所述的lattice包括不同长度的span,所述的span之间有三种关系:包含、分离、相交。
[0031]
更进一步的,步骤s4,连接所述的集成表示和最佳特征表示,具体为:将所述的最佳特征表示xc和集成表示x
l
连接,通过线性投影将其转换为原始维度x
in
:
[0032]
x
in
=linear[xc;x
l
]
[0033]
其中,linear表示线性函数。
[0034]
更进一步的,步骤s4中transformer包括两层神经网络,分别是自注意力层和前馈神经网络层;其中所述的自注意力层为多头注意力网络,其多头并行地对输入的序列进行关注,然后将多头的结果连接起来,并再次投影产生最终值;而前馈神经网络是一个多层感知器,由多层连续非线性函数组成;所述的前馈神经网络包括两个线性变换,中间有一个relu激活函数;自注意力子层的输出将被输入前馈神经网络做进一步的处理。
[0035]
更进一步的,所述的自注意力层采用了相对位置编码,具体步骤为:
[0036]
st401.通过头部和尾部信息的连续变换来计算;用head[i]and tail[i]
[0037]
来分别表示lattice中spansxi的头和尾的位置,同时,用四种相对距离来表示spansxi和xj的关系:
[0038][0039][0040][0041][0042]
其中表示spansxi的头和spansxj的头之间的距离,表示spansxi的头和spansxj的尾之间的距离,表示spansxi的尾和spansxj的头之间的距离,表示spansxi的尾和spansxj的尾之间的距离;
[0043]
st402.通过所述的四个距离的非线性变换,得到span的相对位置:
[0044][0045]
其中wr是一个可训练的参数,表示连接运算符,pd计算如下:
[0046][0047][0048]
其中pd即公式10中的p,d是4个距离或者之一,k表示位置编码的维度索引。
[0049]
更进一步的,步骤s4中,以条件随机场进行解码,具体为:
[0050]
sp401.对于给定的文本序列s,创建其对应的其对应的标签序列为y={y1,y2,
…
,yn},y(s)表示所有有效的标签序列;
[0051]
sp402.计算y的概率:
[0052][0053]
其中f(y
i-1
,yi,n)计算从y
i-1
到yi的transition score和yi的分数;
[0054]
sp403.结合所述的y的概率,通过viterbi算法来寻找达到最大概率的路径。
[0055]
本发明的有益效果如下:
[0056]
本发明提供了一种融合信息高级特征的命名实体识别方法,本发明通过深度卷积神经网络得到的字符级特征和文本信息,得到lattice,提取的字符级特征和将提取的字符级特征和lattice表示送到全连接网络,以获得每个输入的最佳特征表示。之后,通过transformer进行编码并以条件随机场进行解码从而有效地发现词与词之间的关系以有效识别实体。相较于其它模型,本发明在嵌入层提取的更加细粒度的特征的有效性,这些特征从实体中捕获有意义的信息,解决了现有技术不能够可靠高效地提取命名实体的问题。
附图说明
[0057]
图1是本命名实体识别方法的流程示意图。
[0058]
图2是本命名实体识别方法的模型结构。
[0059]
图3是本命名实体识别方法步骤s2的流程示意图。
具体实施方式
[0060]
下面结合附图和具体实施方式对本发明做详细描述。
[0061]
实施例1
[0062]
如图1所示,一种融合信息高级特征的命名实体识别方法,包括以下具体步骤:
[0063]
s1.得到待分析文本信息,并进行预处理,得到预处理后的文本特征;
[0064]
s2.将得到的预处理后的文本特征输入到深度卷积神经网络提取文本中的字符级特征,将提取的字符级特征输入全连接网络,获得字符的最佳特征表示;
[0065]
s3.通过得到的字符级特征和文本信息,得到lattice,并进行lattice嵌入,得到集成表示;
[0066]
s4.连接所述的集成表示和最佳特征表示,并用transformer作为编码器,以条件随机场进行解码,得到词与词之间的关系,并进行实体识别。
[0067]
步骤s1,具体为:将得到的文本信息的序列表示为s={c1,c2,
…
,cn},其中n表示句子长度,ci为句子s中的字符;将输入的句子中的每个字符ci映射为字符向量,公式如下:
[0068]
xi=ec(ci),
[0069]
其中xi为字符向量,ec是一个包含了字符和词语的预训练词向量;由此,得到预处理后的文本特征:
[0070]
x=[x1,x2,
…
,xn]。
[0071]
如图3所示,步骤s2,具体步骤为:
[0072]
s201.对得到预处理后的文本特征两端进行填充;
[0073]
s202.使用三个尺寸不同的过滤器扫描填充后的文本特征,并提取第一特征、第二特征、第三特征;
[0074]
s203.分别对所述的第一特征、第二特征、第三特征进行最大池化操作,并将操作后的第一特征、第二特征、第三特征拼接起来得到文本中的字符信息;在本实施例中,最大池化操作用于减少拟合。
