基于深度学习的高频区域增强的光度立体三维重建方法
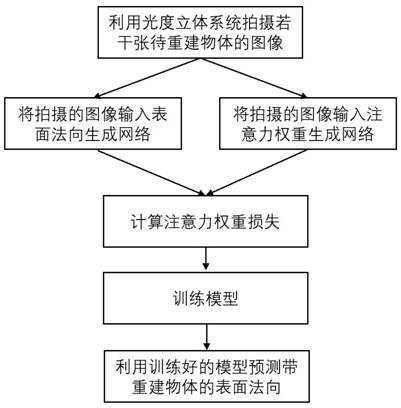
1.本发明涉及一种基于深度学习的高频区域增强光度立体三维重建方法,属于多度立体三维重建领域。
背景技术:
2.三维重建算法是计算机视觉中非常重要且基础的问题,光度立体算法是一种高精度的逐像素三维重建方法,其利用不同光照方向下的图像提供的灰度变化线索恢复物体表面法向。光度立体在许多高精度三维重建任务求中有着不可替代的位置,例如其在考古勘探,管道检测,海床精细测绘等方面有着重要的应用价值。
3.但现有的基于深度学习的光度立体方法在物体表面高频区域的误差很大,例如褶皱、边缘,现有方法在这些区域会生成模糊的三维重建结果,然而,这些区域正是重点关注并需要精确重建的地方。
技术实现要素:
4.针对以上问题,本发明目的是提出了一种基于深度学习的高频区域增强光度立体三维重建方法,以克服现有技术的不足。
5.基于深度学习的高频区域增强光度立体三维重建方法,其特征是包括以下步骤:1)利用光度立体系统,拍摄若干张待重建物体的图像:待重建物体在单个平行白色光源的照射下拍摄图像,以待重建物体中心为坐标轴原点,建立笛卡尔坐标系,则白光光源的位置由该笛卡尔坐标系中向量 l = [x, y, z]表示;改变该光源位置,在另一光照方向下获得拍摄图像;通常需至少拍摄10张以上的在不同光照方向照射下的图像,记作m1, m2, ..., mj,同时相对应的光源位置记作l1, l2, ...,lj,j为大于等于10的自然数;2)利用深度学习算法输入m1,m2, ..., mj和l1,l2, ..., lj,输出准确的表面法向三维重建:所利用的深度学习算法分为以下四个部分:(1)表面法向生成网络,(2)注意力权重生成网络,(3)注意力权重损失函数联合训练,(4)网络训练;其中:(1)表面法向生成网络被设计成从图像m1,m2, ..., mj和光照l1,l2, ..., lj中生成需要重建物体的表面法向;(2)注意力权重生成网络被设计成从图像m1, m2, ..., mj中生成需要重建物体的注意力权重图p ;(3)注意力权重损失l是一个逐像素处理的损失函数,它由每一个像素点的损失lk平均计算得到,公式为;p*q为图像m的分辨率,p、q≥2n,n≥4;每一个像素位置的损失lk包括两部分,第一部分是带有系数项的梯度损失
l
gradient
,第二部分是带有系数项的法向损失l
normal
,即l
k=
pkl
gradient
+λ(1
–
pk)l
normal
;其中,,是待重建物体的真实表面法向n在位置k的梯度,ζ是计算梯度时使用的邻域像素范围,ζ设置范围为1、2、3、4、5,是预测的表面法向在位置k的梯度;表示网络预测的表面法向,表示真实表面法向;梯度损失在网络中可以锐化表面法向的高频表达;pk为注意力权重图上像素位置k上的值;其次,,
●
代表点乘操作,λ是一个超参,目的是为了梯度损失和法向损失,设置范围为{7、8、9、10};通过上述(3)注意力权重损失可将(1)表面法向生成网络和(2)注意力权重生成网络建立起联系;(4)网络训练训练网络时,利用反向传播算法不断调整优化,最小化上述损失函数,使其在达到设定的循环次数时停止训练,以达到最优效果;或者l
normal
小于0.03时,即认为训练已经达到最有效果,停止训练;3)将上述训练好的网络用于光度立体图像的表面法向重建:先拍摄s张以上不同光照方向的图像,s≥10,将m1,m2,...,ms和l1,l2,...,ls输入训练好的网络,得到预测的表面法向。
[0006]
所述(1)表面法向生成网络被设计成从图像m1,m2,...,mj和光照l1,l2,...,lj中生成需要重建物体的表面法向具体如下:图像m的分辨率记为p*q,p、q≥2n,n≥4,则m∈
ℝ
p*q*3
,其中3表示rgb;表面法向生成网络首先按照m的分辨率p*q将光照l=[x,y,z]∈
ℝ3重复填充至
ℝ
p*q*3
的空间中,将填充后的光照记为h,则h∈
ℝ
p*q*3
,此时h与m有相同的空间大小,将h与m在第三组维度上连接融合,成为新的张量,新的张量属于
ℝ
p*q*6
,在输入j张图像和光照的情况下,得到了j个融合后的张量;将这些张量分别进行4层卷积层操作,卷积层1、2、3、4的卷积核大小均为3*3,均采用“relu”激活函数,其中第2层和第4层是步长“stride”为2的卷积,第1层和第3层是步长“stride”为1的卷积,卷积层1、2、3、4的特征通道数分别为64,128,128,256;之后,利用最大池化层从j个经过4层卷积的张量∈
