距离选通成像设备获取玻璃幕墙后图像的目标检测方法与流程
1.本发明涉及目标检测技术领域,具体是一种适用于无人机载距离选通成像设备透射玻璃下的人体目标检测方法。
背景技术:
2.透窗探测技术在近几年得到广泛关注,其主要目的是远距离获取建筑物内的人员活动信息以及场景信息。此类技术具有探测距离远、隐蔽性强的特点,常被应用于察、监视、人员识别与定位、战场评估等多种任务需求以获取准确的战场信息感知,为行动部门提供可靠的情报支持。
3.然而由于无人机载距离选通成像设备透射建筑物玻璃幕墙环境下的图像分辨率不强,信噪较低等缺陷,采用传统的图像处理方法无法满足实时准确的目标检测效果。
技术实现要素:
4.为了解决上述技术问题,本发明提出一种距离选通成像设备获取玻璃幕墙后图像的目标检测方法,步骤包括:1)对原始图像进行增强图像;2)对增强后图像进行特征和人体目标检测,对图形中的目标标记边界框;3)采用视频目标跟踪方法,通过对相邻时序切片数据中目标的关联统计,实现对同一个体目标识别结果的合并;
5.视频目标跟踪方法是通过检测现有目标的所有预测边界框之间的交并比作为相邻两个帧之间的相似度的度量指标,利用卡尔曼滤波器预测当前位置,再通过匈牙利算法关联检测框和目标位置,应用试探器鉴别虚假。
6.步骤1)中,采用神经网络模型并结合残差学习来进行距离选通成像数据的超分辨率重构与降噪。
7.步骤2)中,采用神经网络技术对对增强后图像进行特征和人体目标检测。
8.本发明为了提高简单的在线和实时跟踪算法在有遮挡情况下的准确率,将简单的在线和实时跟踪算法用在多目标实时跟踪上,并加入了基于神经网络的特征信息提取等方法,优化了简单的在线和实时跟踪算法,而且可以很好的满足激光照射选通成像环境下跟踪器设计的要求,简单的在线和实时区分技术处理流程如图2所示。
9.基于目标跟踪算法的多人目标区分技术可以利用相邻时序切片数据之间的空间对应关系,在合并同一个体目标的同时,还可以滤除单张数据中的虚警结果,从而进一步提高最终人员识别与发现的准确率。
附图说明
10.图1是本发明方法的流程图;
11.图2是基于目标跟踪算法的多人目标区分技术处理流程图的流程图;
12.图3是基于vdsr模型的图像超分辨率重构与降噪技术处理流程图;
13.图4是基于yolo-v4网络的人体目标检测技术处理流程图。
具体实施方式
14.以无人机载距离选通成像设备透射建筑物玻璃幕墙环境下图像为例,对本发明进行说明。
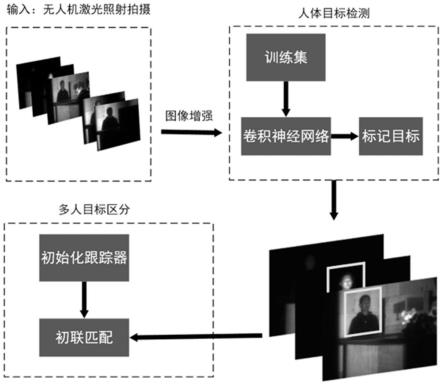
15.本发明针对该类图像的分辨率不强,信噪较低等特点,解决复杂平台运动环境、复杂激光照射环境下的室内人目标检测问题,具体步骤如下:
16.1、采用图像超分辨重建与降噪的图像质量增强方法,解决图像信噪比低的问题。
17.2、基于yolov4目标检测网络实现对人体目标的检测。
18.3、采用面向时序切片数据的多人目标区分技术,实现对同一目标的检测,提高目标检测的准确率。
19.本发明采用的方法整体思路如图1所示。利用超分辨重构技术和降噪技术来增强图像。基于深度学习和卷积神经网络,采用回归问题求解和目标识别验证相结合思路,结合端到端网络技术实现激光照射环境下的快速人体目标检测追踪,并进行验证测试。围绕增强图像、特征提取、人体目标检测识别、人体追踪几个方面开展研究工作。
20.①
超分辨率重构与降噪技术
21.距离选通成像对照射场景产生多帧图像,照射能量会分散到各个帧中,导致图像清晰度下降。针对每层人体目标图像清晰度不强、信噪比较低的特点,基于深度学习和卷积神经网络,采用超分辨重建与降噪技术,解决激光照射下选通成像分辨率较低、信噪比较差的问题。
22.本发明基于表现优秀的vdsr模型,使用非常深的神经网络模型来进行模型预测,然后结合残差学习来进行距离选通成像数据的超分辨率重构与降噪,处理流程图如图3所示。一方面,使用了带padding形式的卷积,使得输入与输出的尺寸保持一致,使得中间的网络模型层的可变空间非常的大,模型使用非常的自由;另一方面,使用了残差学习的方法,直接预测超分的残差,极大地加速了模型的训练过程,也使得最终输出中保留的细节较好。
23.对比距离选通成像数据与传统低分辨率光学数据的特点,基于vdsr模型,本方法预期能使距离选通成像数据的峰值信噪比提升约30%,可为后续的目标检测等应用提供可靠的数据支撑。
24.②
基于卷积神经网络的人体目标检测技术
25.利用图像超分辨率重建与降噪技术获取的图像中人体目标轮廓清晰、同时具有一定的纹理信息,因此,本方明基于人工智能领域的研究热点——卷积神经网络开展研究。