[0075]
s204.将得到的文本中的字符信息输入到全连接网络中,并得到字符信息的最佳特征表示xc。
[0076]
步骤s202中三个尺寸不同的过滤器分别为面积为2*50,3*50和4*50的三个过滤器。
[0077]
实施例2
[0078]
如图1所示,一种融合信息高级特征的命名实体识别方法,包括以下具体步骤:
[0079]
s1.得到待分析文本信息,并进行预处理,得到预处理后的文本特征;
[0080]
s2.将得到的预处理后的文本特征输入到深度卷积神经网络提取文本中的字符级特征,将提取的字符级特征输入全连接网络,获得字符的最佳特征表示;
[0081]
s3.通过得到的字符级特征和文本信息,得到lattice,并进行lattice嵌入,得到
集成表示;
[0082]
s4.连接所述的集成表示和最佳特征表示,并用transformer作为编码器,以条件随机场进行解码,得到词与词之间的关系,并进行实体识别。
[0083]
步骤s1,具体为:将得到的文本信息的序列表示为s={c1,c2,
…
,cn},其中n表示句子长度,ci为句子s中的字符;将输入的句子中的每个字符ci映射为字符向量,公式如下:
[0084]
xi=ec(ci),
[0085]
其中xi为字符向量,ec是一个包含了字符和词语的预训练词向量;由此,得到预处理后的文本特征:
[0086]
x=[x1,x2,
…
,xn]。
[0087]
如图3所示,步骤s2,具体步骤为:
[0088]
s201.对得到预处理后的文本特征两端进行填充;
[0089]
s202.使用三个尺寸不同的过滤器扫描填充后的文本特征,并提取第一特征、第二特征、第三特征;
[0090]
s203.分别对所述的第一特征、第二特征、第三特征进行最大池化操作,并将操作后的第一特征、第二特征、第三特征拼接起来得到文本中的字符信息;
[0091]
s204.将得到的文本中的字符信息输入到全连接网络中,并得到字符信息的最佳特征表示xc。
[0092]
步骤s3,具体步骤为:
[0093]
s301.将所述的文本序列s的所有子序列分别与现有词典d,用来表示从字符序号b开始到字符序号e结束的子序列,b和e是常数,并得到文本序列s中所有与现有词典d匹配的序列
[0094]
s302.将cw映射为向量:xw=ec(cw),其中ec是一个包含了字符和词语的预训练词向量;
[0095]
s303.将预处理后的文本特征x和向量xw拼接起来,得到latticex
l
,即x
l
=[x,xw];
[0096]
s304.将x
l
输入一个全连接层来获得本特征x和向量xw的集成表示x
l
:
[0097]
x
l
=w
l
x
l
+b
[0098]
其中w
l
是可训练的参数。
[0099]
所述的lattice包括不同长度的span,所述的span之间有三种关系:包含、分离、相交。
[0100]
步骤s4,连接所述的集成表示和最佳特征表示,具体为:将所述的最佳特征表示xc和集成表示x
l
连接,通过线性投影将其转换为原始维度x
in
:
[0101]
x
in
=linear[xc;x
l
]
[0102]
其中,linear表示线性函数。
[0103]
如图2所示,步骤s4中transformer包括两层神经网络,分别是自注意力层和前馈神经网络层;本实施例中,每个层之后依次是求和与归一化。换句话说,每个层的输出是layernorm(x+layer(x)),layer(x)是自注意力或者前馈神经网络的输出;其中所述的自注意力层为多头注意力网络,其多头并行地对输入的序列进行关注,然后将多头的结果连接起来,并再次投影产生最终值,本实施例中有h头注意力,h头并行地对序列进行关注。然后
将h头的结果连接起来,并再次投影产生最终值。每个头的计算方式如下。
[0104]
att(a,v)=softmax(a)v
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(13)
[0105]aij
=(qi+u)
t
kj+(qi+v)
trijwr (14)
[0106]
[q,k,v]=e
x
[wq, wk, wv]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(15)
[0107]
e是输入向量x
in
.wq,wkwv是可训练矩阵,用于将e
x
投影到不同的空间。wr是可训练矩阵.qi,kj分别是span xi和xj的查询向量和键向量.v是值向量.a
ij
表示注意力分数。而前馈神经网络是一个多层感知器,由多层连续非线性函数组成;所述的前馈神经网络包括两个线性变换,中间有一个relu激活函数;自注意力子层的输出将被输入前馈神经网络做进一步的处理。
[0108]
所述的自注意力层采用了相对位置编码,具体步骤为:
[0109]
st401.通过头部和尾部信息的连续变换来计算;用head[i]and tail[i]
[0110]
来分别表示lattice中spansxi的头和尾的位置,同时,用四种相对距离来表示spansxi和xj的关系:
[0111][0112][0113][0114][0115]
其中表示spansxi的头和spansxj的头之间的距离,表示spansxi的头和spansxj的尾之间的距离,表示spansxi的尾和spansxj的头之间的距离,表示spansxi的尾和spansxj的尾之间的距离;
[0116]
st402.通过所述的四个距离的非线性变换,得到span的相对位置:
[0117][0118]
其中wr是一个可训练的参数,表示连接运算符,pd计算如下:
[0119][0120][0121]
其中pd即公式10中的p,d是4个距离或者之一,k表示位置编码的维度索引。
[0122]
步骤s4中,以条件随机场进行解码,具体为:
[0123]
sp401.对于给定的文本序列s,创建其对应的其对应的标签序列为y={y1,y2,
…
,yn},y(s)表示所有有效的标签序列;
[0124]
sp402.计算y的概率:
[0125][0126]
其中f(y
i-1
,yi,n)计算从y
i-1
到yi的transition score和yi的分数;
[0127]
sp403.结合所述的y的概率,通过viterbi算法来寻找达到最大概率的路径。
[0128]
实施例3
[0129]
如图1所示,一种融合信息高级特征的命名实体识别方法,包括以下具体步骤:
[0130]
s1.得到待分析文本信息,并进行预处理,得到预处理后的文本特征;
[0131]
本实施例中,所述的待分析文本信息为900条可以用来做命名实体识别的海洋产业句子数据。
[0132]
s2.将得到的预处理后的文本特征输入到深度卷积神经网络提取文本中的字符级特征,将提取的字符级特征输入全连接网络,获得字符的最佳特征表示;
[0133]
s3.通过得到的字符级特征和文本信息,得到lattice,并进行lattice嵌入,得到集成表示;
[0134]
s4.连接所述的集成表示和最佳特征表示,并用transformer作为编码器,
[0135]
以条件随机场进行解码,得到词与词之间的关系,并进行实体识别。
[0136]
步骤s1,具体为:将得到的文本信息的序列表示为s={c1,c2,
…
,cn},其中n表示句子长度,ci为句子s中的字符;将输入的句子中的每个字符ci映射为字符向量,公式如下:
[0137]
xi=ec(ci),
[0138]
其中xi为字符向量,ec是一个包含了字符和词语的预训练词向量;由此,得到预处理后的文本特征:
[0139]
x=[x1,x2,
…
,xn]。
[0140]
如图3所示,步骤s2,具体步骤为:
[0141]
s201.对得到预处理后的文本特征两端进行填充;
[0142]
s202.使用三个尺寸不同的过滤器扫描填充后的文本特征,并提取第一特征、第二特征、第三特征;
[0143]
s203.分别对所述的第一特征、第二特征、第三特征进行最大池化操作,并将操作后的第一特征、第二特征、第三特征拼接起来得到文本中的字符信息;
[0144]
s204.将得到的文本中的字符信息输入到全连接网络中,并得到字符信息的最佳特征表示xc。
[0145]
步骤s3,具体步骤为:
[0146]
s301.将所述的文本序列s的所有子序列分别与现有词典d,用来表示从字符序号b开始到字符序号e结束的子序列,b和e是常数,并得到文本序列s中所有与现有词典d匹配的序列
[0147]
s302.将cw映射为向量:xw=ec(cw),其中ec是一个包含了字符和词语的预训练词向量;
[0148]
s303.将预处理后的文本特征x和向量xw拼接起来,得到latticex
l
,即x
l
=[x,xw];
[0149]
s304.将x
l
输入一个全连接层来获得本特征x和向量xw的集成表示x
l
:
[0150]
x
l
=w
l
x
l
+b
[0151]
其中w
l
是可训练的参数。
[0152]
所述的lattice包括不同长度的span,所述的span之间有三种关系:包含、分离、相交。
[0153]
步骤s4,连接所述的集成表示和最佳特征表示,具体为:将所述的最佳特征表示xc和集成表示x
l
连接,通过线性投影将其转换为原始维度x
in
:
[0154]
x
in
=linear[xc;x
l
]
[0155]
其中,linear表示线性函数。
[0156]
如图2所示,步骤s4中transformer包括两层神经网络,分别是自注意力层和前馈神经网络层;本实施例中,每个层之后依次是求和与归一化。换句话说,每个层的输出是layernorm(x+layer(x)),layer(x)是自注意力或者前馈神经网络的输出;其中所述的自注意力层为多头注意力网络,其多头并行地对输入的序列进行关注,然后将多头的结果连接起来,并再次投影产生最终值,本实施例中有h头注意力,h头并行地对序列进行关注。然后将h头的结果连接起来,并再次投影产生最终值。每个头的计算方式如下。
[0157]
att(a,v)=softmax(a)v