ℝ
p/4*q/4*256
池化为一个
ℝ
p/4*q/4*256
中的张量;再经过卷积层5、6、7、8计算,卷积层5、6、7、8的卷积核大小均为3*3,均采用“relu”激活函数,其中第5层和第7层为转置卷积,第6层和第8层是步长“stride”为1的卷积,卷积层5、6、7、8的特征通道数为128、128、64、3;最后,对第8层卷积得到的张量进行规范化处理,使其模为1,得到需要重建物体的的表面法向。
[0007]
所述(2)注意力权重生成网络被设计成从图像m1, m2, ..., mj中生成需要重建物体的注意力权重图p具体如下:注意力权重生成网络对图像m∈
ℝ
p*q*3
计算其梯度值,该梯度值也属于空间
ℝ
p*q*3
,并将其梯度与图像在第三组维度上连接融合,成为新的张量,新的张量属于
ℝ
p*q*6
,在输入j张图像和光照的情况下,得到了j个融合后的张量;首先将这些融合后的张量分别进行3层的卷积层操作,这3层的卷积核大小均为3*3,均采用“relu”激活函数,其中第2层的步长“stride”为2,第1层和第3层的步长“stride”为1,四个卷积层的特征通道数分别为64、128、128;之后,利用最大池化层从j个经过3层卷积的张量∈
ℝ
p/2*q/2*128
池化为一个
ℝ
p/2*q/2*128
中的张量;再经过卷积层5、6、7计算,卷积层5、6、7的卷积核大小均为3*3,均采用“relu”激活函数,其中第6层为转置卷积,第5层和第7层是步长“stride”为1的卷积,卷积层5、6、7的特征通道数为128、64、1,从而得到需要重建物体的注意力权重图p 。
[0008]
所述的基于深度学习的高频区域增强光度立体三维重建方法,其特征是所述图像m的分辨率p*q中,p取值16,32,48,64,q取值16,32,48,64。
[0009]
所述的基于深度学习的高频区域增强光度立体三维重建方法,其特征是所述ζ设置为1。
[0010]
所述的基于深度学习的高频区域增强光度立体三维重建方法,其特征是所述λ设置为8。
[0011]
所述的基于深度学习的高频区域增强光度立体三维重建方法,其特征是所述的循环次数设定为30次epoch。
[0012]
所述的基于深度学习的高频区域增强光度立体三维重建方法,其特征是所述p取值32,q取值32。
[0013]
本发明提出的基于深度学习的高频区域增强的光度立体三维重建方法,通过提出的表面法向生成网络,注意力权重生成网络,分别学习表面法向和高频信息,并利用提出的注意力权重损失进行训练,可以改善褶皱边缘等高频区域表面的重建精度。相比先前传统光度立体方法,提高了三维重建精度,尤其是待重建物体表面的细节。
[0014]
本发明提出的注意力权重损失,可以应用于多种底层视觉任务,提高任务精度,丰富图像的细节,例如深度估计,图像去模糊和图像去雾。
附图说明
[0015]
图1是本发明的流程图。
[0016]
图2是步骤2)中表面法向生成网络示意图。
[0017]
图3是步骤2)中注意力权重生成网络示意图。
[0018]
图4是本发明的应用效果示意图,其中第一行为输入图像,第二行为生成的权重图像,第三行为生成的表面法向。
具体实施方式
[0019]
如图1,基于深度学习的高频区域增强光度立体三维重建方法,其特征是包括以下
步骤:1)利用光度立体系统,拍摄若干张待重建物体的图像:待重建物体在单个平行白色光源的照射下拍摄图像,以待重建物体中心为坐标轴原点,建立笛卡尔坐标系,则白光光源的位置由该笛卡尔坐标系中向量 l = [x, y, z]表示;改变该光源位置,在另一光照方向下获得拍摄图像;通常需至少拍摄10张以上的在不同光照方向照射下的图像,记作m1, m2, ..., mj,同时相对应的光源位置记作l1, l2, ...,lj,j为大于等于10的自然数;2)利用深度学习算法输入m1,m2, ..., mj和l1,l2, ..., lj,输出准确的表面法向三维重建:所利用的深度学习算法分为以下四个部分:(1)表面法向生成网络,(2)注意力权重生成网络,(3)注意力权重损失函数联合训练,(4)网络训练;(1)表面法向生成网络被设计成从图像m1,m2, ..., mj和光照l1,l2, ..., lj中生成需要重建物体的表面法向;图像m的分辨率记为p*q,p、q≥2n,n≥4,则m∈
ℝ
p*q*3