26.兼顾算法高精度、高效率以及模型轻量化等需求,本技术方案中基于yolo-v4网络实现选通成像数据中人体目标的检测,处理流程图如图4所示。采用单独端到端网络,通过卷积神经网络获取选通成像的卷积层和全连接层,利用卷积层直接提取人体特征,利用全连接层直接得到图像中所有物体的位置和其所属类别及相应的置信概率。
27.基于yolo-v4网络的目标检测技术在光学数据集上测试的性能为66%的ap值(ms coco数据集:328,000张图像,91类/超过150万个目标)。由于选通成像数据背景干扰更小,且人体目标特征信息明显,本发明可实现人体目标检测准确率优于90%。
28.③
面向时序切片数据的多人目标区分技术
29.结合选通成像原理,单一个体目标会在时序切片数据中连续出现,会对人员识别结果产生极大的干扰。针对上述问题,本项目引用视频目标跟踪技术,通过对相邻时序切片
数据中目标的关联统计,实现对同一个体目标识别结果的合并。
30.简单的在线和实时跟踪算法通过检测现有目标的所有预测边界框之间的交并比作为相邻两个帧之间的相似度的度量指标,并利用卡尔曼滤波器预测当前位置,通过匈牙利算法关联检测框和目标位置,应用试探器鉴别虚假。为了提高简单的在线和实时跟踪算法在有遮挡情况下的准确率,将简单的在线和实时跟踪算法用在多目标实时跟踪上,并加入了基于神经网络的特征信息提取等方法,优化了简单的在线和实时跟踪算法,而且可以很好的满足激光照射选通成像环境下跟踪器设计的要求,简单的在线和实时区分技术处理流程如图2所示。
31.基于目标跟踪算法的多人目标区分技术可以利用相邻时序切片数据之间的空间对应关系,在合并同一个体目标的同时,还可以滤除单张数据中的虚警结果,从而进一步提高最终人员识别与发现的准确率。
32.本实施例中:
33.步骤1中:
34.1)数据预处理:
35.首先将图像进行插值得到ilr图像,在将其输入网络,网络是基于vgg19的,利用19组conv+relu层,每个conv采用的filter规格为3*3*64。
36.2)模型训练:
37.2.1)低清图像与高清图像相似度高,直接学习两者间的映射会引入大量的冗余计算,其实低清图像与高清图像的主要差别在于高频部分,所以只需学习二者之间的高频残差即可,这就自然的引入了残差学习。
38.2.2)网络用深达20层的卷积网络学习插值后的低清图像与高清图像之间的残差,并在最后一层将残差与低清图像相加得到输出。为了保证图像的大小始终与高清图像保持一致,每个卷积层都使用了等大小填充。
39.2.3)为了防止梯度爆炸与梯度消失,引入动态的θ,并且这个θ和学习率γ成反比,梯度限制在θ是限制梯度范围的超参数。
40.2.4)采用多尺度模型训练,即在每个批次中有不同scale的图像,参数共享在所有预定义的尺度中。
41.3)图像增强:
42.利用训练好的模型对低质量输入图像进行超分辨重构与降噪处理。
43.步骤2中:
44.1)处理训练集:
45.1.1)将采集设备获得的图片数据集格式转化为适合yolov4训练的xml格式;
46.1.2)然后把数据集划分为训练集和测试集两大部分;
47.2)搭建pytorch深度学习框架,其中深度学习模型的配置利用yolov4算法:
48.2.1)利用输入端的mosaic数据增强、自适应锚框计算和自适应图片放缩对图片数据进行预处理操作;
49.2.2)利用backbone主干网络中的focus结构、csp结构和spp结构进行网络特征提取;
50.2.3)通过neck的fpn+pan结构加强网络特征融合的能力;
51.2.4)利用输出端prediction进行特征大小输出,按照图像网格划分得到参数矩阵。
52.步骤3中:
53.1)检测器检测到人体目标,从而得到bbox信息;
54.2)基于bbox信息,生成detections信息;
55.3)进行卡尔曼滤波预测;
56.4)使用匈牙利算法将预测后的tracks和当前帧中的detecions进行匹配(包括级联匹配和iou匹配)
57.5)卡尔曼滤波更新;
58.具体实现为:
59.1)frame0:检测器检测到了3个detections,当前没有任何tracks,将这3个detections初始化为tracks
60.2)frame1:检测器又检测到了3个detections,对于frame 0中的tracks,先进行预测得到新的tracks,然后使用匈牙利算法将新的tracks与detections进行匹配,得到(track,detection)匹配对,最后用每对中的detection更新对应的track。
61.3)frame2:重复2)的操作
62.4)如此进行下去。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1