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(13)
[0158]aij
=(qi+u)
t
kj+(qi+v)
trijwr (14)
[0159]
[q,k,v]=e
x
[wq, wk, wv]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(15)
[0160]
e是输入向量x
in
.wq,wk,wv是可训练矩阵,用于将e
x
投影到不同的空间。wr是可训练矩阵.qi,kj分别是span xi和xj的查询向量和键向量.v是值向量.a
ij
表示注意力分数。而前馈神经网络是一个多层感知器,由多层连续非线性函数组成;所述的前馈神经网络包括两个线性变换,中间有一个relu激活函数;自注意力子层的输出将被输入前馈神经网络做进一步的处理。
[0161]
所述的自注意力层采用了相对位置编码,具体步骤为:
[0162]
st401.通过头部和尾部信息的连续变换来计算;用head[i]and tail[i]来分别表示lattice中spansxi的头和尾的位置,同时,用四种相对距离来表示spansxi和xj的关系:
[0163][0164][0165][0166][0167]
其中表示spansxi的头和spansxj的头之间的距离,表示spansxi的头和spansxj的尾之间的距离,表示spansxi的尾和spansxj的头之间的距离,表示spansxi的尾和spansxj的尾之间的距离;
[0168]
st402.通过所述的四个距离的非线性变换,得到span的相对位置:
[0169][0170]
其中wr是一个可训练的参数,表示连接运算符,pd计算如下:
[0171][0172][0173]
其中pd即公式10中的p,d是4个距离或者之一,k表示位置编码的维度索引。
[0174]
步骤s4中,以条件随机场进行解码,具体为:
[0175]
sp401.对于给定的文本序列s,创建其对应的其对应的标签序列为y={y1,y2,
…
,yn},y(s)表示所有有效的标签序列;
[0176]
sp402.计算y的概率:
[0177][0178]
其中f(y
i-1
,yi,n)计算从y
i-1
到yi的transition score和yi的分数;
[0179]
sp403.结合所述的y的概率,通过viterbi算法来寻找达到最大概率的路径。
[0180]
本实施例设计了实验来测试本命名实体识别方法的有效性。
[0181]
本实施例中,采用了900条可以用来做命名实体识别的海洋产业句子数据集,包括的实体类型包括per(人物),loc(地点),org(组织)等8类。
[0182]
本实施例采用bilstm-crf和flat作为基线模型。flat是一个使用character-word lattice结构,采用相对位置编码的transformer模型for ner.同时与其它模型做出比较,采用了和zhang一样的embedding和lexicons.与其他模型做比较时,统一使用与flat相同的embedding和lexicons。
[0183]
下表显示了模型的超参数设置,使用了随机梯度下降(sgd)作为模型的优化算法。
[0184]
paremetervalueepoch100batch7char emb size50lattice emb size50cnn emb size50cnn dropout0.23transformer layer1head8head dim20learning rate lr0.001input dropout0.5
[0185]
集对其进行参数调整。我们使用随机梯度下降(sgd)作为我们的模型的优化算法。
[0186][0187][0188]
本实施例采用了标准精度(p)、召回率(r)和f1分数(f1)作为评价指标,具体如下。
[0189][0190][0191][0192]
tp表示对于被标记为实体的单词被正确识别为实体,fp表示非实体的单词被预测为实体的情况。此外,fn表示未检测到被标记为实体的单词的情况,tn表示被标记为非实体的单词被正确检测为非实体的情况。精度是正确预测的实体数量与预测的实体总数的比率。召回是正确预测的实体数量与实体总数的比率。f1分数是精确度和召回率的调和平均值,它反映了ner模型的整体性能。
[0193]
如下表所示,本命名实体识别方法相对别的模型在评价指标上具有相对优势,
[0194][0195]
从表上可以看出,作为基线的flat模型的f1平均分数为63.16%,加上深度卷积神经网络从字符级输入中提取的更高level的特征后,f1平均分数提升到了65.07%,高于所有其他用于比较的有竞争力的模型,尤其是那些不使用外部词典的基于字符的模型。这是因为深度卷积神经网络可以提取每个字符与前后字符的关系,从而捕获文中潜在的词语,与外部词典结合,能更清晰准确地界定实体边界,从而提高实体识别的准确率。
[0196]
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1