一种食品安全舆情分析技术抽取方法与流程
1.本发明涉及食品安全舆情分析技术抽取方法领域,具体而言,涉及一种食品安全舆情分析技术抽取方法。
背景技术:
2.食品安全舆情分析在食品安全研究中起到重要的辅助作用,随着人工智能的发展,舆情分析与自然语言处理技术结合越发紧密,现有的食品安全缺少一种食品安全舆情分析技术抽取方法,因此我们对此做出改进,提出一种食品安全舆情分析技术抽取方法,在舆情分析中,流程大概是搜集新闻,筛选内容,针对和食品安全相关的新闻进行情感分析,完成舆情分析的初筛,接下来对情感分析结果为p(积极)和n(消极)的新闻进行事件分析以及风险抽取。
技术实现要素:
3.本发明的目的在于:针对目前存在的背景技术提出的问题,为了实现上述发明目的,本发明提供了以下技术方案:一种食品安全舆情分析技术抽取方法,以改善上述问题,本技术具体是这样的:包括以下步骤,s1筛选食品安全内容,所述筛选食品安全内容包括s11关键词匹配法和s12无监督聚类分类法;s2语义情感分析,所述语义情感分析包括s21bert预训练模型和s22softmax分类;s3信息提取,所述信息提取包括s31prompt tuning和s32skep主体观点抽取。
4.作为本技术优选的技术方案,述s1筛选食品安全内容中s11中关键词匹配法中,s111筛选食品安全内容需要query和网页正文content的语义相关度,所述query与所述content的匹配使用短文本长文本语义匹配;s112计算相似度,计算分布生成短文本的概率作为相似度值;s113文档关键词抽取,抽取关键词做标签tag并设置主题模型估算文档产生单词的概率。
5.作为本技术优选的技术方案,所述s11中关键词匹配法中s112计算相似度的公式为:
[0006][0007]
其中,q表示query,c表示content,w表示q中的词,zk表示第k个主题;
[0008]
所述s11中关键词匹配法中s113文档关键词抽取估计文档产生单词的概率公式为:
[0009]
p(w∣d)=k=1∑kp(w∣zk)p(zk∣d);
[0010]
其中,d表示文档内容,w表示词,zk表示第k个主题;
[0011]
所述s11中关键词匹配法中s113文档关键词抽取twe训练得到主题和单词向量表示公式为:
[0012]
similarity(w,d)=k=1∑kcos(vm,zk)p(zk|d);
[0013]
其中,d表示文档内容,w表示词,zk表示第k个主题。
[0014]
作为本技术优选的技术方案,所述s1筛选食品安全内容中s12无监督聚类分类法中进行knn聚类,分成两类取其中心点,选取内容与食品安全无关者作为参照点并设定一阈值,计算目标新闻舆情与其距离,距离小于该阈值为食品安全数据。
[0015]
作为本技术优选的技术方案,所述s2语义情感分析中s21bert预训练模型中包括s211模型架构;s212bert输入和输出的表示;s213bert的预训练;s214bert的微调。
[0016]
作为本技术优选的技术方案,所述s21bert预训练模型中s211模型架构建立多层双向的transformer的encoder,s212bert输入和输出的表示,输入的自然语言句子通过wordpiece embeddings来转化为token序列,s213bert的预训练,bert使用两个无监督的任务进行预训练,分别是masked lm和next sentence prediction(nsp)。
[0017]
作为本技术优选的技术方案,所述s2语义情感分析中s22softmax分类通过softmax函数处理输出各种情感预测概率,取概率最大者为结果,公式为:
[0018][0019]
其中e为自然数,kwei第k个主题。
[0020]
作为本技术优选的技术方案,所述s3信息提取中s31prompt tuning,将prompt代替显式的prompt,并训练更新token参数。
[0021]
作为本技术优选的技术方案,所述s3信息提取中s32skep主体观点抽取skep是基于情感知识增强的情感预训练,通过skep算法挖掘情感知识,并通过情感知识构建预训练目标让机器理解情感语义。
[0022]
作为本技术优选的技术方案,所述skep算法通过统计方法从无标记数据中挖掘情感知识信息,所述情感知识信息包括情感词、情感词极性以及观点搭配词。
[0023]
与现有技术相比,本发明的有益效果:
[0024]
在本技术的方案中:
[0025]