,其中3表示rgb;如图2,表面法向生成网络首先按照m的分辨率p*q将光照l = [x, y, z] ∈
ℝ3重复填充至
ℝ
p*q*3
的空间中,将填充后的光照记为h,则h∈
ℝ
p*q*3
,此时h与m有相同的空间大小,将h与m在第三组维度上连接融合,成为新的张量,新的张量属于
ℝ
p*q*6
,在输入j张图像和光照的情况下,得到了j个融合后的张量;将这些张量分别进行4层卷积层操作,卷积层1、2、3、4的卷积核大小均为3*3,均采用“relu”激活函数,其中第2层和第4层是步长“stride”为2的卷积,第1层和第3层是步长“stride”为1的卷积,卷积层1、2、3、4的特征通道数分别为64,128,128,256;之后,利用最大池化层从j个经过4层卷积的张量∈
ℝ
p/4*q/4*256
池化为一个
ℝ
p/4*q/4*256
中的张量;再经过卷积层5、6、7、8计算,卷积层5、6、7、8的卷积核大小均为3*3,均采用“relu”激活函数,其中第5层和第7层为转置卷积,第6层和第8层是步长“stride”为1的卷积,卷积层5、6、7、8的特征通道数为128、128、64、3;最后,对第8层卷积得到的张量进行规范化处理,使其模为1,得到预测的表面法向;(2)注意力权重生成网络被设计成从图像m1, m2, ..., mj中生成需要重建物体的注意力权重图:注意力权重生成网络对图像m∈
ℝ
p*q*3
计算其梯度值,该梯度值也属于空间
ℝ
p*q*3
,并将其梯度与图像在第三组维度上连接融合,如图3,成为新的张量,新的张量属于
ℝ
p*q*6
,在输入j张图像和光照的情况下,得到了j个融合后的张量;首先将这些融合后的张量分别进行3层的卷积层操作,这3层的卷积核大小均为3*3,均采用“relu”激活函数,其中第2层的步长“stride”为2,第1层和第3层的步长“stride”为1,四个卷积层的特征通道数分别为64、128、128;之后,利用最大池化层从j个经过3层卷积的张量∈
ℝ
p/2*q/2*128
池化为一个
ℝ
p/2*q/2*128
中的张量;再经过卷积层5、6、7计算,卷积层5、6、7的卷积核大小均为3*3,均采用“relu”激活函数,其中第6层为转置卷积,第5层和第7层是步长“stride”为1的卷积,卷积层5、6、7的特征通道数为128、64、1,从而得到待重建物体的注意力权重图p;(3)注意力权重损失l是一个逐像素处理的损失函数,它由每一个像素点的损失lk平均计算得到,公式为;每一个像素位置的损失lk包括两部分,第一部分是带有系数项的梯度损失l
gradient
,第二部分是带有系数项的法向损失l
normal
,即l
k=
pkl
gradient
+λ(1
–
pk)l
normal
;其中,,是待重建物体的真实表面法向n在位置k的梯度,ζ是计算梯度时使用的邻域像素范围,ζ设置范围为1、2、3、4、5,本发明中默认设置为1,是预测的表面法向在位置k的梯度;表示网络预测的表面法向,表示真实表面法向;梯度损失在网络中可以锐化表面法向的高频表达;pk为注意力权重图上像素位置k上的值,也即注意力权重为逐像素的损失lk提供第一个梯度损失分项l
gradient
的权重,注意力权重值大的地方,梯度损失的权重就大;其次,,
●
代表点乘操作,λ是一个超参,目的是为了梯度损失和法向损失,本文将其设置为8;一般可以设置为{7,8,9,10},取8时可以获得较好的效果;通过上述(3)注意力权重损失可将(1)表面法向生成网络和(2)注意力权重生成网络建立起联系;(4)网络训练训练网络时,利用反向传播算法不断调整优化,最小化上述损失函数,使其在达到30次epoch(循环)的时刻停止训练,以达到最优效果;或者l
normal
小于0.03时,即认为训练已经达到最有效果,停止训练;在本发明中,在30个epoch后结束结束网络的训练,此时即认为训练已经达到最优效果;(5)将上述训练好的网络用于光度立体图像的表面法向重建:先拍摄s张以上不同光照方向的图像,s≥10,将m1,m2,...,ms和l1,l2,...,ls输入训练好的网络,得到预测的表面法向。
[0020]
其中p,q∈{16、32、48、64},λ∈{7,8,910},ζ可以取1,2,3,4,5。
[0021]
重建效果如图4所示。第一行表示待重建物体拍摄的图像,第二行代表生成的注意力权重图p,第三行代表生成的表面法向。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1