基于语义的数据湖查询系统及方法
1.本发明涉及的是一种信息处理领域的技术,具体是一种基于语义的数据湖查询系统及方法。
背景技术:
2.数据湖作为一种数据存储方式,扁平化地管理海量异构的原始数据,能够支撑对数据中的信息和知识的发现,从而充分挖掘数据中的价值。而大规模数据的快速产生、动态变化、关联复杂的特点,对在数据湖中进行智能有效的检索和分析提出了挑战。
3.现有的数据湖查询的解决方案,主要通过人工构建索引进行支持。但该类技术手段缺乏灵活性,在对数据的动态访问和对查询的智能响应方面的性能较低,不能适应不同模态的原始数据的持续生成中,对查询请求的准确理解和结果匹配。查询索引与数据的多对多映射主要通过前端节点进行多模式匹配,对数据语义的挖掘不足,难以支持复杂业务的数据共享,难以实现数据关系的深度分析,因而无法准确分析用户意图,全面地返回查询结果。
技术实现要素:
4.本发明针对现有的数据湖检索技术没有自动化的索引构建机制,没有利用原始数据中的隐含关联和知识,也缺乏对检索结果的智能排序的不足,提出一种基于语义的数据湖查询系统及方法,在数据湖元数据的支撑下,进行基于语义的数据查询和数据资源调用,能够有效适应数据湖中原始数据多源异构、动态变化和关联复杂的特点,在保证数据一致性的前提下,提升用户检索的灵活性和检索结果的全面性,对用户输入的查询请求,智能返回检索得到的知识实例结果。
5.本发明是通过以下技术方案实现的:
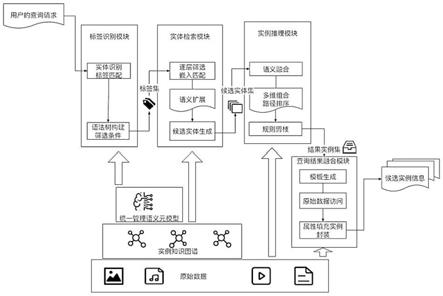
6.本发明涉及一种基于语义的数据湖查询系统,包括:标签识别模块、实体检索模块、实例推理模块和查询结果融合模块,其中:标签识别模块依托数据湖元模型索引顶层分类标签,对用户输入的查询语句文本进行命名实体识别,并进行语法树构建,输出查询请求涉及的语义标签集和对标签的筛选条件;实体检索模块按标签访问、筛选实体,并将筛选得到的实例知识图谱的实体子集与查询语义块进行深度匹配,链接到与所查询模式语义相关的实体后,经过语义扩展,生成候选实体集;实例推理模块访问、融合与前一步骤输出的实体相关联的实例的属性数据,并对实例进行多维度综合的排序,结合约束条件进行剪枝,从而缩小结果集;查询结果融合模块按照汇总查询语义标签信和排序评价维度的信息模板读取原始数据,封装为知识实例,将结构化的实例知识返回给用户。
7.所述的数据湖元数据包括:统一管理语义元模型层、实例知识图谱层和原始数据层,其中:层与层之间通过外键建立映射,支持准确提取;语义元模型层是owl格式描述的分类分层的概念、属性与关联模型,是数据的全局目录索引;实例知识图谱层是以统一资源管理框架(rdf)描述的关联数据,通过统一资源描述符(uri)标识,对实时抽取和更新的实例
知识进行全局语义一致的存储。其中,实例知识包括从原始数据层抽取出的实例数据和历史查询语句结构模型。并通过历史查询语句结构模型对抽取颗粒度和封装结构进行调整;原始数据层是文本、图片、语音、视频等模态、多源异构的原始数据。
8.所述的标签识别模块根据用户查询语句和统一管理语义元模型中目录索引构成的顶层实体分类标签,经过词典匹配识别出粗粒度的实体;然后通过预训练的bert模型在标注集上微调后,将用户输入的查询中每个语句嵌入表示为词向量和字向量,通过条件随机场层(crf)使用上一层输出的得分及转移概率矩阵确定最优标签序列,从而获取从查询语句中能直接解析出的语义标签集合l
in
;再综合词典模型和深度学习模型的匹配结果,构建语法树,根据语法依存关系,识别针对该标签的筛选条件。
9.所述的实体检索模块,逐个按解析出的标签从该标签分类中进行实体筛选,并通过基于图嵌入的实体深度匹配,利用实例知识图谱中实体的上下文补充用户查询中的语义信息;通过语义扩展算法扩展实体集合,从而扩大召回,生成候选实体集,输入实例推理模块剪枝。
10.所述的实例知识图谱,是数据湖原始数据中自动识别出的命名实体和关联关系、属性经过统一标准化形成的网状知识结构,以关联数据的形式存储。该实例知识图谱的构建,是通过对各类原始数据进行具体预处理以及不同颗粒度的信息抽取,然后进行知识封装,最后经过词义消歧和实体匹配以解决大量知识在合并时存在的问题,保证知识的唯一性和准确性后进行知识融合处理得到。
11.所述的实体深度匹配通过最大化查询语句和筛选得到的实体在知识图谱中的语义块嵌入向量的余弦相似度来实现,即基于嵌入的深度匹配:使用g2s(graph-to-segment,基于语义块的知识图谱语义解析)模型,在融合多模态数据的实例知识图谱中实例知识节点和关联关系的信息的策略下,对标签筛选结果和查询请求的语义块,进行嵌入、基于注意力机制的对齐、序列解码,得到嵌入的向量,进行相似度匹配,然后使用语义扩展算法,扩充结果集,具体步骤如下:
12.步骤a)知识图谱节点实体嵌入为其邻接节点的拼接
13.步骤b)通过对语义块中节点的最大池化形成语义块子图的嵌入;
14.步骤c)采用双向门控循环网络(gru)对语义块序列进行解码,隐状态s1=s
i+1
=gru([φ
(y)
(yi),ci],si,),其中:φ
(y)
(yi)为语义块的嵌入;
[0015]
步骤d)基于注意力机制对向量进行对齐:知识图谱的节点注意力上下文向量下文向量其中:e
ij
=a(s
i-1
,hj),a
ij
为每个节点表示的权重,a是作为对齐函数的前馈神经网络,作用是对位置j周围的输入节点和位置i处的输出匹配程度进行评分。
[0016]
步骤e)最大化计算用户当前检索语句嵌入sq和知识图语义块嵌入sh的余弦相似度其中:qi,hi分别表示向量的各个分量,从而将查询匹配到知识图谱中的语义块。
[0017]
步骤f)跨概念和实例层进行语义扩展:通过标签传播(lpa),来将上述候选实体集
rs膨胀为扩充集es,其中:|es|=γ
·
|rs|,γ为膨胀系数,γ∈[1,min(|neighborset|)],即:由兴趣节点e(e∈es)向有同义或上下位关系关联的邻接节点e’(e
′
∈实例知识图谱kg)发送消息,邻接节点接收消息,更新节点的实体标签集为累加权重最大的标签或标签集,当权重相等则随机选择;在标签稳定之后,实体与标签相关联;使用窗口衰减的滑窗从匹配度权重最高的实体e1的邻居开始,扩充结果集,从而在知识图谱中提高检索的召回率,具体包括:
[0018]
步骤1、在e1邻域中选择邻居节点nei(e1),nei(e1)≠e1作为监听节点;
[0019]
步骤2、nei(e1)接收来自它邻居节点的消息,消息权重w=s
×wsplit
,其中:节点权重s是步骤e)计算得到的节点所在的语义块嵌入后的相似度数值,表征实体与检索式的关联度,w
split
分割系数为节点出度的倒数。每轮迭代中对节点标签进行归一化;
[0020]
步骤3、依次处理下一个匹配实体节点的邻域;
[0021]
步骤4、返回步骤1,直到达到预定义的最大迭代次数t;
[0022]
步骤5、遍历rs节点邻域,排序权重最高的窗口大小的个节点加入扩充集es。处理结束。
[0023]
经窗口衰减的语义实例扩充的方法得到的扩展结果实体集es,是用户查询目标的超集,经过后续路径排序步骤剪枝得到返回给用户的排序实例集。对包含时间信息的筛选条件,将时间约束匹配到等于、包含、重叠、先于、后于、紧靠六种语义。由此,将查询匹配为符合知识图谱语义的实体,并基于标签传播方法对用户输入的检索的语义扩充,自动化地生成候选实体集合。
[0024]
所述的实例推理模块对候选实体集es进行多维度组合的排序,在用户自定义的裁剪系数k的限制下返回关联匹配到查询意图的实例。具体方法是在实体集合中选择出k个符合规则约束的、多维度组合评分排序高,并且数据质量描述好、节点响应程度高的实例数据,通过动态设置裁剪阈值对链接到的实例剪枝,输入后续步骤进行融合处理。
[0025]
所述的多维组合评分排序是指:按候选实体集,路由到实例数据;然后将实例数据中多维度属性和特征融合,经过加权聚合,得到实体评分:f[f1(e),f2(e),...,fn(e)]
·
φ(e),其中:实体e在维度i的数值化评分fi(e)=μi·
i(e),μi为该特征维度的权重,i(e)为组成维度标签的实例属性聚合结果φ(e)=πrule
λ
,rule
λ
为该实例的属性λ对数据规则、时间语义、权限规则的可满足性,φ(e)∈[0,1];f为打分函数,包括但不限于求和、加权平均。
[0026]
所述的查询结果融合模块根据数据湖元模型中的目录索引构成的分类语义标签和评分涉及的属性维度标签,生成信息模板;读取原始数据进行汇总、压缩,填充到信息模板中,实现关键属性的填充,从而将相关的原始数据投影到与查询意图主题相关的特征视图,并通过信息模板进行封装,得到返回用户的候选实体信息。
[0027]
所述的信息模板生成是在不同抽象层面上选择与查询和排序语义相关的标签,原始数据读取是根据结果实例集对应的uri路由到实例原始数据,属性填充是根据信息模板对应的信息项,从原始数据中按预定义接口进行补充抽取、融合高低层次不同尺度不同模态的语义信息并根据语义元模型分层压缩,形成不同颗粒度的属性、特征后填充到返回的
知识模板的对应槽位。
[0028]