1.通过为了能够双向地训练语言模型,bert的做法是简单地随机mask掉一定比例的输入token,然后预测这些被遮盖掉的token,这种方法就是masked lm(mlm),相当于完形填空任务,被mask掉的词将会被输入到一个softmax分类器中,分类器输出的维度对应词典的大小,在预训练时通常为每个序列mask掉15%的token,与降噪自编码器相比,在生成训练数据时我们随机选择15%的token进行替换,被选中的token有80%的几率被替换成mask,10%的几率被替换成另一个随机的token,10%的几率该token不被改变。然后将使用交叉熵损失来预测原来的token;
[0026]
2.通过训练了一个二值的next sentence prediction任务,其训练数据可以从任何单语语料库中生成。当选择句子a和句子b作为训练数据时,句子b有50%的几率的确是句子a的下一句,50%的几率是从语料库中随机选择的句子。cls对应的最后一个隐层输出向量被用来训练nsp任务,这个embedding就相当于sentence embedding,在微调时其在qa和nli任务上表现出了很好的效果。
附图说明:
[0027]
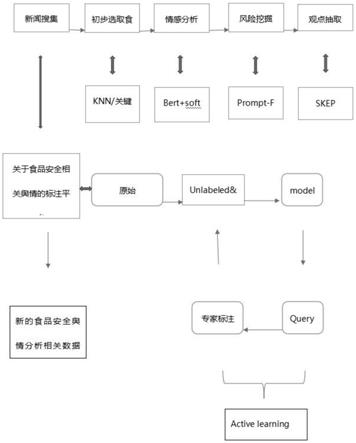
图1为本技术提供的食品安全舆情分析技术抽取方法的新闻数据标注平台架构图;
[0028]
图2为本技术提供的食品安全舆情分析技术抽取方法的p-tuning预训练模型图;
[0029]
图3为本技术提供的食品安全舆情分析技术抽取方法的bert示意图;
[0030]
图4为本技术提供的食品安全舆情分析技术抽取方法无监督聚类分类法图。
具体实施方式
[0031]
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合附图,对本发明实施例中的技术方案进行清楚、完整的描述。显然,所描述的实施例是本发明的一种具体实施方式,不限于全部的实施例。
[0032]
因此,以下对本发明的实施例的详细描述并非旨在限制要求保护的本发明的范围,而是仅仅表示本发明的部分实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0033]
如图1-图4,一种食品安全舆情分析技术抽取方法,包括以下步骤,s1筛选食品安全内容,筛选食品安全内容包括s11关键词匹配法和s12无监督聚类分类法;s2语义情感分析,语义情感分析包括s21bert预训练模型和s22softmax分类;s3信息提取,信息提取包括s31prompt tuning和s32skep主体观点抽取。
[0034]
优选的,s1筛选食品安全内容中s11中关键词匹配法中,s111筛选食品安全内容需要query和一个网页正文(content)的语义相关度,query与content的匹配使用短文本长文本语义匹配;s112计算相似度,根据长文本的主题分布,计算分布生成短文本的概率作为相似度值;s113文档关键词抽取,抽取关键词做标签tag并设置主题模型,估算文档产生单词的概率。
[0035]
优选的,s11中关键词匹配法中s112计算相似度的公式为:
[0036][0037]
其中,q表示query,c表示content,w表示q中的词,zk表示第k个主题;
[0038]
s11中关键词匹配法中s113文档关键词抽取估计文档产生单词的概率公式为:
[0039]
p(w∣d)=k=1∑kp(w∣zk)p(zk∣d);
[0040]
其中,d表示文档内容,w表示词,zk表示第k个主题;
[0041]
s11中关键词匹配法中s113文档关键词抽取twe训练得到主题和单词向量表示公式为:
[0042]
similarity(w,d)=k=1∑kcos(vm,zk)p(zk|d);
[0043]
其中,d表示文档内容,w表示词,zk表示第k个主题。
[0044]
优选的,s1筛选食品安全内容中s12无监督聚类分类法中在若干样本数据中先进行knn聚类,分成两类各取其中心点,选取内容与食品安全无关者作为参照点并设定一阈值,计算目标新闻舆情与其距离,距离小于该阈值默认食品安全相关。
[0045]
优选的,s2语义情感分析中s21bert预训练模型中包括s211模型架构;s212bert输入和输出的表示;s213bert的预训练;s214bert的微调。
[0046]
优选的,s21bert预训练模型中s211模型架构建立多层双向的transformer的encoder,对比gpt,bert使用了双向self-attention架构,而gpt使用的是受限的self-attention,即限制每个token只能attend到其左边的token,
[0047]
s21bert预训练模型中s212bert输入和输出的表示,输入的自然语言句子通过wordpiece embeddings来转化为token序列。在token序列开头加上[cls],最终输出的[cls]这个token的embedding使用这个embedding来做分类任务,并在token序列中区分,区分方式有两种:
[0048]
1、在token序列中两个句子的token之间添加[sep]这样一个特殊的token;
[0049]
2、我们为每个token添加一个用来学习的embedding来区分token属于句子a还是句子b,这个embedding叫做segment embedding。
[0050]
bert的输入由三部分相加组成:token embeddings、segment embeddings和position embeddings;s21bert预训练模型中s213bert的预训练,bert使用两个无监督的任务进行预训练,分别是masked lm和next sentence prediction(nsp);
[0051]
task 1:masked lm,为了能够双向地训练语言模型,bert的做法是简单地随机mask掉一定比例的输入token(这些token被替换成[mask]这个特殊token),然后预测这些被遮盖掉的token,这种方法就是masked lm(mlm),相当于完形填空任务(cloze task)。被mask掉的词将会被输入到一个softmax分类器中,分类器输出的维度对应词典的大小。在预训练时通常为每个序列mask掉15%的token。与降噪自编码器(denoising auto-encoders)相比,我们只预测被mask掉的token,并不重建整个输入,这种方法允许预训练一个双向的语言模型,但是有一个缺点就是造成了预训练和微调之间的mismatch,这是因为[mask]这个token不会在微调时出现。为了缓解这一点,采取以下做法:在生成训练数据时我们随机选择15%的token进行替换,被选中的token有80%的几率被替换成[mask],10%的几率被替换成另一个随机的token,10%的几率该token不被改变。然后将使用交叉熵损失来预测原来的token。
[0052]
task 2:next sentence prediction(nsp)一些重要的nlp任务如question answering(qa)或者natural language inference(nli)需要理解句子之间的关系,而这种关系通常不会被语言模型直接捕捉到。为了使得模型能够理解句子之间的关系,我们训练了一个二值的next sentence prediction任务,其训练数据可以从任何单语语料库中生成。具体的做法是:当选择句子a和句子b作为训练数据时,句子b有50%的几率的确是句子a的下一句(标签是isnext),50%的几率是从语料库中随机选择的句子(标签是notnext)。[cls]对应的最后一个隐层输出向量被用来训练nsp任务,这个embedding就相当于sentence embedding。虽然这个预训练任务很简单,但是事实上在微调时其在qa和nli任务上表现出了很好的效果。在前人的工作中,只有sentence embedding被迁移到下游任务中,而bert会迁移所有的参数来初始化下游任务模型;
[0053]
s21bert预训练模型中s214bert的微调,transformer的self-attention机制允许bert建模多种下游任务。对于包含句子对的任务,通常的做法是先独立地对句子对中的句子进行编码,然后再应用双向交叉注意。而bert使用self-attention机制统一了这两个过程,这是因为对拼接起来的句子对进行self-attention有效地包含了两个句子之间的双向交叉注意。
[0054]
对于情感分析任务来说,本质上是一个分类问题。只需要将任务特定的输入输出插入到bert中然后端到端地微调即可。bert的预训练输入句子a和句子b在微调时可以类比为:
[0055]
①
paraphrasing任务中的句子对;
[0056]
②
entailment任务中的hypothesis-premise对;
[0057]
③
question answering任务中的question-passage对;
[0058]
④