本发明涉及一种基于语义的数据湖查询方法,对用户输入的请求进行语义解析,识别出查询包含的标签;在数据湖元数据支撑下,在知识图谱中逐个标签进行逐层筛选和匹配,并通过语义标签传播扩展查询,生成候选实体集;然后在实例推理模块综合多个评价维度,对实例排序、剪枝;最后调用原始数据,按解析的语义标签和排序的维度标签生成信息模板,填充实例数据到模板中的各个槽位,对实例数据进行汇总聚合和知识封装。通过上述步骤,准确理解用户的查询意图,并在充分语义融合的基础上,全面地汇总实例信息,响应多变的查询请求,返回按不同维度排序组合的候选实例信息。技术效果
[0029]
与现有技术相比,本发明在数据湖元数据的支撑下,对用户意图进行解析;然后在实体检索模块进行筛选和语义扩展,召回匹配的实体;接着在实例推理模块,通过进行多维属性融合和加权聚合,进行数据语义关联度推理,从而按实例数据在多个评价维度的打分,对召回的结果集进行排序;最后在查询结果融合模块,生成信息模板,调用原始数据对信息模板中的关键标签进行填充,说明排序标签,返回构建的结果实例信息给用户。
附图说明
[0030]
图1为本发明系统示意图;
[0031]
图2为实施例应用示意图。
具体实施方式
[0032]
本实施例涉及一种基于上述系统的基于语义的数据湖查询方法,在用户对数据的查询检索过程中,基于数据融合程度高、融合数据的语义关联性强、对新数据实时融合更新的统一管理语义元模型和实例知识图谱,灵活准确地响应多样的查询请求。
[0033]
如图2所示,用户输入的查询,封装为json,通过restful接口输入标签识别模块。首先,在应用层标签识别模块中通过命名实体识别算法和语法树构建,识别出查询语句中的分类语义标签和筛选条件;然后,在逻辑层的实体检索模块,逐个标签逐层筛选实体,并通过知识图谱语义块嵌入模型,准确链接到具有该标签的部分实体。基于分层语义元模型,通过标签算法进行语义扩展,扩充召回实体的范围;接着,在实例推理模块,经过实例知识融合和多维度排序得出查询结果,从而在全面地获取待查询实体的描述数据的基础上,准确根据用户查询意图,填充作为返回结果的知识实例。最后,在知识应用层,通过restful接口,以html的形式向前端返回相关实例信息,完成智能查询。
[0034]
在数据层,图数据库neo4j存储包括统一管理语义元模型、实例知识图谱、历史查询语句和模型的数据湖元数据;关系型数据库mysql、非关系型数据库mongodb、分布式文件系统hdfs和对象存储系统存储多模态的原始数据。本系统通过以下步骤实现对数据湖的智能检索:
[0035]
步骤1、对系统用户输入的查询进行解析,在数据湖的统一管理语义元模型目录索引的辅助下识别出查询中包含的语义标签和筛选条件;
[0036]
步骤2、根据步骤1输出的标签对知识实体进行筛选,并结合知识图谱中实体的上下文获取表征查询意图的语义块,再通过标签传播扩展语义,发现相关实体,扩展候选实体
集合;
[0037]
步骤3、按候选实体集合,在实例数据中融合不同维度不同语义高低层次的指标属性,构造多维度排序函数,并根据时间约束、大小约束等约束关系,对数据进行排序,按自定义阈值剪枝,得到小查询结果集;
[0038]
步骤4、从原始数据中调用相关文件进行汇总和信息模板填充;返回候选实例信息。
[0039]
上述工作的技术特性与国内外同类技术产品的比较见表1。
[0040]
表1技术特性对比:
[0041]
与现有技术相比,本发明技术效果包括:
[0042]
本发明通过数据湖语义元模型的支撑,对用户查询语句进行解析和推理,在用户对数据湖进行查询的过程中实现对相关数据的全面和智能的召回和排序:对实时更新的数据,经过语义融合后,由元数据统一管理;在该持续生成的数据湖元数据的支撑的下,在语义检索的过程中,通过标签筛选实体、关联关系推理得到相关实例;通过跨模态融合提取的实例数据的属性、特征,从而智能化地扩充知识,进而返回数据湖中与查询有相关性的知识融合后形成的实例对象作为查询结果。通过这种方式,用户无需了解业务数据中具体的字段和实例数据间的复杂关联,直接通过自然语言描述查询意图,即可通过动态的候选实体生成方法链接到相关的实体集合。另外,知识图谱建模方法对数据模型的全局统一表述,使原始数据和推理结果能在满足语义约束的前提下,关联到统一管理的元模型,保证查询和相关度分析的数据一致性。
[0043]
上述具体实施可由本领域技术人员在不背离本发明原理和宗旨的前提下以不同的方式对其进行局部调整,本发明的保护范围以权利要求书为准且不由上述具体实施所限,在其范围内的各个实现方案均受本发明之约束。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1