text classification或者sequence tagging任务中的对(也就是只输入一个text,不必一定需要两个句子),对于bert的输出,bert的token表示将被输入到一个输出层,可以将[cls]对应的表示输入到一个输出层。
[0059]
优选的,s2语义情感分析中s22softmax分类在情感分类问题中,下游任务是分类问题,采用softmax函数处理,该函数输出各种情感预测概率,取概率最大者为结果。它可用公式表示为:
[0060][0061]
优选的,s3信息提取中s31prompt tuning,事先定义好一个prompt,如这里的"the capital of原始样本is【mask】";p-tuning做法是用一些伪prompt代替这些显式的prompt,具体的做法是可以用预训练词表中的【unused】token作为伪prompt(bert的vocab里有【unused 1】~【unused99】,就是为了方便增加词汇的),然后通过训练去更新这些token的参数。p-tuning的prompt prompt不是显式的,而是一些隐式的、经过训练的、模型认为最好的prompt token,p-tuning和bert相结合,在一些传统监督训练和小样本学习的任务中,取得不俗的效果。尤其是数据集少的时候应用于增强学习可用得到不错的效果。它有效解决有标注数据集不足的问题,在此模型应用中,预训练模型为:bert/gpt/roberta/t5
→
classification。
[0062]
优选的,s3信息提取中s32skep主体观点抽取skep是基于情感知识增强的情感预训练。情感分析旨在自动识别和提取文本中的倾向、立场、评价、观点等主观信息。它包含各式各样的任务,比如情感倾向分类、实体级情感分类、观点抽取、情绪分析等,整体上观点抽取任务均依赖于深入的情感语义理解。
[0063]
skep算法采用了无监督方法自动挖掘情感知识,然后利用情感知识构建预训练目标,从而让机器学会理解情感语义,具体的说,skep首先基于统计方法从大量无标记数据中自动挖掘情感知识,然后,基于自动挖掘的情感知识,skep对原始输入句子中的部分词语进行屏蔽(mask),即替换为特殊字符[mask]。除了像传统的预训练对单词或者连续片段进行屏蔽,skep还会对观点搭配这种skip-gram进行屏蔽,最后,skep设计了三个情感优化目标,要求模型复原被屏蔽的情感信息,包括:基于多标签优化的观点搭配预测,如图x1位置预测《product,fast》情感搭配;情感词预测,如图x6位置预测fast;情感极性分类,如图x6、x9预测该位置情感极性,这样,通过面向情感的优化目标进行预训练,自动挖掘的情感知识就被有效地嵌入到模型的语义表示中,最终形成面向情感的语义表示,针对观点抽取任务,可先在mpqa-h,cote_bd,cote-mf,cote-dp几个公开数据集训练,再放到实际场景微调。
[0064]
工作原理:本发明在使用的过程中,s1筛选食品安全内容,筛选食品安全内容包括s11关键词匹配法和s12无监督聚类分类法;
[0065]
s1筛选食品安全内容中s11中关键词匹配法中,s111筛选食品安全内容需要query和一个网页正文(content)的语义相关度,query与content的匹配使用短文本长文本语义
匹配;s112计算相似度,根据长文本的主题分布,计算分布生成短文本的概率作为相似度值;s113文档关键词抽取,抽取关键词做标签tag并设置主题模型,估算文档产生单词的概率;
[0066]
s11中关键词匹配法中s112计算相似度的公式为:
[0067][0068]
其中,q表示query,c表示content,w表示q中的词,zk表示第k个主题;
[0069]
s11中关键词匹配法中s113文档关键词抽取估计文档产生单词的概率公式为:
[0070]
p(w∣d)=k=1∑kp(w∣zk)p(zk∣d);
[0071]
其中,d表示文档内容,w表示词,zk表示第k个主题;
[0072]
s11中关键词匹配法中s113文档关键词抽取twe训练得到主题和单词向量表示公式为:
[0073]
similarity(w,d)=k=1∑kcos(vm,zk)p(zk|d);
[0074]
其中,d表示文档内容,w表示词,zk表示第k个主题;
[0075]
s1筛选食品安全内容中s12无监督聚类分类法中在若干样本数据中先进行knn聚类,分成两类各取其中心点,选取内容与食品安全无关者作为参照点并设定一阈值,计算目标新闻舆情与其距离,距离小于该阈值默认食品安全相关
[0076]
s2语义情感分析,语义情感分析包括s21bert预训练模型和s22softmax分类;
[0077]
s2语义情感分析中s21bert预训练模型中包括s211模型架构;s212bert输入和输出的表示;s213bert的预训练;s214bert的微调;
[0078]
s21bert预训练模型中s211模型架构建立多层双向的transformer的encoder,对比gpt,bert使用了双向self-attention架构,而gpt使用的是受限的self-attention,即限制每个token只能attend到其左边的token,
[0079]
s21bert预训练模型中s212bert输入和输出的表示,输入的自然语言句子通过wordpiece embeddings来转化为token序列。在token序列开头加上[cls],最终输出的[cls]这个token的embedding使用这个embedding来做分类任务,并在token序列中区分,区分方式有两种:
[0080]
1、在token序列中两个句子的token之间添加[sep]这样一个特殊的token;
[0081]
2、我们为每个token添加一个用来学习的embedding来区分token属于句子a还是句子b,这个embedding叫做segment embedding。
[0082]
bert的输入由三部分相加组成:token embeddings、segment embeddings和position embeddings;
[0083]
s21bert预训练模型中s213bert的预训练,bert使用两个无监督的任务进行预训练,分别是masked lm和next sentence prediction(nsp)
[0084]
task 1:masked lm
[0085]
为了能够双向地训练语言模型,bert的做法是简单地随机mask掉一定比例的输入token(这些token被替换成[mask]这个特殊token),然后预测这些被遮盖掉的token,这种方法就是masked lm(mlm),相当于完形填空任务(cloze task)。被mask掉的词将会被输入到一个softmax分类器中,分类器输出的维度对应词典的大小。在预训练时通常为每个序列
mask掉15%的token。与降噪自编码器(denoising auto-encoders)相比,我们只预测被mask掉的token,并不重建整个输入。
[0086]
这种方法允许预训练一个双向的语言模型,但是有一个缺点就是造成了预训练和微调之间的mismatch,这是因为[mask]这个token不会在微调时出现。为了缓解这一点,采取以下做法:在生成训练数据时我们随机选择15%的token进行替换,被选中的token有80%的几率被替换成[mask],10%的几率被替换成另一个随机的token,10%的几率该token不被改变。然后将使用交叉熵损失来预测原来的token。
[0087]
task 2:next sentence prediction(nsp)
[0088]
一些重要的nlp任务如question answering(qa)或者natural language inference(nli)需要理解句子之间的关系,而这种关系通常不会被语言模型直接捕捉到。为了使得模型能够理解句子之间的关系,我们训练了一个二值的next sentence prediction任务,其训练数据可以从任何单语语料库中生成。具体的做法是:当选择句子a和句子b作为训练数据时,句子b有50%的几率的确是句子a的下一句(标签是isnext),50%的几率是从语料库中随机选择的句子(标签是notnext)。[cls]对应的最后一个隐层输出向量被用来训练nsp任务,这个embedding就相当于sentence embedding。虽然这个预训练任务很简单,但是事实上在微调时其在qa和nli任务上表现出了很好的效果。在前人的工作中,只有sentence embedding被迁移到下游任务中,而bert会迁移所有的参数来初始化下游任务模型;
[0089]
s21bert预训练模型中s214bert的微调,
[0090]
transformer的self-attention机制允许bert建模多种下游任务。对于包含句子对的任务,通常的做法是先独立地对句子对中的句子进行编码,然后再应用双向交叉注意。而bert使用self-attention机制统一了这两个过程,这是因为对拼接起来的句子对进行self-attention有效地包含了两个句子之间的双向交叉注意。
[0091]
对于情感分析任务来说,本质上是一个分类问题。只需要将任务特定的输入输出插入到bert中然后端到端地微调即可。bert的预训练输入句子a和句子b在微调时可以类比为:
[0092]
①
paraphrasing任务中的句子对;
[0093]
②
entailment任务中的hypothesis-premise对;
[0094]
③
question answering任务中的question-passage对;
[0095]
④
text classification或者sequence tagging任务中的对(也就是只输入一个text,不必一定需要两个句子)。
[0096]
对于bert的输出,bert的token表示将被输入到一个输出层,可以将[cls]对应的表示输入到一个输出层;
[0097]
s2语义情感分析中s22softmax分类在情感分类问题中,下游任务是分类问题,采用softmax函数处理,该函数输出各种情感预测概率,取概率最大者为结果。它可用公式表示为:
[0098]
[0099]
s3信息提取,信息提取包括s31prompt tuning和s32skep主体观点抽取。
[0100]
s3信息提取中s31prompt tuning,事先定义好一个prompt,如这里的"the capital of原始样本is【mask】";
[0101]
p-tuning做法是用一些伪prompt代替这些显式的prompt,具体的做法是可以用预训练词表中的【unused】token作为伪prompt(bert的vocab里有【unused 1】~【unused99】,就是为了方便增加词汇的),然后通过训练去更新这些token的参数。p-tuning的prompt prompt不是显式的,而是一些隐式的、经过训练的、模型认为最好的prompt token。
[0102]
p-tuning和bert相结合,在一些传统监督训练和小样本学习的任务中,取得不俗的效果。尤其是数据集少的时候应用于增强学习可用得到不错的效果。它有效解决有标注数据集不足的问题,在此模型应用中,预训练模型为:bert/gpt/roberta/t5
→
classification;
[0103]
s3信息提取中s32skep主体观点抽取skep是基于情感知识增强的情感预训练。情感分析旨在自动识别和提取文本中的倾向、立场、评价、观点等主观信息。它包含各式各样的任务,比如情感倾向分类、实体级情感分类、观点抽取、情绪分析等,整体上观点抽取任务均依赖于深入的情感语义理解。
[0104]
skep算法采用了无监督方法自动挖掘情感知识,然后利用情感知识构建预训练目标,从而让机器学会理解情感语义。
[0105]
具体的说,skep首先基于统计方法从大量无标记数据中自动挖掘情感知识,包括情感词(如图中情感词fast、appreciated)、情感词极性(如图中fast对应的情感极性为积极)以及观点搭配(如图中《product,fast》构成的二元组)。
[0106]
然后,基于自动挖掘的情感知识,skep对原始输入句子中的部分词语进行屏蔽(mask),即替换为特殊字符[mask]。除了像传统的预训练对单词或者连续片段进行屏蔽,skep还会对观点搭配这种skip-gram进行屏蔽。
[0107]
最后,skep设计了三个情感优化目标,要求模型复原被屏蔽的情感信息,包括:基于多标签优化的观点搭配预测,如图x1位置预测《product,fast》情感搭配;情感词预测,如图x6位置预测fast;情感极性分类,如图x6、x9预测该位置情感极性。
[0108]
这样,通过面向情感的优化目标进行预训练,自动挖掘的情感知识就被有效地嵌入到模型的语义表示中,最终形成面向情感的语义表示,针对观点抽取任务,可先在mpqa-h,cote_bd,cote-mf,cote-dp几个公开数据集训练,再放到实际场景微调;
[0109]
以上实施例仅用以说明本发明而并非限制本发明所描述的技术方案,尽管本说明书参照上述的各个实施例对本发明已进行了详细的说明,但本发明不局限于上述具体实施方式,因此任何对本发明进行修改或等同替换;而一切不脱离发明的精神和范围的技术方案及其改进,其均涵盖在本发明的权利要求范围当中。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1